第三次作业
1、
| 结对使用的Github项目地址 | https://github.com/Cherish599/WordCount.git |
| 作业地址 | https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass2/homework/2879 |
| 结对伙伴的作业地址 |
2、我这次结对编程是和我室友胡杨帅一起进行的。我主要负责代码的编写部分,他负责测试部分。

PSP表格
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
20 | 22 |
|
· Estimate |
· 估计这个任务需要多少时间 |
||
|
Development |
开发 |
270 | 320 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
20 | 20 |
|
· Design Spec |
· 生成设计文档 |
||
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
||
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 | 20 |
|
· Design |
· 具体设计 |
||
|
· Coding |
· 具体编码 |
240 | 260 |
|
· Code Review |
· 代码复审 |
20 | 25 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
20 | 20 |
|
Reporting |
报告 |
||
|
· Test Report |
· 测试报告 |
10 | 10 |
|
· Size Measurement |
· 计算工作量 |
||
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
20 | 15 |
|
合计 |
400 | 432 |
3、计算模块接口的设计与实现过程:
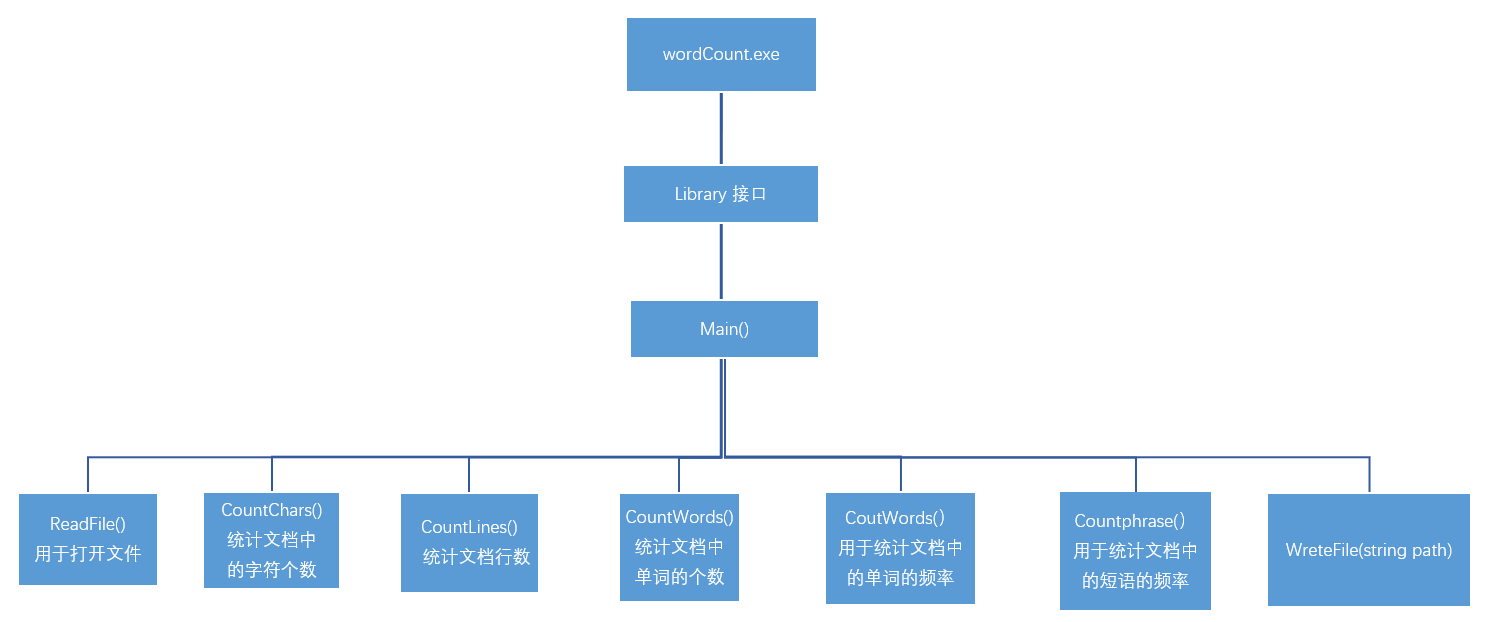
首先,我们俩先对这个项目进行了分工。我主要负责代代码编写这一块。经过我们俩的讨论,我们俩列出了一个程序的整体框架。对于程序的基本功能部分,由于比较简单,实现起来也不复杂。就分别写了几个函数,然后在Main()函数中调用即可。如下图所示:

对于解题思路:
