ansible自动化部署 Zookeeper 集群
Linux 9 自动化部署 Zookeeper 集群
Apache ZooKeeper 是一个开源服务,可以实现高度可靠的分布式协调。它常被应用于分布式系统中,管理配置信息、命名服务、分布式同步、法定人数和状态。此外,一些分布式系统依靠 ZooKeeper 来实现共识、leader 选举和组管理。
本文将通过以下主题,讨论在 Rocky Linux 9 上安装和配置满足生产环境高可用性及弹性要求的 Zookeeper 集群:
- 部署环境介绍
- 下载 Zookeeper 包
- 部署 JDK
- 部署 Zookeeper 集群
- 验证集群
- 自动化监控
- 总结
35.1 部署环境介绍
完成本教程需要四个节点:一个节点作为 Ansible 控制节点,三个节点部署 Zookeeper 集群。
35.1.1 节点信息
四个节点分别为 2 核 CPU、2 GB 内存的虚拟机。
ZooKeeper 将数据保存在内存中以实现高吞吐量和低延迟,因此生产环境要提供更高内存的主机,建议 8 GB 内存。低内存可能产生 JVM 交换,导致 ZooKeeper 服务延迟。高延迟可能会导致客户端会话超时等问题,影响系统稳定。
Ansilbe 节点信息:
# IP:10.211.55.18# 主机名:automate-host.aiops.red# 系统版本:Rocky Linux release 9.1
Ansible Inventory hosts:
[zookeeper]zk1.server.aiops.redzk2.server.aiops.redzk3.server.aiops.red[prometheus]prometheus.server.aiops.red
Zookeeper 节点信息:
# zookeeper1# IP:10.211.55.31# 主机名:zk1.server.aiops.red# 系统版本:Rocky Linux release 9.1# zookeeper2# IP:10.211.55.32# 主机名:zk2.server.aiops.red# 系统版本:Rocky Linux release 9.1# zookeeper3# IP:10.211.55.33# 主机名:zk3.server.aiops.red# 系统版本:Rocky Linux release 9.1
35.1.2 节点要求
为使安装过程顺利进行,节点应满足以下要求。
35.1.2.1 时钟同步
Zookeeper 集群节点时钟须保持同步。
要自动化实现时钟同步,可以参考 “Linux 9 自动化部署 NTP 服务”。
35.1.2.2 主机名解析
Ansible 控制节点能够解析 Zookeeper 节点的主机名,通过主机名访问 Zookeeper 节点。
要实现主机名称解析,可以在 Ansible 控制节点的 /etc/hosts 文件中指定 Zookeeper 节点的 IP、主机名条目,或者参考 “Linux 9 自动化部署 DNS 服务” 一文配置 DNS 服务。
35.1.2.3 账号权限
Ansible 控制节点可以免密登录 Zookeeper 节点,并能够免密执行 sudo。可以参考 “Linux 9 自动化部署 NTP 服务” 中的 “部署环境要求” 一节实现。
35.1.3 扩展知识
在本文的最后部分,演示了通过 Prometheus 自动化监控 Zookeeper 集群。如要完成此部分,需要准备好 Prometheus 监控系统。有关 Prometheus 监控系统的自动化部署,可以参考 ”Linux 9 自动化配置 Prometheus 监控系统“。
在满足以上要求后,开始 Zookeeper 集群的部署。
35.2 下载 Zookeeper 包
Linux 的 dnf 仓库没有提供 Zookeeper 的安装包,因此需要从 Apache Zookeeper 官网下载。应将下载包和安装配置 Zookeeper 分成两个 Ansible Role 实现。因为包下载一次即可,无需多次执行。
35.2.1 创建下载 Zookeeper 的角色
执行以下命令,创建 download_zookeeper Role:
ansible-galaxy role init --init-path ~/roles download_zookeepercd ~/roles/download_zookeeper
在 tasks/main.yml 文件中,编辑下载 Zookeeper 的任务:
---# tasks file for download_zookeeper- name: create download directory taskansible.builtin.file:path: "{{ download_path }}"state: directory- name: download and unarchive tarball taskansible.builtin.unarchive:src: "{{ download_url }}"dest: "{{ download_path }}"remote_src: trueextra_opts:- --strip-components=1
35.2.2 创建下载 Zookeeper 的 Playbook
在 ~/playbooks/ 目录下创建 deploy_zookeeper/ 目录:
mkdir ~/playbooks/deploy_zookeepercd ~/playbooks/deploy_zookeeper
创建 download_zookeeper.yaml Playbook 文件,内容如下:
---- name: download zookeeper tarball playhosts: localhostbecome: falsegather_facts: falsevars_files:- variables.yamlroles:- role: download_zookeepertags: download_zookeeper...
