第二章 文法和语言
作者:@cherish.
课程学习内容为作者从学校的PPT处摘抄,仅供自己学习参考,若需转载请注明出处:https://www.cnblogs.com/cherish-/p/16370380.html
文法和语言
符号和符号串
-
字母表:字母表是非空有穷集合,其元素称为符号。
-
符号串:由字母表中的符号组成的有穷序列称为(字母表上的)符号串。不含任何符号的有穷序列称为空串,记为。
-
规则:以某种形式表达的在一定范围内共同遵守的章程和制度;这里指符号串的组成规则。
例如:设字母表,则是上的符号串,不是上的符号串。
-
符号串长度:符号串的长度是指符号串中含有符号的个数,记为。特别约定空串为零,即。
-
符号串集合:如果集合的元素都是字母表上的符号串,则称集合为上的符号串集合,简称串集。
例如:设字母表,则是上的符号串集合,不是上的符号串集合。
运算
-
符号串的运算:
设为两个符号串,则:
-
连接:,如
-
或:
-
方幂:。注意:。
-
闭包:
的正闭包:
的星闭包:
-
-
符号串集合的运算:
设为两个符号串集合,则:
-
乘积:
-
和:
-
方幂:。注意:。
-
闭包:
的正闭包:
的星闭包:
-
推论:若为任一字母表,则就是该字母表上的所有符号串(包括空串)的集合。
-
文法和语言的形式化定义
什么是“形式化定义”?
- 对文法的一种精确的数学定义
- 定义的“文法”,“句子”等概念,虽然可以和自然语言的对应概念类比,但它们有严格的数学基础,可以被计算机处理。
文法的形式化定义包含哪些内容?
- 文法的生成规则(<主语> := <名词>|<代词>)
- 文法使用的非终结符(代词)
- 文法使用的终结符
- 文法的开始符号
定义:文法定义为一个四元组,记为。其中:
- 是非空有穷集合,称为非终结符集,其元素称为非终结符;
- 是有穷集合,称为终结符集,其元素称为终结符;
- 是非空有穷集合,称为规则集,其元素是字母表上的规则,称为文法的字母表,且;
- ,称为开始符。
字母表上的规则:(重写规则、产生式、生成式)
简记为。规则的左部,称为规则的右部。
是空规则
左部相同的多个规则,可以使用符号简写。如:
- 可简写为。
【例】定义文法如下:,其中:。
上式亦可写成如下形式:
【例】:文法定义如下:
这个文法表达的语言是什么?。
直接推导
设文法,如果中包含,那么任意的串可以推导出,我们把这种推导称为直接推导或一步推导,记为。。
直接规约
如果,我们也可以说规约 到,这种规约称为直接归约或一步归约。
多步推导
设文法,对于,如果之间存在一个推导序列:,则称经过步推导出,记作,这种推导称为多步推导或步推导。。
多步规约
如果,也称规约到,也称为步归约或多步归约。
步及步以上推导与规约:若有,或,则记作。
句型与句子
- 有,则称是文法的句型。
- 若,则称是文法的句子。
语言
文法的产生语言定义为文法的句子集合,记为。即:。
【例】:,则。
文法的等价
文法,如果,则称文法和是等价的。
【例】:
显然有。
文法的类型
0型文法
- 如果一个文法的所有规则左侧至少含有一个非终结符,则称此文法为型文法,也称为短语文法。
- 产生式形如:,其中且至少含有一个非终结符;。
1型文法
- 如果一个文法的所有规则左侧符号串的长度不大于右侧符号串的长度(空规则除外),且左侧至少含有一个非终结符,则称此文法为型文法,也称为上下文相关文法。
- 产生式形如:,其中,仅例外。
- 考虑,被替换成,跟的上下文相关。
2型文法
- ,则文法是型文法,也称为上下文无关文法。。(即任一产生式左部均为一非终结符。)
3型文法
文法的产生式只能是以下两者之一:
- ——右线性文法
- ——左线性文法
统称型文法,又叫正则文法。
【例】:文法是正则文法,。
则。
文法的类型于表达能力
- 从型文法到型文法,限制逐渐增多,表达能力也逐渐减弱
- 如果和分别是型文法、型文法、型文法和型文法能产生的语言之集,则有如下关系:。
上下文无关文法及其语法树
-
上下文无关文法—描述程序语言的语法结构
【例】
-
从一个句型到另一个句型的推导往往不唯一
如:。
-
最左推导:任何一步都是对中的最左非终结符进行替换
-
最右推导:任何一步都是对中的最右非终结符进行替换
-
最右推导,也叫做规范推导。由规范推导所得到的句型,叫做规范句型(右句型)。规范推导的逆过程,叫做规范归约。
【例】 最左/最右推导过程示例
已知文法如下,试给出句子aabbaa的推导过程。
- 最左推导:
- 最右推导:
语法树
文法的任何一个句型,根据其推导都能构造一个语法树,也称为推导树。它是一个满足下列条件的多叉树:
- 文法的开始符为树的根节点
- 对任一产生式,的各符号严格依生产式的次序依次为的子节点;文法符号为其节点标记(节点名)。
【例】 语法树示例
已知文法如下,试给出句子aabbaa的推导过程。
- 最左推导:
- 最右推导:
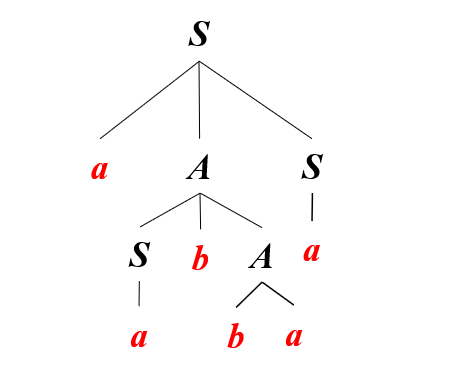
结论:
- 非叶子结点一定是非终结符
- 全部叶子结点组成的符号串是文法的句子
语法树的二义性
- 如果文法的某个句子存在至少两棵不同的语法树,则称该文法是二义的。
- 如果文法是无二义性的,一个句子的语法树反映了该句子的全部推导过程。
- 如果文法是无二义性的,一个句子的最左(最右)推导是唯一的。
【例】语法二义性示例
已知文法,证明是二义的。
证明:因为句子存在下列两棵不同的语法树
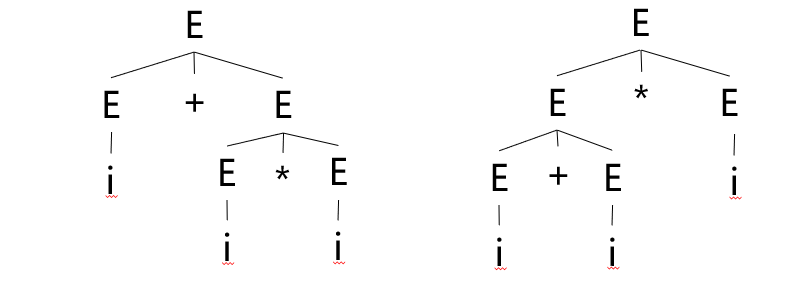
故文法是二义性的文法。
语言的二义性
- 文法的二义性并不等同于语言的二义性。
- 因为二义性文法,可能存在与之等价的无二性的文法,即。
- 如果一个语言不存在无二义性的文法,则称该语言是先天二义性的。
- 二义性问题是不可判定问题,即不存在一个算法,它能在有限步骤内,确切地判定一个文法是否是二义的。
句型的分析
-
假设文法是语言之文法,即,则“符号串 是否符合语言的语法问题”被等价地转化成“推导或归约问题”,即:
-
推导法 VS 归约法
-
自顶向下 VS 自底向上
-
AntlrVSBison自顶向下分析
-
从文法开始符号出发,反复使用规则,寻找匹配符号串(推导)的句型,直到推导出句子或穷尽规则也不能推导出。进行每一步推导时,存在两个选择问题:
- 选择句型中那一个非终结符进行推导
- 选择非终结符的那一个规则进行推导
-
最左推导,穷举规则:
- 推导过程中一旦出现符号串:是合法的句子。
- 穷尽规则,不存在的推导过程:不是合法的句子。
【例】 串的推导过程
设文法
| 序号 | 推导过程 | 串 | 说明 |
|---|---|---|---|
| 1 | cabd | ||
| 2 | caba | 匹配 | |
