编程习惯
- 1. 在使用多重宏嵌套定义的时候,要在#endif的后面写上注释,便于区分嵌套的关系
#ifdef RTMP_MAC_PCI
2.使用嵌套宏定义的时候,自己的习惯,只使用这一种嵌套定义的方式。pDrvOps->RTMPHandleInterrupt = RTMPHandleInterrupt;
#endif // RTMP_MAC_PCI //
当编译器遇到#warning和#error这两个时,会分别产生一个警告和错误
遇到warning的指令时,会给用户显示#warning指令后面的文本,之后编译继续。
遇到error的质量时,会给用户显示#error指令后面的文本,之后退出编译
#warning
#if defined(A)
#elif defined(B) || defined(C)
#else
#error "You must specify the Board Version!!\n"
#endif
#if DEBUG && RELEASE #error "You've defined DEBUG and RELEASE simultaneously! " #endif
以上的宏定义,如果同时定义的DEBUG和RELEASE的话,那就在编译过程中就报错。
利用编译器的预编译检查作用来控制多版本的编译使用说明。
3.在原有代码的基础上,进行自己的修改,需要加上自己的修改时间以及其他必要的信息。如果与其他内容相重叠,则用#if 0注释掉原有的代码,千万不能删除掉原有的代码
/*start modified by hu hao at 2013-10-28*/
//简要的修改说明
自己修改的内容
/*end modified by hu hao at 2013-10-28*/
4.用git或者svn管理自己的代码。
用git来建立本地仓库和远程git的repos中心仓库,操作方法如下:
在本地新建一个目录,git_test,然后执行 git init。
在其他地方新建一个git的repos中心仓库目录,然后执行 git clone --bare git_test目录所在的位置,就建立好的自己的一个git的repos中心目录。
后面,可以在git_test里面做相应的修改,然后git push就可以了。
git clone 指定自定义远程库的路径就可以下载保存在库中的资料的。
5.多个文件的调试信息,用一个统一的控制宏来控制
6. 类似与这样的宏定义,如果不用其中一条,则必须要完成去掉,不能只是注释掉,要全部去掉。
#define INIT_DISK_SPINDOWN(arg) \
do{ \
arg.vs_disk_spin_lock = SPIN_LOCK_UNLOCKED;\
arg.vs_timer_cnt = 0;\
arg.vs_disk_spindown_flag = 0;\
arg.vs_usb_suspend_flag = VS_USB_SUSPEDN_DISABLE; \arg.vs_disk_spindown_flag_last_timer = 0; \
arg.vs_sd_spindown_flag = 0;\
arg.vs_sd_rw_cnt = 0;\
}while(0)
7.内核打印提示采用如下方式,更加清晰,便于找错。
printk(KERN_INFO "[%s,%d] prepars ssd, 0x%x\n", __FUNCTION__, __LINE__, vs_get_usb_suspend_state()); \
printk(KERN_INFO "[file:%s func:%s line:%d] e = 0x%x.\n", __FILE__, __FUNCTION__, __LINE__, status);
8.以后,在自己开发的模块中,一定要有可以动态打开调试信息,动态使能模块和动态禁止模块的三项功能。对于每一个自己实现的内核模块来说,要有一个proc文件,读取它时,可以显示自己模块里面的相应的必要信息。往里面写入时,就是动态的执行模块的控制命令的过程。这样,便于测试部门的使用和自己的开发。正式发版时,是关闭debug和开启模块功能的。
9.使用vi+ctag来快速浏览源码
ctags -R // 递归创建
l 用#define定义的宏
l 枚举型变量的值
l 函数的定义、原型和声明
l 名字空间(namespace)
l 类型定义(typedefs)
l 变量(包括定义和声明)
l 类(class)、结构(struct)、枚举类型(enum)和联合(union)
l 类、结构和联合中成员变量或函数
1.使用 vi -t foo_bar //将打开foo_bar(变量或者函数或者其他)
