pandas模块-----------比对不同数据(部分相同)
代码如下:
import pandas as pd
# 学生成绩表
df_grade = pd.read_excel("find.xlsx")
df_grade.head()
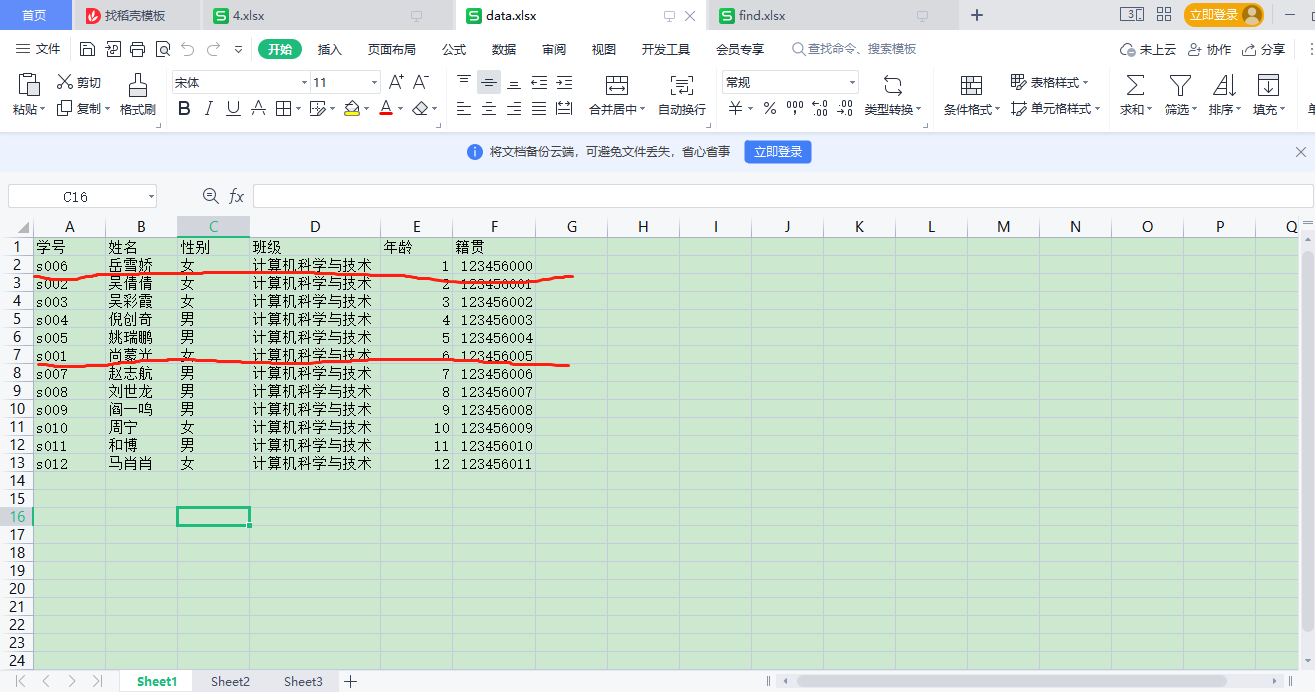
# 学生信息表
df_sinfo = pd.read_excel("data.xlsx")
df_sinfo.head()
# 只筛选第二个表的少量的列
df_sinfo = df_sinfo[["学号", "姓名", "性别"]]
df_sinfo.head()
df_merge = pd.merge(left=df_grade, right=df_sinfo, left_on="学号", right_on="学号")
df_merge.head()
# 将columns变成python的列表形式
new_columns = df_merge.columns.to_list()
# 按逆序insert,会将"姓名","性别"放到"学号"的后面
for name in ["姓名", "性别"][::-1]:
