
mysql主从复制模式
mysql主从复制的原理:
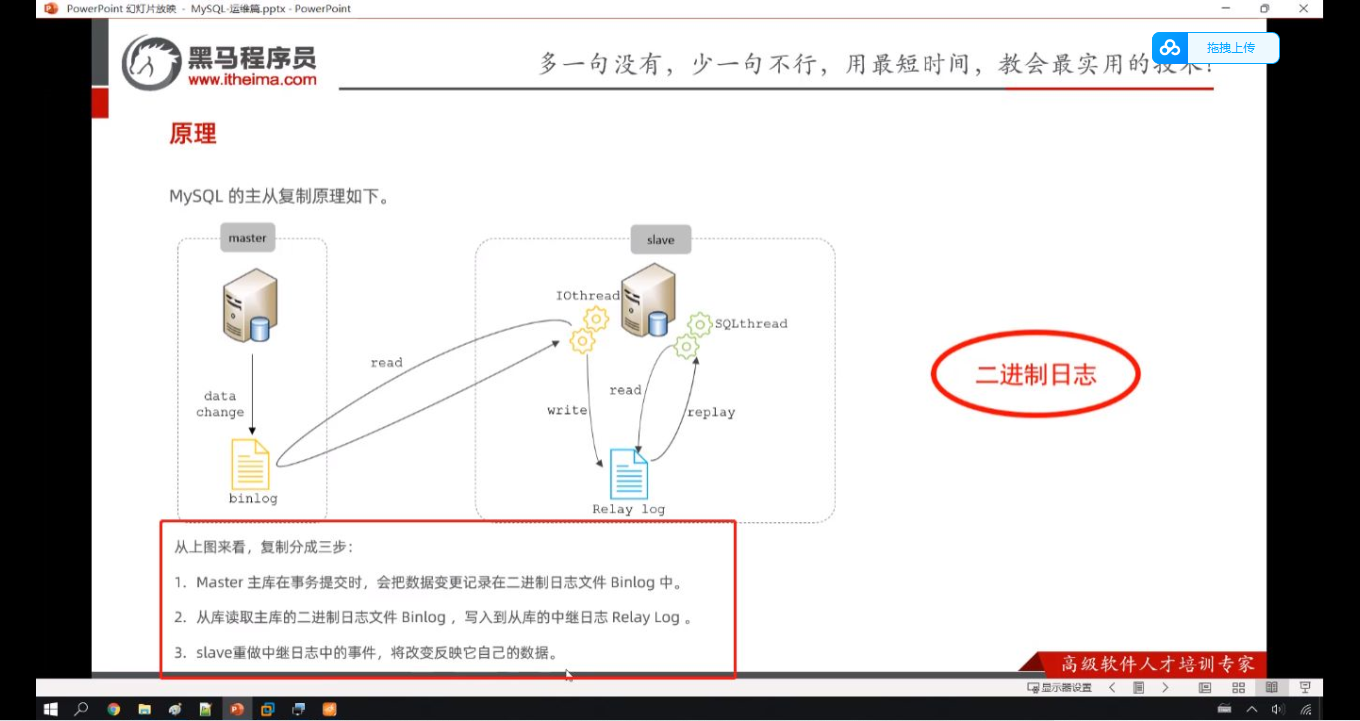
原理:1.master主库在事务提交时,会把数据变更记录在二进制日志文件binlog中;
2.从库读取主库的二进制日志文件binlog,写入到从库中的中继日志relaylog;
3.slave重做中继日志中的事件,将改变反映它自己的数据。
change master to
master_host='192.168.3.111',
master_log_pos=3266,
master_log_file='master-bin.000001',
master_password='SlaveAdmin',
master_user='data_cp';
主从复制实例:
ubuntu1804 mysql主配置文件的目录:/etc/mysql/mysql.conf.d/
主配置文件:/etc/mysql/mysql.conf.d/mysqld.cnf
一:主mysql服务器的操作如下:
vim /etc/mysql/mysql.conf.d/mysqld.cnf
#[mysqld]
#pid-file = /var/run/mysqld/mysqld.pid
#socket = /var/run/mysqld/mysqld.sock
#datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
#bind-address = 0.0.0.0
log-bin=master-bin #如果版本是5.7,则添加此四行
server-id=201
validate_password_length=6
validate_password_policy=0
#############
如果是8.0版本,添加的是一下四行:
log-bin=master-bin #添加此四行
server-id=201
validate_password.length=6
validate_password.policy=0
[root@gitlab ~]# mysql -V
mysql Ver 8.0.33 for Linux on x86_64 (MySQL Community Server - GPL)
service mysql restart
主添加登陆账号及主从复制的权限
create user sync@'%' identified by '123456';
grant replication slave on *.* to sync@'%' ;
show master status
-> ;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| slave-bin.000001 | 1219 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
二: 从mysql服务器的配置如下:
vim /etc/mysql/mysql.conf.d/mysqld.cnf
server-id=111
service mysql restart
change master to
master_host='192.168.3.201',
master_log_pos=692,
master_log_file='master-bin.000004',
master_password='123456',
master_user='sync';
start slave
mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 192.168.3.112
Master_User: sync
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: slave-bin.000001
Read_Master_Log_Pos: 1219
Relay_Log_File: ubuntu19-relay-bin.000002
Relay_Log_Pos: 326
Relay_Master_Log_File: slave-bin.000001
Slave_IO_Running: Yes #主要看这两个地方为yes就可以了
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 1219
Relay_Log_Space: 539
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 112
Master_UUID: d109bff1-6344-11ed-8286-000c29e564cb
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Replica has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set, 1 warning (0.01 sec)
