if语句条件判断大集合--------------------------------------python语言学习
准备数据:
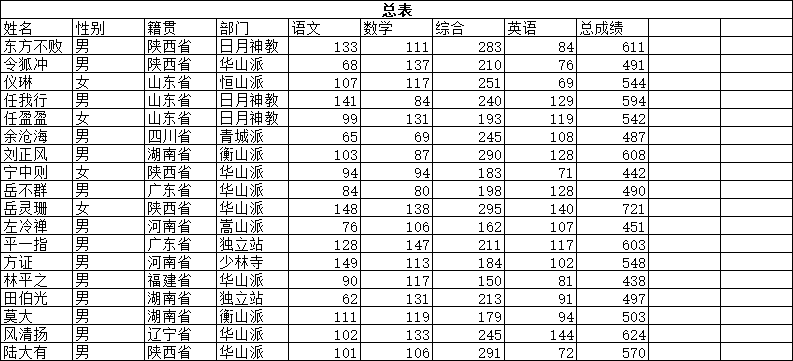
##实现成绩大于等于600为优秀,其他为普通等级
上代码:
import pandas as pd
df = pd.read_excel('C:/Users/Administrator/Desktop/test1.xlsx',header=1)
def score_if(score):
if score >= 600:
a = "优秀"
return a
else:
a = "普通"
return a
df["是否优秀"] = df["总成绩"].apply(lambda x:score_if(x))
#可以选择下面一行,一行代码实现“判断等级”的目的
# df["是否优秀"] = df["总成绩"].apply(lambda x: "优秀" if x >= 600 else "普通")
print(df)
实现效果如下:
注意if语句下面,需要跟return a否则不会出现“优秀”或者“普通”
字样,则会出现“NONE”,空的字符串,字符串为空

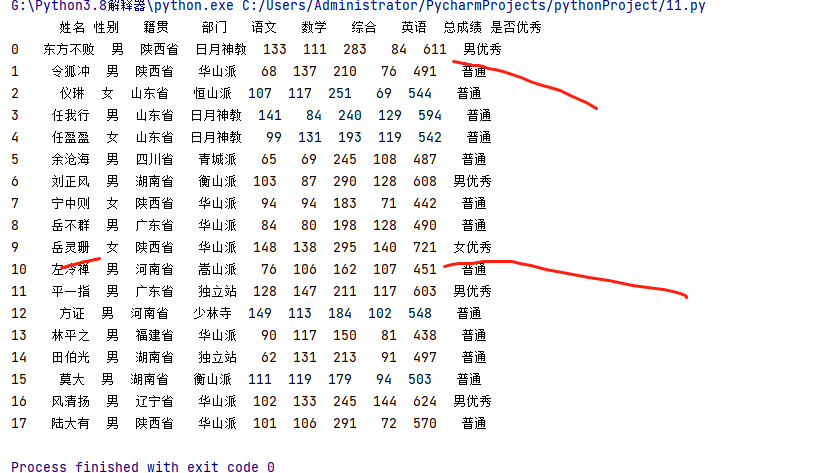
多条件:600及以上为优秀,500及以上为普通,500以下为 一般,不优秀
def score_if(score):
if score >= 600:
a = "优秀"
return a
elif score >= 500:
a = "普通"
return a
else:
a = "不优秀,一般"
return a
df["是否优秀"] = df["总成绩"].apply(lambda x:score_if(x))
##第二种写法:一行代码解决
df["是否优秀"] = df["总成绩"].apply(lambda x: "优秀" if x >= 600 else ("普通" if x >= 500 else "不优秀"))

判断600及以上的学生,在此基础上再判断性别进行分类
上代码:
import pandas as pd
df = pd.read_excel('C:/Users/Administrator/Desktop/test1.xlsx',header=1)
def score_if(score,sex):
if score >= 600 and sex == "男":
a = "男优秀"
return a
elif score >= 600 and sex == "女":
a = "女优秀"
return a
else:
a = "普通"
return a
df["是否优秀"] = df.apply(lambda df:score_if(df['总成绩'],df['性别']),axis=1)
print(df)
##第二种写法
df["是否优秀"] = None
for i in range(len(df)):
df["是否优秀"][i] = score_if(df['总成绩'][i],df['性别'][i])
print(df)
实现效果如下:
判断单科优秀:语文,数学有一科大于等于120
上代码
import pandas as pd
df = pd.read_excel('C:/Users/Administrator/Desktop/test1.xlsx',header=1)
def score_if(chinese,math):
if chinese >= 120 or math >= 120:
a = "单科优秀"
return a
else:
a = "普通"
return a
df["是否优秀"] = df.apply(lambda df:score_if(df['语文'],df['数学']),axis=1)
print(df)
实现效果如下:

