
shutil,sys,xlwt,xlrd模块---------------vlookup匹配相同内容,不同顺序的数据
代码如下:
import shutil
import sys
import xlwt
import xlrd
file1 = "a.xlsx"
# 打开表1
wb1 = xlrd.open_workbook(filename=file1)
# 表1要匹配的列索引
hid_index1 = 0
# 表1目标数据列索引
target_index1 = 1
# 表1的sheet
sheet1 = wb1.sheet_by_index(0)
# 表1的sheet的总行数
rowNum1 = sheet1.nrows
# 表1的sheet的总列数
colNum1 = sheet1.ncols
file2 = "b.xlsx"
# 打开表2
wb2 = xlrd.open_workbook(filename=file2) # 打开文件
# 表2要匹配的列索引
hid_index2 = 0
# 表2目标数据列索引
target_index2 = 2
# 表2的sheet
sheet2 = wb2.sheet_by_index(0) # 通过索引获取表格
# 表2的sheet的总行数
rowNum2 = sheet2.nrows
# 表2的sheet的总列数
colNum2 = sheet2.ncols
# xlwt准备生成一个新的文件
write_workbook = xlwt.Workbook()
write_sheet = write_workbook.add_sheet('sheet1', cell_overwrite_ok=True)
for index2 in range(0, rowNum2):
for col_index in range(0, colNum2):
# 遍历表2的每一行每一列,把对应的单元设置到新的文件中,即复制了表2的数据
write_sheet.write(index2, col_index, sheet2.cell_value(index2, col_index))
# 在遍历列过程中,如果碰到目标数据列索引.即需要补充的字段,则进行遍历表1,判断的id索引匹配
if col_index == target_index2:
for index1 in range(1, rowNum1):
hid1 = sheet1.cell_value(index1, hid_index1)
if hid1 == sheet2.cell_value(index2, hid_index2):
# 如果两个表的id相同则把表1的单元内容设置到表2对应的单元格
write_sheet.write(index2, col_index, sheet1.cell_value(index1, target_index1))
# 保存新的文件
write_workbook.save('new.xlsx')
实现效果如下:
a表
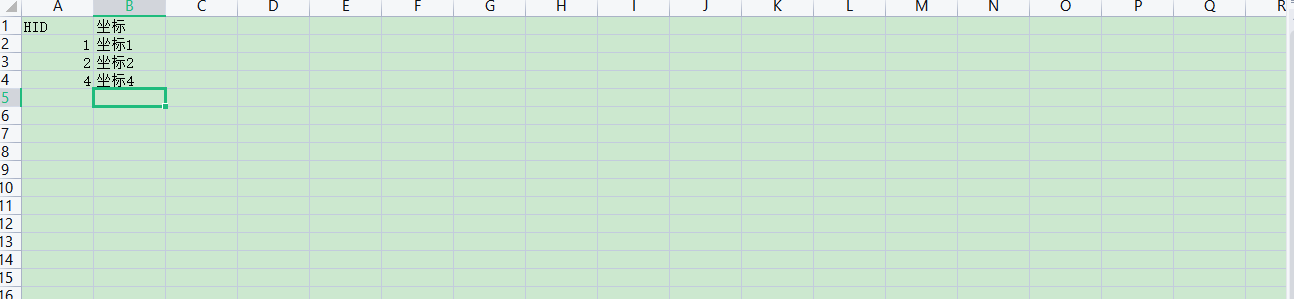
b表
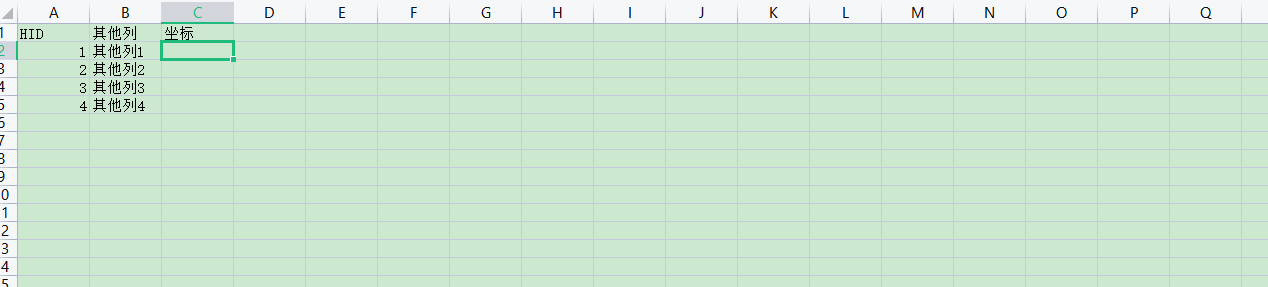
产生新表new表