new_columns.remove(name)
new_columns.insert(new_columns.index("学号") + 1, name)
df_merge = df_merge.reindex(columns=new_columns)
df_merge.head()
#步骤4:输出最终的Excel文件
df_merge.to_excel("4.xlsx", index=False)
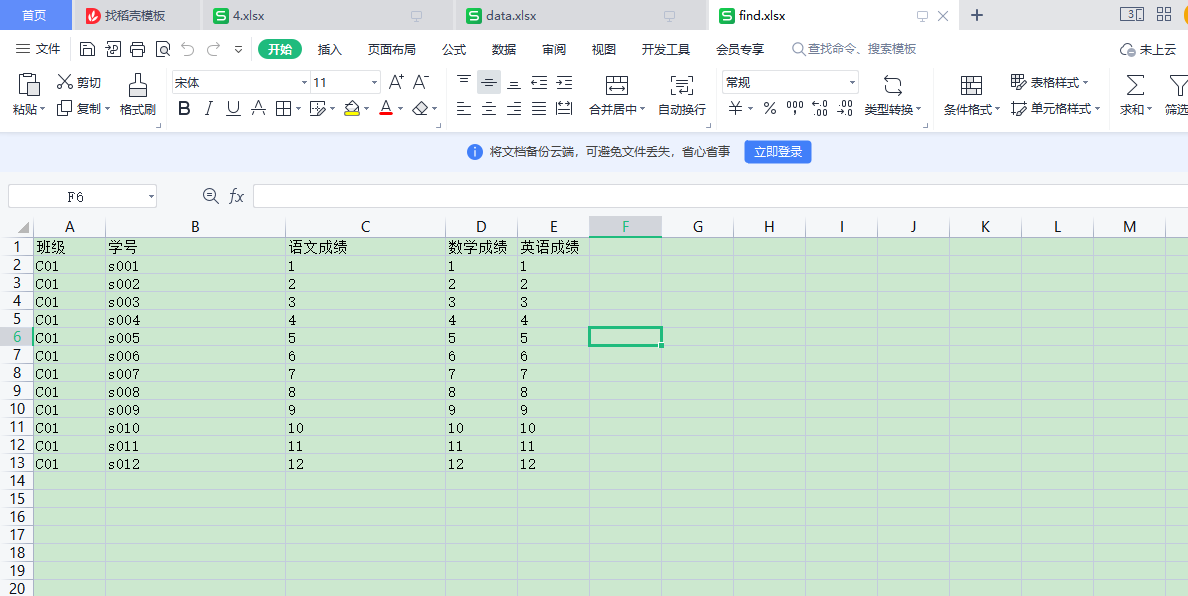
实现效果如下:
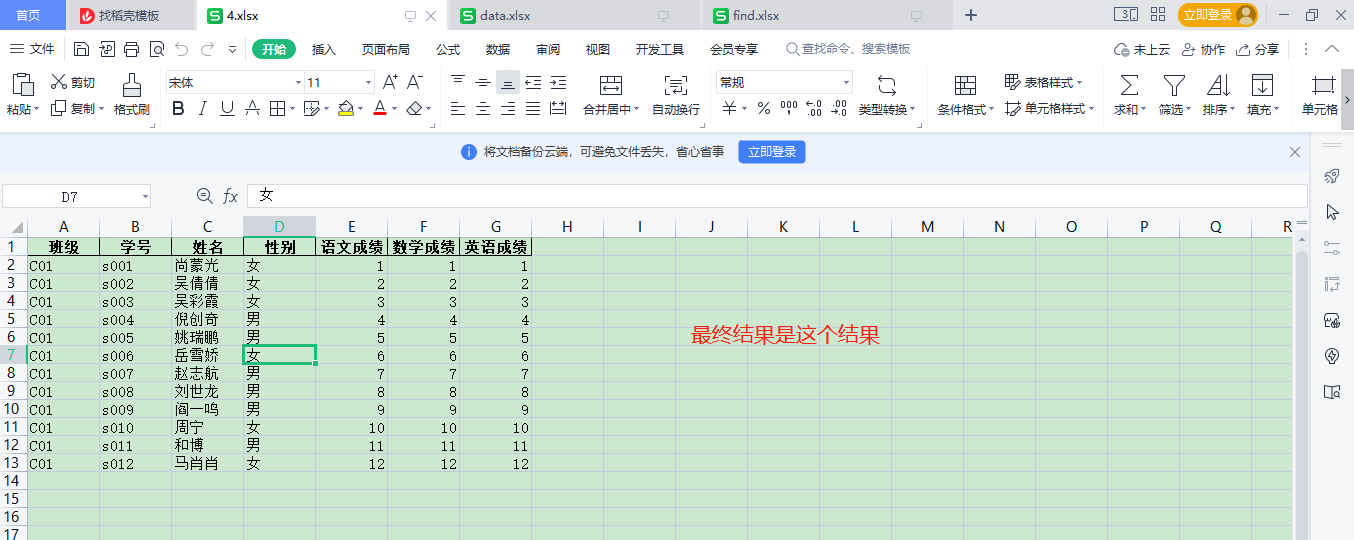
最终结果如下:4.xlsx
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
比对获得渠道名称,渠道编码:
上代码:
import pandas as pd
# 学生成绩表
df_grade = pd.read_excel("C:/Users/Administrator/Desktop/qu.xlsx")