在CountChars()这个函数中,我们把整个文档遍历了一遍,然后筛选每个Ascii码字符,并统计总的字符个数;
在Countlines()这个函数中,我们统计文章中的换行符,每统计一个,lines++;
在CountWords()这个函数中,我们先去掉了文档中的所有的特殊符号,然后把所有的字符转换成了小写,这样就不用区分大小写的问题了,然后遍历以空格来分隔每个单词;最后看每个单词是否至少以4个英文字母开头,跟上字母数字符号,如果满足条件,words++;
在CoutWords()这个函数中,因为要输出的是单词出现的频率,并且要输出前几个出现频率最高的单词和相应的频率,因为之前我做过相同功能的程序,上次做的就是用的字典类型,所以这次做这个功能有点经验。至于排序的问题,我之前是写了一个排序的方法,不过这次我了解到,原来C#的字典类型中有自带的排序的方法,这次就直接用了自带的方法。比上次实现好了很多。
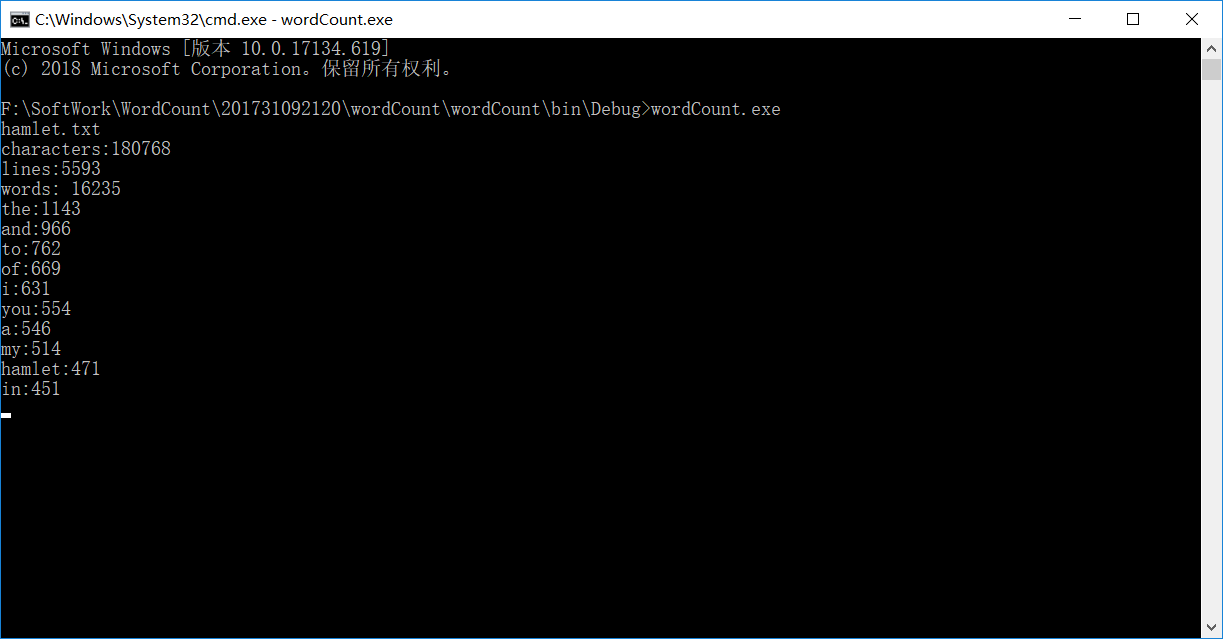
我们使用了著名的戏剧作品《哈姆雷特》英文版作为测试。运行结果如下:
接下来就是作业的第二个要求,用一个接口来封装不同功能的函数:
1 interface library 2 { 3 string ReadFile(string path); //用于打开文件 4 int CountChars(string text); //用于统计文档中的字符个数 5 int CountLines(string text); //用于统计文档行数 6 int CountWords(string Text); //用于统计文档中单词的个数 7 Dictionary<string, int> Countphrase(string text, int n); //用于统计文档中的短语的频率 8 Dictionary<string, int> CoutWords(string text, int n); //用于统计文档中的单词的频率 9 void WreteFile(string path); //用于创建一个文件,将统计结果保存在文件中 10 11 }
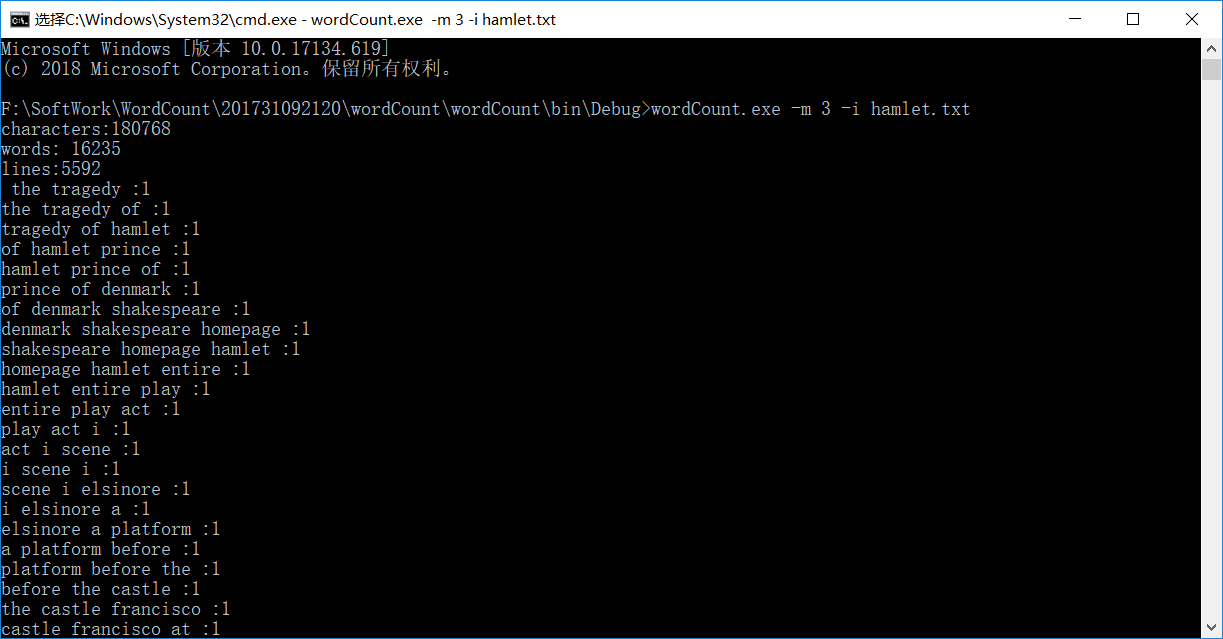
在第二步的基础上,我们便开始了第三个要求的编码。第三个要求是在cmd命令行中传入参数,然后按照不同的参数,实现不同的功能。并且在第一步的基础上增加了词组统计和自定义输出两个新的功能。词组的统计其实是和单词的统计是差不多的,还是要用到字典类型。我在Countphrase()中新增了一个数组,用来记录每一定长度的词组,然后统计它出现的频率。至于自定义输出功能,是比较简单的文件操作,就不在详细说明了。
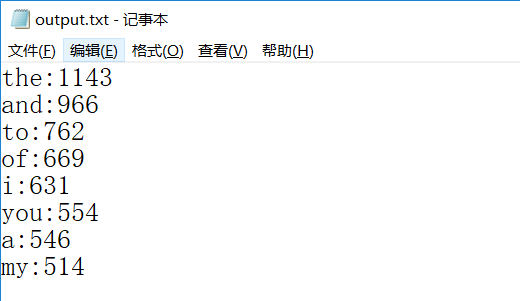
同样选著名戏剧作品《哈姆雷特》英文版,运行结果如下:(由于文本较长,没有将所有的词组全部截屏)

4、代码规范与代码复审过程 :
当我写完代码给胡杨帅看的时候,他看了之后给我提了几个意见。第一个就是代码空的行数太多的问题,使得代码看起来不怎么美观;其次就是代码的命名有一些不妥,尤其体现在变量名的命名上面。就像这样:
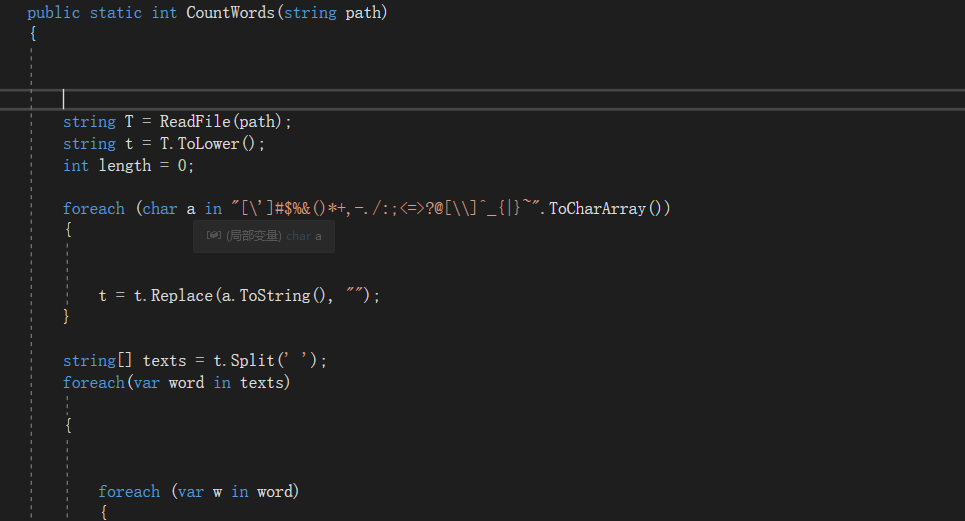
之后我对所有的代码进行了规范,严格按照邹欣老师书中的代码规范与代码复审的方法,把所有的代码都改了一遍。
5、 测试运行通过:
测试部分由胡杨帅完成
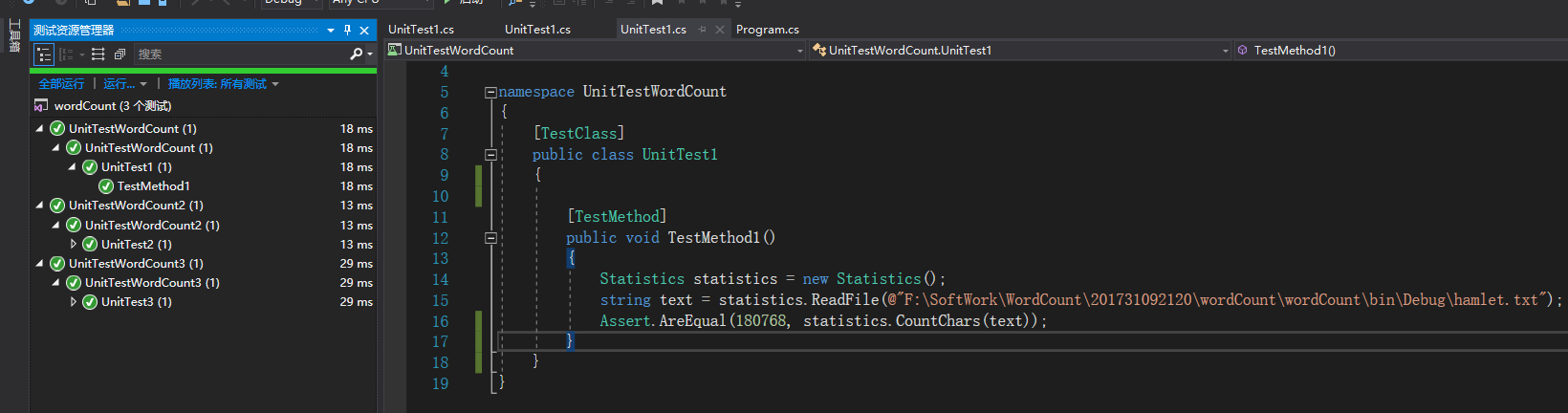
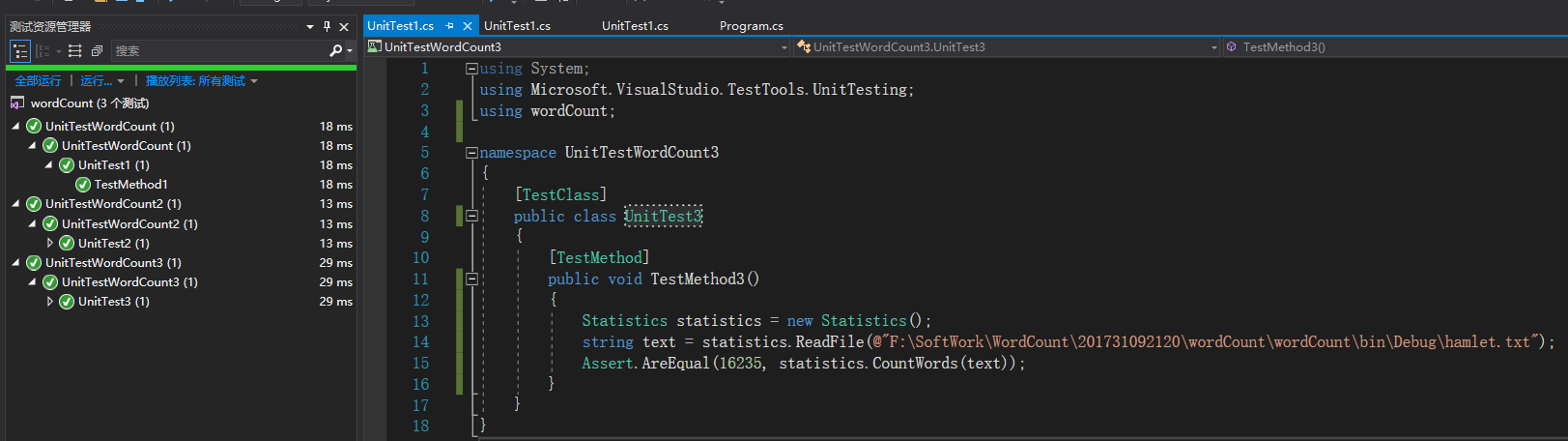
单元测试:(这次我们俩测试了几个重要的函数,可以看到全部通过)

性能测试:
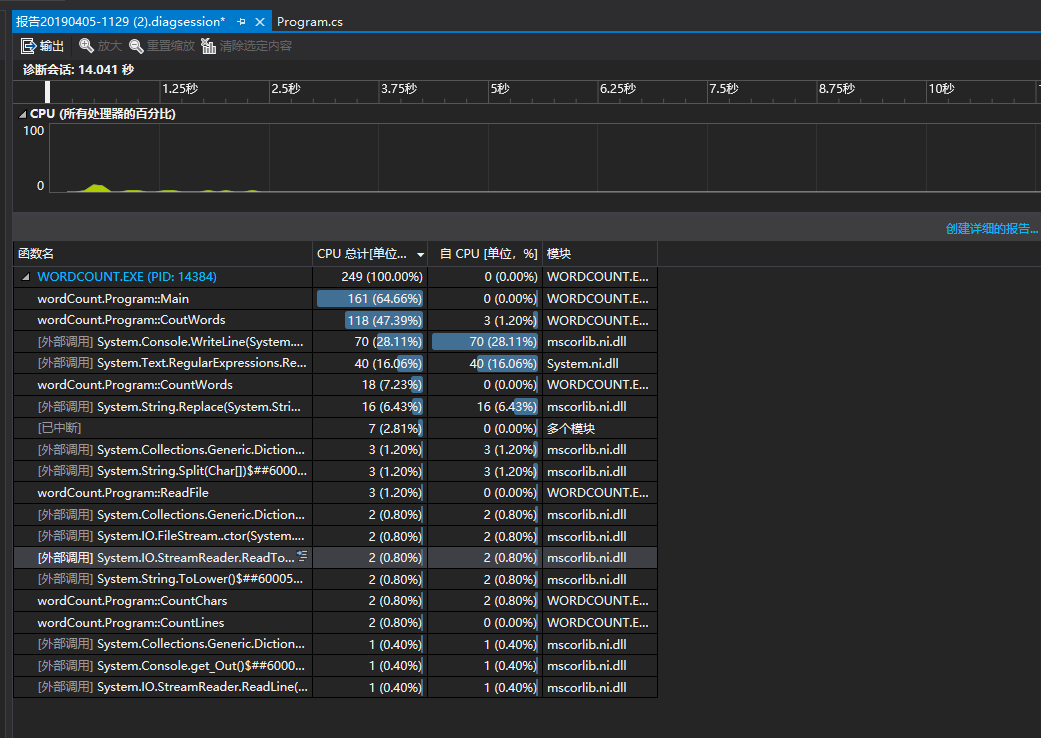
