内存系统
内存系统
存储系统的基本知识
存储系统的层次结构
计算机系统结构设计中关键的问题之一:如何以合理的价格,设计容量和速度都满足计算机系统要求的存储器系统。
人们对这三个指标的要求:容量大、速度快、价格低。
三个要求是相互矛盾的:
- 速度越快,每位价格就越高
- 容量越大,每位价格就越低
- 容量越大,速度越慢
解决方法:采用多种存储器技术,构成多级存储层次结构。
- 程序访问的局部性原理:对于绝大多数程序来说,程序所访问的指令和数据在地址上不是均匀分布的,而是相对簇聚的。
- 程序访问的局部性包含两个方面
- 时间局部性:程序马上将要用到的信息很可能就是现在正在使用的信息。
- 空间局部性:程序马上将要用到的信息很可能与现在正在使用的信息在存储空间上是相邻的。
存储系统的多层次结构:
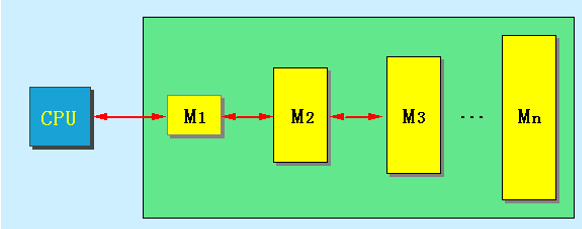
- 假设第
i个存储器\(M_i\)的访问时间为\(T_i\),容量为\(S_i\),平均每位价格为\(C_i\),则:- 访问时间:\(T_1 < T_2 < ... < T_n\)
- 容量:\(S_1 < S_2 < ... < S_n\)
- 平均每位价格:\(C_1 > C_2 > ... > C_n\)
- 整个存储系统要达到的目标:从
CPU来看,该存储系统的速度接近于\(M_1\)的,而容量和每位价格都接近与\(M_n\)。存储器越靠近CPU,则CPU对它的访问频度越高,而且最好大多数的访问都能在\(M_1\)完成。
存储层次的性能参数
下面仅考虑由\(M_1\)和\(M_2\)构成的两级存储层次,其中\(M_1\)的参数为\((S_1 , T_1 , C_1)\),\(M_2\)的参数为\((S_2 , T_2 , C_2)\)。
存储容量\(S\):一般来说,整个存储系统的容量即是第二级存储器\(M_2\)的容量,即\(S = S_2\)。
每位价格\(C\):\(C = \frac{C_1S_1 + C_2S_2}{S_1 + S_2}\),当\(S_1 \ll S_2\)时,\(C \approx C_2\)。
命中率\(H\)和不命中率\(F\):
- 命中率:
CPU访问存储系统时,在\(M_1\)中找到所需信息的概率:\(H = \frac{N_1}{N_1 + N_2}\)- \(N_1\):访问\(M_1\)的次数。
- \(N_2\):访问\(M_2\)的次数。
- 不命中率:\(F = 1 - H\)。
平均访问时间\(T_A\):\(T_A = HT_1 + (1 - H)(T_1 + T_M) = T_1 + (1 - H)T_M = T_1 + FT_M\)
分两种情况来考虑CPU的一次访存:
-
当命中时,访问时间即为\(T_1\)(命中时间)
-
当不命中时,情况比较复杂:
不命中时的访问时间为:\(T_2 + T_b + T_1 = T_1 + T_m , T_M = T_2 + T_B\)。