df_grade.head()
# 学生信息表
df_sinfo = pd.read_excel("C:/Users/Administrator/Desktop/source.xlsx")
df_sinfo.head()
# 只筛选第二个表的少量的列
df_sinfo = df_sinfo[["渠道编码", "渠道名称"]]
df_sinfo.head()
df_merge = pd.merge(left=df_grade, right=df_sinfo, left_on="渠道编码", right_on="渠道编码")
df_merge.head()
# 将columns变成python的列表形式
new_columns = df_merge.columns.to_list()
# 按逆序insert,会将"姓名","性别"放到"学号"的后面
for name in ["渠道名称"][::-1]:
new_columns.remove(name)
new_columns.insert(new_columns.index("渠道编码") + 1, name)
df_merge = df_merge.reindex(columns=new_columns)
df_merge.head()
#步骤4:输出最终的Excel文件
df_merge.to_excel("5.xlsx", index=False)
实现效果如下:
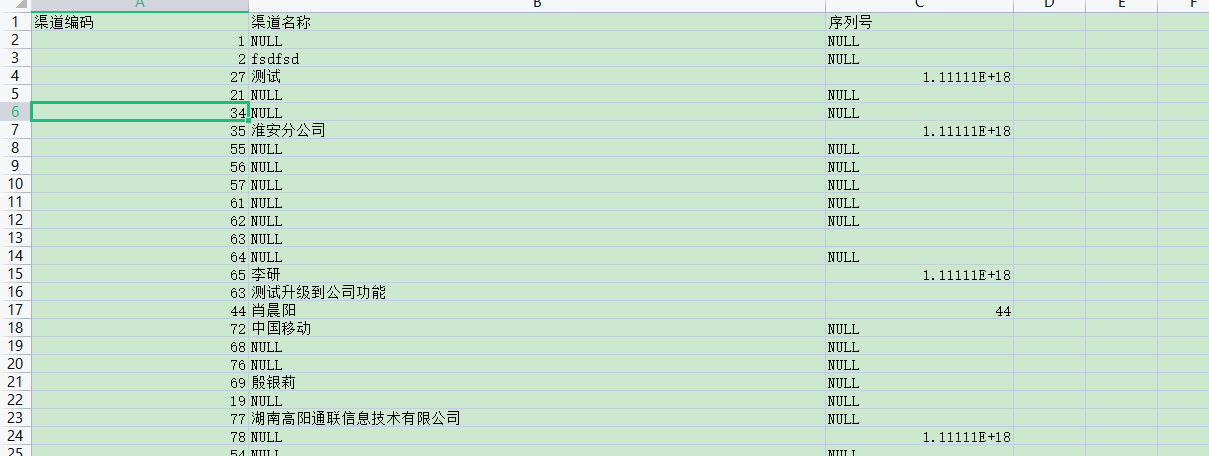
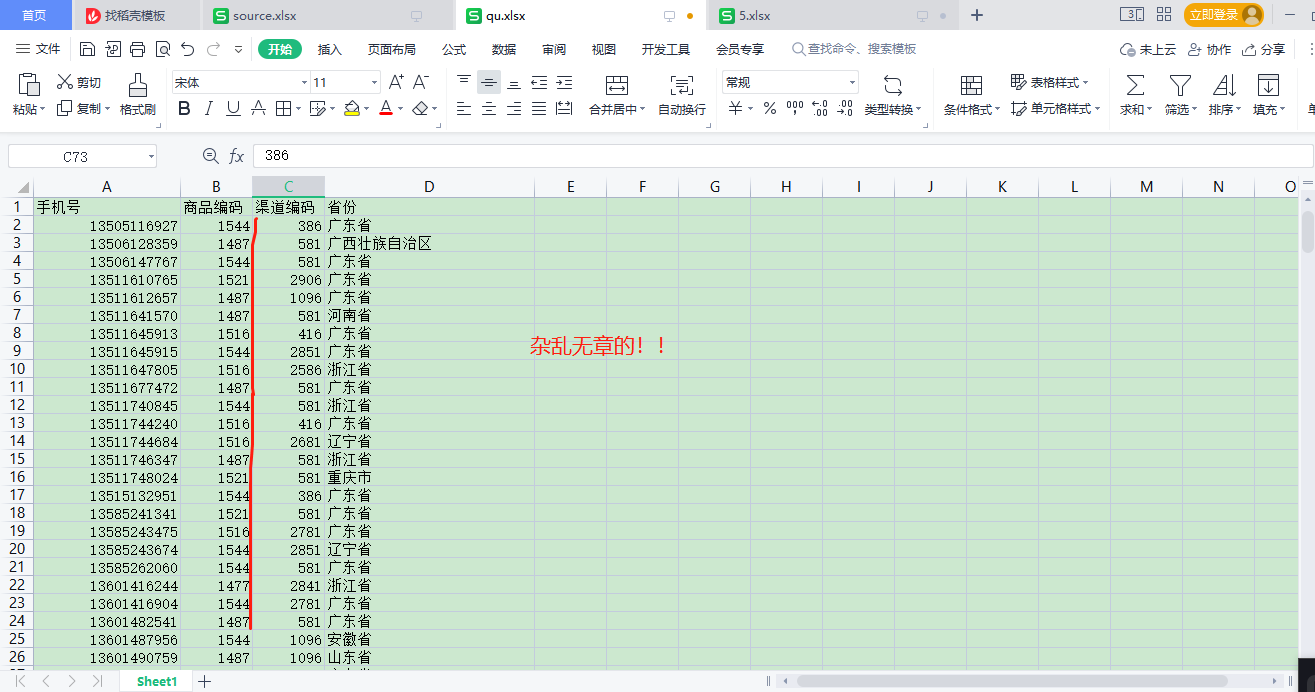
数据非常清晰明了:
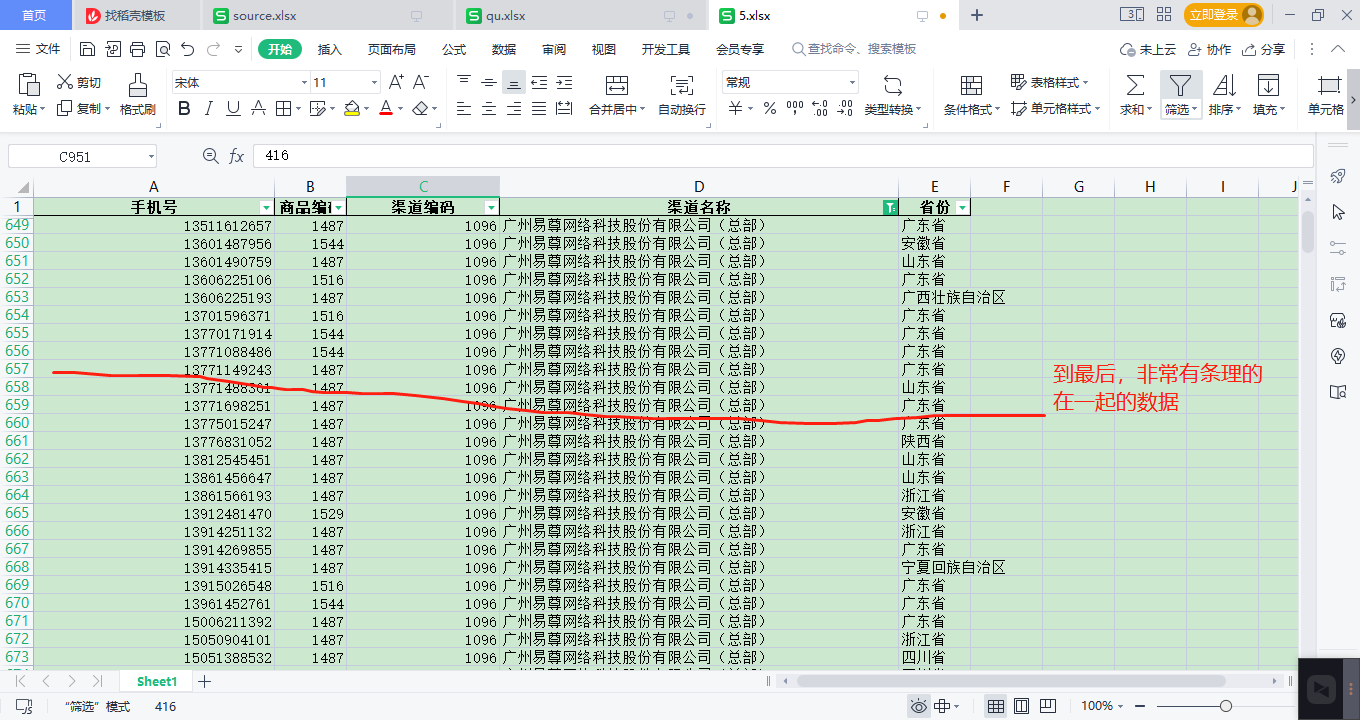
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
不安顺序来,执行相关代码:
import pandas as pd
#获取信息表
df_person = pd.read_excel('C:/Users/Administrator/Desktop/huo.xlsx')
df_person.head()
#获取第二张表
df_all = pd.read_excel('C:/Users/Administrator/Desktop/table.xlsx')
df_all.head()
#进行筛选
df_all = df_all[["姓名","学号","考试时间","第三次成绩","第二次成绩","第一次成绩"]]
df_all.head()
df_merge = pd.merge(left=df_person,right=df_all,left_on="姓名",right_on="姓名")
new_columns = df_merge.columns.to_list()
#输出最终的文件
df_merge.to_excel('C:/Users/Administrator/Desktop/1.xlsx',index=False)
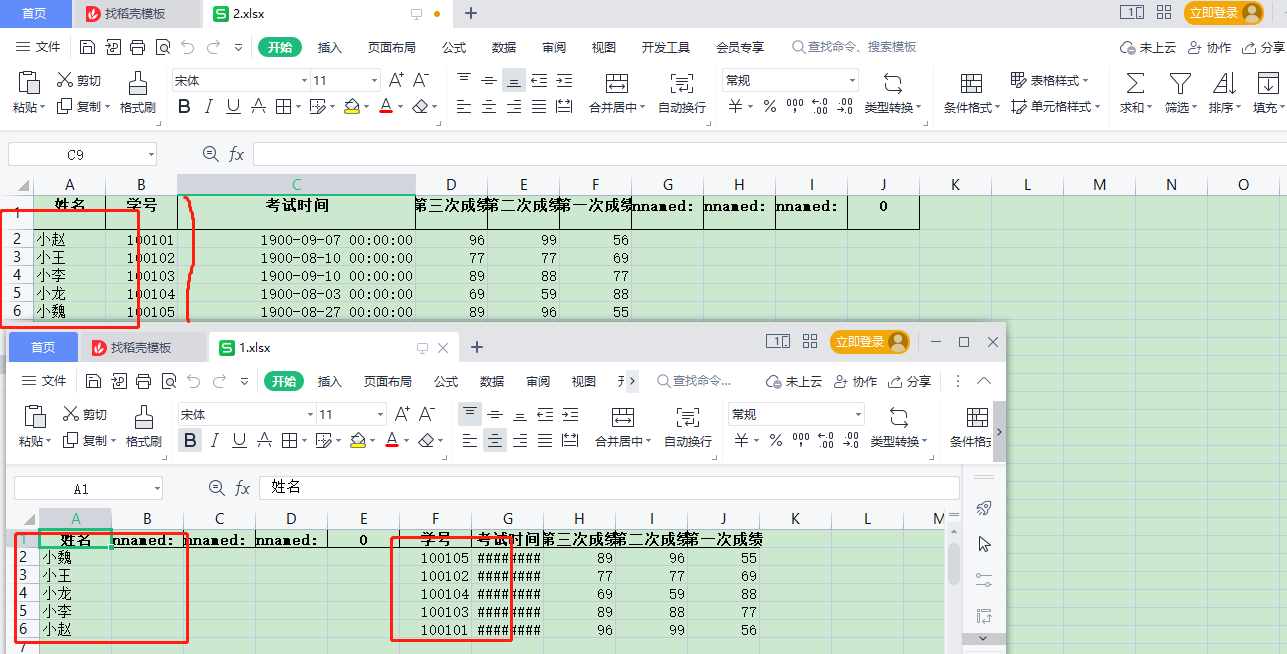
实现效果如下:
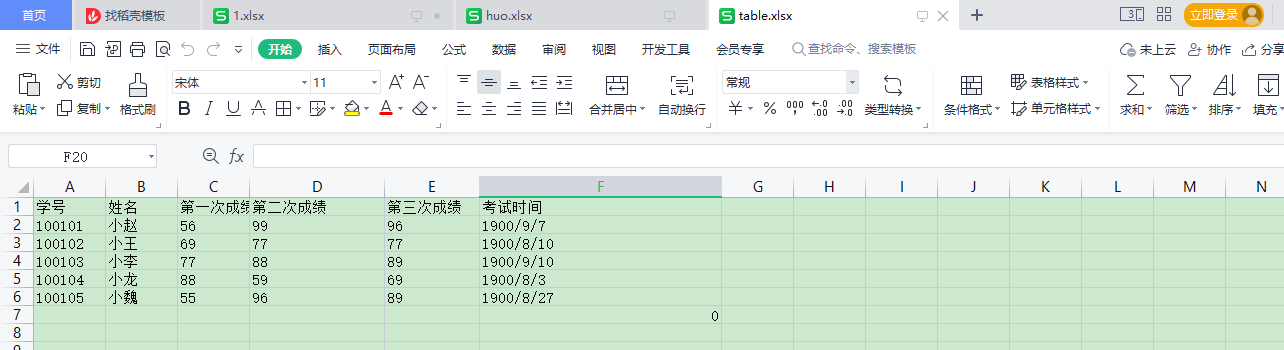
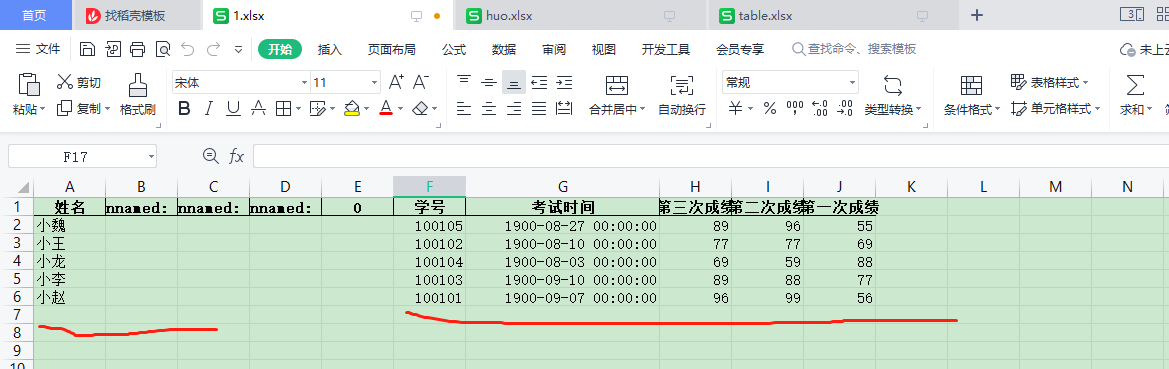
"姓名","学号","考试时间","第三次成绩","第二次成绩","第一次成绩"
-------------------------------------------------------------------------------
换个顺序
import pandas as pd
#获取信息表
df_person = pd.read_excel('C:/Users/Administrator/Desktop/huo.xlsx')
df_person.head()
#获取第二张表
df_all = pd.read_excel('C:/Users/Administrator/Desktop/table.xlsx')
df_all.head()
#进行筛选
df_all = df_all[["姓名","学号","考试时间","第三次成绩","第二次成绩","第一次成绩"]]
df_all.head()
df_merge = pd.merge(left=df_all,right=df_person)
new_columns = df_merge.columns.to_list()
#输出最终的文件
df_merge.to_excel('C:/Users/Administrator/Desktop/2.xlsx',index=False)