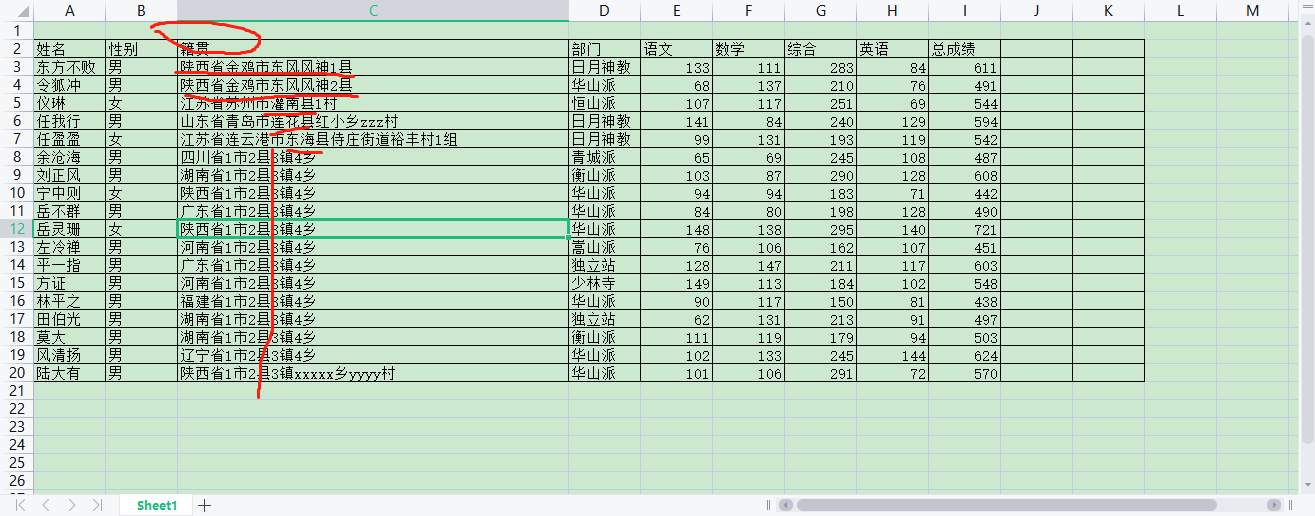
##截取省,市,县区域信息:
上代码:
import pandas as pd
df = pd.read_excel('C:/Users/Administrator/Desktop/test1.xlsx',header=1)
df["省"] = df["籍贯"].apply(lambda x: x[0:x.find("省")+1])
df["市"] = df["籍贯"].apply(lambda x: x[x.find("省")+1:x.find("市")+1])
df["县"] = df["籍贯"].apply(lambda x: x[x.find("市")+1:])
print(df)
实现效果如下:
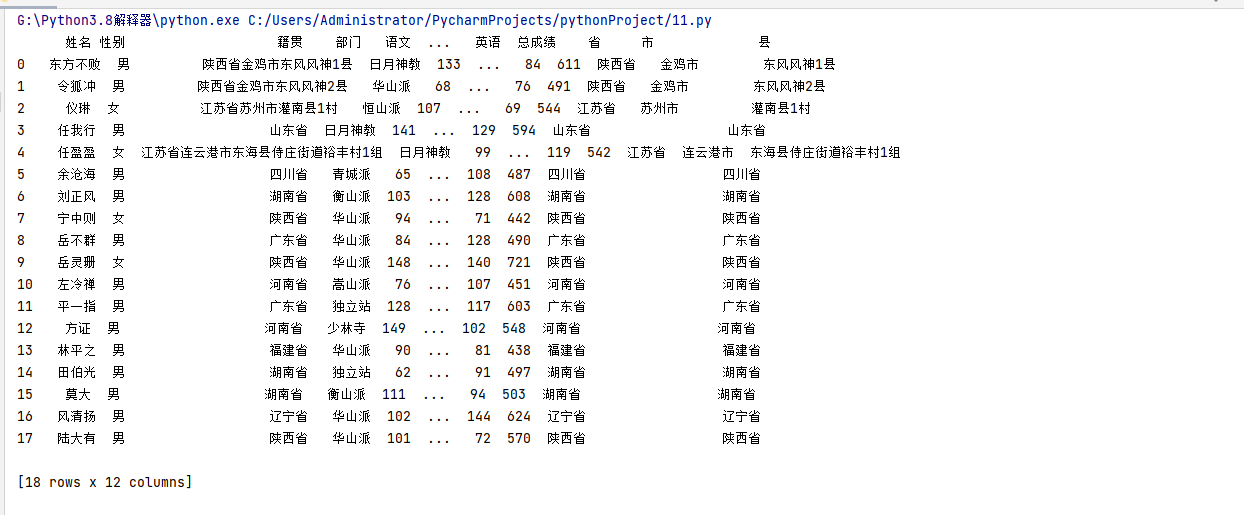
再看个例子:





