Linux调度机制以及应用层的优化
本文简要介绍Linux调度机制以及如何在应用层进行调度优化。
进程分类
根据进程工作场景,可将进程分为
- 交互时进程:这类进程大部分时间都在等待输入,CPU占用不高,要求响应迅速。例如:编辑器
- 批处理进程:进行大量密集计算以及IO,关心最终输出结果,对响应时间以及资源要求较低
- 实时进程:硬实时,严格要求在指定时间内完成指定任务。软件实时,尽可能快的完成任务。。
上述三类进程,从实时性视角上,分为实时进程和普通进程,具体取决于进程优先级数值。
调度器对这两类进程有不同的调度方式:
- 实时进程,基于优先级队列进行调度,优先级定义从0到99,0表示最高,99最低,共100个优先级。高优先级优于低优先级进程调度,相同优先级下,根据调度策略来调度。
- 普通进程,使用
CFS调度器。在一个调度周期内,所有进程都有机会被调度,区别在于运行时间,与进程的nice相关。
调度策略
调度策略有:
SCHED_FIFO: 同等优先级,先入先出,调度触发时机:- 进程主动调用
sched_yield,让出CPU资源 - 进程被更高优先级进程抢占
- 进程停止或者被杀死
- 进程在等待锁、睡眠(把调度实体从优先级队列中删掉,等待被唤醒后,再添加到优先级队列中)
- 进程主动调用
SCHED_RR: 同等优先级的进程,按时间片轮转,调度时间片为100ms,调度时机:- 包含
SCHED_FIFO的4种情况 - 当前进程耗尽时间片(将调度实体移动到优先级队列尾部)
- 包含
问题:那如果一直存在实时进程,会不会导致普通进程始终获取不到CPU资源?
解答:Linux针对这种情况,提出组调度策略,限制实时进程的总运行时间,可通过以下两个参数进行控制:

在 sched_rt_period_us 时间内,所有实时进程运行时间之和不得超过 sched_rt_runtime_us的时间,如上图所示,在1秒内,所有实时进程最多运行0.95秒,剩下的0.05秒留给普通进程。
针对普通进程,采用CFS调度器,其核心思想是完全公平,调度策略为SCHED_OTHER,新创建的线程,默认都是普通进程。
实践前的准备
linux中,应用层和内核层对优先级的定义不同。
| 优先级区分 | 实时进程 | 普通进程 |
|---|---|---|
| 应用层优先级 | [1,99] 1最低,99最高 | |
| 内核优先级 | [0,99],0最高,99最低 | [100,139],100最高,139最低 |
应用层可通过如下两种方式设置进程优先级:
nice函数设置普通进程优先级,取值范围为-20~19,设置值越大,优先级越低。pthread_setschedparam设置实时进程优先级,设置的值越大,优先级越高。
默认情况下,创建的进程都是普通进程,通过top命令查看进程状态,与优先级相关的字段有PR和NI。
- PR列:给内核调度使用的优先级,如果该域显示为
rt,则表明该进程为实时进程 - NI列:进程的nice值,默认为0,取值范围为[-20,19], 负值意味着更高的优先级
控制接口
多线程在内核看来是轻量级进程,以下都以进程来标识说明。调度机制由调度策略以及调度参数来控制,目前有两套接口可供使用:
-
以
sched_开头的系统调用,例如,sched_setparam、sched_setscheduler,
对进程标识采用__pid_t,使用getpid()接口获取,以应用层进程级别来控制。 -
以
pthread_XX开头的接口,由线程库提供,例如,pthread_setschedparam等,对进程标识采用pthread_t,使用pthread_self接口获取,以应用层线程级别来控制。
以下采用pthread_XX系列接口。
实践
测试思路, 主线程创建两个子线程1和2,每个子线程中循环执行耗时代码,直到主线程通知它们退出,留给子线程的运行时间设置为5秒,测试代码见文末链接。
场景1:两个线程都是默认属性
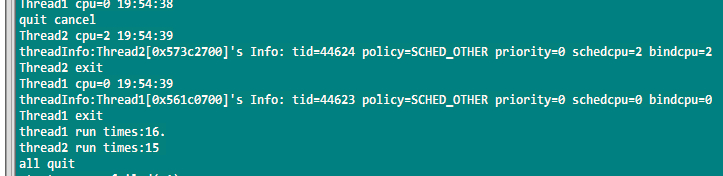
测试结果:两个线程执行次数相差无几,表明线程1和2平均得到了CPU资源。
场景2:通过nice增加线程1优先级,线程2保持不变。
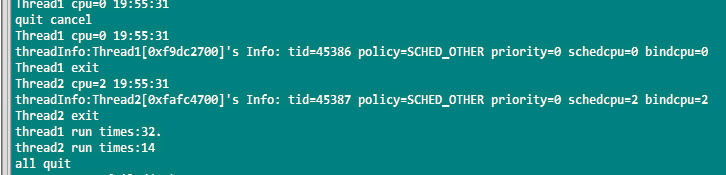
测试结果:增加线程1的优先级,线程1的执行次数多余线程2的执行次数
场景3:通过nice降低线程1优先级,线程2保持不变。

测试结果:降低线程1的优先级,线程1的执行次数少于线程2的执行次数
场景3:设置线程1调度模式为FIFO,线程2为默认属性。
测试结果:线程1和线程2都有机会运行,但线程1运行次数多余2。通过查看运行时的绑定CPU,发现两个线程在运行过程中会切换CPU,如果线程1和线程2绑定在同一个CPU上,FIFO调度策略线程会一直占用CPU,直到它退出。
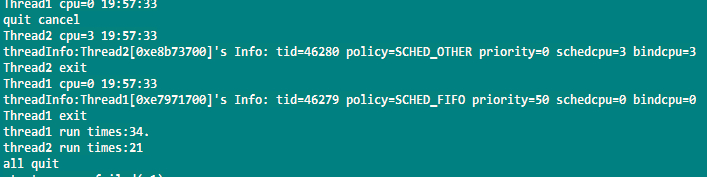
场景4:线程A和线程B绑定在同一个CPU上,线程A为FIFO模式,线程B保持默认。
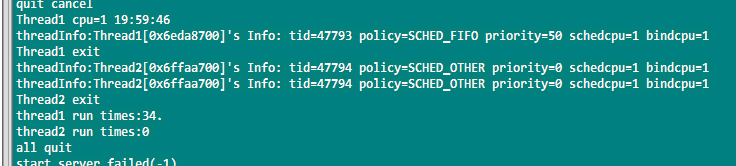
测试结果:绑定在同一个CPU上后,线程A始终占据CPU资源,一直在运行,线程B得不到资源。FIFO这种模式会一直占用CPU,直到进程主动退出,即使有相同FIFO和相同优先级的进程,也不会抢占。
场景5:线程A和线程B绑定在同一个CPU上,线程A为RR模式,线程B也认为RR模式。两种优先级一样。
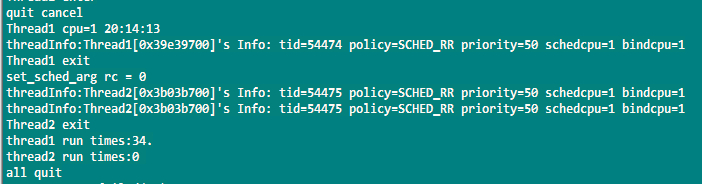
测试结果:先抢占到CPU的线程,始终占有CPU资源。测试结果和RR模式下时间片轮转,相同优先级会均匀调度的结论不一样。不知道什么原因?后来在线程中加入适当延时,主动让出调度机会,得到的结果就符合预期。
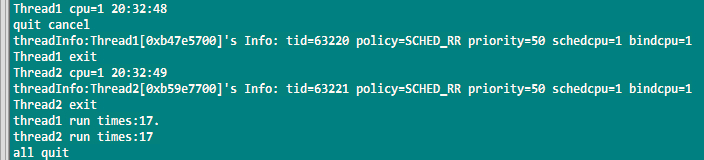
场景6:线程中加入适当延时后的

优先级不同的两个RR进程,高优先级的RR进程1始终占用CPU,直到进程1退出,进程2才获取了1次执行机会。
如果两个线程优先级设置为一致,则平均获得CPU资源,结果如下图:
小结
在多线程程序中,要在应用层提高线程优先级,可通过nice函数提高线程静态优先级,或者采用SCHED_RR调度模式,同时,采用绑定CPU的方式来独占某个核,降低cache失效概率,提高线程运行效率。
参考文档:
- linux进程调度之 FIFO 和 RR 调度策略
- linux内核普通进程CFS调度原理
- linux线程调度策略
- 查看代码运行在哪个CPU
- 测试代码下载链接 ,提取码: dkj3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号