

pandas模块--------------------基础篇学习
1.读取Excel数据
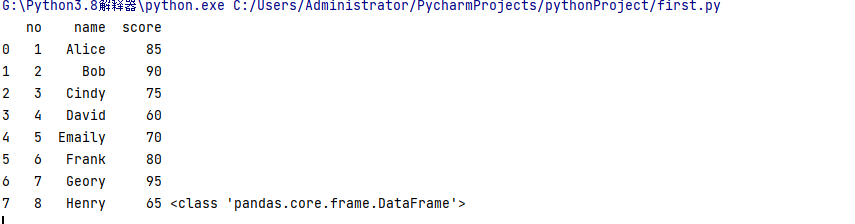
Python通过pandas库可以轻松地读取Excel数据。pandas库是一个专门用于数据分析和处理的库,它可以将Excel中的数据读取为DataFrame格式,便于进行后续的数据分析和操作。
import pandas as pd
data = pd.read_excel('new.xlsx')
print(data,type(data))
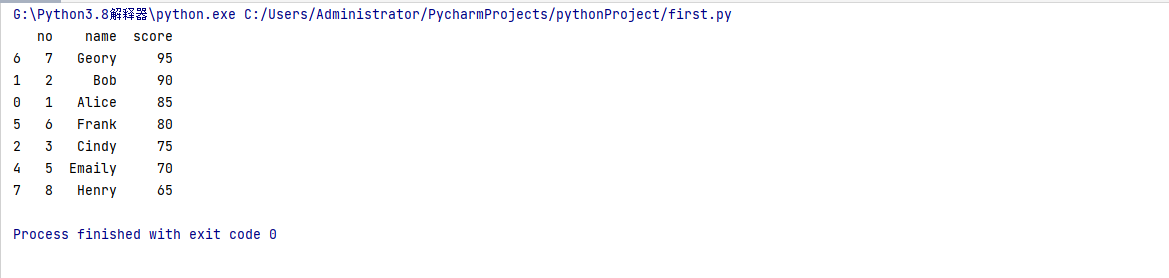
2. 同样是上面的测试表格,我们将分值大于60的人员筛选出来,然后按照分值降序排列。
import pandas as pd
data = pd.read_excel('new.xlsx')
res = data[data['score'] > 60 ].sort_values(by='score',ascending=False)
print(res)
3.使用pandas库,可以将处理好的数据快速写入Excel文件中,方便数据的保存和分享。
我们将刚才筛选的数据存入到一个Excel表格中。如下演示:
import pandas as pd
data = pd.read_excel('new.xlsx')
res = data[data['score'] > 60 ].sort_values(by='score',ascending=False)
res.to_excel('test_res.xlsx',index=False)

4.同样,我们可以使用Python的xlwings库,轻松地生成Excel报表,以便更好地展示数据和结果。示例如下:
import xlwings as xw
def generate_report():
#打开已存在的new.xlsx文件
wb = xw.Book('new.xlsx')
#获取Sheet1
sht = wb.sheets['Sheet1'] #添加图表
chart = sht.charts.add() #设置图表数据源
chart.set_source_data(sht.range('B1').expand('down').expand('right'))
chart.chart_type = 'column_clustered' #设置图表类型
chart.name= '成绩统计图' #设置图表名称
wb.save('report.xlsx') #保存工作簿
wb.close() #关闭工作簿
if __name__ == "__main__":
generate_report()

