pandas模块------------------------筛选条件loc(多条件选择) iloc(固定选择哪行哪列)
loc
在选择时应用条件。
单条件:选择大于90成绩的学生信息:
import pandas as pd
source = pd.read_excel('C:/Users/Administrator/Desktop/source.xlsx')
print(source)
da = source.loc[(source['成绩'] > 90)]
print(da)
G:\Python3.8解释器\python.exe C:/Users/Administrator/PycharmProjects/pythonProject/first.py
学生姓名 成绩 班级 学校
0 a 80 1班 第5中学
1 b 56 1班 第4中学
2 c 91 3班 第3中学
3 d 100 4班 第2中学
4 e 76 2班 第1中学
5 f 73 2班 第1中学
6 g 66 3班 第1中学
学生姓名 成绩 班级 学校
2 c 91 3班 第3中学
3 d 100 4班 第2中学
Process finished with exit code 0
多条件选择:
import pandas as pd
source = pd.read_excel('C:/Users/Administrator/Desktop/source.xlsx')
da = source.loc[(source['成绩'] > 70)]
print(da)
daa = source.loc[(source['成绩'] > 70) & (source['成绩'] < 80)]
print('====================================')
print('成绩在70到80之间成绩的学生信息如下:')
print(daa)
dab = source.loc[(source['成绩'] > 90) & (source['学校'] == '第2中学')]
print('#####################################')
print('成绩在90分以上成绩的第二中学学生信息如下:')
print(dab)
实现效果如下:
G:\Python3.8解释器\python.exe C:/Users/Administrator/PycharmProjects/pythonProject/first.py
学生姓名 成绩 班级 学校
0 a 80 1班 第5中学
2 c 91 3班 第3中学
3 d 100 4班 第2中学
4 e 76 2班 第1中学
5 f 73 2班 第1中学
====================================
成绩在70到80之间成绩的学生信息如下:
学生姓名 成绩 班级 学校
4 e 76 2班 第1中学
5 f 73 2班 第1中学
#####################################
成绩在90分以上成绩的第二中学学生信息如下:
学生姓名 成绩 班级 学校
3 d 100 4班 第2中学
Process finished with exit code 0
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
准备数据
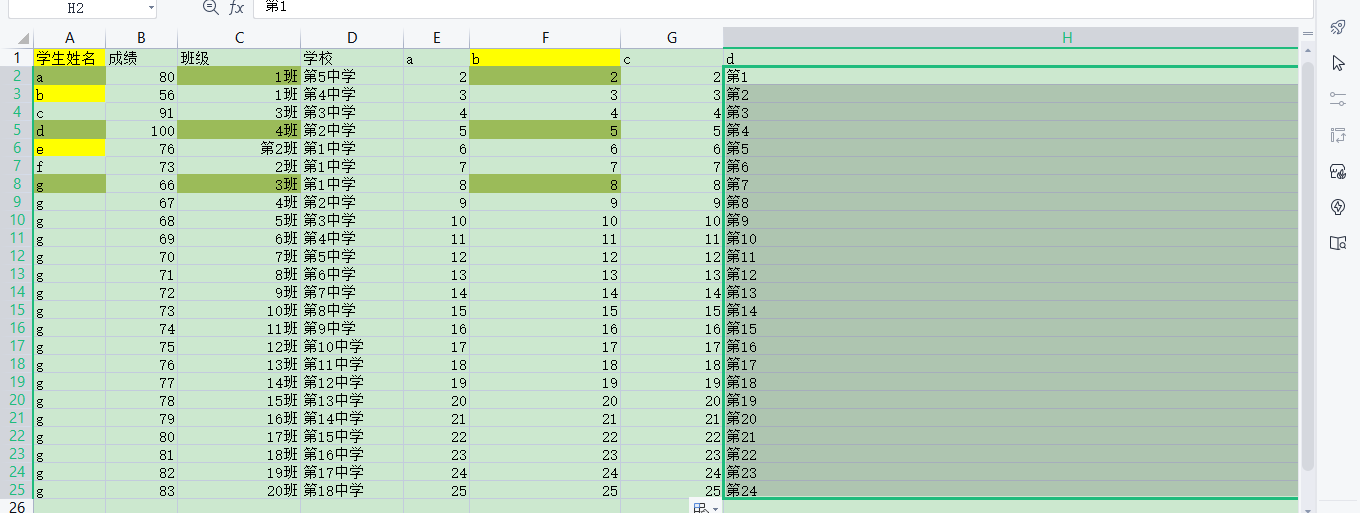
上代码:
import pandas as pd
df = pd.read_excel('C:/Users/Administrator/Desktop/source.xlsx')
print(df.iloc[0:6]) # first 6 rows of dataframe
print('--------------------------------------')

print(df.iloc[:, 0:4]) # first 4 columns of data frame with all rows
print('--------------------------------------')


