CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器.
1.CMS堆内存布局
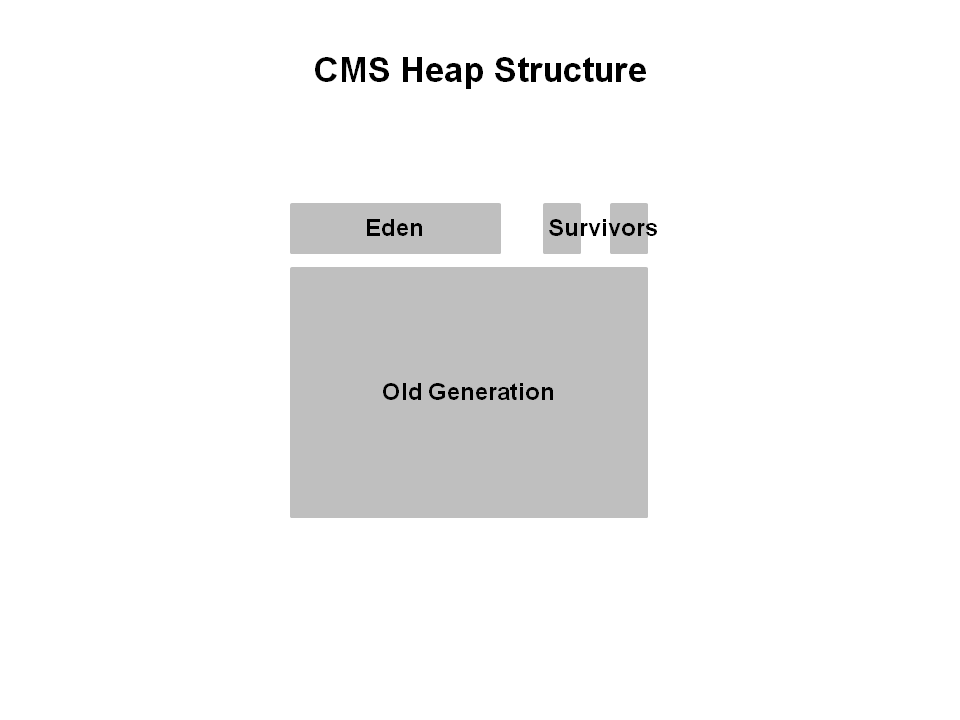
新生代分为Eden和两个survivor区;老年代是一个连续区域。
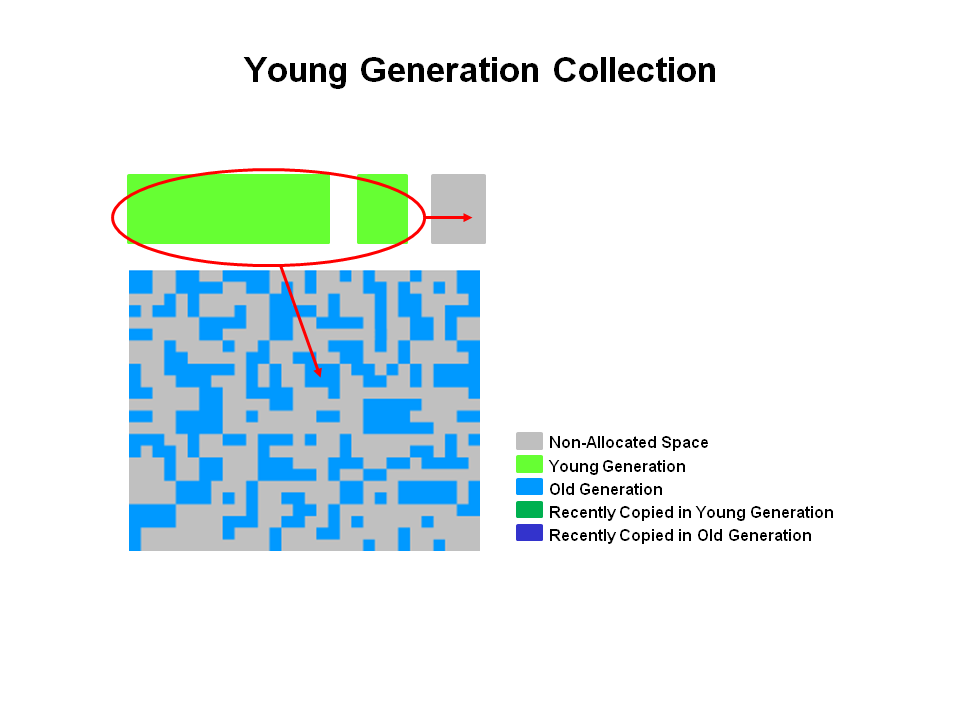
2. 新生代的GC
这是stop the world的过程。但是因为新生代中一般存活的对象很少,所以停顿时间不明显。
1)GC前
新生代中存活的对象会从Eden和survivor区拷贝到另外一个survivor区,超过一定年龄的存活对象,会被送到老年代。