创建变量文件:
mkdir varstouch vars/variables.yaml
在 vars/variables.yaml 中添加需要的变量:
download_path: ~/software/zookeeper_tools/zookeeperdownload_url: https://downloads.apache.org/zookeeper/stable/apache-zookeeper-3.6.3-bin.tar.gz
35.2.3 下载安装包
执行 download_zookeeper.yaml Playbook,下载安装包:
ansible-playbook download_zookeeper.yaml使用 tree 命令查看下载文件的目录结构:
tree -L 1 ~/software/zookeeper_tools/zookeeper下载的版本为当前稳定版,可以在 https://downloads.apache.org/zookeeper/stable/ 查看。
35.3 部署 JDK
Zookeeper 服务依赖 Java 环境才能运行,因此需要在运行 Zookeeper 的节点上部署 JDK。
有关 JDK 自动化部署的详细介绍,可以参考 ”Linux 9 自动化部署 JDK“。在 JDK 部署完成后,继续下面的步骤。
35.4 部署 Zookeeper 集群
在节点和安装包准备好后,本节讨论 Zookeeper 集群的安装。
35.4.1 设置 Local Facts 变量
Zookeeper 集群依赖 SID 进行快速选举,SID 的值必须写入数据目录的 myid 文件中。通过定义 Local Facts 变量,为节点设置 SID 值。
创建三个 Facts 文件:
for sid in $(seq 1 3); do echo -e "[var]\nsid=${sid}" > zk${sid}.fact; done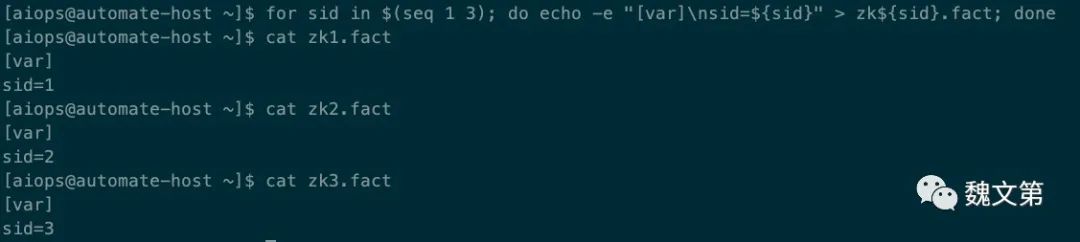 图 35.5 创建 Local Facts 变量文件
图 35.5 创建 Local Facts 变量文件
为 Zookeeper 节点创建 /etc/ansible/facts.d/ 目录:
ansible zookeeper -m file -a "path=/etc/ansible/facts.d state=directory" -b将三个文件拷贝到对应节点的 /etc/ansible/facts.d/:
ansible zk1.server.aiops.red -m copy -a "src=zk1.fact dest=/etc/ansible/facts.d/zk.fact" -bansible zk2.server.aiops.red -m copy -a "src=zk2.fact dest=/etc/ansible/facts.d/zk.fact" -bansible zk3.server.aiops.red -m copy -a "src=zk3.fact dest=/etc/ansible/facts.d/zk.fact" -b
图 35.7 拷贝 fact 文件到对应的托管节点
35.4.2 创建部署 Zookeeper 的角色
使用以下命令创建 Role:
ansible-galaxy role init --init-path ~/roles deploy_zookeepercd ~/roles/deploy_zookeeper
图 35.8 创建部署 Zookeeper 的角色
35.4.2.1 创建用户
使用独立用户运行服务,可以提高隔离性和安全性。因此,第一个任务是创建用于启动 Zookeeper 服务的用户。
编辑 tasks/main.yml 文件,添加创建用户的任务:
- name: "create {{ user_name }} user task"ansible.builtin.user:name: "{{ user_name }}"home: "{{ home_dir }}"shell: /sbin/nologin
需要为任务定义两个变量,user_name 表示创建的用户名;home_dir 用户家目录。Zookeeper 文件将被安装在 home_dir 目录。
变量可以在 defaults/main.yml 文件或 vars/main.yml 文件中定义,前者定义的变量,可以被 Playbook 中的变量覆盖。
35.4.2.2 创建数据目录
Zookeeper 将所有配置、状态数据持久化在磁盘上,这样即使重启后,服务仍能正常工作。
在 tasks/main.yml 中编写第二个任务,为 Zookeeper 创建数据目录:
- name: create data directory taskansible.builtin.file:path: "{{ home_dir }}/data/zookeeper"state: directoryowner: "{{ user_name }}"group: "{{ user_name }}"mode: 0755
35.4.2.3 拷贝二进制文件
将下载好的 Zookeeper 安装文件,拷贝到 home_dir 下。编辑 tasks/main.yml 文件,添加以下两个任务:
- name: copy the installation file taskansible.posix.synchronize:src: "{{ download_path }}"dest: "{{ home_dir }}"- name: set the file owner taskansible.builtin.shell: "chown {{ user_name }}.{{ user_name }} {{ home_dir }} -R"
ansible.posix.synchronize 模块在此处以 root 用户同步文件。因此,在文件同步结束后,使用 chown 修改目录的属主及属组。
35.4.2.4 配置文件模板
Zookeeper 集群中的节点应为奇数个,这样就能形成有效的法定人数。法定人数是指在提交事务前,需要同意的最小节点数。法定人数为奇数,才能形成多数。偶数个节点可能导致平局,这将意味着节点不会达成多数或共识。
在 templates/ 目录下,创建 zoo.cfg.j2 文件,内容如下:
tickTime=2000dataDir={{ home_dir }}/data/zookeeperclientPort={{ client_port }}maxClientCnxns=60initLimit=10syncLimit=5{% for host in groups['zookeeper'] %}server.{{ hostvars[host].ansible_local.zk.var['sid'] }}={{ host }}:{{ follower_port }}:{{ leader_port }}{% endfor %}
模板配置文件解析:
- tickTime:单位毫秒。Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,每个 tickTime 时间都会发送一个心跳。
- dataDir:Zookeeper 保存数据的目录。
- clientPort:客户端连接 Zookeeper 服务器的端口,Zookeeper 监听该端口,接受客户端的访问请求。默认 TCP 2181。
- maxClientCnxns:单个客户端与单台服务器的连接数限制,是 ip 级别的,默认 60,如果设置为 0,表示不作任何限制。
- initLimit:Follower 在启动过程中,会从 Leader 同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader 允许 Follower 在 initLimit 时间内完成这个工作。
- syncLimit:在运行过程中,Leader 负责与 Zookeeper 集群中所有机器进行通信,例如通过一些心跳检测机制,检测机器的存活状态。如果 Leader 发出心跳包在 syncLimit 之后,还没有从 Follower 那里收到响应,那么就认为这个 Follower 已经下线。
- server.sid:sid 是一个数字,与
myid文件中的值一致。右边可以配置两个端口,第一个端口用于 Follower 和 Leader 之间的数据同步和其它通信,第二个端口用于 Leader 选举过程中投票通信。
sid 的值来自于之前定义的 Local Facts 变量,通过 hostvars[host] 从对应主机获取 sid。
准备好了模板文件,接下来在 tasks/main.yml 中定义将模板配置文件渲染为 Zookeeper 配置文件的任务:
- name: render configuration file taskansible.builtin.template:src: zoo.cfg.j2dest: "{{ home_dir }}/zookeeper/conf/zoo.cfg"notify: restart zookeeper service handler
notify: restart zookeeper service handler 定义了当配置文件有变化时,执行 ”restart zookeeper service handler“,重启 Zookeeper 服务。
35.4.2.5 myid 模板
为 Zookeeper 生成 myid 文件,该文件的内容应与 sid 一致。创建 templates/myid.j2 文件,内容如下:
{{ ansible_local.zk.var['sid'] }}在 tasks/main.yml 中定义将模板渲染为 myid 文件的任务:
- name: render myid file taskansible.builtin.template:src: myid.j2dest: "{{ home_dir }}/data/zookeeper/myid"
myid 文件应存放在 Zookeeper 的 dataDir 目录下。
35.4.2.6 单元文件模板
创建启动 Zookeeper 服务的单元文件模板,templates/zookeeper.service.j2 内容如下:
[Unit]Description=Zookeeper DaemonDocumentation=http://zookeeper.apache.orgRequires=network.targetAfter=network.target[Service]Type=forkingWorkingDirectory={{ home_dir }}/zookeeperUser={{ user_name }}Group={{ user_name }}ExecStart={{ home_dir }}/zookeeper/bin/zkServer.sh start {{ home_dir }}/zookeeper/conf/zoo.cfgExecStop={{ home_dir }}/zookeeper/bin/zkServer.sh stop {{ home_dir }}/zookeeper/conf/zoo.cfgExecReload={{ home_dir }}/zookeeper/bin/zkServer.sh restart {{ home_dir }}/zookeeper/conf/zoo.cfgTimeoutSec=30Restart=on-failure[Install]WantedBy=default.target
在 tasks/main.yml 中定义将模板文件渲染为 systemd 单元文件的任务:
- name: render systemd unit file taskansible.builtin.template:src: zookeeper.service.j2dest: /usr/lib/systemd/system/zookeeper.service
35.4.2.7 设置防火墙
需要在 Firewalld 上开启 Zookeeper 服务的相关端口。编辑 tasks/main.yml 文件,添加以下任务:
- name: turn on zk ports in the firewalld taskansible.builtin.firewalld:port: "{{ item }}"permanent: trueimmediate: truestate: enabledwith_items:- "{{ client_port }}/tcp"- "{{ follower_port }}/tcp"- "{{ leader_port }}/tcp"
35.4.2.8 设置 JAVA_HOME
Zookeeper 在启动时,需要为其指定 JAVA_HOME 变量。编辑 tasks/main.yml 文件,添加在 zkEnv.sh 文件中设置该变量的任务:
- name: set JAVA_HOME in zkEnv.sh file taskansible.builtin.lineinfile:path: "{{ home_dir }}/zookeeper/bin/zkEnv.sh"line: "export JAVA_HOME=/opt/jdk19"insertafter: "/usr/bin/env"
JAVA_HOME 变量的值要设置为真实值,通过 “Linux 9 自动化部署 JDK” 安装的 JDK,路径为 /opt/jdk19。
35.4.2.9 启动 Zookeeper 集群
安装和配置已经进行完成,可以启动 Zookeeper 服务了。编辑 tasks/main.yml 文件,添加启动任务:
- name: enable and start the zk service taskansible.builtin.systemd:name: zookeeper.servicestate: startedenabled: truedaemon_reload: true
在这个任务中,会重载单元文件,启动 zookeeper 服务,并把该服务设置为开机启动。
35.4.2.10 添加 Handlers
在 handlers/main.yml 文件中,添加名为 ”restart zookeeper service handler“ 的 Handlers:
---# handlers file for deploy_zookeeper- name: restart zookeeper service handleransible.builtin.systemd:name: zookeeper.servicestate: restarted
35.4.3 创建部署 Zookeeper 的 Playbook
创建 ~/playbooks/deploy_zookeeper/deploy.yaml 文件,内容如下:
---- name: deploy zookeeper cluster playhosts: zookeeperbecome: truegather_facts: truevars_files:- variables.yamlroles:- role: deploy_zookeepertags: deploy_zookeeper...
Playbook 文件中用到了 variables.yaml 变量文件,在该文件中添加需要的变量。
35.4.4 提供变量
vars/variables.yaml 文件内容如下:
download_path: ~/software/zookeeper_tools/zookeeperdownload_url: https://downloads.apache.org/zookeeper/stable/apache-zookeeper-3.6.3-bin.tar.gzhome_dir: /opt/zkuser_name: zkclient_port: 2181follower_port: 2888leader_port: 3888
35.4.5 部署集群
执行 deploy.yaml Playbook 文件,部署 Zookeeper 集群:
ansible-playbook deploy.yaml35.5 验证 Zookeeper
在集群成功部署后,可以对集群进行测试。
登录 Zookeeper 集群的某个节点,执行 zkCli.sh 命令:
ssh zk1.server.aiops.redsudo su -/opt/zk/zookeeper/bin/zkCli.sh -server zk2.server.aiops.red:2181
执行以下命令,创建、查看、删除 znode:
# 创建create /hello "aiops"# 查看get /hello# 删除delete /hello
图 35.10 验证 Zookeeper 集群
znodes 是 ZooKeeper 中的基本抽象,类似于文件系统上的文件和目录。ZooKeeper 将其数据维护在分层命名空间中,znodes 是该命名空间的数据寄存器。
成功测试了两个 ZooKeeper 节点之间的连接。还通过 create、get 和 delete znodes 学习了基本的 znode 管理。Zookeeper 集群已成功部署,可以使用 ZooKeeper 了。
35.6 自动化监控 Zookeeper
本节讨论 Zookeeper 的自动化监控。监控服务使用 Prometheus 完成,因此需要准备好 Prometheus 监控系统。可参考上一篇文章完成 Prometheus 的自动化部署。
35.6.1 启用 MetircsProvider
从 3.6.0 版本开始,Zookeeper 内置的指标系统提供了丰富的指标,方便用户对其监控。编辑 Zookeeper 模板配置文件 templates/zoo.cfg.j2,添加 metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider:
tickTime=2000dataDir={{ home_dir }}/data/zookeeperclientPort={{ client_port }}maxClientCnxns=60initLimit=10syncLimit=5{% for host in groups['zookeeper'] %}server.{{ hostvars[host].ansible_local.zk.var['sid'] }}={{ host }}:{{ follower_port }}:{{ leader_port }}{% endfor %}metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
该配置启用了 Prometheus MetricsProvider,Zookeeper 服务将新增对 TCP 7000 端口的监听。
编辑 Zookeeper Role tasks/main.yml,在 firewalld 任务增加 7000 端口:
- name: turn on zk ports in the firewalld taskansible.builtin.firewalld:port: "{{ item }}"permanent: trueimmediate: truestate: enabledwith_items:- "{{ client_port }}/tcp"- "{{ follower_port }}/tcp"- "{{ leader_port }}/tcp"- "7000/tcp"
再次运行 Playbook 使配置文件生效:
ansible-playbook deploy.yaml35.6.2 Prometheus 收集 Zookeeper 指标
创建名为 zk_monitor.yaml Playbook 文件,添加以下任务向 Prometheus 的配置文件插入抓取 Zookeeper 目标的配置:
- name: zk monitor playhosts: prometheusbecome: truegather_facts: falsetasks:- name: insert scrape zk block taskansible.builtin.blockinfile:path: /opt/monitor/prometheus/prometheus.yamlinsertafter: EOFmarker: "# add zk scrape {mark}"marker_begin: "begin ==>"marker_end: "end ==>"create: truestate: presentblock: |2- job_name: "zk"static_configs:- targets:{% for host in groups["zookeeper"] %}- "{{ host }}:7000"{% endfor %}notify: restart prometheus service handler
ansible.builtin.blockinfile 任务将在 promethues.yaml 文件末尾添加抓取 Zookeeper 指标的配置。
有了指标,接下来配置 Dashboard。
35.6.3 配置 Zookeeper Dashboard
在 zk_monitor.yaml 文件中,新增下载 Grafana Dashboard 的任务。因为 Grafana 与 Prometheus 是同一主机,因此该任务与 “insert scrape zk block task” 任务定义在同一 Play 中:
- name: downlaod zookeeper dashboard json file taskansible.builtin.get_url:url: https://grafana.com/api/dashboards/10465/revisions/4/downloaddest: /var/lib/grafana/dashboard/zookeeper.json
35.6.4 配置报警规则
创建 files/ 目录,并在该目录下创建规则文件 zk_rule.yml,内容如下:
groups:- name: zk-alert-examplerules:- alert: ZooKeeper server is downexpr: up == 0for: 1mlabels:severity: criticalannotations:summary: "Instance {{ $labels.instance }} ZooKeeper server is down"description: "{{ $labels.instance }} of job {{$labels.job}} ZooKeeper server is down: [{{ $value }}]."- alert: create too many znodesexpr: znode_count > 1000000for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} create too many znodes"description: "{{ $labels.instance }} of job {{$labels.job}} create too many znodes: [{{ $value }}]."- alert: create too many connectionsexpr: num_alive_connections > 50 # suppose we use the default maxClientCnxns: 60for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} create too many connections"description: "{{ $labels.instance }} of job {{$labels.job}} create too many connections: [{{ $value }}]."- alert: znode total occupied memory is too bigexpr: approximate_data_size /1024 /1024 > 1 * 1024 # more than 1024 MB(1 GB)for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} znode total occupied memory is too big"description: "{{ $labels.instance }} of job {{$labels.job}} znode total occupied memory is too big: [{{ $value }}] MB."- alert: set too many watchexpr: watch_count > 10000for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} set too many watch"description: "{{ $labels.instance }} of job {{$labels.job}} set too many watch: [{{ $value }}]."- alert: a leader election happensexpr: increase(election_time_count[5m]) > 0for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} a leader election happens"description: "{{ $labels.instance }} of job {{$labels.job}} a leader election happens: [{{ $value }}]."- alert: open too many filesexpr: open_file_descriptor_count > 300for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} open too many files"description: "{{ $labels.instance }} of job {{$labels.job}} open too many files: [{{ $value }}]."- alert: fsync time is too longexpr: rate(fsynctime_sum[1m]) > 100for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} fsync time is too long"description: "{{ $labels.instance }} of job {{$labels.job}} fsync time is too long: [{{ $value }}]."- alert: take snapshot time is too longexpr: rate(snapshottime_sum[5m]) > 100for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} take snapshot time is too long"description: "{{ $labels.instance }} of job {{$labels.job}} take snapshot time is too long: [{{ $value }}]."- alert: avg latency is too highexpr: avg_latency > 100for: 1mlabels:severity: warningannotations:summary: "Instance {{ $labels.instance }} avg latency is too high"description: "{{ $labels.instance }} of job {{$labels.job}} avg latency is too high: [{{ $value }}]."- alert: JvmMemoryFillingUpexpr: jvm_memory_bytes_used / jvm_memory_bytes_max{area="heap"} > 0.8for: 5mlabels:severity: warningannotations:summary: "JVM memory filling up (instance {{ $labels.instance }})"description: "JVM memory is filling up (> 80%)\n labels: {{ $labels }} value = {{ $value }}\n"
将 zk_rule.yml 文件拷贝至 Prometheus 安装目录下:
- name: copy rule file to prometheus taskansible.builtin.copy:src: zk_rule.ymldest: /opt/monitor/prometheus/zk_rule.ymlowner: monitorgroup: monitor
在 Prometheus 配置文件 prometheus.yaml 插入引用 zk_rule.yml 规则文件的行:
- name: insert linelineinfile:path: /opt/monitor/prometheus/prometheus.yamlinsertafter: "rule_files:"line: " - zk_rule.yml"notify: restart prometheus service handler
在 zk_monitor.yaml 中定义 Handlers:
handlers:- name: restart prometheus service handleransible.builtin.systemd:name: prometheus.servicestate: restarted
最后执行 zk_monitor.yaml Playbook 文件:
ansible-playbook zk_monitor.yaml35.6.5 查看监控页面
登录 Grafana,查看 Dashboard,点击 “Zookeeper by Prometheus”,Cluster 选择 “zk”,浏览器将显示 Zookeeper 的监控页面:
图 35.13 Zookeeper 监控页面
在 Prometheus 的 rules 页面,能够看到为 Zookeeper 配置的报警规则,如下图:
图 35.14 Zookeeper 报警规则
35.7 总结
本教程演示了 Zookeeper 集群的自动化部署、简单的数据操作,以及通过 Prometheus 对 Zookeeper 集群进行监控。教程同样适用于其他基于 RPM 的 Linux 发行版。