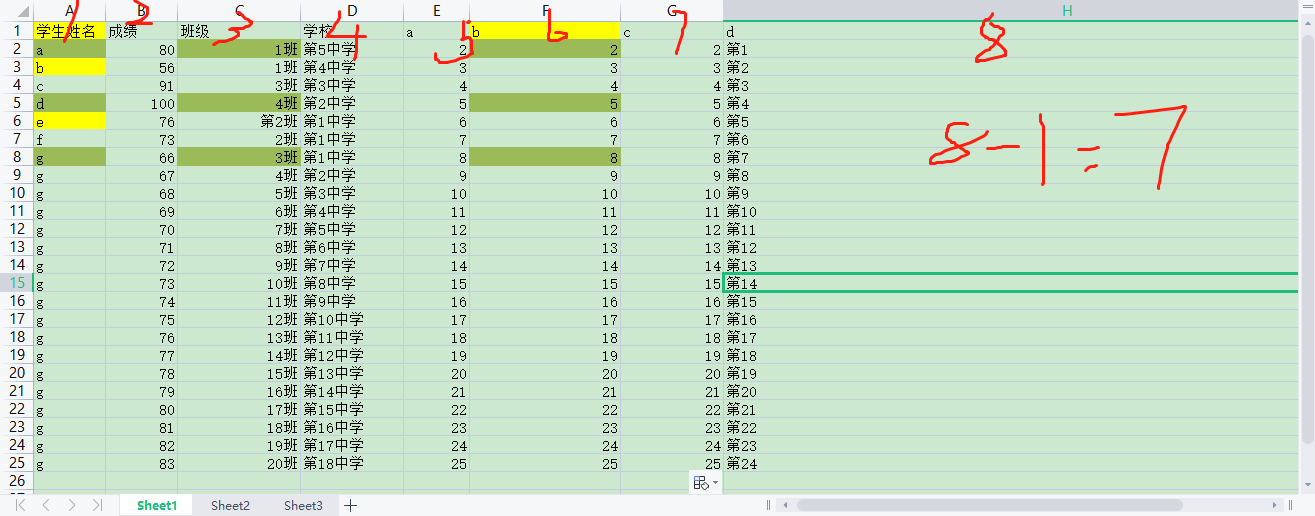
# 选择特定的行和列0,3,6行,2,1,3,0,6列
print(df.iloc[[0, 3, 6], [2,1, 3,0,6]])
print('--------------------------------------')

# first 5 rows and 5th, 6th, 7th columns of data frame
#前5行,第5,6,7列的数据:
print(df.iloc[:5, 5:8])
print('--------------------------------------')

@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
练习:
import pandas as pd
Student_dict = {'姓名':['张三', '李四', '王五', '赵六'],
'性别':['男', '女', '男', '女'],
'年龄':[20, 21, 19, 18],
'Python成绩':[70, 80, 90, 50],
'评价':['良好', '良好', '良好', '良好'],
'地址':['A小区10幢', 'A小区11幢','B小区10幢','C小区11幢']}
# 字典创建DataFrame,字典键变DataFrame的列名
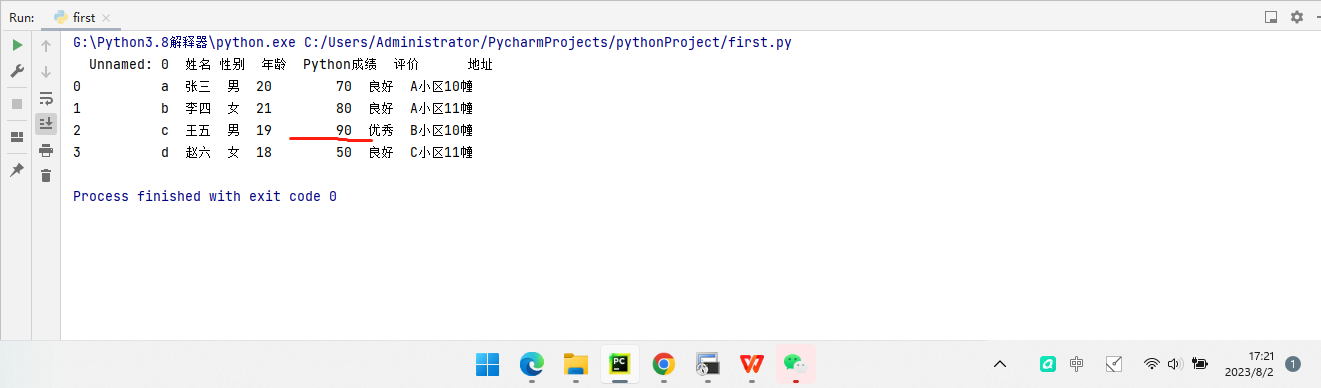
df = pd.DataFrame(data=Student_dict, index=['a','b','c','d'])
print(df)df.to_excel('C:/Users/Administrator/Desktop/test.xlsx')