不命中开销\(T_M\):从向\(M_2\)发出访问请求到把整个数据块调入\(M_1\)中所需的时间。
传送一个信息块所需的时间为\(T_B\)。
三级存储系统
三级存储系统
cache(高速缓冲存储器)- 主存储器
- 磁盘存储器(辅存)
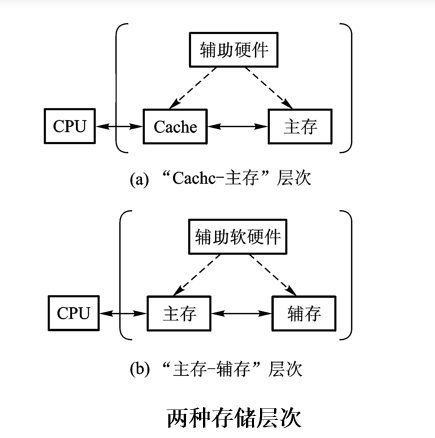
可以看成是由cache-主存层次和主存-辅存层次构成的系统
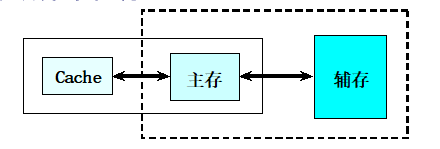
从主存的角度来看
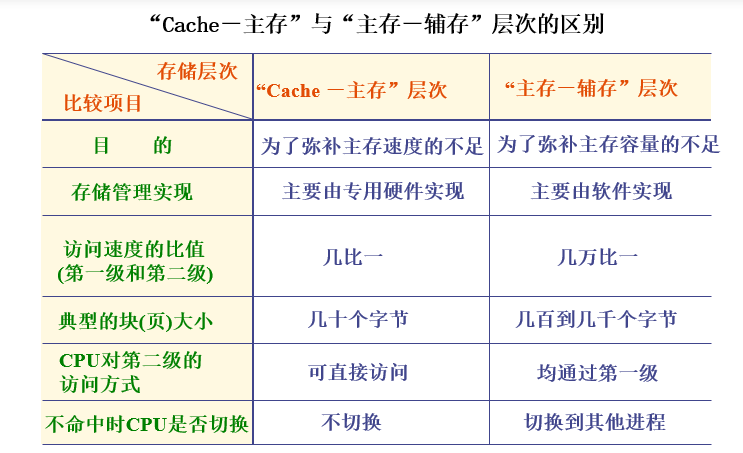
cache-主存层次:弥补主存速度的不足主存-辅存层次:弥补主存容量的不足
存储层次的四个问题:
- 当把一个块调入高一层存储器时,可以放在那些位置上? 映象规则
- 当所要访问的块在高一层存储器时,如何找到该块? 查找算法
- 当发生不命中时,应替换那一块? 替换算法
- 当进行写访问时,应进行那些操作? 写策略
Cache基本知识
基本结构和原理
Cache和主存分块
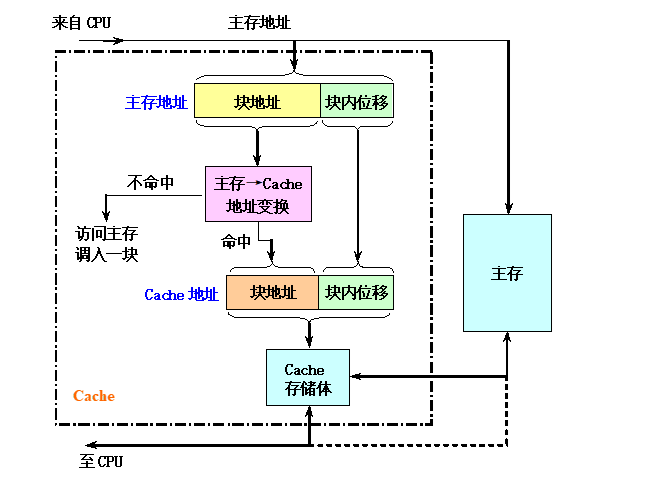
cache是按块进行管理的。cache和主存均被分割成大小相同的块。信息以块为单位调入cache。- 主存块地址(块号)用于查找该块在
cache中的位置 - 块内位移用于确定所访问的数据在该块中的位置

- 主存块地址(块号)用于查找该块在
Cache的基本工作原理示意图
映象规则
全相联映象
- 全相联:主存中的任一块可以被放置到
cache中的任意一个位置。 - 对比:阅览室位置-随便坐
- 特点:空间利用率最高,冲突概率最低,实现最复杂
直接映象
- 直接映象:主存中的每一块只能被放置到
cache中唯一的一个位置。 - 对比:阅览室位置——只有一个位置可以坐
- 特点:空间利用率最低,冲突概率最高,实现最简单
- 对于主存的第
i块,若它映象到cache的第j块,则j = i mod M,M为cache的块数。
组相联映象
-
组相联:主存中的每一块可以被放置到
cache中唯一的一个组中的任何一个位置。 -
组相联是直接映象和全相联的一种折中。
-
组的选择常采用位选择算法
- 若主存第
i块映象到第k组,则k = i mod G,G是cache的组数 - 设\(G = 2^g\),则当表示为二进制数时,
k实际上就是i的低g位。
- 若主存第
-
低
g位以及直接映象中的低m位通常称为索引。 -
n路组相联:每组中有n个块\(n = \frac{M}{G}\)。n称为相联度。相联度越高,cache空间的利用率就越高,块冲突概率就越低,不命中率也就越低。 -
绝大多数计算机的
cache:\(n \leq 4\)。
查找算法
- 当
CPU访问cache时,如何确定cache中是否有所要访问的块? - 若有的话,如何确定其位置?