ERROR:
No query specified
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
测试主从复制:
主服务器上面添加数据:
mysql> select * from employee;
+-------------+---------------+------------------+
| employee_id | employee_name | employee_contact |
+-------------+---------------+------------------+
| 1 | xiaoming | 11111111111 |
| 2 | jianjun | abc12345678 |
| 3 | 张三 | 222222222 |
| 4 | 张三 | 1234567890 |
+-------------+---------------+------------------+
4 rows in set (0.01 sec)
mysql> update employee set employee_name="李四" where employee_contact="1234567890"
-> ;
Query OK, 1 row affected (0.35 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from employee;
+-------------+---------------+------------------+
| employee_id | employee_name | employee_contact |
+-------------+---------------+------------------+
| 1 | xiaoming | 11111111111 |
| 2 | jianjun | abc12345678 |
| 3 | 张三 | 222222222 |
| 4 | 李四 | 1234567890 |
+-------------+---------------+------------------+
从服务器上面查看数据:
mysql> show tables;
+---------------+
| Tables_in_hr2 |
+---------------+
| employee |
+---------------+
1 row in set (0.01 sec)
mysql> select * from employee;
+-------------+---------------+------------------+
| employee_id | employee_name | employee_contact |
+-------------+---------------+------------------+
| 1 | xiaoming | 11111111111 |
| 2 | jianjun | abc12345678 |
| 3 | 张三 | 222222222 |
| 4 | 张三 | 1234567890 |
+-------------+---------------+------------------+
4 rows in set (0.00 sec)
mysql> select * from employee;
+-------------+---------------+------------------+
| employee_id | employee_name | employee_contact |
+-------------+---------------+------------------+
| 1 | xiaoming | 11111111111 |
| 2 | jianjun | abc12345678 |
| 3 | 张三 | 222222222 |
| 4 | 李四 | 1234567890 |
+-------------+---------------+------------------+
4 rows in set (0.00 sec)
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
由于从和主的数据发生不一致的情况,导致以下报错:::
Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS' at source log master-bin.000001, end_log_pos 3286. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any.
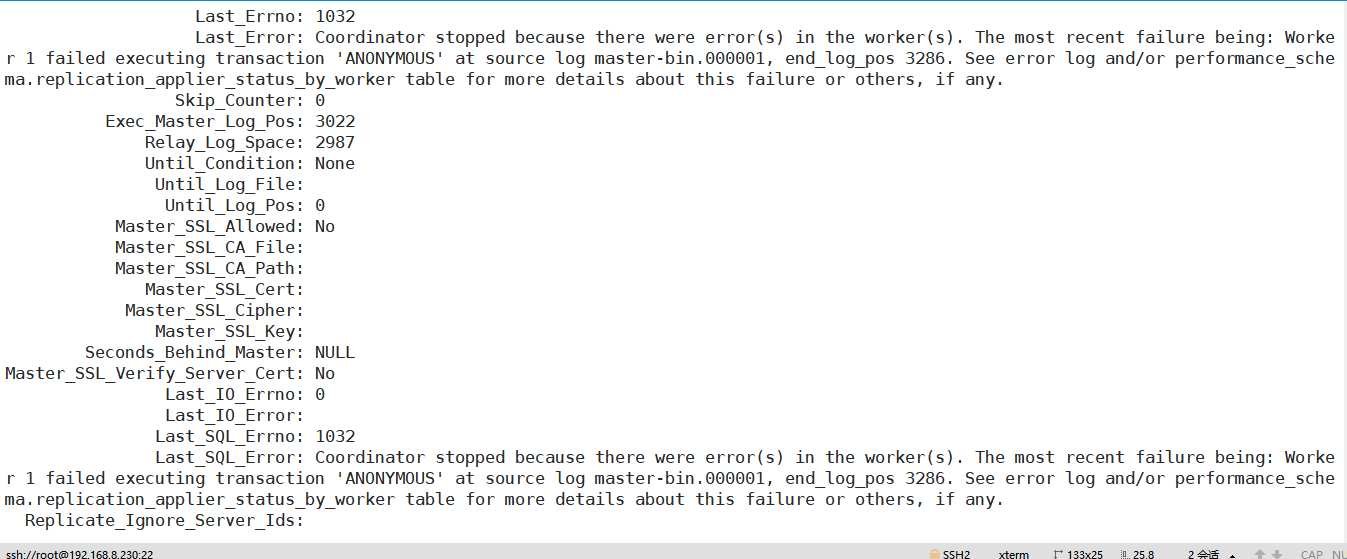
select * from performance_schema.replication_applier_status_by_worker\G
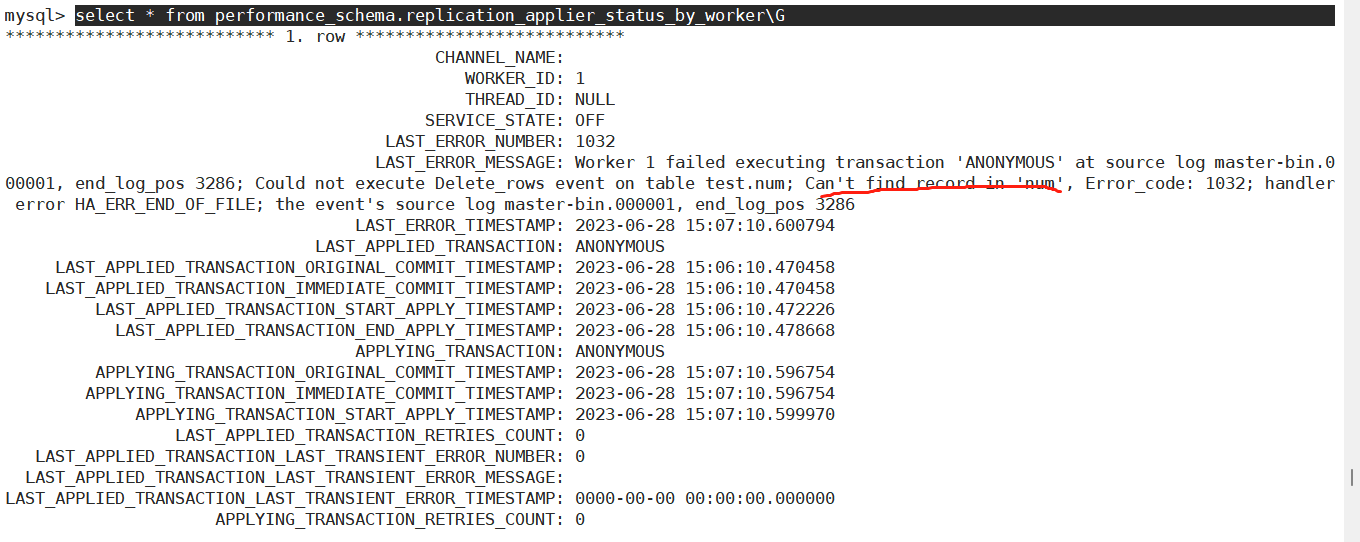
Worker 1 failed executing transaction 'ANONYMOUS' at source log master-bin.000001, end_log_pos 3286; Could not execute Delete_rows event on table test.num; Can't find record in 'num', Error_code: 1032; handler error HA_ERR_END_OF_FILE; the event's source log master-bin.000001, end_log_pos 3286
mysqlbinlog --no-defaults -v -v --base64-output=decode-rows /zdata/mysql_data/mysql-bin.000063 | grep -A 20 “171661170” --color
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
补充设置数据库用户密码的命令::
mysql> select plugin from user where user='sync';
Empty set (0.00 sec)
mysql> create user sync@'%' identified with mysql_native_password by '12345678';
Query OK, 0 rows affected (0.25 sec)
mysql> select plugin from user where user='sync';
+-----------------------+
| plugin |
+-----------------------+
| mysql_native_password |
+-----------------------+
1 row in set (0.00 sec)
mysql> select plugin from user where user='root';
+-----------------------+
| plugin |
+-----------------------+
| caching_sha2_password |
+-----------------------+
1 row in set (0.00 sec)
mysql> grant replication slave on *.* to sync@'%'
-> ;
Query OK, 0 rows affected (0.06 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.08 sec)
MySQL 8.0 配置mysql_native_password身份验证插件的密码
mysql8.0的默认密码验证不再是password。所以在创建用户时,create user 'username'@'%' identified by 'password'; 客户端是无法连接服务的。
方法一:
登录MySQL后输入:
ALTER USER 'username'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
FLUSH PRIVILEGES;
方法二:
编辑my.cnf文件,更改默认的身份认证插件。比如说:
vim /data/mysql/mysql_3306/my_3306.cnf
# 在[mysqld]中添加下边的代码
default_authentication_plugin=mysql_native_password
这个需要重启服务才生效。

mysql> select user,host,plugin from mysql.user; +------------------+-----------+-----------------------+ | user | host | plugin | +------------------+-----------+-----------------------+ | bak | % | mysql_native_password | | monitor | % | mysql_native_password | | repuser | % | caching_sha2_password | | mysql.infoschema | localhost | caching_sha2_password | | mysql.session | localhost | caching_sha2_password | | mysql.sys | localhost | caching_sha2_password | | repuser | localhost | caching_sha2_password | | root | localhost | caching_sha2_password | +------------------+-----------+-----------------------+ 8 rows in set (0.00 sec)
认真研究MySQL的主从复制
【1】主从复制概述
① 如何提升数据库并发能力
在实际工作中,我们常常将Redis作为缓存与MySQL配合使用,当有请求的时候,首先会从缓存中进行查找。如果存在就直接取出,如果不存在再访问数据库。这样就提升了读取的效率,也减少了对后端数据库的访问压力。Redis的缓存结构是高并发架构中非常重要的一环。
此外,一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大。有一个思路就是采用数据库集群的方案,做主从架构、进行读写分离,这样同样可以提升数据库的并发处理能力。但并不是所有的应用都需要对数据库进行主从架构的设置,毕竟设置架构本身是有成本的。
如果我们的目的在于提升数据库高并发访问的效率,那么首先考虑的是如何优化SQL和索引,这种方式简单有效。其次才是采用缓存的策略,比如使用Redis将热点数据保存在内存数据库中,提升读取的效率。最后才是对数据库采用主从架构,进行读写分离。
按照上面的方式进行优化,使用和维护的成本是由低到高的。
② 主从复制的作用
主从同步设计不仅可以提高数据库的吞吐量,还有以下3个方面的作用。
第一个作用:读写分离。我们可以通过主从复制的方式来同步数据,然后通过读写分离提高数据库并发处理能力。
其中一个是Master库,负责写入数据,我们称之为:写库。其他都是slave从库,负责读取数据,我们称之为:读库。
当主库进行更新的时候会自动将数据复制到从库中,而我们在客户端读取数据的时候,会从从库中进行读取。
面对“读多写少”的需求,采用读写分离的方式,可以实现更高的并发访问。同时,我们还能对从服务器进行负载均衡,让不同的读请求按照策略均匀地分发到不同的从服务器上,让读取更加顺畅。读取顺畅的另一个原因,就是减少了锁表的影响。比如我们让主库负责写,当主库出现写锁的时候,不会影响到从库进行select的读取。
第2个作用就是数据备份。
我们通过主从复制将主库上的数据复制到了从库上,相当于是一种热备份机制,也就是在主库正常运行的情况下进行的备份不会影响到服务。
第3个作用是具有高可用性。
数据备份实际上是一种冗余的机制,通过这种冗余的方式可以换取数据库的高可用性,也就是当服务器出现故障或宕机的情况下,可以切换到从服务器上,保证服务器的正常运行。
关于高可用性的程度,我们可以用一个指标衡量,即正常可用时间 / 全年时间。比如要达到全年99.999%的时间都可用,就意味着系统在一年中的不可用时间不得超过3652460*(1-99.999%)=5.256分钟(含系统崩溃的时间、日常维护操作导致的停机时间等),其他时间都需要保持可用的状态。
实际上,更高的高可用性,意味着需要付出更高的成本代价。在现实中我们需要结合业务需求和成本来进行选择。
【2】主从复制的原理
① 原理剖析
核心关键词:三个线程。实际上主从同步的原理就是基于binlog进行数据同步的。在主从复制过程中,会基于3个线程来操作,一个主库线程,两个从库线程。
二进制日志转储线程(Binlog dump thread)是一个主库线程。当从库线程连接的时候,主库可以将二进制日志发送给从库,当主库读取事件(Event)的时候,会在Binlog上加锁,读取完成之后,再将锁释放掉。
从库I/O线程会连接到主库, 向主库发送请求更新Binlog。这时从库的IO线程就可以读取到主库的二进制日志转储线程发送的Binlog更新部分,并且拷贝到本地的中继日志(Relay log)。
从库SQL线程会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
注意:不是所有版本的MySQL都默认开启服务器的二进制日志。在进行主从同步的时候,我们需要先检查服务器是否已经开启了二进制日志。除非特殊指定,默认情况下从服务器会执行所有主服务器中保存的事件。也可以通过配置,使从服务器执行特定的事件。
② 复制三步骤
步骤1:Master将写操作记录到二进制日志(binlog)。这些记录叫做二进制日志事件(binary log events);
步骤2:Slave 将Master的binary log events 拷贝到它的中继日志(relay log);
步骤3:Slave重做中继日志中的事件,将改变应用到自己的数据库总。MySQL复制是异步的且串行化的,而且重启后从接入点开始复制。
不过复制的最大问题是:延时。
③ 复制的基本原则
有三个需要注意事项:
每个Slave只有一个Master
每个Slave只能有一个唯一的服务器ID
每个Master可以有多个Slave。
【3】主从架构的搭建
这部分参考博文Linux下搭建MySQL主从复制之一主一从架构 。
【4】同步数据一致性问题
主从同步的要求:
读库和写库的数据一致(最终一致)
写数据必须写到写库
读数据必须到读库(不一定哦,根据业务来定)
① 主从延迟问题
进行主从同步的内容是二进制日志,它是一个文件,在进行网络传输的过程中就一定会存在主从延迟,这样就可能造成用户在从库读取的数据不是最新的数据,也就是主从同步中的数据不一致性问题。
导致主从延迟的时间点主要包括以下三个:
主库A执行完成一个事务,写入binlog,我们把这个时刻记为T1;
之后传给从库B,我们把从库B接收完这个binlog的时刻记为T2;
从库B执行完成这个事务,我们把这个时刻记为T3。
② 如何减少主从延迟
降低多线程大事务并发的概率,优化业务逻辑
优化SQL,避免慢SQL,减少批量操作
提高从库机器的配置,减少主库写binlog和从库读binlog的效率差
尽量采用短的链路,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时。
实时性要求的业务读强制性走主库,从库只做灾备。
③ 如何解决一致性问题
如果操作的数据存储在同一个数据库中,那么对数据进行更新的时候,可以对记录进行加写锁。这样在读取的时候就不会发生数据不一致的情况。但这时从库的作用就是备份,并没有起到读写分离,分担主库读压力的作用。
读写分离情况下,解决主从同步中数据不一致的问题,就是解决主从之间数据复制方式的问题。如果按照数据一致性从弱到强来进行划分,有以下3种复制方式。
方法1:异步复制
异步模式就是客户端提交commit之后不需要等从库返回任何结果,而是直接将结果返回给客户端。这样做的好处是不会影响主库写的效率,但可能会存在主库宕机,而binlog还没有同步到从库的情况,也就是此时的主库和从库数据不一致。
这时候从从库中选择一个作为新主,那么新主则可能缺少原来主服务器中已提交的事务。所以,这种复制模式下的数据一致性是最弱的。
方法2:半同步复制
MySQL5.5版本之后开始支持半同步复制的方式。原理是在客户端提交commit之后不直接将结果返回给客户端,而是等待至少有一个从库接收到了binlog,并且写入到中继日志中,再返回给客户端。
这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。
在MySQL5.7版本中还增加了一个rpl_semi_sync_master_wait_for_slave_cout参数,可以对应答的从库数量进行设置,默认为1。也就是说只要有1个从库进行了响应,就可以返回给客户端。如果将这个参数调大,可以提升数据一致性的强度,但也会增加主库等待从库响应的时间。
方法3:组复制
异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制是通过判断从库响应的个数来决定是否返回给客户端,虽然数据一致性相比于异步复制有提升,但仍然无法满足对数据一致性要求高的场景,比如金融领域。MGR很好地弥补了这两种复制模式的不足。
组复制技术,简称MGR(MySQL Group Replication),是MySQL在5.7.17版本中推出的一种新的数据复制技术,这种复制技术是基于Paxos协议的状态机复制。
MGR是如何工作的?
首先我们将多个节点共同组成一个复制组,在执行读写RW事务的时候,需要通过一致性协议层(Consensus层)的同意,也就是读写事务想要进行提交,必须要经过组里“大多数人”(对应Node节点)的同意,大多数指的是同意的节点数量需要大于(N/2+1),这样才可以进行提交,而不是原发起方一个说了算。而针对只读(RO)事务则不需要经过组内同意,直接commit即可。
在一个复制组内有多个节点组成,它们各自维护了自己的数据副本,并且在一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性。
MGR将MySQL带入了数据强一致性的时代,是一个划时代的创新,其中一个中药的原因就是MGR是基于Paxos协议的。Paxos算法是由2013年的图灵奖获得者Leslie Lamport于1990年提出的。事实上,Paxos算法提出来之后就作为分布式一致性算法被广泛应用,比如Apache的Zookeeper也是基于Paxos实现的。
推荐阅读
Java 线程池的工作原理Java判断线程是否结束的方法有哪些基于MySQL binlog日志,实现Elasticsearch近实时同步实践
equals方法深入解析