2.在vi的命令行中:ta foo_bar
3.光标移到需要定位的变量名上,Ctrl+](右括号)查找,Ctrl+o退回到原来的地方 原来这个功能好强啊
当前在第11个标签处。
Ctrl+T回到上一个标签处,
:tfirst 到第一个匹配
:[count]tprevious 向前 [count] 个匹配
:[count]tnext 向后 [count] 个匹配
:tlast 到最后一个匹配
10.驱动开发头文件中,要有自己定义的调试信息输出,借鉴MTK源码驱动里面的实现,如下:
//#define DEBUG_INIT_MODE //开启驱动中,输出模块功能的默认输出内容
//#define SPDIF_DEBUG_PRN //开启MSG调试信息输出
#ifdef SPDIF_DEBUG_PRN
#define MSG(fmt, args...) printk("SPDIF: " fmt, ## args) //指定调试信息输出模块名
#else
#define MSG(fmt, args...) { }
#endif
在调试写入写出寄存器时,可以如下:
#ifdef SPDIF_DEBUG_PRN
#define spdif_outw(address, value)
do{printk("0x%08X = 0x%08X\n",(u32)address,(u32)value);*((volatile uint32_t *)(address)) = cpu_to_le32(value);}while(0) //写入寄存器的值
#else
#define spdif_outw(address, value) *((volatile uint32_t *)(address)) = cpu_to_le32(value)
#endif
#define spdif_inw(address) le32_to_cpu(*(volatile u32 *)(address)) //读出寄存器的值
对于一个功能模块,要定义全部的控制寄存器以及每一个在datasheet中起作用的控制位的名称
例如:
/* Register Map Detail - SPDIF*/
#define IEC_CTRL (RALINK_SPDIF_BASE+0x0000)
#define IEC_BUF0_BS_SBLK (RALINK_SPDIF_BASE+0x0004)
/* IEC_CTRL bit field */
#define RAW_EN 31
#define RAW_EN_OPT 30
提供给上层的ioctl的命令定义以及使用说明,以及在驱动文件中使用到的函数的声明。
11.在编译Uboot和kernel时,当采用了新的.config配置文件时,一定要执行make menucofnig,重新读取.congfig配置文件,用来生成新的autoconf.h的文件,如果更改了其他配置,在生成镜像后,需要拷贝其他的config配置文件成为.config的话,一定要执行make menuconfig来重新生成autoconf.h配置文件
12.如果在编译连接时出现错误,不要心慌,不要心急,从最简单的入手,一个一个的添加编译,人工手动的加入一些编译错误,查看该文件是否被编译进去了,是否调用了正确的值。
13.
#pragma message 。 它能够在编译信息输出窗口中输出相应的信息,这对于源代码信息的控制是非常重要的。其使用方法为:
#pragma message(“消息文本”)
#ifdef CONFIG_TEXT
#error "this error will block the compilering process.."
#endif
当遇到一些连接的问题时,本来自己添加的头文件,想引用结果还是没有找到,可以在
![clipboard[1]](http://images0.cnblogs.com/blog/350213/201410/180546593104019.png "clipboard[1]")
解决问题的思路:common/vs_cfg.c里面调用drivers/i2c_drv.c里面的函数,出现错误。
1.在common目录下新建一个测试文件,hello.c hello.h,然后再vs_cfg.c里面调用hello.c里面的函数,编译通过。
2. 将i2c_drv.c里面的函数一个一个拷贝到hello.c里面去,在vs_cfg.c里面调用这里的函数,看有没有问题,如果没问题,继续下面的。
3. 在对于的Makefile里面,查看这两者的编译顺序
小技巧:主动写一些错误的代码,利用编译器的查错功能来检测,这部分代码是否被编译进去了。
14:

15、

16. 内核出错提示信息相关函数.