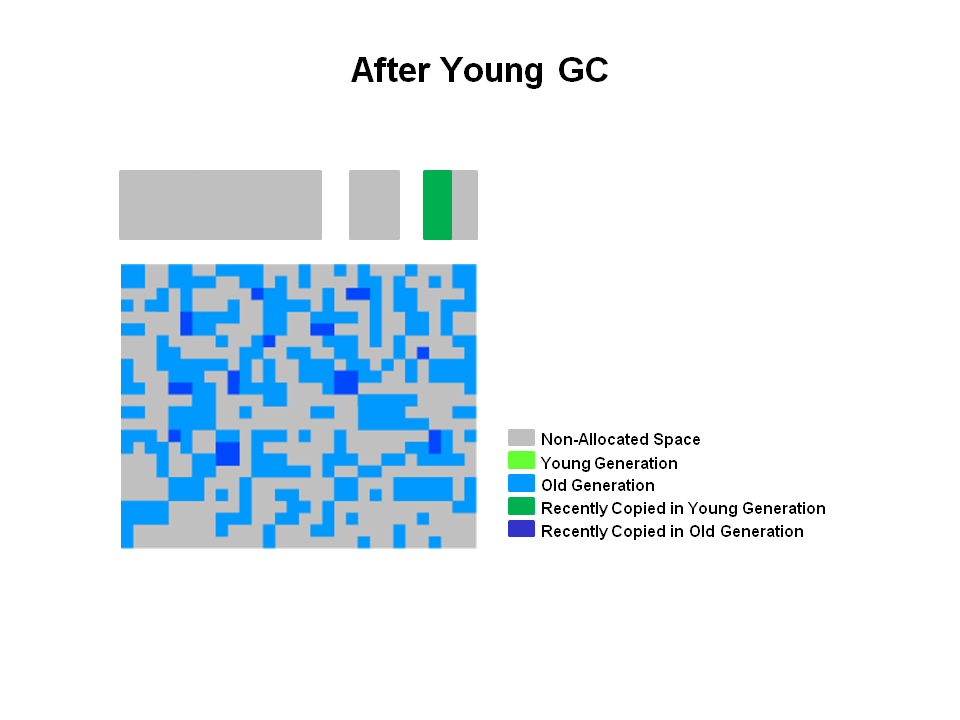
2)GC后
超过一定年龄的存活对象晋升到了老年代(深蓝色);其他的存活对象拷贝到了当时空闲的survivor(to survivor)区;Eden区和另外一个survivor(from survivor)区上的对象清空了。在下一次GC中,这两个survivor区的角色互换。
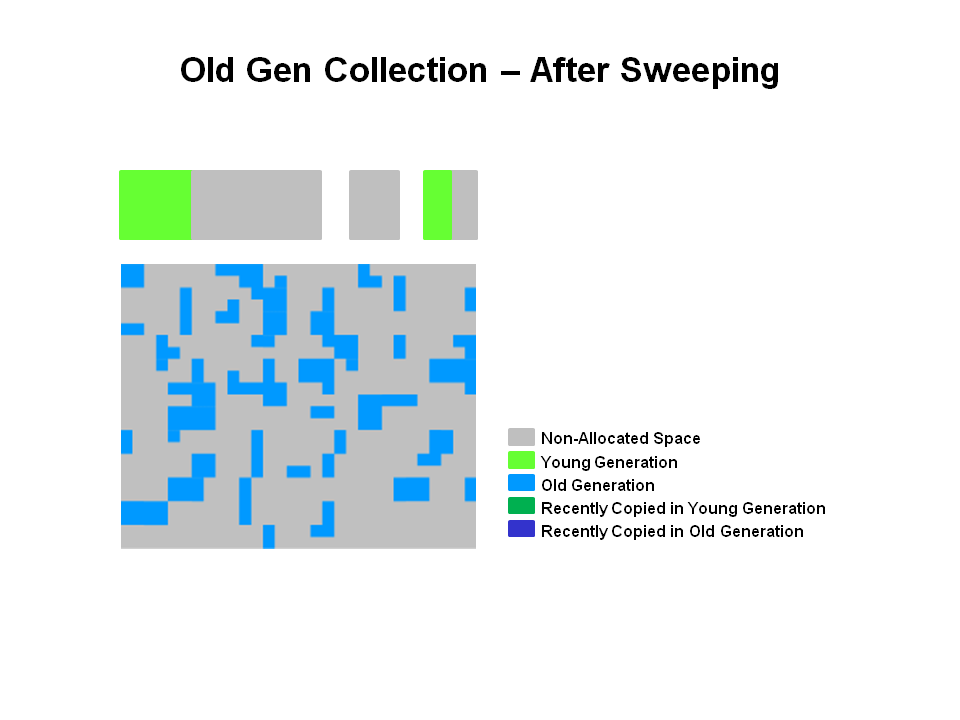
3.老年代的GC
当老年代的内存使用率达到一定的阈值后,就会触发老年代的GC.