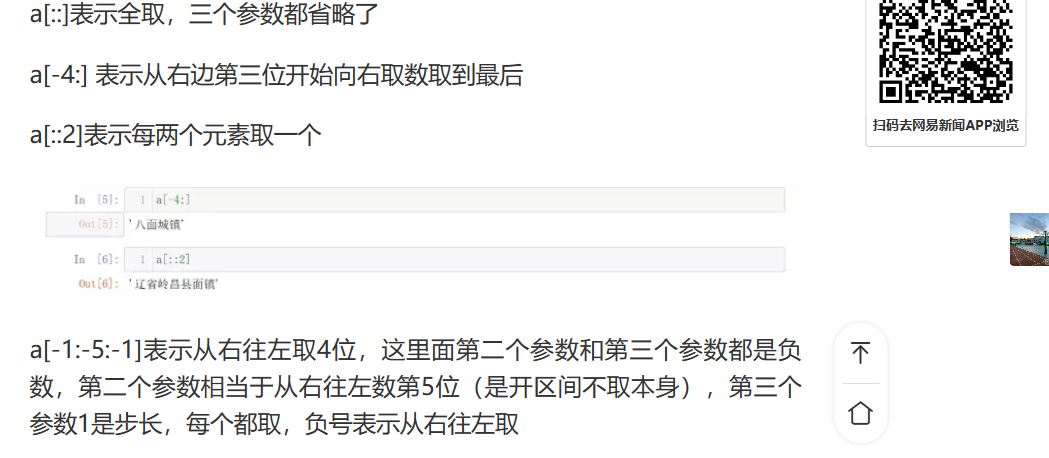

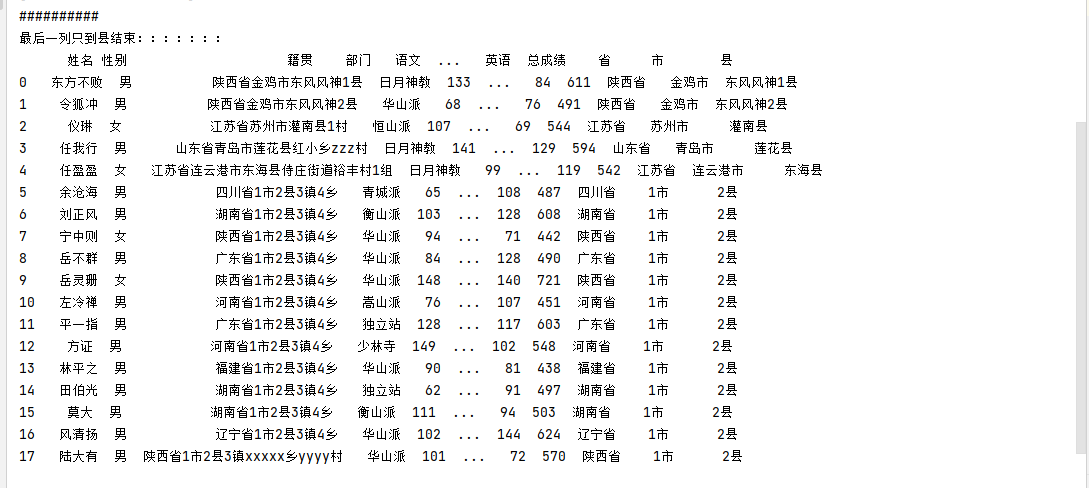
@@@@@@@@@@@精确到县结束:::::::::::::::::
上代码:
import pandas as pd
df = pd.read_excel('C:/Users/Administrator/Desktop/test1.xlsx',header=1)
df["省"] = df["籍贯"].apply(lambda x: x[0:x.find("省")+1])
df["市"] = df["籍贯"].apply(lambda x: x[x.find("省")+1:x.find("市")+1])
######市以后的内容都要,全部都获取
df["县"] = df["籍贯"].apply(lambda x: x[x.find("市")+1:])
print(df)
print("##########")
print("最后一列只到县结束:::::::")
###########只到县结束,获取什么什么县
df["县"] = df["籍贯"].apply(lambda x: x[x.find("市")+1:x.find("县")+1])
print(df)
实现效果如下: