第三章词法分析
词法分析
单词的形式化描述工具
- 基于生成观点、计算机观点和识别观点,分别形成了正规文法、正规式和有穷自动机\(3\)种用于描述词法的工具。
正规文法
设文法\(G= (V_N , V_T , P , S)\),如果任意\(A \to \beta \in P , A \in V_N\),且\(\beta\)只能是\(aB\)或\(a\)或\(\varepsilon\),则称文法\(G\)属于右线性\(3\)型文法。
正规式及其表达的语言
也称为正则表达式,其表达的语言称为正规集。
- 对给定的字母表\(\sum\)
- \(\varepsilon\)和\(\empty\)都是正规式,其正规集分别是\(\{\varepsilon\}\)和\(\empty\)
- \(\forall a \in \sum\),\(a\)是\(\sum\)上的正规式,其正规则集为\(\{a\}\)
- 如果\(r\)和\(s\)都是\(\sum\)上的正规式,则(算符优先级由高到低位:*,\(\cdot\) ,|)
- \((r)\)是正规式,它表示的正规集为\(L(r)\)
- \(r | s\)是正规式,它表示的正规集为\(L(r) \cup L(s)\)
- \(r \cdot s\)是正规式,它表示的正规集为\(L(r) \cdot L(s)\)
- \(r^*\)是正规式,它表示的正规集为\(L(r^*) = L(r)^*\)
- 有限次使用上述步骤而定义的表达式仍是正规表达式,它们表示的符号串的集合是正规集。
【例】:令\(\sum = \{a , b\}\),则\(\sum\)上正规式和对应的正规集如下:
| 正规式 |
正规集 |
|---|---|
| \(a\) | \(\{a \}\) |
| \(a|b\) | \(\{a , b\}\) |
| \(a b\) | \(\{ab\}\) |
| \((a|b)^*\) | \(\{a , b\}^*\) |
| \(a^*\) | \(\{\varepsilon , a , aa , ....\}\) |
| \((a|b)^*a\) | \(\{a , b\}^*\{a\}\) |
| \((a|b)(a|b)\) | \(\{aa , ab , ba , bb\}\) |
-
所有词法结构一般都可以用正规式描述
-
若两个正规式所表示的正规集相同,则称这两个正规式等价,如\(b(ab)^* = (ba)^*b\)。
-
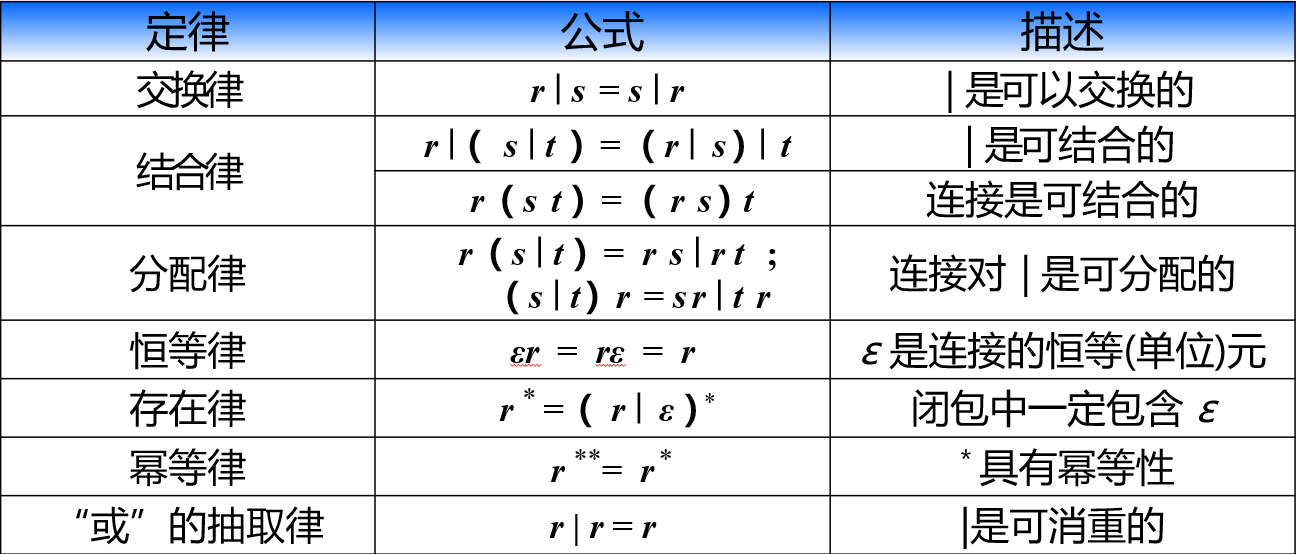
正规式的代数定律:设\(r , s , t\)为正规式,则有:
正规式和正规文法之间转换
- 如果正规式\(r\)和正规文法\(G\),有\(L(r)= L(G)\)则称正规式\(r\)和文法\(G\)是等价的。
正规式\(r\to\)文法\(G\)转换方法
-
设\(\sum\)上正规式\(r\),则等价文法\(G = (V_N , V_T , P , S)\)。其中\(V_T = \sum\);从形如产生式\(S \to r\)开始,按下表规则进行转换,直到全部形如产生式,符合正规文法指规则形式为止,可得到\(P , V_N\)。
-

-

正规文法转换成正规式
-
基本上是正规式到正规文法的逆过程,按下列规则将文法处理成只剩下一个开始符号定义的正规式。
-

-
注意此处规则\(2\)与前面的区别
-

有穷自动机
本质上和状态转换图相同,但有穷自动机只回答Yes/No。
分为两类:
- 不确定的有穷自动机
NFA:输入符号包括\(\varepsilon\),一个符号可以标记在离开同一状态的多条边上 - 确定的有穷自动机
DFA:输入符号不含\(\varepsilon\),每个状态以及每个符号最多只有一条边
两种自动机都识别正则语言,对于每个可以用正则表达式描述的语言,均可用某个NFA或DFA来识别;反之亦然。
确定的有穷自动机DFA
DFA形式化定义
-
确定有穷自动机
DFAM是一个五元组\(M = (K , \sum , f , S , Z)\),其中:- \(K\):有穷状态集。
- \(\sum\):输入字母表(有穷),输入符号集。
- \(f\):状态转移函数,为\(K \times \sum \to K\)的单值部分映射,\(f(k_i , a) = k_j\)表示:当现行状态为\(k_i\);输入字符为\(a\)时,将状态转移到下一状态\(k_j\),\(k_j\)称为\(k_i\)的一个后继状态。
- \(S \in K\):初始状态。
- \(Z \subseteq K\):终态集,也称可接受状态或结束状态。
DFA的扩展状态转移函数
-
\(f^{'}:K \times \sum^* \to K\)映射。设\(a \in \sum,\beta \in \sum^* , q \in K\),即(\(q \in K , f^{'}(K\;k , \sum^* t)\))
\[f'(q , a\beta) = \begin{cases} f(q , a)\; \beta = \varepsilon\\ f'(f(q , a) , \beta)\;\beta \neq \varepsilon \end{cases} \] -
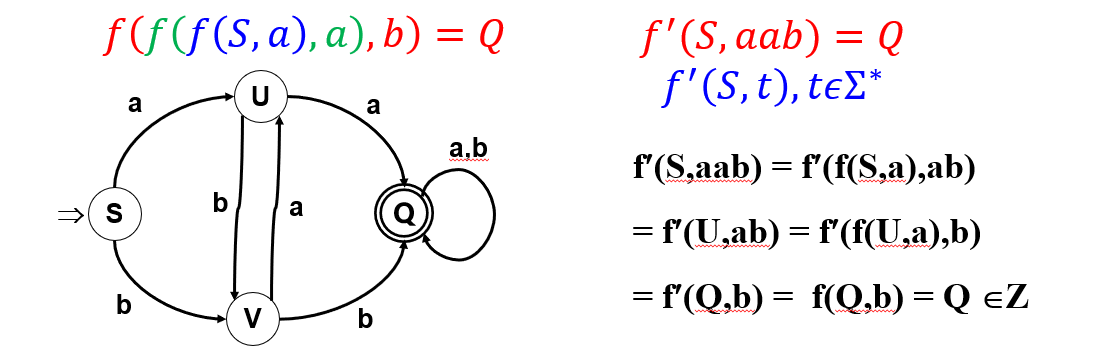
DFA识别的语言
-
设
DFA M= \((K , \sum , f , S , Z)\),如果\(\alpha \in \sum^* , f'(S , \alpha) \in Z\),则称符号串\(\alpha\)是DFA M所接受(或识别)的。DFA M所接受的符号串的集合记为\(L(M)\):\[L(M) = \{\alpha | \alpha \in {\sum} ^* , f'(S , \alpha) \in Z \} \] -
\(\sum\)上的一个符号串集\(V \subseteq \sum^*\)是正规的,当且仅当存在一个\(\sum\)上的
DFA,使得\(V = L(M)\)。
非确定有穷自动机NFA
一个非确定有穷自动机NFA M是一个五元组\(M = (K , \sum , f , S , Z)\),其中:
- \(K\):有穷状态集。
- \(\sum\):输入字母表(有穷)。
- \(f\):状态转移函数,为\(K \times (\sum \cup \{\varepsilon\}) \to P(K)\)的部分映射,\(P(K)\)表示\(K\)的幂集。
- \(S \subseteq K\):初始状态
- \(Z \subseteq K\):终态集
【例】
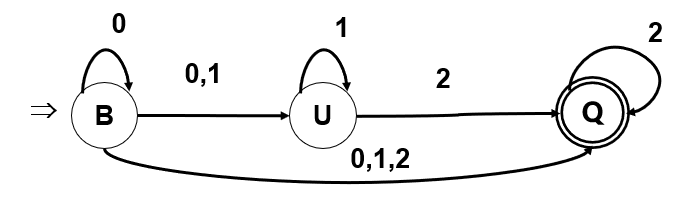

NFA扩展状态转移函数:\(f(q , a)\to Move(I , a) \to f'(I , t)\)
\(f': P(K) \times \sum^* \to P(K)\)映射。
设\(a \in \sum , t , \beta \in \sum^* , I \sub K\),即:
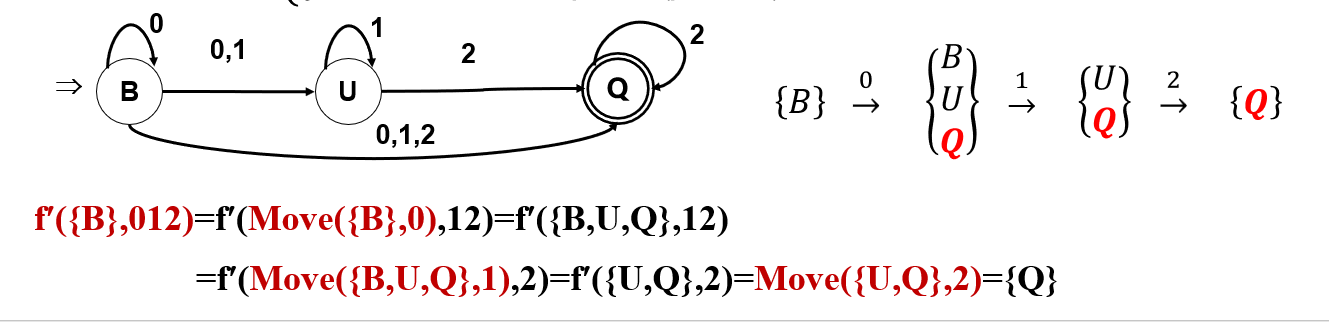
NFA识别的语言
设NFA M = \((K , \sum , f , S , Z)\),如果\(\alpha \in \sum^*,f'(S , \alpha) \cap Z \neq \empty\),则称符号串\(\alpha\)是NFA M所接受(或识别)的。NFA M所接受的符号串的集合亦记为\(L(M)\),即:
自动机的等价
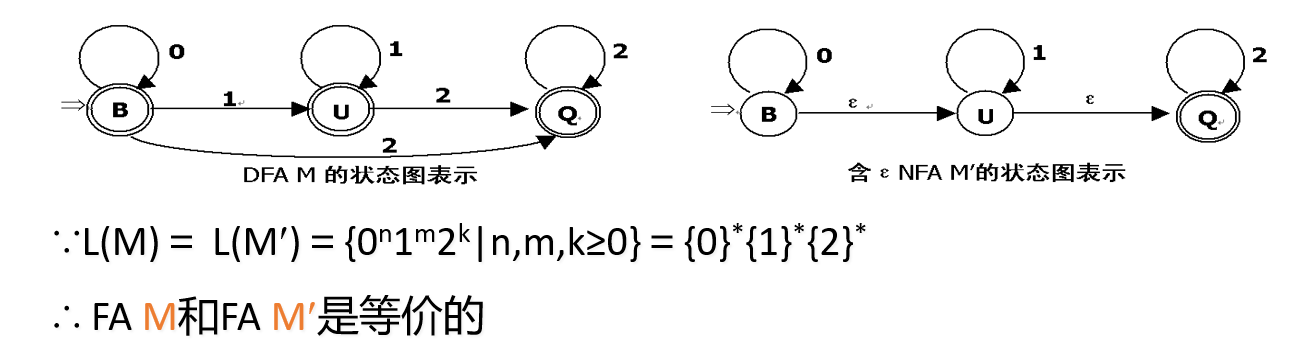
对于任何两个有穷自动机\(M\)和\(M'\),如果\(L(M) = L(M')\),则称\(M\)与\(M'\)等价。
对于每个NFA M存在一个DFA M,使得\(L(M) = L(M')\),反之亦然。
DFA与NFA描述能力相同
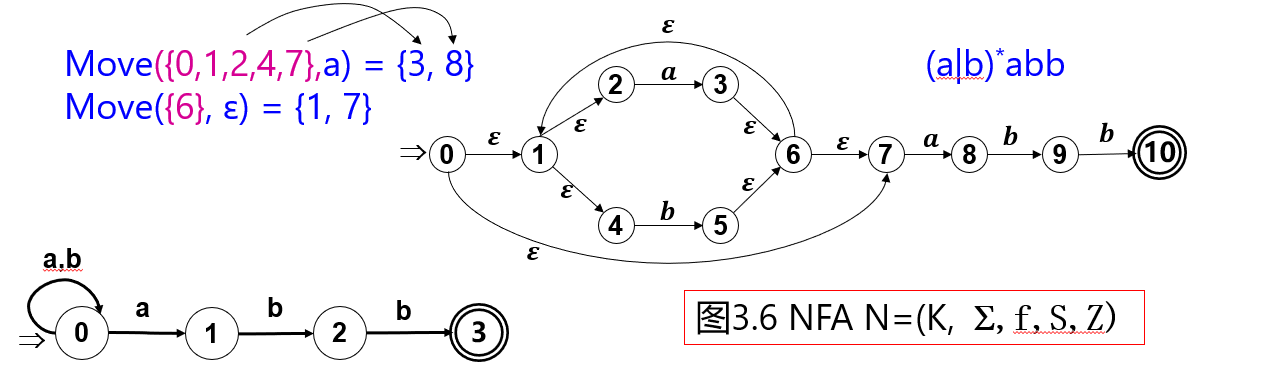
状态集I的转换运算
设NFA M = \((K , \sum , f , S , Z), I \sub K , a \in \sum \cup \{\varepsilon\}\),则\(Move(I , a)\)定义如下:
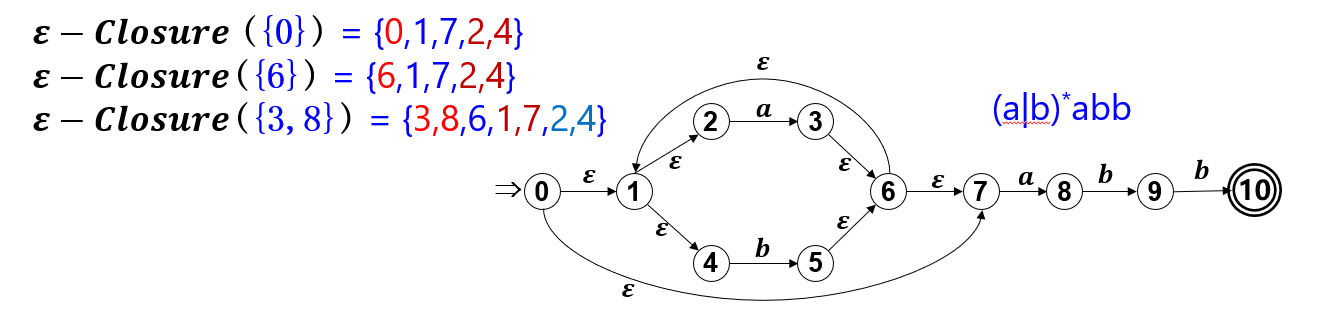
状态集\(I\)的\(\varepsilon - Closure(I)\)
设NFA M = \((K , \sum , f , S , Z) , I \sub K\),则\(\varepsilon - Closure(I)\)定义如下:
- \(\varepsilon - Closure(I) = I\)
- \(\varepsilon - Closure(I) = \varepsilon - Closure(I) \cup Move(\varepsilon - Closure(I) , \varepsilon)\)
- 重复上一步,直到\(\varepsilon - Closure(I)\)不再扩大为止。
NFA到DFA的转换算法(子集构造法)
-
输入:
NFA N= \((K , \sum , f , S_0 , Z)\) -
输出:等价的
DFA D= \((D , \sum , g , S = \varepsilon - Closure(\{S_0\}) , F)\);\(g(T , a) = \varepsilon - Closure(move(T , a)) = U\)。 -
方法:一开始\(\varepsilon - Closure(\{S_0\})\)是\(D\)中的唯一状态,且它未加标记:
while(在D中有一个未标记状态T){ 给T加上标记; for(每个输入符号a){ U = ε-closure(move(T , a)); if(U不在D中) 将U加入D中,且不加标记; Dtran[T , a] = U; } } -
\(F = \{q | q \in D , q \cap Z \neq \empty\}\)
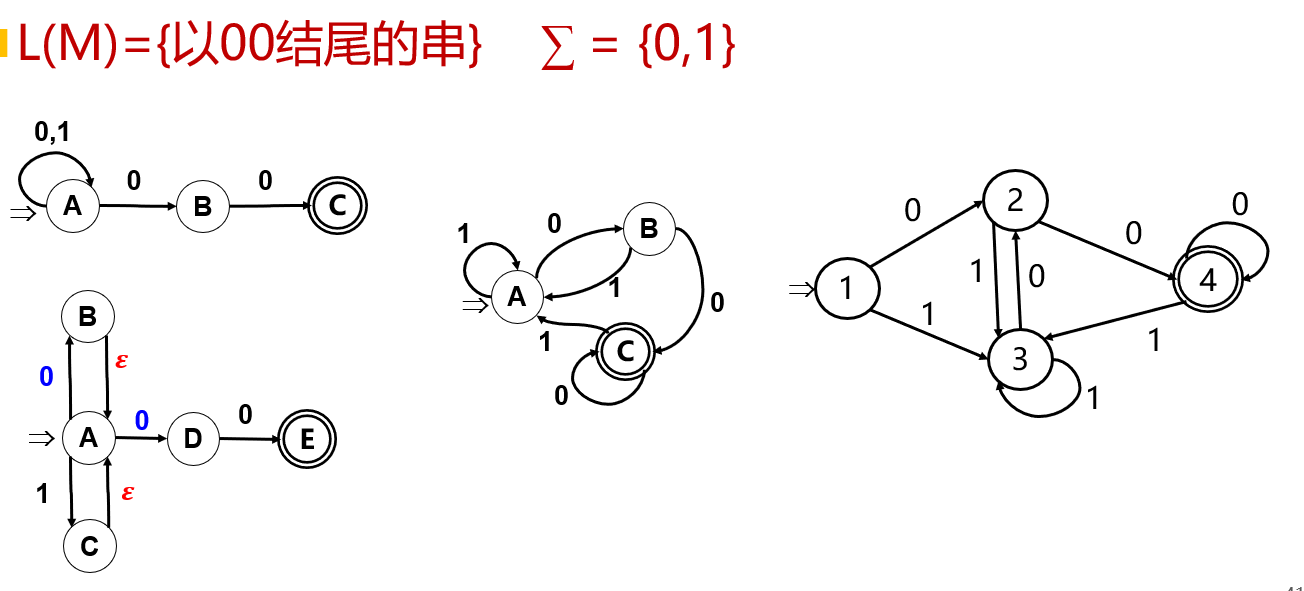
【例】
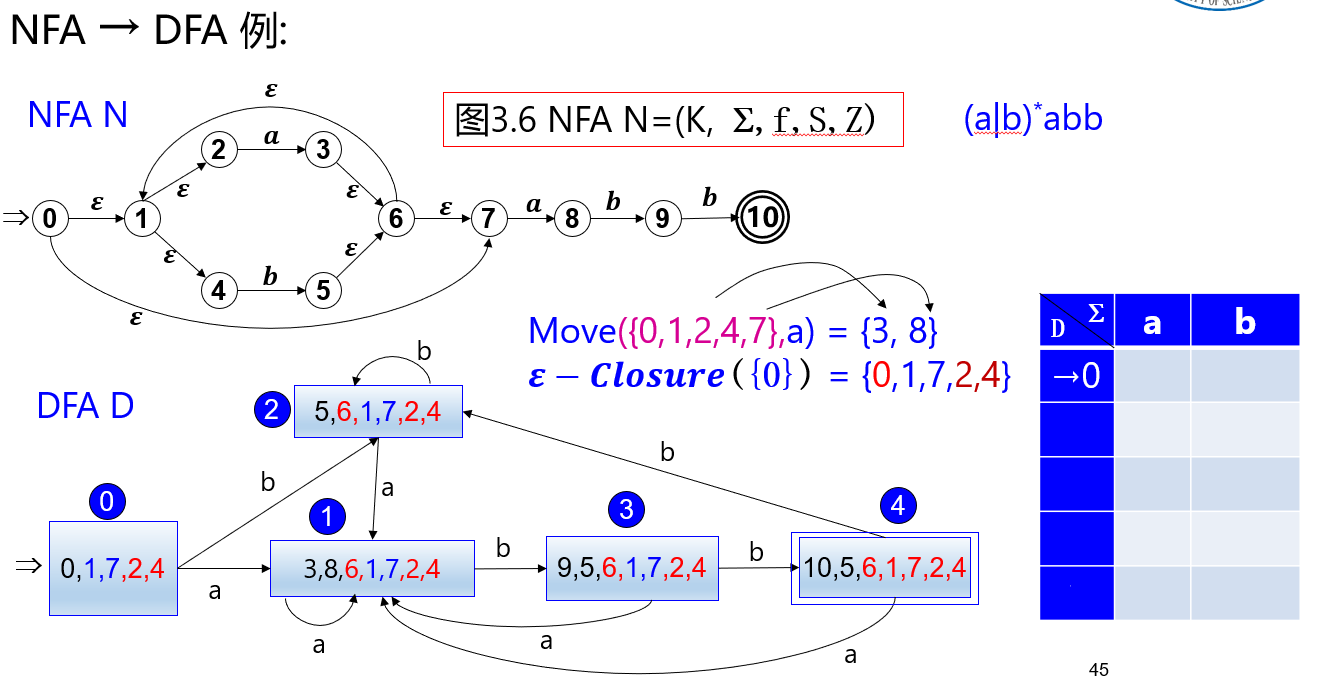
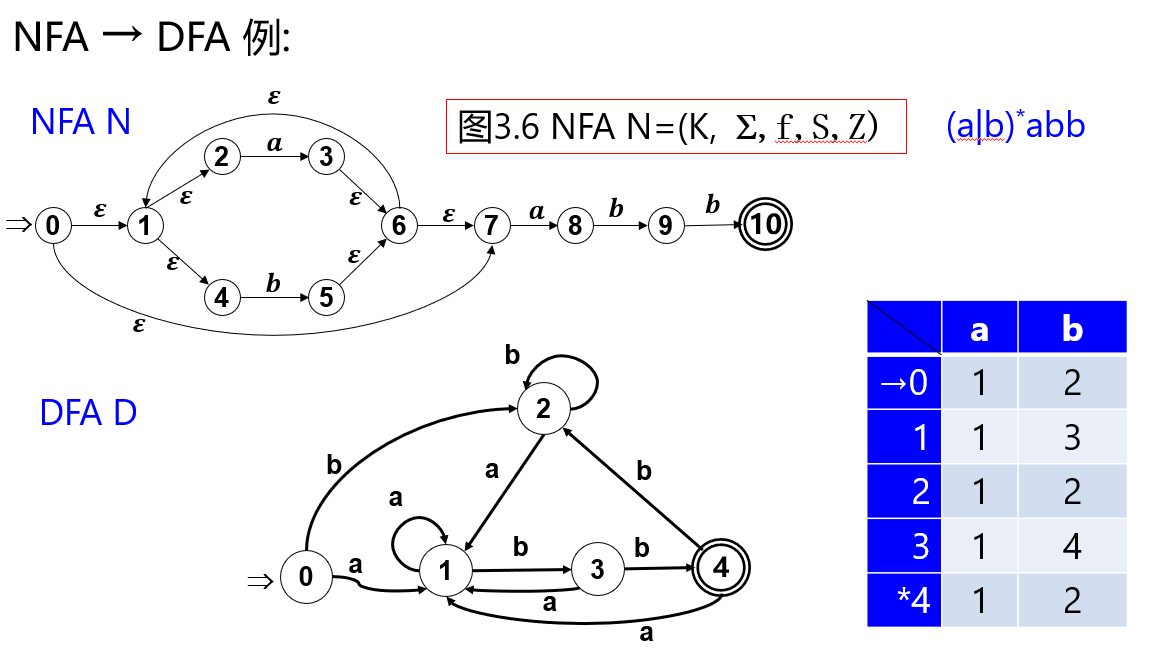
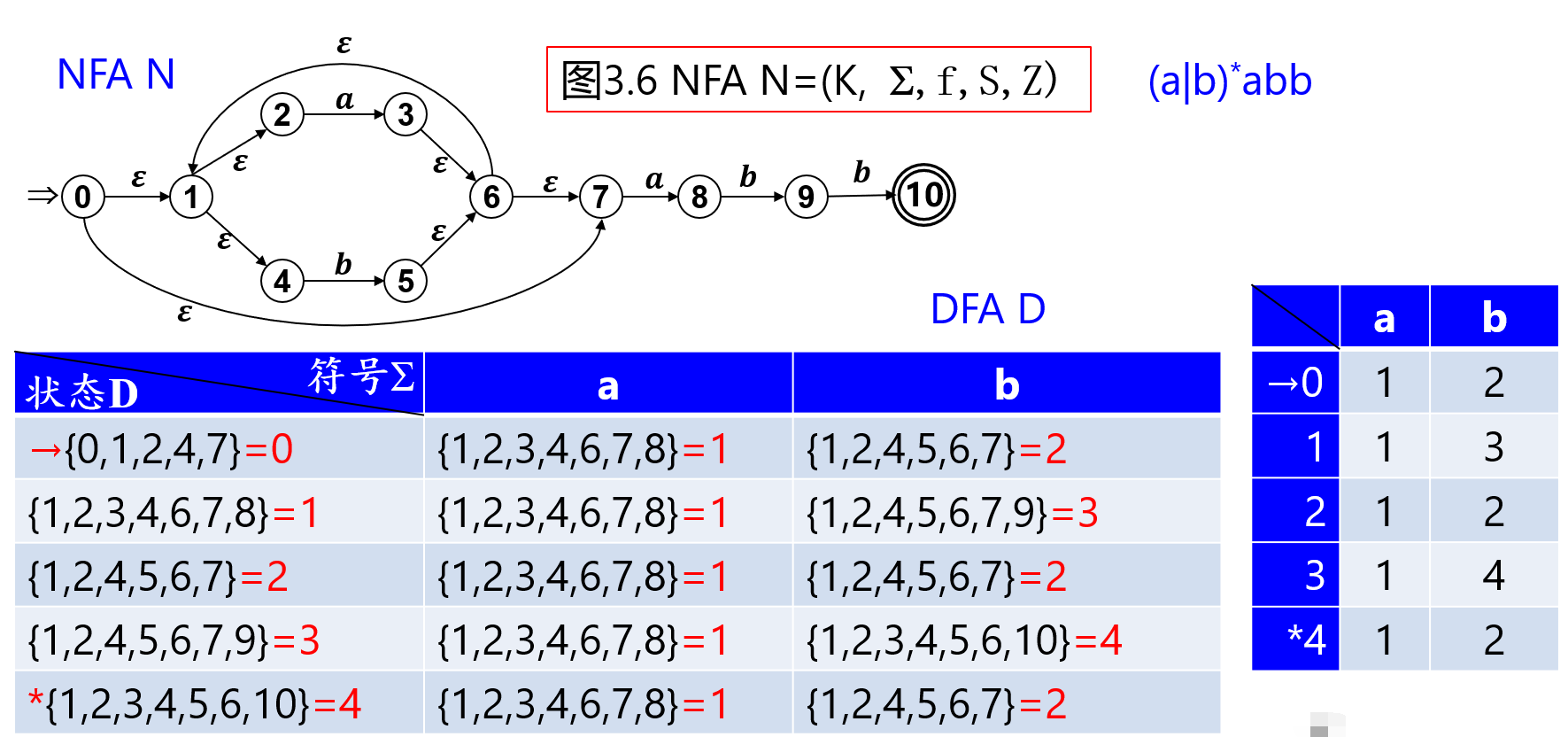
DFA的化简
消除无用状态;无用状态是指不可达,没有通路到达终态。
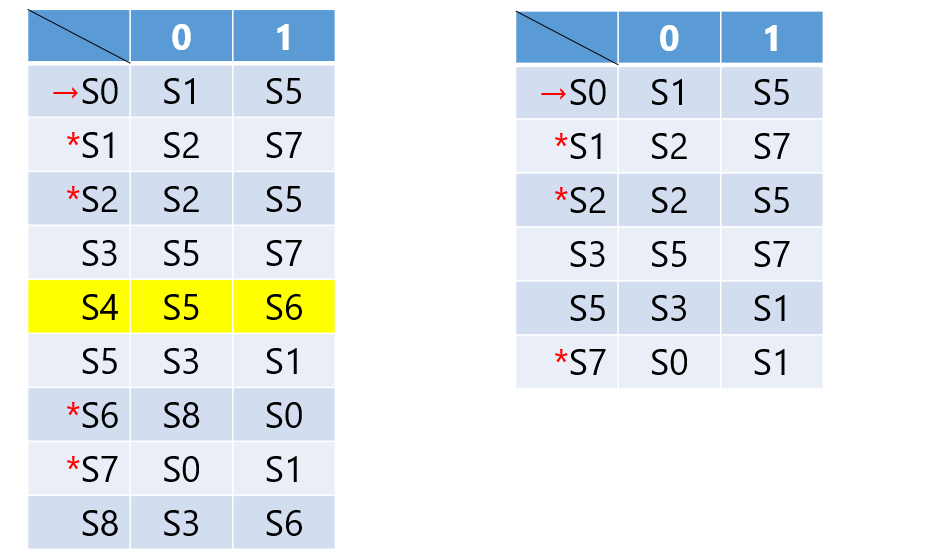
合并等价状态:
- 一致性条件:\(p\)和\(q\)同时是可接受状态或不可接受状态
- 蔓延性条件:对所有输入符号,\(p\)和\(q\)必须转移到等价的状态中。
方法:分割法——状态被分成不同子集,不同的子集不等价,同一子集等价
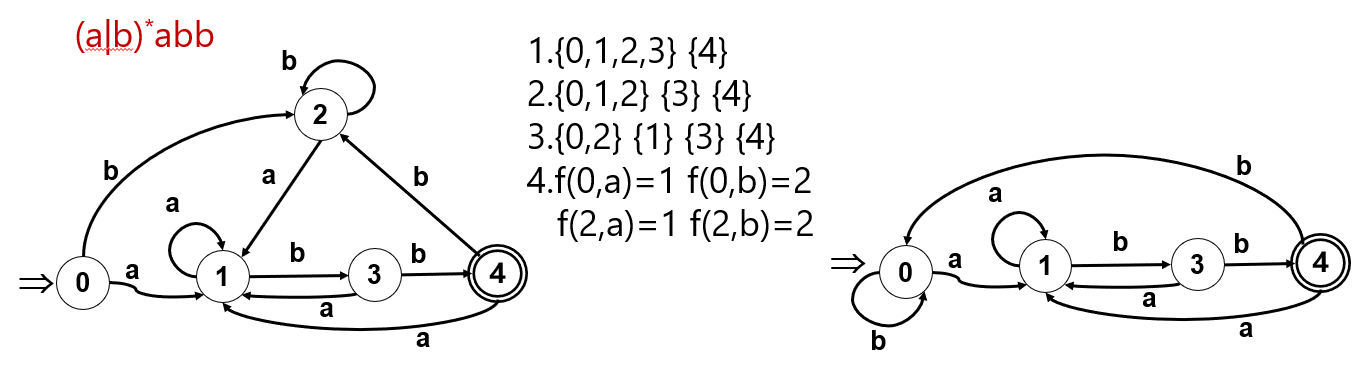
DFA最小化:

正规式和有穷自动机的等价性
对于\(\sum\)上的NFA M,可以构造一个\(\sum\)上的正规式\(r\),使得\(L(r) = L(M)\)。
对于\(\sum\)上的每一个正规式\(r\),可以构造一个\(\sum\)上的NFA M,使得\(L(M) = L(r)\)
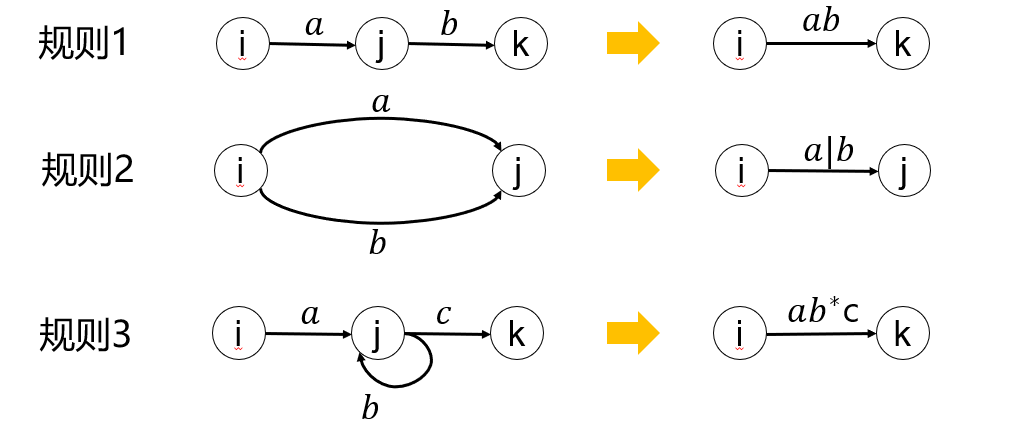
NFA M \(\to\) 正规式\(r\)
\(M = <S , \sum , \delta , S_0 , F>\),对\(M\)的状态转移图进行以下改造:
-
新增两个状态\(X , Y\),作为开始状态和接受状态,且将\(X\)经\(\varepsilon\)指向\(M\)的所有开始状态,将\(M\)的所有接受状态经\(\varepsilon\)指向\(Y\),得到\(M'\),显然有\(L(M') = L(M)\)。
-
反复使用下面的三条规则,逐步消去结点,直到只剩下\(X , Y\)为止。\(X\)到\(Y\)的弧上标记的符号串,即为\(\sum\)上等价的正规式\(r\)。
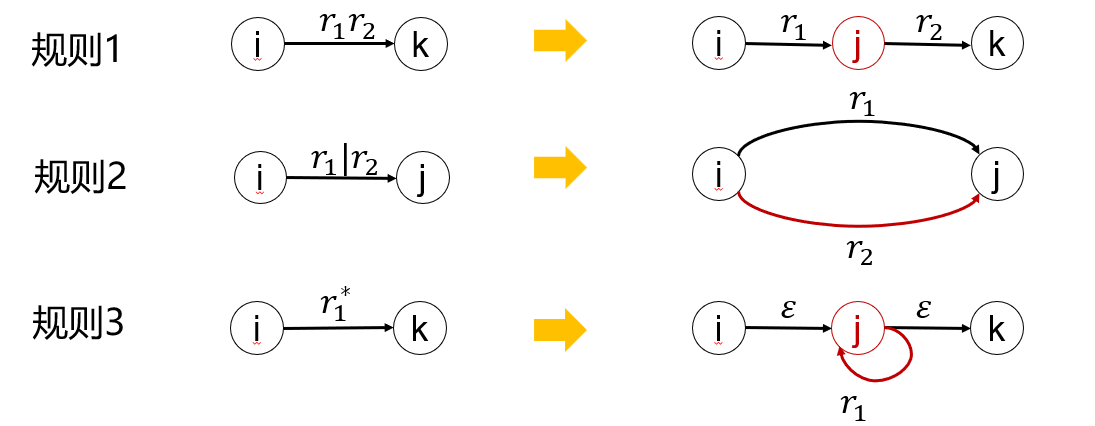
正规式\(r\to\) NFA M
-
首先把\(r\)表示成:
-
按下面的规则对\(r\)进行分裂:
-
直到每条弧上只剩单个符号\(a \in \sum \cup \{\varepsilon\}\)。
【例】
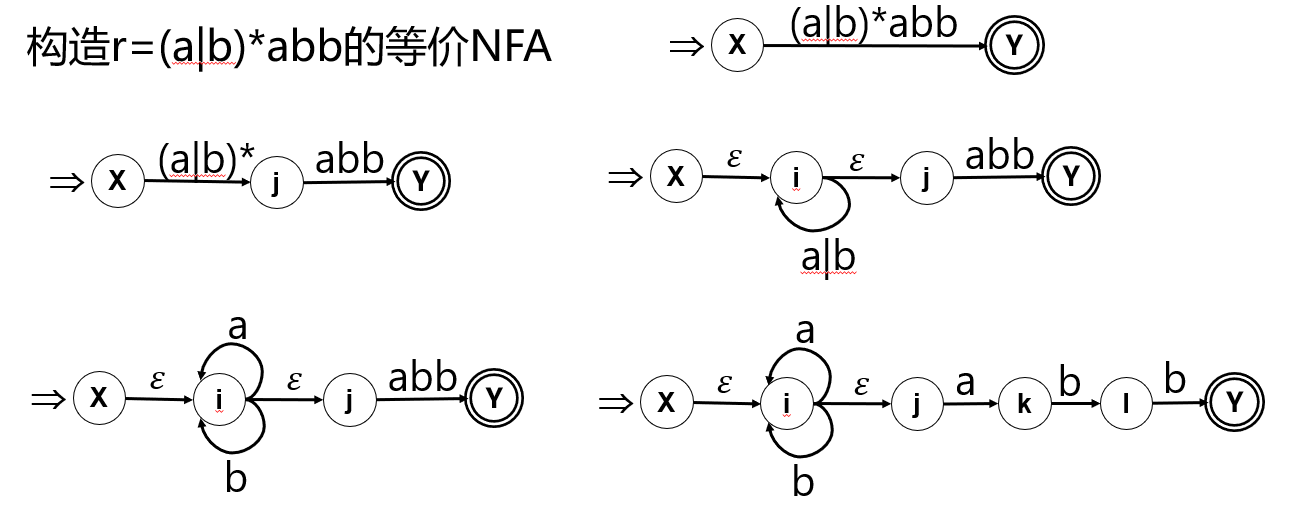
正规文法和有穷自动机的转换
- \(\forall\)正规文法\(G,\exists NFA\;M\),使得\(L(M) = L(G)\)。
- \(\forall NFA\;M , \exists\)正规文法\(G\),使得\(L(M) = L(G)\)。
