爬取qq,酷我,千千VIP音乐 上
多线程以后再打吧
记在开头:如果req返回不是200不要慌,先试一下下面的方法
404:请求头,
503:访问频繁加一个time.sleep:
206:似乎和200一样不过它代表网页可以缓存
还不对?换个ip或cookie?
千千音乐
爬之前不得不喷一下,千千版权真少,加载真慢...
步骤|思路:
首先要能爬取一首歌然后再爬取歌单的第一面,最后爬取可选择的页数
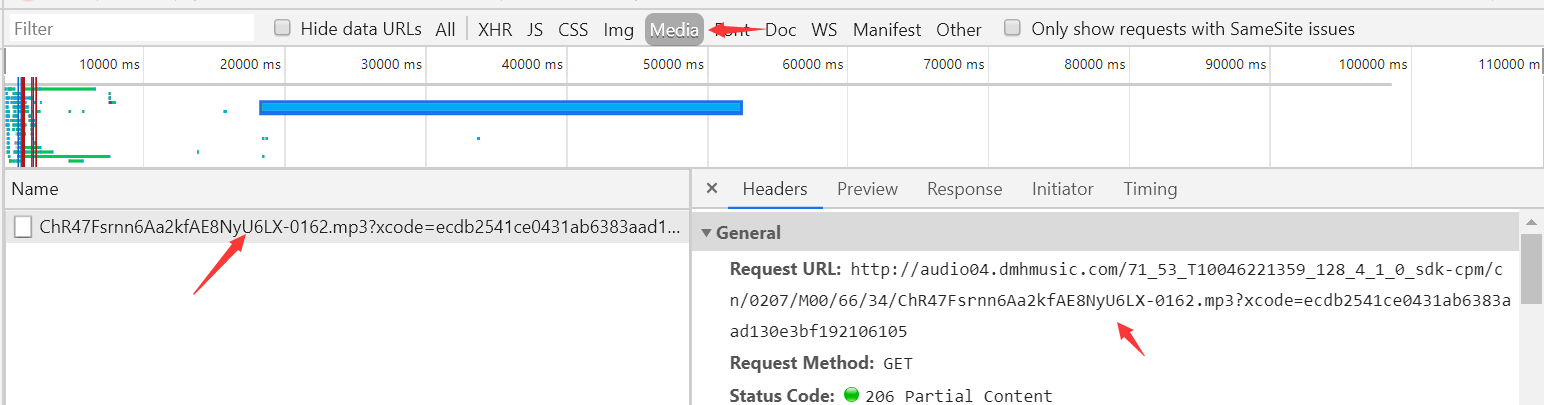
爬取一首歌首先要找到network里的media 里面如果有东西则可发现这才是这首歌真实的 播放|下载 地址 然后根据xcode来搜索(倒推)它的下载源比如有 songlink,ting...等类似的文件,进去后preview可以看到歌曲的各种介绍,最后爬进这个下载源获得歌曲下载链接等数据 即可
坑点:
(我认为)json文件是像字典一样的所以开头结尾要是{}如果{}前后有东西要先正则除去,之后才能json.loads(xxx)否则会报错说什么不是json格式(这里百度的话答案都是 ‘ 叫你该单引号 ’ 之类的然鹅实际上是上面的问题)
如果request.get(url,parama,headers).text='' .content=b''则说明header要加referer参数(被反爬了)
下载一首歌
播放一首歌后就可以看到这个mp3文件,点进去就是下载这首歌
def qianqian_download_mp3(song_name,song_artist,song_api): ''' 下载音乐 :return: ''' res = requests.get(song_api) res.encoding = res.apparent_encoding req = res.content with open(song_name + '-' + song_artist + '.mp3', 'wb') as f: f.write(req) path = os.getcwd() print(song_name + '-' + song_artist + ' 成功下载到' + path) time.sleep(1.5) return
找到歌的id
对比不同的歌发现只有xcode和MP3前面那个字符串改变推测这就和id有关的东西
找到所有歌的id
因为歌单肯定包含所有歌的id所以我们直接找歌单就行了,但是出大问题,xcode和那串字符搜索不到!!!
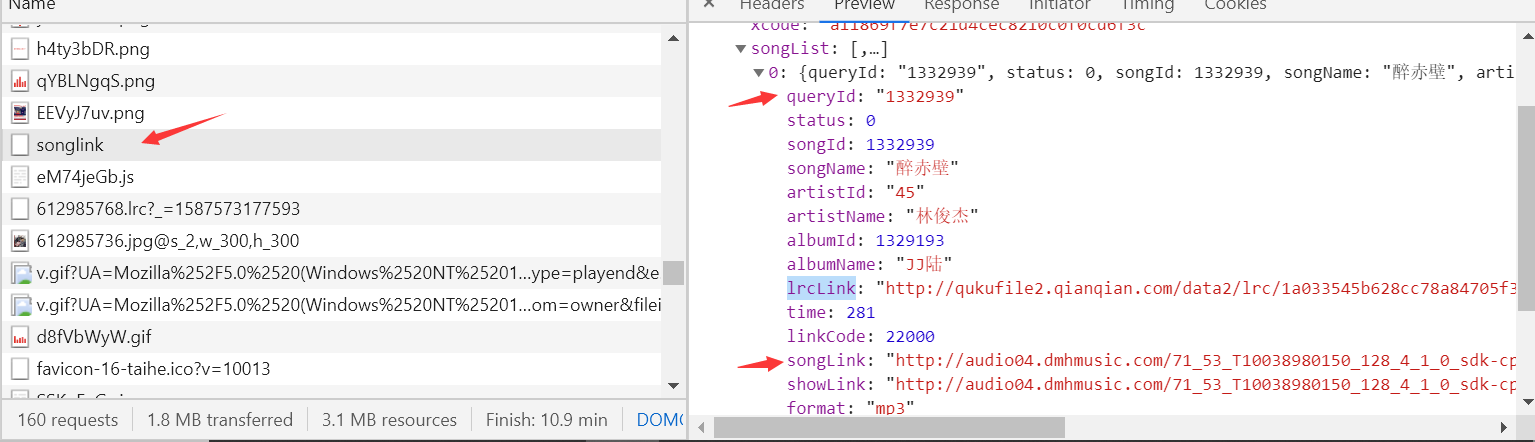
我找半天最后发现在千千音乐盒里面才有songlist和songlink
而这里面的songlist是你听过的歌
songlink里面什么都有|歌词地址,歌曲地址...
再观察url是一个post类型
data参数发现是songid也就是说我们只要有songid就可以为所欲为了
假如我们已经有了songid那么可以先写出get_song_api的代码
def get_qianqian_song_api(song_nameid): ''' 得到千千音乐歌曲的下载地址 :param song_nameid: :param song_keyid: :return: ''' url = 'http://play.taihe.com/data/music/songlink' data = { 'songIds': '%s'%song_nameid, 'hq': '0', 'type': 'm4a,mp3', 'rate': '', 'pt': '0', 'flag': '-1', 's2p': '-1', 'prerate': '-1', 'bwt': '-1', 'dur': '-1', 'bat': '-1', 'bp': '-1', 'pos': '-1', 'auto': '-1', } header = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Content-Length': '114', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie': 'BAIDUID=39467BA490578EC38644901B14F6C417:FG=1; flash_tip_pop=true; app_vip=show; tipToTaihe=1; UM_distinctid=171a0f546b6835-04de0099ddf7e4-4313f6a-e1000-171a0f546b7acb; log_sid=158754725356639467BA490578EC38644901B14F6C417; sort-guide-showtimes=2; sort-guide-lastshow=1587547252753; Hm_lvt_2b0f0945031c52df2a103f3ed5d7c3aa=1587543328,1587543572,1587547253,1587547334; Hm_lpvt_2b0f0945031c52df2a103f3ed5d7c3aa=1587548461', 'Host': 'play.taihe.com', 'Origin': 'http://play.taihe.com', 'Pragma': 'no-cache', 'Referer': 'http://play.taihe.com/?__m=mboxCtrl.playSong&__a=2113234&__o=song/||songListIcon&fr=web||play.taihe.com&__s=%E6%9E%97%E4%BF%8A%E6%9D%B0', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36', } req = requests.post(url, headers=header, data=data) text = req.json() return text['data']['songList'][0]['songLink']
下面我们就找song_nameid了
进入一首歌的页面
直接搜索发现网页html源码就有有版权的song_nameid!!!
就是不太好处理...随便正则搞一搞
def get_qianqian_song_list(key_word,page): url='http://music.taihe.com/search/song?s=1&key='+key_word+'&jump=0&start='+str((page-1)*20)+'&size=20&third_type=0' header={ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Cookie': 'BAIDUID=39467BA490578EC38644901B14F6C417:FG=1; u_lo=0; u_id=; u_t=; flash_tip_pop=true; app_vip=show; tipToTaihe=1; UM_distinctid=171a0f546b6835-04de0099ddf7e4-4313f6a-e1000-171a0f546b7acb; CNZZDATA1262632547=358279739-1587539552-http%253A%252F%252Fmusic.taihe.com%252F%7C1587539552; Hm_lvt_d0ad46e4afeacf34cd12de4c9b553aa6=1587543138,1587543339,1587543455,1587545349; tracesrc=web%7C%7Cplay.taihe.com; log_sid=158754534871539467BA490578EC38644901B14F6C417; __qianqian_pop_tt=6; Hm_lpvt_d0ad46e4afeacf34cd12de4c9b553aa6=1587546565', 'Host': 'music.taihe.com', 'Pragma': 'no-cache', 'Referer': 'http://music.taihe.com/', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' } req = requests.get(url, headers=header) res = req.text song_ids = re.findall(r'"sid":(\d+),"', res) return song_ids
改变歌手名字
这只用改keyword就行了
改变页码来获得普遍性结果
根据规律页面改变至于start有关
page-1=start/20
完整代码
暂时只支持搜索歌手
看class就知道大概了吧
顺便把歌词也弄到了|lrk_api 不过没有下
如果有兴趣也可以尝试自己下下来
#-*- coding:utf-8 -*- # @Author : Dummerfu # @Time : 2020/4/22 16:54 import requests import os from bs4 import BeautifulSoup import time import re import json class Song_info(object): def __init__(self): self.song_name='' self.song_nameid='' self.artist_name='' self.lrk_api='' self.belong='' self.song_api='' def qianqian_download_mp3(song_name,song_artist,song_api): ''' 下载音乐 :return: ''' res = requests.get(song_api) res.encoding = res.apparent_encoding req = res.content with open(song_name + '-' + song_artist + '.mp3', 'wb') as f: f.write(req) path = os.getcwd() print(song_name + '-' + song_artist + ' 成功下载到' + path) time.sleep(1.5) return def get_qianqian_song_list(key_word,page): url='http://music.taihe.com/search/song?s=1&key='+key_word+'&jump=0&start='+str((page-1)*20)+'&size=20&third_type=0' header={ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Cookie': 'BAIDUID=39467BA490578EC38644901B14F6C417:FG=1; u_lo=0; u_id=; u_t=; flash_tip_pop=true; app_vip=show; tipToTaihe=1; UM_distinctid=171a0f546b6835-04de0099ddf7e4-4313f6a-e1000-171a0f546b7acb; CNZZDATA1262632547=358279739-1587539552-http%253A%252F%252Fmusic.taihe.com%252F%7C1587539552; Hm_lvt_d0ad46e4afeacf34cd12de4c9b553aa6=1587543138,1587543339,1587543455,1587545349; tracesrc=web%7C%7Cplay.taihe.com; log_sid=158754534871539467BA490578EC38644901B14F6C417; __qianqian_pop_tt=6; Hm_lpvt_d0ad46e4afeacf34cd12de4c9b553aa6=1587546565', 'Host': 'music.taihe.com', 'Pragma': 'no-cache', 'Referer': 'http://music.taihe.com/', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' } req = requests.get(url, headers=header) res = req.text song_ids = re.findall(r'"sid":(\d+),"', res) return song_ids def get_single_song_info(song_nameid): ''' 得到千千音乐歌曲的下载地址 :param song_nameid: :param song_keyid: :return: ''' url = 'http://play.taihe.com/data/music/songlink' data = { 'songIds': '%s'%song_nameid, 'hq': '0', 'type': 'm4a,mp3', 'rate': '', 'pt': '0', 'flag': '-1', 's2p': '-1', 'prerate': '-1', 'bwt': '-1', 'dur': '-1', 'bat': '-1', 'bp': '-1', 'pos': '-1', 'auto': '-1', } header = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Content-Length': '114', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Cookie': 'BAIDUID=39467BA490578EC38644901B14F6C417:FG=1; flash_tip_pop=true; app_vip=show; tipToTaihe=1; UM_distinctid=171a0f546b6835-04de0099ddf7e4-4313f6a-e1000-171a0f546b7acb; log_sid=158754725356639467BA490578EC38644901B14F6C417; sort-guide-showtimes=2; sort-guide-lastshow=1587547252753; Hm_lvt_2b0f0945031c52df2a103f3ed5d7c3aa=1587543328,1587543572,1587547253,1587547334; Hm_lpvt_2b0f0945031c52df2a103f3ed5d7c3aa=1587548461', 'Host': 'play.taihe.com', 'Origin': 'http://play.taihe.com', 'Pragma': 'no-cache', 'Referer': 'http://play.taihe.com/?__m=mboxCtrl.playSong&__a=2113234&__o=song/||songListIcon&fr=web||play.taihe.com&__s=%E6%9E%97%E4%BF%8A%E6%9D%B0', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36', } req = requests.post(url, headers=header, data=data) text = req.json() return text['data']['songList'][0] def get_song_info_from_qianqian(song_info,tot,qianqian_song_list): ''' 得到每个歌曲的info :param song_info: :param tot: :param kuwo_song_list: :return: ''' for i in qianqian_song_list: song=get_single_song_info(i) song_info[tot].song_nameid=i song_info[tot].song_api=song['songLink'] song_info[tot].artist_name=song['artistName'] song_info[tot].song_name=song['songName'] song_info[tot].belong='qianqian' song_info[tot].lrk_api=song['lrcLink'] print(tot, song_info[tot].song_name, '--------歌手:', song_info[tot].artist_name) tot+=1 return tot def qianqian_spider(): print('------------introduction-------------------') print('---------------程序仅供学习交流-------------') print('因涉及到vip音乐下载请不要讨论版权问题\n本程序音乐来源--音乐') print('输入关键字可以查找,之后再输入编号即可下载 None则代表无版权') # print('flag:1:只在酷我音乐中寻找,2:只在qq音乐中寻找 否则同时寻找') print('下载可能比较慢防封ip|暂不知道音质是啥(默认?)') print('--------------------------------------------') #key_word = input(' 输入关键字\n ') key_word=input() page = 0 global song_info song_info = [Song_info() for i in range(10000)] global tot # try: while 1: page += 1 qianqian_song_list = get_qianqian_song_list(key_word, page) tot = 1 time.sleep(0.5) tot=get_song_info_from_qianqian(song_info,tot,qianqian_song_list) # 重复选择下载歌曲并下载 while (1): download_song = input('输入要下载的一首歌编号|输入pass:加载一页|exit: 退出程序|return:返回搜索关键词\n').strip() if download_song == 'exit': return 0 if download_song == 'return': os.system('cls') return 1 if download_song == 'pass': os.system('cls') break else: download_song = int(download_song) song_name = song_info[download_song].song_name song_nameid = song_info[download_song].song_nameid song_artist = song_info[download_song].artist_name song_api=song_info[download_song].song_api #song_lrk_api = song_info[download_song].lrk_api print(song_name, song_artist, '正在下载') if song_info[download_song].belong == 'qianqian': print('------正在下载' + song_name + '-------') #song_api=get_qianqian_song_api(song_nameid) qianqian_download_mp3(song_name, song_artist, song_api) #download_qianqian_song_lrk(song_name, song_artist, song_lrkid) # except: # print('已经到最后一页') if __name__=='__main__': qianqian_spider()
总的来说思路都一样,见招拆招
酷我音乐|亲测能用
思路都差不多...
1 下载一首歌
2 找到歌的id
3 找到所有歌的id
4 进入一首歌的页面
5 下载
6 改变歌手
7 改变页码
先放一首歌发现有一个url?文件进入发现里面就是歌曲的url即可下载url长这样http://www.kuwo.cn/urlformat=mp3&rid=76323299&response=url&type=convert_url3&br=128kmp3&from=web&t=1583462447941&reqId=e2c09e60-5f53-11ea-9a8c-a5d0d057abd1
但是不知道为什么可以不用改动reqid坑我半天直接删掉都行 吐血
多找几个能放的歌发现只有rid和reqId改变。这就可以合成歌曲下载地址
然后再搜索歌手,翻页(这里你会发现翻页上方的搜索码不会变化,应该被隐藏了?)可以发现出来一个song_list里面有所有歌的rid,name等data(翻页真时有惊喜)
然后因为不能直接从页面获得搜索url的变化规律所有点击搜索页面点击搜索来抓一个search?的包。可以发现里面的url只有rid和reqId变化,所以只用改rid即可进入单个歌曲的页面然后再根据上面的即可下载歌曲
盲猜改变歌手,页面 仍有用
完整代码
import requests import pprint import os import re import selenium import threading import sys import time class Song_info(object): def __init__(self): self.name='' self.song_nameid='' self.atrist_name='' self.belong='' def get_kuwo_song_list(key_word,page): ''' 得到关键字和page的歌单 :param key_word: :param page: :return: ''' #url='https://y.qq.com/portal/search.html url='http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key='+key_word+'&pn='+str(page)+'&rn=30' header={'Referer': 'http://www.kuwo.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6', 'csrf': '7OUIGZGNE07', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36', 'cookie':'_ga=GA1.2.816678460.1583305531; _gid=GA1.2.1330734898.1583412010; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1583412949,1583413217,1583413235,1583413437; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1583419987; kw_token=7OUIGZGNE07'} res=requests.get(url,headers=header) res.encoding=res.apparent_encoding html=res.json() song_list=html['data']['list'] return song_list def kuwo_down_load(song_name,song_api): ''' 下载酷我音乐 :param song_name: :param song_api: :return: ''' html=requests.get(song_api).content with open(song_name+'.mp3','wb') as f: f.write(html) path=os.getcwd() print(song_name+' 成功下载到'+path) time.sleep(1.5) return def get_kuwo_song_api(song_nameid,song_keyid): ''' 获得kuwosong的下载地址 :param song_nameid: :param song_keyid: :return: ''' url='http://www.kuwo.cn/url?format=mp3&rid='+str(song_nameid)+'&response=url&type=convert_url3&br=128kmp3&from=web&t=1583424526196' # 1 这里很奇怪reqID为什么可以不用管 不然我早就弄好了 # 2 不能直接进preview里然后用里面的url格式来套不然会403 header={'Cookie':'ga=GA1.2.816678460.1583305531; _gid=GA1.2.1330734898.1583412010; _gat=1; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1583412949,1583413217,1583413235,1583413437; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1583413437; kw_token=3PV9YR4C19D', 'csrf':'3PV9YR4C19D', 'Referer':'http://www.kuwo.cn/play_detail/324244', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' }#当前页面的标头 html=requests.get(url,headers=header).json() song_api=html['url'] #print(song_api) return song_api def get_song_info_from_kuwo(song_info,tot,kuwo_song_list): ''' 从歌单得到每一首歌的数据 :param tot: :param kuwo_song_list: :return: ''' for song in kuwo_song_list: song_info[tot].name = song['name'] song_info[tot].song_nameid = song['rid'] song_info[tot].atrist_name = song['artist'] song_info[tot].song_keyid='' song_info[tot].belong = 'kuwo' print(tot, song_info[tot].name, '--------歌手:', song_info[tot].atrist_name) tot += 1 return tot def kuwo_spider(): print('-----------------introduction---------------') print('---------------程序仅供学习交流-------------') print('因涉及到vip音乐下载请不要讨论版权问题\n本程序音乐来源--酷我音乐') print('输入歌手|歌曲名称可以查找,之后再输入编号即可下载')print('暂不知道音质是啥(默认?)') print('--------------------------------------------') key_word=input(' 输入关键字\n ') page=0 global song_info song_info=[Song_info() for i in range(10000)] global tot try: while 1: page+=1 kuwo_song_list=get_kuwo_song_list(key_word,page) tot=1 tot=get_song_info_from_kuwo(tot,kuwo_song_list) #重复选择下载歌曲并下载 while(1): download_song=input('输入要下载的一首歌编号 输入pass加载一页 exit 退出程序\n') if download_song=='exit': return if download_song=='pass': break else: download_song=int(download_song) song_name=song_info[download_song].name song_nameid=song_info[download_song].song_nameid song_keyid=song_info[download_song].song_keyid song_artist=song_info[download_song].atrist_name print(song_name, song_artist,'开始下载') if song_info[download_song].belong=='kuwo': print('------正在下载' + song_name + '-------') song_api=get_kuwo_song_api(song_nameid,song_keyid) kuwo_down_load(song_name,song_api) except: print('已经到最后一页') if __name__=='__main__': kuwo_spider() time.sleep(1)
之后pyinstaller打包一下即可
没懂?下篇 图解 更详细
有用点个推荐吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号