通过查找目录表来实现
-
目录表的结构
- 主存块的块地址的高位部分称为标识。
- 每个主存块能唯一地由其标识来确定。
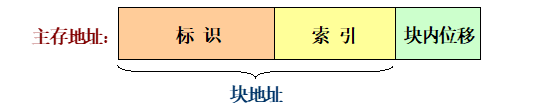
-
只需要查找候选位置所对应的目录表项
并行查找与顺序查找
- 提高性能的重要思想:主候选位置(MRU块) (前瞻执行)
并行查找的实现方法
-
相连存储器
- 目录由\(2^g\)个相联存储区构成,每个相联存储区的大小为\(n \times (h+ log_2n)\)位。
- 根据所查找到的组内块地址,从
cache存储体中读出的多个信息字中选一个,发送给CPU。 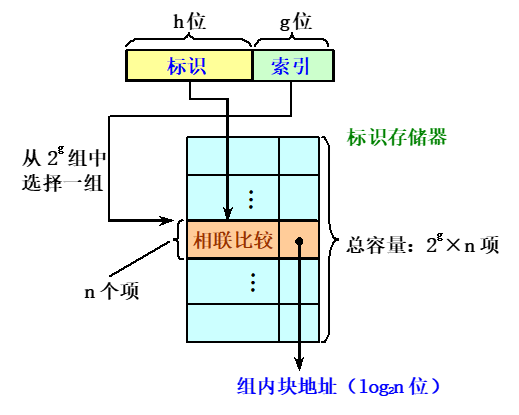
-
单体多字符存储器+比较器
- 举例:
4路组相联并行标识比较 - 优缺点
- 不必采用相联存储器,而是用按地址访问的存储器来实现
- 所需要的硬件为:大小为\(2^g\times n \times h\)位的存储器和\(n\)个\(h\)位的比较器。
- 当相联度
n增加时,不仅比较器的个数会增加,而且比较器的位数也会增加。
- 举例:
替换算法
- 所要解决的问题:当新调入一块,而
cache又已被占满时,替换那一块?- 直接映象
cache中的替换很简单。因为只有一个块,别无选择。 - 在组相联和全相联
cache中,则有多个块供选择。
- 直接映象
- 主要的替换算法有三种
- 随机法,优点:实现简单
- 先进先出法
FIFO - 最近最少使用法
LRU- 选择近期最少被访问的块作为被替换的块。(实现比较困难)
- 实际上:选择最久没有被访问过的块作为被替换的块
- 优点:命中率较高
LRU和随机法分别因其不命中率低和实现简单而被广泛采用- 模拟数据表明,对于容量很大的
cache,LRU和随机法的命中率差别不大。
- 模拟数据表明,对于容量很大的
LRU算法的硬件实现
-
堆栈法
-
用一个堆栈来记录组相联
cache的同一组中各块被访问的先后次序。 -
用堆栈元素的物理位置来反映先后次序
- 栈底记录的是该组中最早被访问过的块,次栈底记录的是该组中第二个被访问过的块,… ,栈顶记录的是刚访问过的块。
- 当需要替换时,从栈底得到应该被替换的块(块地址)。
-
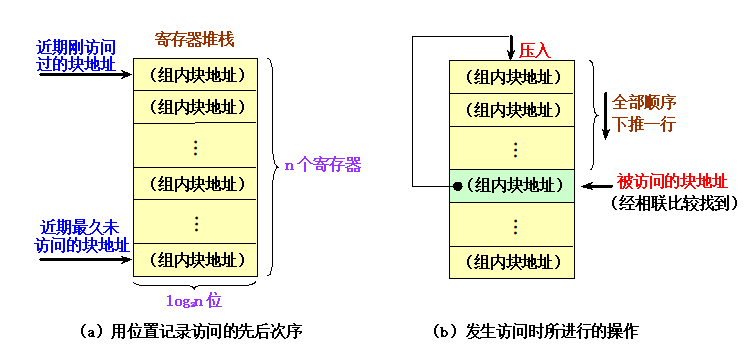
-
堆栈中的内容必须动态更新
- 当
cache访问命中时,通过用块地址进行相联查找,在堆栈中查找找到相应的元素,然后把该元素的上面的所有元素下压一个位置,同时把本次访问的块地址抽出来,从最上面压入栈顶。而该元素下面的所有元素则保持不动。 - 如果
Cache访问不命中,则把本次访问的块地址从最上面压入栈顶,堆栈中所有原来的元素都下移一个位置。如果Cache中该组已经没有空闲块,就要替换一个块。这时从栈底被挤出去的块地址就是需要被替换的块的块地址。
- 当
-
堆栈法所需要的硬件:需要为每一组都设置一个项数与相联度相同的小堆栈,每一项的位数为\(log_2n\)位。
-
硬件堆栈所需的功能:相联比较;能全部下移,部分下移和从中间取出一项的功能。
-