正规文法\(G\to\) NFA M
- 设\(G = (V_N , V_T , P , S)\)
- \(M\)的字母表\(\sum = V_T\);
- \(G\)的每个非终结符是\(M\)的一个状态;
- \(G\)的开始符\(S\)是\(M\)的开始状态\(S\);
- 增加一个新状态\(Z\),作为\(M\)的终态;
- \(M\)的状态转移函数\(f\):
- 如果\(A \to a \in P , f(A , a) = Z\);
- 如果\(A \to \varepsilon \in P , f(A , \varepsilon) = Z\);
- 如果\(A \to aB \in P , f(A , a) = B\);
【例】
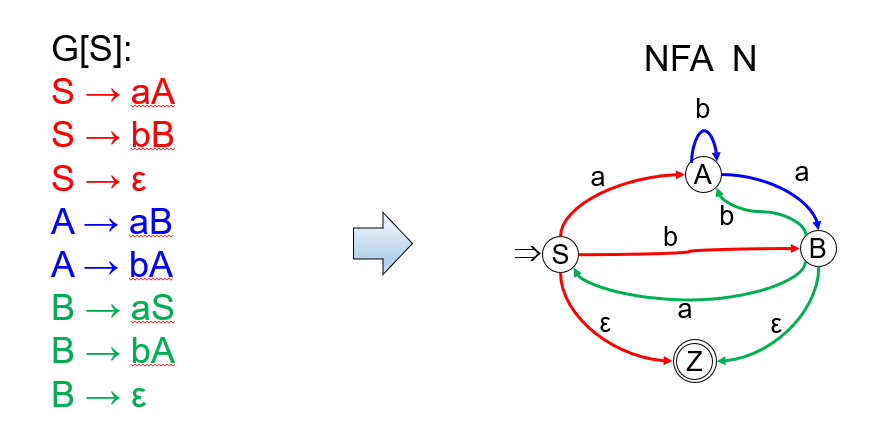
NFAM \(\to G\)
有穷自动机\(M = (K , \sum , f , S , Z) \to\)正则文法\(G = (K , \sum , P , S)\)
- 必要时确定化\(M\)(如果\(M\)含有\(\varepsilon\)转移)
- \(G\)的产生式\(P\)由下列方法构造:
- 如果\(f(B ,a) = C,B \to aC\);
- 对可接受态\(Z\),增加产生式\(Z \to \varepsilon\);
- 如果\(f(B , a) = C\),\(C\)为终态且非始态又无出边,可直接\(B \to a\)。
【例】
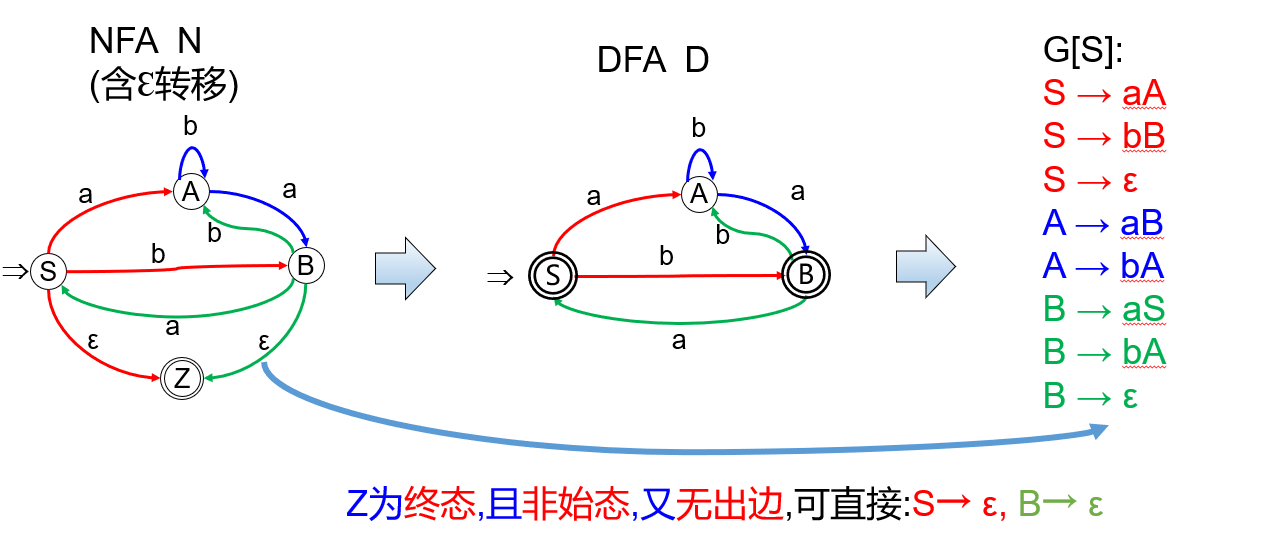
作者:cherish.
出处:https://home.cnblogs.com/u/cherish-/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号