Python读取文件
==========
本文记录使用Python在读取文件时的一些心得体会。
不能decode bytes
使用open方法读取文件时,经常会遇到这样的问题:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xaa in position 205: illegal multibyte sequence
open方法原型如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
如果encoding未指定,会使用平台默认的编码方式,该方式可通过
import locale
locale.getpreferredencoding(False)
来获得。本人的Windows为cp936,Linux为ANSI_X3.4-1968和UTF-8。
上述问题出现的原因,是因为文件全部或者部分内容的编码方式与读取的编码方式不一致。
注意:以二进制方式读写文件时,encoding参数会被忽略。
解决方案:
方案一:修改数据源的编码方式,使其以期望的格式保存,再以期望的格式打开即可。修改原始编码方式可能会造成文件乱码,慎重使用。
方案二:对于含有中文内容的文件来说,可以用包含更大容量字符数的编码方式来打开。GB2312 < GBK < GB18030
方案二:使用 errors 参数来忽略错误行,有不同的忽略级别:
- ignore:忽略由非法字符触发的编码错误
- strict:默认属性,遇到编码错误时,对外抛出
ValueError异常 - replace:使用"?"来替换非法字符
pandas的 read_csv
使用pandas,从csv格式文件中读取数据,可使用 read_csv 函数,该函数有很多有用的参数,现把常用的列举如下:
- nrows: 读取设定的行数,eg:nrows = 10,只读取前10行
- usecols:只读取指定列。eg:usecols=["name", "age"],只读取"name"和"age"列,在读取大文件时很有用。
- keep_default_na:当为空时,是否使用Nan值来代替。设置False时,表示保留原样。
- 分块读取相关:iterator、chunksize。
- encoding:指定字符集类型
- error_bad_line:当遇到异常行记录时,比如某行逗号较其他行多,导致数据列不匹配,这会触发异常,不会有DataFrame返回。可设置为False,忽略掉这些错误行。如果想知道在解析过程中,这些错误行在那里,可再设置 warn_bad_lines 为True,那么会输出解析错误行的相关信息。
Python中的编码
编码历史发展,从最开始的ASCII编码(单字节编码),到兼容ANSI和常用中文的GB2312编码(双字节编码)、GBK(对GB2313的扩展),在扩展编码中,将ASCII中原有的数字、标点和字符等统统重新编码为两字节长,这就是“全角”字符。原来在ASCII范围内的称为“半角”字符,
但这样针对每种文化各自指定一套,不利于全球交流,于是ISO国际组织针对全球现有的文化、字母和符号,指定统一编码,称为Unicode编码方式(2个字节),它只规定各种字符的二进制定义,但具体使用多少个字节来保存,没有做规定,于是出现各种Unicode传输编码,例如:UTF-8,变长编码方式,使用1~4个字节表示一个符号,根据不同符号长度而变化字节长度。ASCII字符使用一个字节,中文使用三个字节。
UTF-16,统一使用2个字节来传输。
unicode是二进制编码方式,是所有编码之间转换的中介。例如utf-8和gbk之间需要通过unicode编码进行中转,才能相互转换。python提供了encode和decode两个函数来进行编码转换。
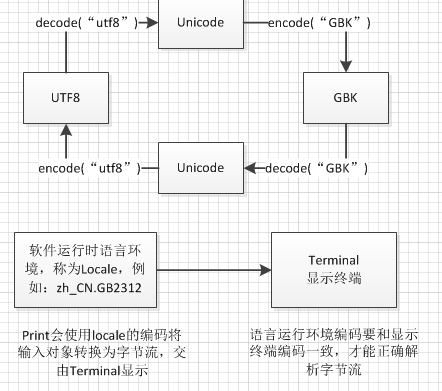
- Python源文件头的编码说明:
#coding:utf-8 #表示Python解释器用什么样的编码去读取该文件,在该文件中,声明str = u"中国"表示str指向由utf8编码的字节流。 - str(),将各种类型转换为str。如果输入是已编码的字符串,则不做改变。如果是未编码的unicode字符串,则会编码再输出。
参考文档:
pandas系列 read_csv 与 to_csv 方法各参数详解(全,中文版)
python中文编码中文乱码问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号