记上报信息格式异常问题的解决
本文记述解决上报信息格式异常问题的全过程。
问题描述
生产环境监控上报无法解析终端信息,通过日志发现是PCN字段前面缺失#号,导致解析程序解析失败。正常情况下,应该展示如下内容:
HD1234#PCN1234
发生错误情况时,记录如下
HD123?PCN1234
问题分析以及解决
通过进一步的后台日志数据分析,发现上述异常情况发生在特定终端,这说明是因为某些终端存在特殊情况,程序中没有考虑到这类特殊情况,从而导致的问题。HD字段后面跟着的是硬盘序列号,PCN字段后面是主机名称,他们中间用 # 字符连接。
下一步是复现问题,复现思路为在本地尝试构造特殊数据,并在复现这类情况,具体做法是在HD~123的后面手动追加异常数据,再和后面正常的 #PCN~1234进行拼接,用程序来检测拼接后是否出现?字符。
由于不知道什么数据会触发,怀疑是混入了无效中文导致的,于是,复习了下中文编码的知识后,
中文编码
ASCII --》 GB2312 --》GBK --》GB18030体系(字符集+编码格式统一)
1980年发布 1995年发布 2000年发布 GB18030-2000 2005年发布 GB18030-2005
6763个汉字和符号 2万多个字符 7万多字符
定长2字节 汉字2字节 变长多字节字符集(1\2\4字节组成)
英文1字节 大部分中文字符只需要2个字节
单字节ASCII
ASCII --> Unicode编码体系(规定字符集)
编码的存储和解析有 UTF8、UTF16等标准。
通过UTF8编码的中文,需要3个字节
如果一个字节最高位是0,说明该字节为ASCII码,查表解析即可,否则认为是多字节编码,需要联合下一个字节一起解析。
utf8编码与ASCII完全兼容,最高位1的数量表示当前字符占用的字节数。
对于汉字来说,没有半角全角的区分;对于符号来说,ASCII和GB2312的符号编码不同,表现不同,GB2312编码的为全角,ASCII编码的为半角。
对于ASCII来说,它是7位编码,共128个字符,分为95个可打印字符和33个不可打印字符,可打印字符用于显示在输出设备,如屏幕或打印纸;不可打印字符又称为控制字符,编码范围在 0x00~0x1F 之间,用于向计算机发出控制指令。
找了几个特例汉字,
GB2312没有,GBK没有,GB18030中独有的字:㙍 0x8230AB33
GB2312没有,GBK有的字: 掆 0x92E2 昞 0x955C 鐯 0xE840 淂 0x9BFA
输入GB2312没有,GBK有的字,能够正常展示;
输入GB2312没有,GBK没有,GB18030中独有的字,显示为 HD~??#PCN,无法显示,但后面的#号没丢。
输入中文的尝试不行,干脆从0~255都试一遍,从1个字节,到2个字节,再到3个字节,都循环一把。这个流程的关键在于如何检测到异常。
判断异常有两个方向,一个是判断是否出现?,另一个是判断是否缺少#。
判断是否出现?, 尝试用 Find 函数查找,几轮全部循环完了都找不到,奇了怪了。
判断是否缺少#,用这个方法可以找到,问题是有太多字符组合发生这种情况了,太多的报错信息反倒是让我怀疑是这个思路不对。在随后的分析中,找一两个错误字符组合一试,果然会出现异常情况,随后多次测试,直到确定发生异常的最佳情况,下面以简化程序为例子来说明:
// 尝试处理无效字符串连接时的问题
void test_invalid_character_string_strcat()
{
char sz2[32] = "123";
const int nBufSize = 256;
char szBuf[nBufSize] = { 0 };
char sz1[32] = { 0x31, 0x13 }; // 测试各种不可打印字符包含在最后时,对后面格式化内容的影响
//char sz1[32] = { 0x31, 0x01, 0x31 }; // 测试各种不可打印字符包含在中间时,对后面格式化内容的影响
#if 1
for (char i = 0;i < 0x1F; i++)
{
sz1[1] = i;
sz1[2] = 0;
memset(szBuf, 0, nBufSize);
_snprintf_s(szBuf, nBufSize, nBufSize - 1, "sz1:%s#sz2:%s", sz1, sz2);
printf("0x%x:%c szBuf:(%s) \t", i, i, szBuf);
if (i % 2 == 1)
{
printf("\n");
fflush(nullptr);
}
}
printf("\n");
#endif
//char sz1[32] = { 0x30, 0x92 }; // 无效字符包含在最后,会吞掉后面的1个符号
//char sz1[32] = { 0x30, 0x91, 0x30 }; // 无效字符包含在中间,不会吞掉后面的1个符号
//char sz1[32] = { 0x30, 0x01 }; // 不可打印字符包含在最后,有些字符会会吞掉后面1个字符内容
//char sz1[32] = { 0x30, 0x06 ,0x30}; // 不可打印字符包含在中间,
_snprintf_s(szBuf, nBufSize, nBufSize - 1, "sz1:%s#sz2:%s", sz1, sz2);
cout << "szBuf:" << szBuf << endl;
string strTest(szBuf);
int nIdx = strTest.find('?');
//assert(nIdx == -1); // 当格式化异常时,界面上展示的是?,但内存中是对应的0x91解决了当异常出现时,无法用 find 来定位
int nFind = '?';
char* pRet = strchr(szBuf, nFind);
//assert(pRet == nullptr);
getchar();
exit(0);
}
经过上述代码实测,得出以下结论:
当待连接字符串中包含无效字符或不可打印字符时,在格式化时会影响后面的内容,具体表现为:
当出现不可打印字符时,详细影响情况见下图:
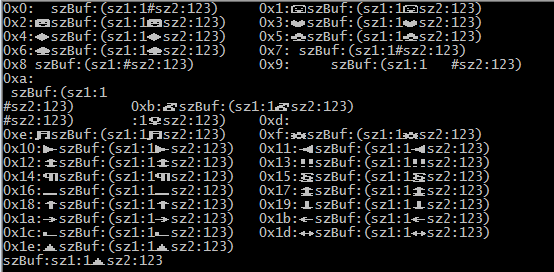
当不可见字符为0x0,0x7,0x8,0x9,0xa等字符时,后面的内容不会被影响,为其他不可打印字符时,在显示时,会吃掉后面的1个字符。
比如 0x11 0x35, 会显示为左三角; 当为 0x11 0x35 0x35, 会显示为左三角5;这说明不可见字符在显示时会隐藏掉后一个字符。
当出现无效字符(字符数值大于127的)时,无效字符在字符串中间,不会影响后续格式化;在字符串最后时,会吞掉后面的一个字符,自身显示为?。
小结
定位到问题原因,解决方案也就出来了。检测待格式化字符串,如果发现最后1位为无效字符,则在它后面追加一个有效字符,可确保不会影响后续格式化内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号