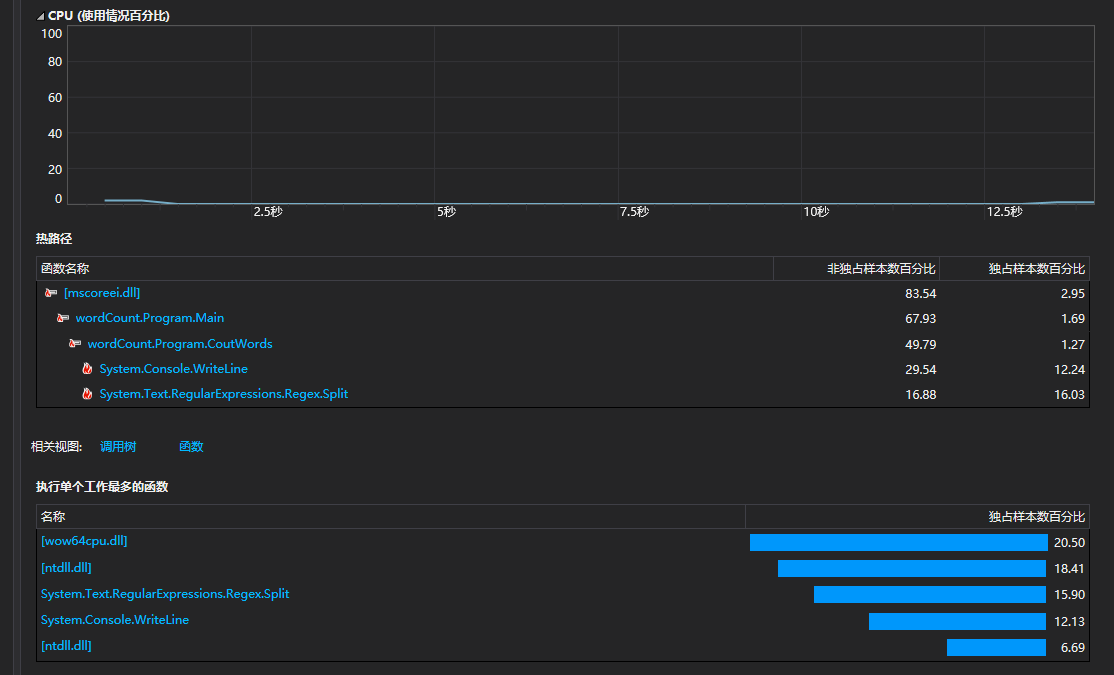
从上面的分析可以看到主程序和CoutWords()这个函数所消耗的CPU是最大的。这个也可以理解,一方面是因为CoutWords()这个函数是用来统计hamlet.txt中的所有单词的出现频率的,要不停的遍历整个文档,并且这个函数用到了字典类型。我暂时还没有想到更佳的优化方法。另一方面是因为hamlet.txt中有着数万个的单词,本身单词数量比较多。
6、git提交部分:(有了以上一次的经验之后,对git的使用相对还是比较熟练了)
这是对基础功能部分的提交:
这是增加新功能的一部分的提交:
7、总结:
结对编程确实能够在一定程度上提高两个人编程的效率。提高了更好的设计质量,毕竟两个人考虑的要比一个人全面一点。不过由于是第一次结对编程,我们俩在配合的过程中还出现了一点问题,比如说沟通方面的问题,有时候会为了一个不一致的意见争论半天。总体来说,本次结对编程还是比较成功的,确实是1+1>2。
posted on 2019-04-04 17:49 Cherish599 阅读(291) 评论(10) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号