data = pd.read_excel('C:/Users/Administrator/Desktop/test.xlsx')
print(data)
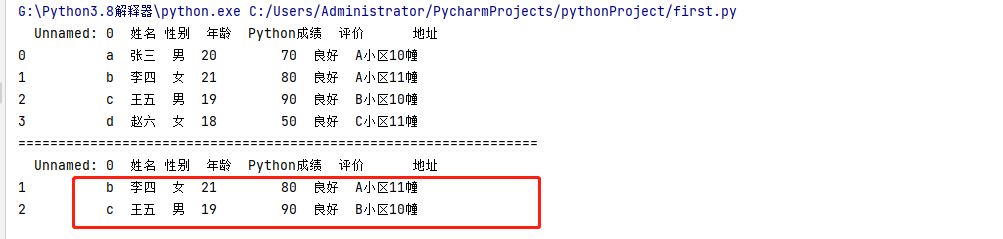
data = data.loc[data['Python成绩'] > 75] # df.loc[]删选Python成绩>75的学生
print('=================================================================')
print(data)
data = data.loc[(data['Python成绩'] > 75) & (data['年龄'] > 20)] # df.loc[]删选Python成绩>75的学生,并且年龄>20的学生

#修改数据:
data = pd.read_excel('C:/Users/Administrator/Desktop/test.xlsx')
data.loc[data['Python成绩'] >= 90, '评价'] = '优秀'
print(data)
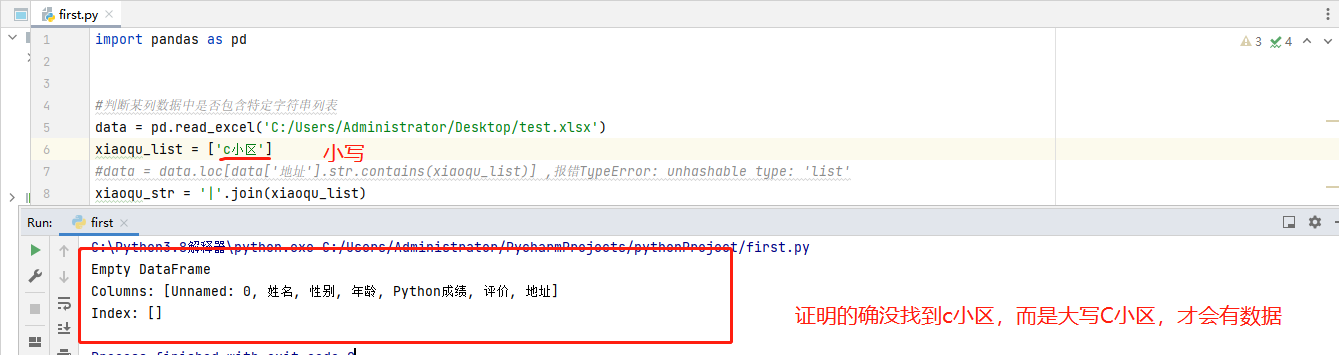
#判断某列数据中是否包含特定字符串列表
data = pd.read_excel('C:/Users/Administrator/Desktop/test.xlsx')
xiaoqu_list = ['A小区', 'B小区']
#data = data.loc[data['地址'].str.contains(xiaoqu_list)] ,报错TypeError: unhashable type: 'list'
xiaoqu_str = '|'.join(xiaoqu_list)
data = data[data['地址'].str.contains(xiaoqu_str)]
print(data)

数据没有的情况如下: