阅读笔记3:字典和集合
1 泛映射类型
collections.abc模块中有Mapping和MutableMapping两个抽象基类,他们的作用视为dict和其他类似的类型定义形式接口(在python2.6-3.2中,这两个基类属于collections模块)
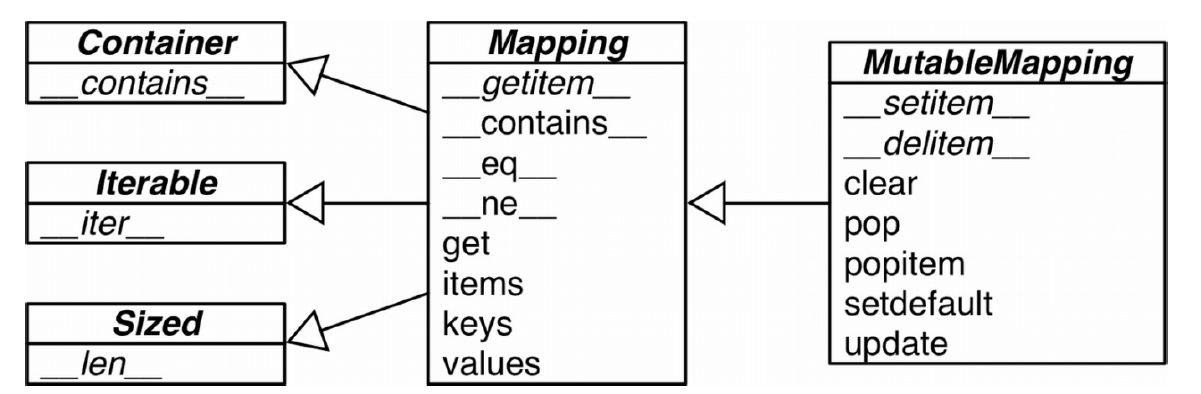
非抽象映射类型一般不会直接继承这些抽象基类,他们会直接对dict或者collections.User.Dict进行扩展
这些抽象基类的主要作用是作为形式化的文档,它们定义了构建一个映射类型所需要的最基本的接口。然后它们还可以和isinstance一起被用来判定某个数据是不是广义上的映射类型
标准库里的所有映射类型都是利用dict来实现的,他们有个共同的限制,只有可散列的数据类型才能用作这些映射里的键
可散列的数据类型:
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不可变的,而且这个对象需要实现__hash__()方法。另外可散列对象还要有__qe__()方法,这样才能和其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的
原子不可变数据类型(str , bytes 和 数值类型)都是可散列类型,frozenset也是可散列的。
元组的话,只有当它所包含的所有元素都是可散列的,它才是可散列的
>>> t1 = (1, 2, (30, 40))
>>> hash(t1)
1350807749
>>> t2 = (1, 2, [30, 40])
>>> hash(t2)
Traceback (most recent call last):
File "<pyshell#92>", line 1, in <module>
hash(t2)
TypeError: unhashable type: 'list'
一般来说,用户自定义的类型的对象都是可散列的,散列值就是它们的id()函数的返回值,所以所有对象在比较的时候都是不相等的。如果一个对象实现了__eq__方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的
字典的构造方法:
>>> a = dict(one=1,two=2)
>>> b = {'one':1, 'two':2}
>>> c = dict(zip(['one','two'],[1,2]))
>>> d = dict([('one',1),('two',2)])
>>> e = dict({'one':1, 'two':2})
>>> a == b == c == d == e
True
2.字典推导
字典推导可以从任何以键值对作为元素的可迭代对象中构建出字典
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不可变的,而且这个对象需要实现__hash__()方法。另外可散列对象还要有__qe__()方法,这样才能和其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的
原子不可变数据类型(str , bytes 和 数值类型)都是可散列类型,frozenset也是可散列的。
元组的话,只有当它所包含的所有元素都是可散列的,它才是可散列的
>>> t1 = (1, 2, (30, 40))
>>> hash(t1)
1350807749
>>> t2 = (1, 2, [30, 40])
>>> hash(t2)
Traceback (most recent call last):
File "<pyshell#92>", line 1, in <module>
hash(t2)
TypeError: unhashable type: 'list'
一般来说,用户自定义的类型的对象都是可散列的,散列值就是它们的id()函数的返回值,所以所有对象在比较的时候都是不相等的。如果一个对象实现了__eq__方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的
字典的构造方法:
>>> a = dict(one=1,two=2)
>>> b = {'one':1, 'two':2}
>>> c = dict(zip(['one','two'],[1,2]))
>>> d = dict([('one',1),('two',2)])
>>> e = dict({'one':1, 'two':2})
>>> a == b == c == d == e
True
2.字典推导
字典推导可以从任何以键值对作为元素的可迭代对象中构建出字典
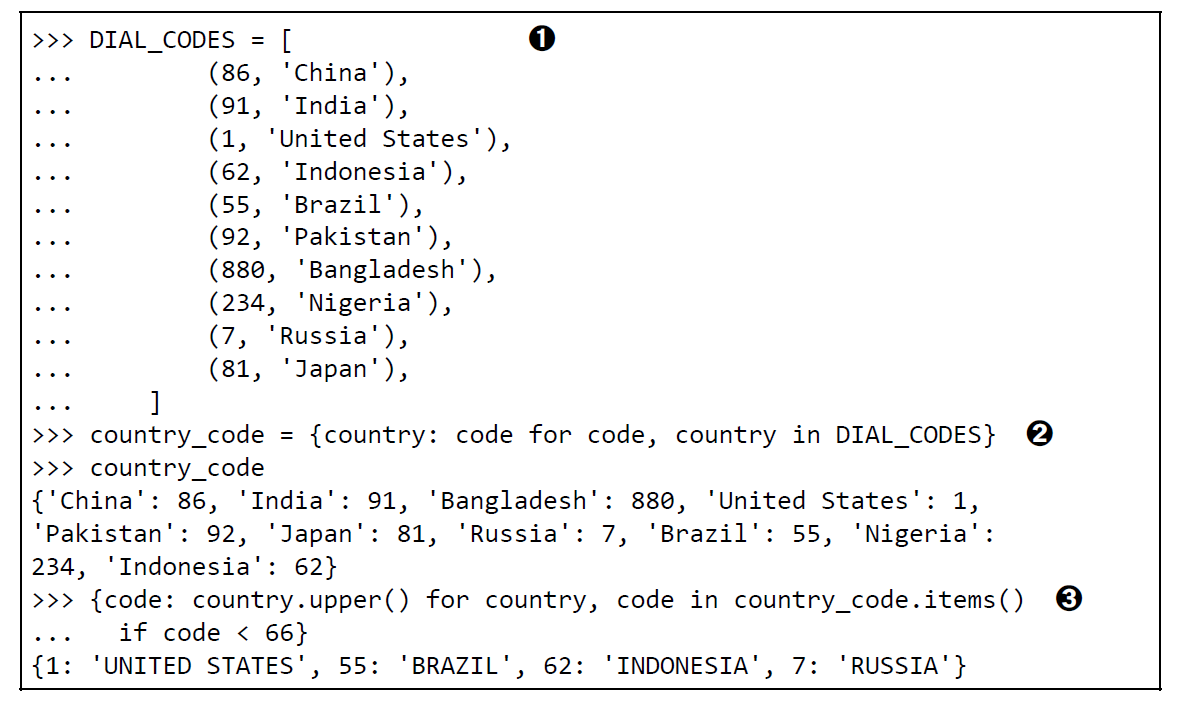
用setdefault处理找不到的键
# BEGIN INDEX
"""Build an index mapping word -> list of occurrences"""
import sys
import re
WORD_RE = re.compile('\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index.setdefault(word, []).append(location) # <1>
# print in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
# END INDEX
3.映射的弹性键查询
当某个键在映射里不存在时,希望通过这个键读取值的时候得到一个默认值,有两个方法:
1)通过defaultdict这个类型而不是普通的dict
2)定义一个dict的子类,然后在子类中实现__missing__方法
3.1 defaultdict: 处理找不到的键的一个选择
在实例化一个defaultdict的时候,需要给构造方法提供一个可调用对象,这个可调用对象会在__getitem__找不到键的时候被调用,让__getitem__返回某种默认值
假设新建了这样一个字典:
dd = defaultdict(list), 如果键'new_key'在dd中还不存在的话,那么表达式dd['new_key']会按照以下步骤:
1)调用list()来创建一个新列表
2)把这个新列表作为值,‘new_key’作为它的键,放到dd中
3)返回这个列表的引用
而这个用来生成默认值的可调用对象存放在名为default_factory的实例属性里
假设dd是个defaultdict,k是个找不到的键,dd[k]这个表达式会调用default_factory创造某个默认值。而dd.get(k)则会返回None
所有背后的原因其实是特殊方法 __missing__。它会在defaultdict遇到找不到的键的时候调用default_factory,这个特性是所有映射类型可以选择去支持的
3.2 特殊方法__missing__
所有的映射类型在处理找不到的键的时候,都会牵扯到__missing__。虽然基类dict并没有定义这个方法,但是dict是知道有这么个东西存在的。也就是说,如果有一个类继承了dict,然后这个继承类提供了__missing__方法,那么在__getitem__碰到找不到的键的时候,python就会自动调用它,而不是抛出一个KeyError异常
当某个键在映射里不存在时,希望通过这个键读取值的时候得到一个默认值,有两个方法:
1)通过defaultdict这个类型而不是普通的dict
2)定义一个dict的子类,然后在子类中实现__missing__方法
3.1 defaultdict: 处理找不到的键的一个选择
在实例化一个defaultdict的时候,需要给构造方法提供一个可调用对象,这个可调用对象会在__getitem__找不到键的时候被调用,让__getitem__返回某种默认值
假设新建了这样一个字典:
dd = defaultdict(list), 如果键'new_key'在dd中还不存在的话,那么表达式dd['new_key']会按照以下步骤:
1)调用list()来创建一个新列表
2)把这个新列表作为值,‘new_key’作为它的键,放到dd中
3)返回这个列表的引用
而这个用来生成默认值的可调用对象存放在名为default_factory的实例属性里
# BEGIN INDEX_DEFAULT
"""Build an index mapping word -> list of occurrences"""
import sys
import re
import collections
WORD_RE = re.compile('\w+')
index = collections.defaultdict(list) # <1>
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index[word].append(location) # <2>
# print in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
# END INDEX_DEFAULT
备注:
defaultdict里的default_factory只会在__getitem__里被调用,在其他的方法里完全不会发挥作用。假设dd是个defaultdict,k是个找不到的键,dd[k]这个表达式会调用default_factory创造某个默认值。而dd.get(k)则会返回None
所有背后的原因其实是特殊方法 __missing__。它会在defaultdict遇到找不到的键的时候调用default_factory,这个特性是所有映射类型可以选择去支持的
3.2 特殊方法__missing__
所有的映射类型在处理找不到的键的时候,都会牵扯到__missing__。虽然基类dict并没有定义这个方法,但是dict是知道有这么个东西存在的。也就是说,如果有一个类继承了dict,然后这个继承类提供了__missing__方法,那么在__getitem__碰到找不到的键的时候,python就会自动调用它,而不是抛出一个KeyError异常
# BEGIN STRKEYDICT0
class StrKeyDict0(dict): # <1>
def __missing__(self, key):
if isinstance(key, str): # <2>
raise KeyError(key)
return self[str(key)] # <3>
def get(self, key, default=None):
try:
return self[key] # <4>
except KeyError:
return default # <5>
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys() # <6>
# END STRKEYDICT0
说明:
1) isinstance(key,str)在上面的__misssing__是必须的,如果str(k)不是一个存在的键,代码就会陷入无限递归。__misssing__最后一行中的self[str(key)]会调用__getitem__,而这个str(key)不存在,又会调用__missing__2) 为了保持一致性,__contains__方法在这里也是必须的,因为k in d这个操作会调用它。但是我们从dict继承到的__contains__方法不会在找不到键的时候调用__missing__方法。
4.字典的变种
collections.OrderDict
这个类型在添加键的时候会保持顺序。键的迭代次序总是一致的。OrderDict的popitem方法默认删除并返回的是字典里的最后一个元素。
collections.ChainMap
该类型可以容纳数个不同的映射对象,然后在进行键查找操作的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。
import builtins
pylookup = ChainMap(locals(), globals(), vars(builtins))
collections.Counter
这个映射类型会给键准备一个整数计数器。每次更新一个键的时候,都会增加这个计数器。
>>> import collections
>>> ct = collections.Counter('abracadabra')
>>> ct
Counter({'a': 5, 'r': 2, 'b': 2, 'c': 1, 'd': 1})
>>> ct.update('aaaaazzz')
>>> ct
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.most_common(2)
[('a', 10), ('z', 3)]
>>>
collections.UserDict
这个类其实是把标准的dict用纯python实现了一遍
跟OrderedDict, ChainMap 和Counter这些开箱即用的类型不同,UserDict是让用户继承写子类的
5.子类化UserDict
一般从UserDict来继承,而不是dict;因为dict会在某些方法的实现上走一些捷径,导致我们不得不在子类中重写这些方法,但是UserDict就不会带来这些问题。UserDict并不是dict的子类,但是它有一个叫做data的属性,是dict的实例,这个属性实际上是UserDict最终存储数据的地方。
# BEGIN STRKEYDICT
import collections
class StrKeyDict(collections.UserDict): # <1>
def __missing__(self, key): # <2>
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data # <3>
def __setitem__(self, key, item):
self.data[str(key)] = item # <4>
# END STRKEYDICT
UserDict继承的是MutableMapping, 所以StrKeyDict里剩下的那些映射类型的方法都是从UserDict MutableMapping和Mapping这些超类继承而来的
Mapping类提供了好几个实用的方法:
MutableMapping.update
可以直接利用,还可用在__init__里,让构造方法利用传入的各种参数来创建实例
这个方法背后是用self[key]=value来添加新值的,所以它其实是在使用__setitem__方法
Mapping.get
这个方法的实现和STRKEYDICT0中的get是一模一样的
6.不可变映射类型
标准库里所有的映射类型都是可变的
从python3.3开始,types模块引入一个封装类名叫MappingProxyType;如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读映射,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。

7.集合论
1) 集合的本质是许多唯一对象的聚集,集合可以用于去重
2) 集合中的元素必须是可散列的,set类型本身是不可散列的,但是frozenset可以,因此可以创建一个包含不同forzenset的set
3) 除了唯一性,集合还实现了很多基础的中缀运算符:
a | b 返回的是a和b的合集
a & b 返回的是交集
a - b 返回的是差集
假设 needles和haystack都是集合,那么查询needles的元素在haystack里出现的次数:
found = len(needles & haystack)
集合对象的创建:
两种方法(第一种更高效):
s = {1,2,3}
s = set([1,2,3])
如果是空集,那么必须用set()
集合推导:
>>> mylist = (1,2,3,4,5)
>>> myset = {chr(i) for i in mylist}
>>> myset
set(['\x01', '\x03', '\x02', '\x05', '\x04'])
>>>
8. dict和set的背后
8.1字典中的散列表
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。
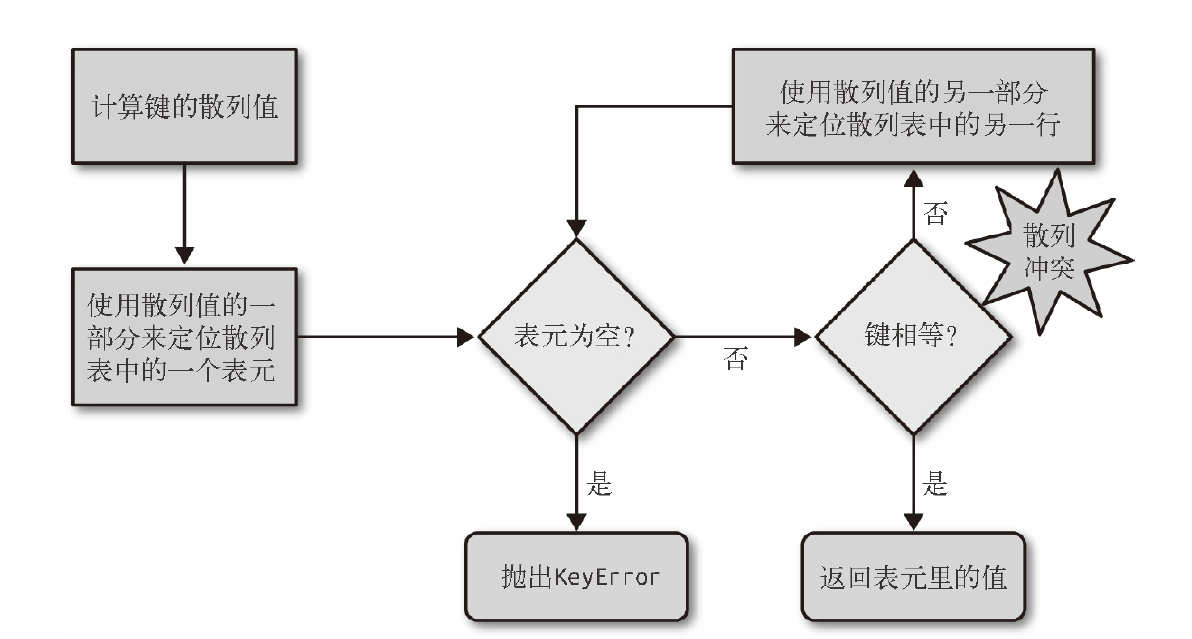
在一般的数据结构教材中,散列表里的单元通常叫做表元(bucket), 在dict的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有的表元大小一致,所以可以通过偏移量来读取某个表元
因为Python会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值,python会用hash()方法来做这个事情
1)散列值和相等性
内置的hash()方法可以用于所有的内置类型对象
如果是自定义对象调用hash()的话,其实是运行自定义的__hash__
如果两个对象在比较的时候是相等的,那么他们的散列值必须相等,否则散列表不能正常运行
为了让散列值能够胜任散列表索引这一角色,他们必须在索引空间中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等的对象,他们散列值的差别应该最大
从python 3.3开始,str bytes和datetime对象的散列值计算过程中多了随机的“加盐”这一步。所加盐值是python进程内的一个常量,但是每次启动python解释器都会生成一个不同的盐值。随机盐值的加入是为了防止DOS攻击
2)散列表算法
内置的hash()方法可以用于所有的内置类型对象
如果是自定义对象调用hash()的话,其实是运行自定义的__hash__
如果两个对象在比较的时候是相等的,那么他们的散列值必须相等,否则散列表不能正常运行
为了让散列值能够胜任散列表索引这一角色,他们必须在索引空间中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等的对象,他们散列值的差别应该最大
从python 3.3开始,str bytes和datetime对象的散列值计算过程中多了随机的“加盐”这一步。所加盐值是python进程内的一个常量,但是每次启动python解释器都会生成一个不同的盐值。随机盐值的加入是为了防止DOS攻击
2)散列表算法
8.2 dict的实现及其导致的结果
1.键必须是可散列的
一个可散列对象必须满足以下要求:
1)支持hash()函数,并且通过__hash__()方法所得到的散列值是不变的
2)支持通过__eq__()方法来检测相等性
3)若a == b 为真,则 hash(a) == hash(b)也为真
所有由用户定义的对象默认都是可散列的,它们的散列值是由id()来获取,而且它们都是不相等的
2.字典在内存上的开销巨大
由于字典使用了散列表,而散列表必须是稀疏的,这导致它在空间上的效率低下
如果需要存放数量巨大的记录,那么元组或者具名元组是更好的选择; 用元组取代字典可以节省空间的原因有两个:其一是避免了散列表所耗费的空间;其二是无需把记录中字段的名字在每个元素里都存一遍
在用户自定义的类型中, __slots__属性可以改变实例属性的存储方式,由dict变成tuple
3.键查询很快
dict的实现是典型的空间换时间;字典类型有着巨大的空间开销,但是它们提供了无视数据量大小的快速访问--只要字典能被装在内存里
4.键的次序取决于添加顺序
5. 往字典里添加新键可能会改变已有键的顺序
如果在迭代一个字典的所有键的过程中,同时对字典进行修改,那么这个循环很有可能会跳过一些键,甚至是跳过那些字典中已有的键
不要对字典同事进行迭代和修改,如果想扫描并且修改一个字典,最好分成两步来,首先对字典进行迭代,以得出需要添加的内容,然后把这些内容放到一个新字典里;迭代结束后再对原有字典进行更新
(原因:发生扩容,更大的散列表,新散列表中字典键的次序变化)
8.3 set的实现及其导致的结果
集合里的元素必须是可散列的
集合很消耗内存
可以很高效地判断元素是否存在某个集合
元素的次序取决于被添加到集合里的次序
往集合里添加元素,可能会改变集合里已有元素的次序
**在set加入到python前,把字典加上无意义的值当作集合来使用
posted on 2018-09-17 09:55 cherryjing0629 阅读(180) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号