记在Linux上定位后台服务偶发崩溃的问题
问题描述
在最近的后台服务中,新增将某个指令的请求数据落盘保存的功能。在具体实现时,采用成员变量来保存请求消息代理头,在接收响应以及消息管理类释放时进行销毁。测试反馈,该服务偶发崩溃。
问题分析
测试环境上运行的是rel版程序,由于在编译时去掉了调试信息(-g)以及开启O3级别优化,从崩溃dump的堆栈上,只看到程序崩溃的调用栈,函数入参等被优化掉,由于此处没有打日志,只能想其他办法来复现。猜测是重复释放指针导致的崩溃,接下来继续分析。
从rel版本的调用栈上看,只看见最后销毁的函数调用,而在实际代码中,有两处销毁的函数调用入口,为什么在dump中看到的调用栈顺序与实际代码不一致呢?猜测是开启O3优化,将函数内联。
做了以下实验来分析,
void test_dump()
{
int* p = NULL;
*p = 2; // occur dump
}
void test_f2(int b)
{
b += 1;
test_dump();
}
void test_f1(int a)
{
a+=1;
test_f2(a);
}
int main()
{
test_f1(1);
return 0;
}
在Debug以及Rel模式下,触发崩溃,使用gdb来输出堆栈信息分别如下:
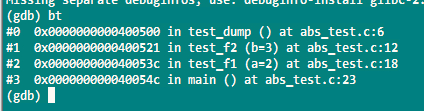

结论:在Rel模式下,O3级别的优化内联了调用函数,如果从崩溃点往上回溯有多个可能入口点,那仅凭dump信息不能确认是哪个入口触发的崩溃。
构造测试环境
通过分析代码,得知要触发可能的多重释放,需要构造一边创建,一边销毁的场景。
- 创建:可通过测试工具,定时高频发送特定指令,触发创建流程
- 销毁:可在定时任务中,进行无效状态上报,触发销毁流程
为了加快崩溃复现速度,创建以及销毁的速度需要合理匹配,如果太快销毁,会导致无法进入创建流程。经过分析尝试,最终
设定测试工具每50毫秒发送一次,后台服务每50ms上报无效状态。
为进一步验证崩溃的想法,在销毁操作等关键路径添加日志,启动Rel版来重现。经过长时间的测试,获得了2次宝贵的崩溃dump以及对应的日志。每次dump要花费2个半小时甚至更多才能复现,说明这个问题是偶发问题,很可能与多线程竞态有关。复现该问题的时间成本有点高,不过,从获得的dump以及日志已足以定位问题。
日志分析
同一后台服务,不同业务模块的日志分布在不同日志文件中,在分析时,需要将各部分日志聚合起来,方便复现全流程。在聚合时,可以按需截取各模块的最后若干行日志,每种日志中包含正常以及异常的日志,将其汇总到单一文件,然后结合代码进行逐行关联分析。
在分析过程中,遇到一些框架方面的疑问,通过询问相关同事得到解答。目前的消息收发框架在接收消息时,先将消息放入线程池的消息队列,通过信号量来唤醒线程,线程从消息队列中获取消息,从消息中取出处理函数进行处理。
在应用层处理不同消息时,可能处理同一个变量时,会有发生竞态。通过对释放指针的分析,正常释放指针指都有一定的规律,当触发崩溃时,释放的指针值与正常的值有明显区别。
通过对业务流程上下文进行仔细分析,提出可能的崩溃点:
- 有没有可能是重复释放
- 有没有可能是释放未初始化指针
- 有没有可能是释放后再次使用。
等等,通过逻辑分析,逐一排除,剩下不能排除的疑问,可以采取去掉无关业务逻辑,抽取可疑核心逻辑,单独进行测试。因为在正常业务流程的下,有些变量处于无效的时间窗口很短,需要特别严格的条件才能触发,因此,抽取可疑核心逻辑,构造不同输入组合,加快测试频率来复现崩溃现场。
经验小结
- 发现有dump文件时,查看dump文件生成时间,将当时的日志以及可执行文件,连同dump文件一并放在独立的文件夹中,便于后续分析。因为当前的日志文件以及可执行文件可能被删除以及更新。
- 每一次问题的解决,都是一次对已有系统的再深入认识,理解。
- 构造复现环境时,要使用Rel版本,且只能通过日志来确认程序流程,而不是断点。
- 在linux上,不能使用嵌套属性的互斥锁,它会破坏设计意图,让潜在的死锁更加难以发现。让错误尽早暴露好过后续找错。
- 大胆假设,小心求证,胜利的曙光终会出现。
参考文章:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号