rtc_class = class_create(THIS_MODULE, "rtc");
if (IS_ERR(rtc_class)) {
printk(KERN_ERR "%s: couldn't create class\n", __FILE__);
return PTR_ERR(rtc_class);
}
对于内核中,返回值为指针数值的情况,有三种情况,有效指针,无效指针(非空),NULL指针。
内核函数返回的正确指针一般是指向页面边界的4K对齐的,也就是ptr&0xfff == 0,这样ptr的值,不可能落在0xffff_f000(-1000的补码)~0xffff_ffff之间了。用(unsigned long )ptr > (unsigned long)-1000L就可以来判断了。
内核在include/linux/errno.h中定义了一些错误返回码的值,实际程序出错时,返回加上一个负号。
#define ENOLCK 77
#define ENOSYS 78
#define ENOMSG 80 ...void perror(const char *s)会先打印出s所指示的字符串,然后将上一个函数的错误信息输出到标准错误输出(stderr),
在库函数中有个error变量,每个error值对应着以字符串表示的错误类型,
当你调用"某些"函数出错时,该函数已经重新设置了error的值。perror函数只是将你输入的一些信息和现在的error所对应的错误一起输出
例子:#include <stdio.h>
int main(void)
{ FILE *fp ;
fp = fopen( "/root/noexitfile", "r+" );
if ( NULL == fp )
{
perror("/root/noexitfile");
}
return 0;
}
输出结果:/root/noexitfile: No such file or directory
使用fprintf
int fprintf(FILE *restrict fp, const char *restrict format, ...);
所谓流,通常是指程序输入或输出的一个连续的字节序列,设备(例如鼠标、键 盘、磁盘、屏幕、调制解调器和打印机)的输入和输出都是用流来处理的,在C语言中,所有的流均以文件的形式出现——不一定是物理磁盘文件,还可以是对应于某个输入/输出源的逻辑文件
17.drivers/char/vs_pio.c:725: error: dereferencing pointer to incomplete type
试图访问该pointer指向的变量,却发现该变量是一个不完整的类型,多出错于访问结构体联合体的成员
#include <linux/mmc/host.h>
...
extern struct mmc_host *g_mmc_host_p; //这个指针的结构体定义在 mmc/host.h里面,在vs_pio.c里面引用。
if( (g_mmc_host_p != NULL) && (g_mmc_host_p->card != NULL)){ //在访问这个指针对指向的结构体的成员时,报错。
extern void mmc_sd_unmount(void);
mmc_sd_unmount();
sd_printk("SD card success unmount!\n");
}else{
//sd_printk("SD card success mount!\n");
}
解决方法:
1. 先试图找一个那个结构体的定义文件是否能找到,用grep "struct xxx" /usr/include -R来递归寻找或者使用vi -t mmc_host来寻找,找到后再include这个头文件就可以。标准头文件用include 来包含就可以,非标准头文件用相对路径来包含或者用绝对路径,编译时-I/usr/local/xxx/include来包含
2.如果include后仍然出错,仔细查看该头文件,看是否被编译宏给包含了。如果确实包含了,在编译时,加上-D_USE_BSD来包含。
18.出现问题时,先要准确描述问题,就这几天遇到的问题做一个总结。
问题描述:
SD卡读写数据时,插拔SD卡,不能卸载完全,proc/partitions下面还有残留的信息。
在代码里面寻找SD卡拔出时的处理流程...在每一个关键的路径下面加上打印调试信息,确定问题发生链,打开所有的log信息,复现出bug。
bug发生时:在本该进入的路径,确没有进入的情况,即可定位为出现问题的原因。
解决方法:在执行拔出动作时,缩短执行函数的时间,
从黄工给出的解决思路来看,1.尝试着插拔时,禁止中断。--->尝试失败
2. 注释掉自己增加的一些功能--->没有效果
3.进入中断拔出时,上次有卡,这次没卡,那就重新执行一次唤醒一次拔出的流程。上一次有卡,这一次没有卡,则执行如下操作。
![clipboard[2]](http://images0.cnblogs.com/blog/350213/201410/180547039663432.png "clipboard[2]")
19.C++中调用C函数代码
![clipboard[3]](http://images0.cnblogs.com/blog/350213/201410/180547048573058.png "clipboard[3]")
统一的解决方法:
__cplusplus是c++编译器内置的标准宏定义,让c代码既可以通过c编译器的编译,又可以在c++编译器中以c的方式进行编译(使用条件编译),代码如下:
- #ifdef __cplusplus
- extern "C" {
- #endif
- // 这里面放函数的声明 或者 函数的定义
- int func(int a, int b)
- {
- return a + b;
- }
- int func(const char* s)
- {
- return strlen(s);
- }
- #ifdef __cplusplus
- }
- #endif
20. 当测试与底层硬件有交互的程序时,尽量先手动设置硬件那边的返回值,前期在软件上面测试,等待可以通过任何硬件的返回值(有效值和无效值)后,再和硬件联合调试。
21:C++的命名空间
C++的命名空间用于控制全局变量的作用域,并且可以指定引用的命名空间。
1.