| 3 | cabd | ,失败,回溯 | |
| 4 | cabd | ||
| 5 | cabd | 成功 |
表示第个规则。
回溯的效率很低,改进办法——提取公因子,原文法转化为:
分析目标::
自下而上的分析法
- 从输入符号串开始,逐步进行归约,直至归约出文法的开始符号,则输入串是文法定义的句子,否则不是。
- 归约是推导的逆过程
- 每步归约时,存在如何选择句型的子串进行归约的问题。
- 方案:按句柄归约—规范归约(移进—归约)
- 简单优先分析法
- LR分析法
【例】:,分析目标:

短语、直接短语、句柄
设文法有:,且。
- 是句型相对于非终结符的短语。任一子树的树叶全体(具有共同祖先的叶结点符号串)皆为短语;
- 特别地,,即,则是句型相对于规则的直接短语(简单短语)。任一简单子树的树叶全体(具有共同父亲的叶节点符号串)皆为简单短语;
- 右句型的最左直接短语称为该句型的句柄。
【例】:文法,分析句型的短语、直接短语或句柄。
- 是句型的、相对于非终结符的直接短语
- 是句型的、相对于非终结符的短语,的直接短语
- 是句型的、相对于非终结符的短语、直接短语和句柄
对于上述文法,分析句型的语法树如下:
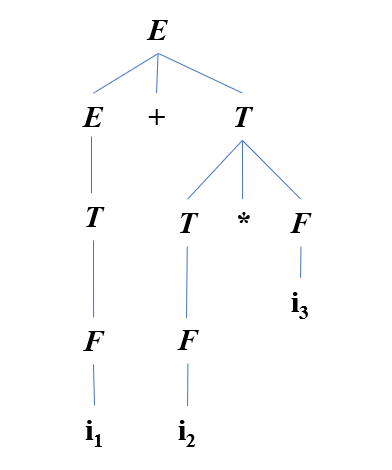
短语:
直接短语:
句柄:
补充说明
- 文法不得含有有害规则,多余规则
- 有害规则:
- 不可达(用)规则:不在任何产生式右部出现的非终结符及其规则
- 不可终止规则:从某非终结符开始,不可能推导出任意终结符串来。
- 对文法中的符号是有用的,是指至少出现在一个句子的推导过程中,即必须同时满足以下两个条件:
- 必须在某个句型中出现,即存在有(可达)
- 必须能够从推导出终结符号串,即存在,使(可终结)
- 含有无用符号的产生式称为无用产生式
文法化简
对于文法
-
删除不终结产生式算法:(满足条件2-可终结)
-
构造能推导出终结符号串的非终结符集,置;
-
对中每一个产生式,若;则;
-
对中的每一个产生式,若,则
-
重复步骤2直到不再扩大为止。
-
-
删除不在中的所有非终结符的相关产生式。
-
-
-
删除不可用产生式算法:(满足条件1-可达)
- 初始化:
- 对每一个产生式,若,则将中的非终结符并入,终结符并入;
- 重复步骤1,直到和都不再扩大为止;
- 将中左右部仅含中的符号的所有产生式并入中。
- 初始化:
epsilon()规则
- 在文法设计中,规则带来方便,也导致文法讨论和证明的复杂性
- 一个上下文无关文法是否必须使用规则,完全取决于文法产生的语言中是否含有语句。
- 可以证明,如果,则存在一个等价的文法,且不含规则。
- 如果,则存在一个等价的文法,且仅含的一个空规则。
- 设文法,,消除规则:
- 首先构造出可以推出空串的非终结符集:
- 若有;则令;
- 若有且全部,则令;
- 重复步骤1,2直到不再扩大为止。
- 删除中的形式的产生式;
- 依次改写中的产生式;若有,则用替换之(一个分裂成两个);
- 若有个,则一个产生式将分裂成个。
- 首先构造出可以推出空串的非终结符集:
【例题】

作者:cherish.
出处:https://home.cnblogs.com/u/cherish-/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人