


hdfs: 数据流(二)
大部分的HDFS程序对文件操作需要的是一次写多次读取的操作模式。
一个文件一旦创建、写入、关闭之后就不需要修改了。这个假定简单化了数据一致的问题和并使高吞吐量的数据访问变得可能。
1. 读文件
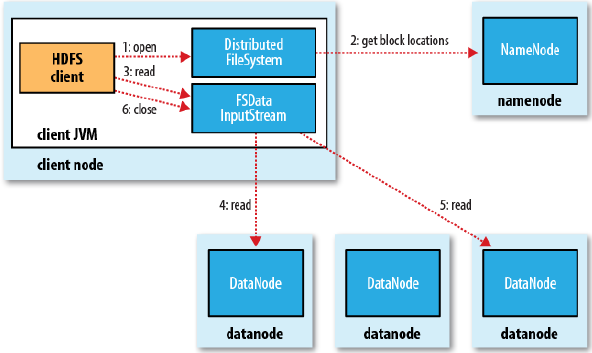
从上图可以看出,客户端读取数据时,
首先从namenode获取如下信息(这些元数据信息是在内存中,所以查询速度很快,这个过程对客户端是透明的):
a. 该文件有哪些数据块
b.这些数据块都放在哪里或者说是取哪个节点上的什么数据块
然后,客户端直接从datanode中以文件流的方式读取数据
最后,关闭这个文件流
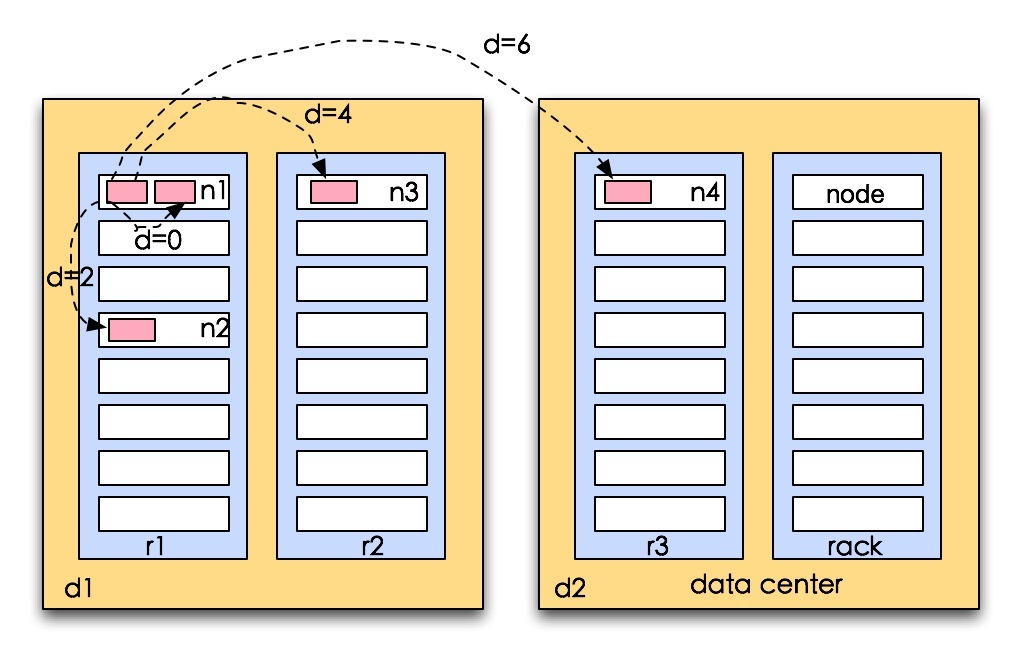
一个问题:因为每个数据块都有三个备份,那么取哪个比较好?
选取读取代价最小的节点,首先会在同一个节点中选取(如果客户端也是datanode时),其次在同一个机架上的datanode中选取,最后再同一个机房中选取
hadoop会根据网络拓扑给每一个冗余数据块打分,原则就是考虑是否在同一个节点上,是否在相同的机架上,是否在同一个机房(目前hadoop不能跨机房部署)
2. 写文件
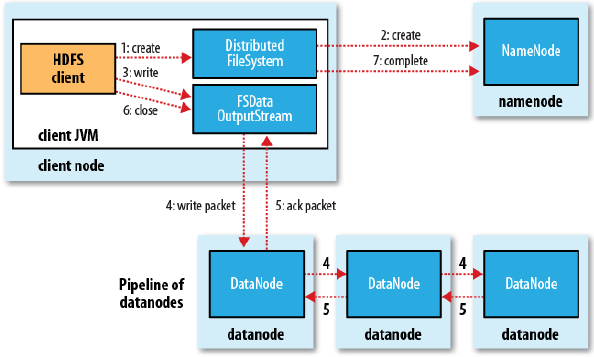
首先,客户端通知namenode:我要写文件了,确认客户端权限和没有相同的文件后,namenode创建一个新的文件记录
然后,将文件分成一个一个的数据块(默认大小是64M),通过文件流的方式往datanode中写数据,写数据时注意是会写冗余数据,冗余数据块的个数默认是3个
最后,只有冗余数据块全部写完,datanode再向客户端发出确认,然后客户端向namenode发出结束消息,并将文件的块信息存储在namenode中
一个问题:如何选datanode用来存储冗余数据块
这是一个权衡的问题:备份的可靠性,网络IO的代价,其实如果都存在不同的机房,这样的可靠性最高,但是网络IO的代价就会很高,因为跨机房的网络IO代价很大,如果都存储在一个节点上,则不需要网络IO,但是数据可靠性就会打折扣
所以hadoop默认的布局策略是:第一个随机在机房中选择一个负载较小的节点,然后在不同的机架上(例如选择了机架A)选择一个节点,再在相同的机架上随机选择一个节点(还是在机架A上)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号