定义一个名称为hao的命名空间
namespace hao{
int a = 9;
}
2. 使用这个命名空间
只使用这个变量 hao::a
全部使用 using namespace hao;
运算符的优先级问题、多线程编程中各个线程的交互、强制类型转换
22.构造函数和析构函数
C++编译器会为每个类默认生成四个辅助函数,构造函数,拷贝构造函数,析构函数和赋值操作符,并且,编译器只在需要的时候生成默认构造函数。
1.默认的构造函数为无参数,无返回值,函数体为空。定义类的方法为:list a 或者 list a = list()
兼容那些没有定义构造函数的类的定义。
2.默认的拷贝构造函数,参数为自己类的引用的构造函数。如list (const list& l).功能为进行简单的成员变量的值的复制,只在list b = p。p为已经定义的对象(已经初始化),b为新定义的对象,要求b拥有和p相同的成员变量时才会被调用。可以自己定义拷贝构造函数来实现自己要想的功能。
无参数的构造函数,有参数的构造函数,拷贝构造函数之间的关系是重载的关系,使用方式如下:
list a list a(5) list b = a或者 list b(a)
自定义的拷贝构造函数不仅会覆盖默认的拷贝构造函数,也会覆盖默认的构造函数
3.默认的析构函数,在对象撤销的时候,对象对自动调用一个析构函数,无参数也无返回值。
~list()
析构函数的调用顺序是与构造函数的调用顺序完全相反的。每一个对象都有构造函数和析构函数。析构函数则需要程序员自己手写
![clipboard[4]](http://images0.cnblogs.com/blog/350213/201410/180547057635914.png "clipboard[4]")
4.静态成员变量和静态成员函数
为了在类的多个对象之间共享变量以及简单的通知,提出了静态成员变量和静态成员函数的概念。
静态成员属于整个类所有,不需要依赖任何对象。可以通过类名直接访问public的静态成员,也可以通过对象名访问public的静态成员
静态成员函数可以直接访问静态成员变量或者全局变量。
![clipboard[5]](http://images0.cnblogs.com/blog/350213/201410/180547086385669.png "clipboard[5]")
参考网址:http://blog.csdn.net/mbh_1991/article/details/17377361
第一:在函数参数与类中成员变量重名的时候,使用this指针来访问成员变量。
第二:当你想通过函数返回本对象或者保存本对象的时候,就要使用*this来访问本对象。
实现代码抽象和重用,分析执行一项操作的步骤,提取通用的部分,然后合理利用
GPS学习网址:http://blog.csdn.net/eastmoon502136/article/details/8562934
把自己看过的知识总结成图表来帮助记忆以及加深理解。
千言万语抵不过一张精美绝伦的图,不对自己狠一点,就不知道自己有多优秀。
23.mount --bind
为了测试某个新功能,必须修改某个系统文件,而这个系统文件又是在只读文件系统中,或者是虽然是这个文件是可写的,但是对这个修改没有把握,只想暂时的修改,作为测试,此时 mount --bind指令就非常的有用了。
23.1 替换已经存在的文件内容。
比如要修改只读文件系统中的 /etc/hosts文件,将修改后的文件放到/tmp下,也可以放在硬盘或者U盘中。
mount --bind /tmp/hosts /etc/hosts ;意思是暂时用 /tmp/hosts内的内容代替/etc/hosts里面的内容
此时,/tmp/hosts就和/etc/hosts两个文件的内容是一致的了,两者的修改会自动同步。修改完成后,
使用 umount /etc/hosts 就可以解开绑定了。/etc/hosts内的内容和原先一样。
23.2增加一个不存在的文件内容,比如在/etc目录下 新增一个export文件。
1.先绑定整个/etc/目录,绑定前先复制另一个目录。然后用mount --bind重定向来访问
cp -a /etc/ /tmp/
mount --bind /tmp/etc/ /etc/
对后者的访问重定向到前者来。
操作完成后,要 umount /etc/
2.挂载ramfs到/etc/
mkdir /tmp/etc/
mount -t ramfs none /tmp/etc
将只读模式重新挂载为读写模式。
mount -o remoun,rw /tmp/usbmounts/sda1
变量的类型决定变量的行为(在没有虚函数的前提下),
泛型编程:
不考虑具体数据类型的编程模式,和普通编程的主要区别是类型可以被参数化。
函数模板:template,关键字,用于开始进行泛型编程
typename 用于声明泛型类型
例子:
template <typename T>
void Swap(T&a , T&b){
T t =a;
a = b;
b = t;
}
两种调用方式:
int a=1,int b=4; Swap(a,b) //自动类型推导
float b=3.4,c=9.3 Swap<float>(b,c) //显示类型调用
1.利用addr2line加debug版的内核来准确定位同名函数
编译一个带有调试信息(选中 CONFIG_DEBUG_INFO)的内核镜像vmlinux,执行下述命令:
比如要找 init_IRQ这个同名函数
![clipboard[6]](http://images0.cnblogs.com/blog/350213/201410/180547125139252.png "clipboard[6]")
查找通过函数指针调用的函数调用链条。
24 设计模块构建函数
尽量功能分解,每个函数只完成单一的功能,在设计辅助函数时,将函数分为两种状态,查询和命令。
查询类函数,只用来查询对象的状态,而不改变对象的状态。
查询时,分为基本查询和复合查询。基本查询只查询单一的状态,符合查询可以同时查询多个状态。 比如:window_get_width 返回窗口的宽度,是单一查询
window_get_rect 返回窗口的左上角坐标,宽度和高度,是符合查询。
命令类函数,只修改对象的状态,只返回其操作是否成功的标识,而不返回对象的状态。
25 随时保存,每天提交SVN.
26 对于设计到线程并发的情况,访问共享资源时,需要加锁和解锁。在有效性的条件判断时,如果判断无效,则需要退出,退出时,需要解锁。这样的每个return语句之前都需要解锁的话,容易遗漏,让一个函数实现单入口单出口的函数。有两种常见的做法:
1. 使用goto语句(在Linux内核中大量使用)


2. 使用do{}while(0)语句

27 项目工程文件组织
由于项目性质、规模上存在着差异,不同项目间的文件组织形式差异很大,但文件、目录结构的基本原则应该是一致的:使外部接口与内部实现尽可能的分离,尽可能的表达软件的层次结构。
对于功能模块或者库文件的组织形式:
显而易见,编写功能模块和库的主要目的是为其它模块提供一套完成特定功能的API,这类项目的文件组织结构通常如下图所示:
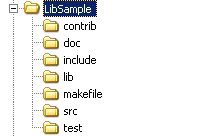

对于应用程序的文件组织来说,应用程序是一个交付给最终用户使用的、可以独立运行并提供完整功能的软件产品,典型的组织如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号