它整个过程分为四个步骤,包括:
初始标记(CMS initial mark)-- (Stop the World )
并发标记(CMS concurrent mark)
重新标记(CMS remark)-- (Stop the World )
并发清除(CMS concurrent sweep)
步骤1和步骤3是stop the world的操作,但是因为这两个步骤,时间占比小,所以对停顿时间影响不大;它两个时间占比较大的步骤,步骤2和步骤4,可以和应用程序并发,这就是为啥它能达到比较小的停顿时间的原因。但是CMS采用了标记-清除算法,不会移动存活对象,不可避免的,会产生内存碎片。
1) GC前
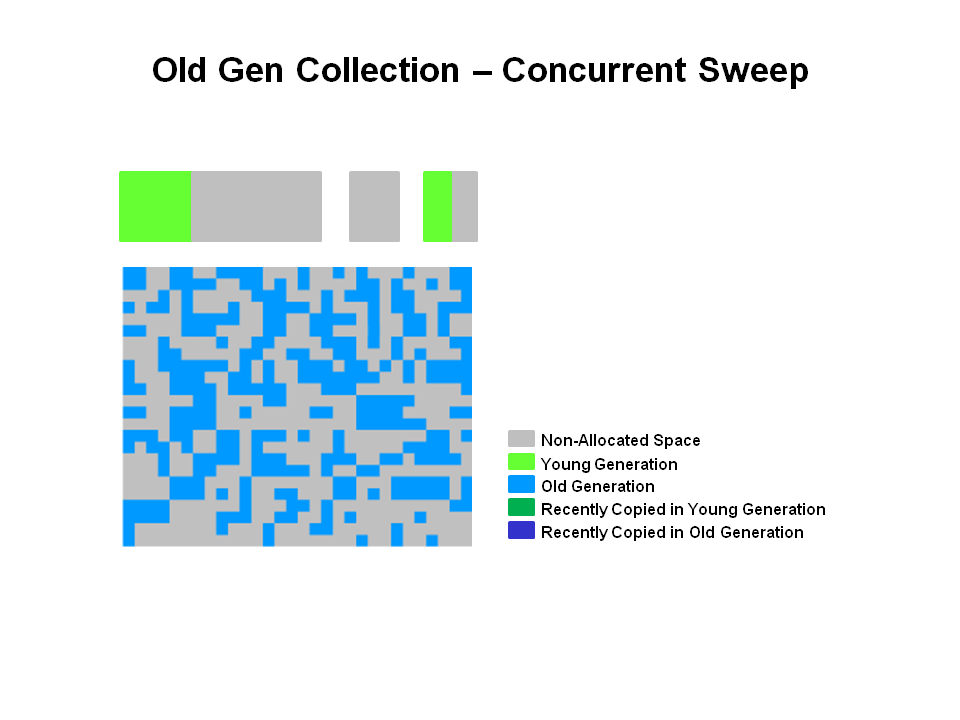
2) GC后
没有在步骤1-3中被标记的对象(垃圾)被直接回收了,并没有发生存活对象的移动。
3.CMS垃圾收集器的缺点:
1)内存碎片:CMS是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往会出现老年代还有很多剩余空间,但就是无法找到足够大的连续空间来分配当前对象,而不得不提前触发一次Full GC的情况;所以为了防止Full GC, CMS会进行碎片整理,这个过程由于需要移动活的对象,所以没办法并发(在ZGC后,才支持这个过程的并发),这个过程解决了碎片,但是导致停顿时间会变长
2)CMS无法处理较大的堆内存:一般只适用于5G或者左右的,现代的服务器,有些内存很高,甚至到了百G或者更高,这种情况下,需要采用G1或者ZGC(G1或者ZGC引入了Region的概念,化整为零的思想,具有管理大内存的能力)
3)CMS会影响吞吐率(这个可以通过增加(牺牲)CPU来改善),也会产生浮动垃圾(这个可以通过增加内存来减少影响),所以这两个问题,在目前硬件性能越来越强大的前提下,会显得相对不是太重要了
参考文档:
https://www.oracle.com/webfolder/technetwork/tutorials/obe/java/G1GettingStarted/index.html
posted on 2020-12-30 16:14 cherryjing0629 阅读(253) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号