速度较低,成本较高(只适用于相联度较小的
LRU算法)
-
-
比较对法
-
基本思路:让各块两两组合,构成比较对。每一个比较对用一个触发器的状态来表示它所相关的两个块最近一次被访问的远近次序,再经过门电路就可找到
LRU块。 -
比较对法所需的硬件量
-
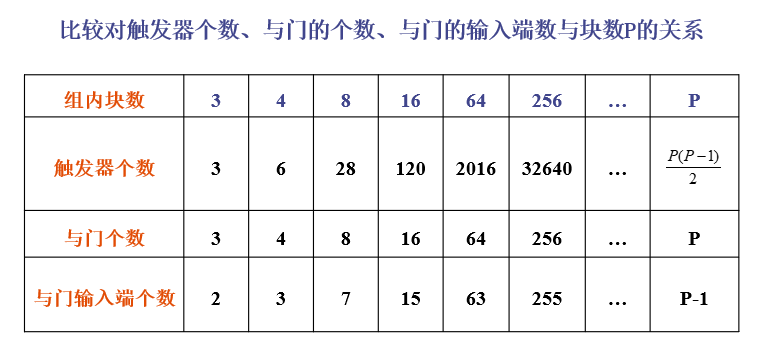
与门:有多少个块,就要有多少个与门; 每个与门的输入端要连接所有与之相关的触发器。对于一个具有P块的组中的任何一个块来说,由于它可以跟除了它自己以外的所有其他的块两两组合,所以与该块相关的比较对触发器个数为
P-1,因而其相应的与门的输入端数是P-1。 -
触发器:所需要的触发器的个数与两两组合的比较对的数目相同。
-
块数少时,所需要的硬件较少
-
随着组内块数
P的增加,所需的触发器的个数会以平方的关系迅速增加,门的输入端数也线性增加。硬件实现的成本很高。
-
-
当组内块数较多时,可以用多级状态位技术减少所需的硬件量。
例如:在
IBM3033中,组内块数为16,可分成群、对、行3级。先分成4群每群两对,每对两行。选LRU群需要6个触发器;每群中选LRU对需要一个触发器,4个群共需要4个触发器。每行中选LRU块需要一个触发器,8个行共需要8个触发器,所需的触发器总个数为18个。以牺牲速度为代价的。
-
写策略
“写”在所有访存操作中所占的比例
- 统计结果表明,对于一组给定的程序;
load指令:26%;store指令:9%。 - “写”在所有访存操作中所占的比例:\(\frac{9\%}{100\% + 26\% + 9\%} \approx 7\%\)。
- “写”在访问
cache操作中所占的比例:\(\frac{9\%}{26\%+9\%} \approx 25\%\)。
“写”操作必须在确认是命中后才可进行
“写”访问有可能导致cache和主存内容的不一致
两种写策略:写策略是区分不同cache设计方案的一个重要标志。
- 写直达(也称为存直达法):执行写操作时,不仅写入
cache,而且也写入下一级存储器。 - 写回法(也称为拷回法):执行写操作时,只写入
cache,仅当cache中相应的块被替换时,才写回主存。(设置“修改位”)
两种写策略的比较
- 写回法的优点:速度快,所使用的存储器带宽较低。
- 写直达法的优点:易于实现,一致性好。
采用写直达法时,若在进行“写”操作的过程中CPU必须等待,直到“写”操作结束,则称为CPU写停顿。
- 减少写停顿的一种常用的优化技术:采用写缓冲器
“写”操作时的调块
- 按写分配(写时取):写不命中时,先把所有写单元所在的块调入
cache再进行写入。 - 不按写分配(绕写法):写不命中,直接写入下一级存储器而不调块。
写策略与调块
- 写回法——按写分配
- 写直达法——不按写分配
Cache的性能分析
不命中率
- 与硬件速度无关
- 容易产生一些误导
平均访存时间 = 命中时间 + 不命中率 \(\times\) 不命中开销
程序执行时间
CPU时间 = (CPU执行周期数 + 存储器停顿周期数) \(\times\) 时钟周期时间
其中:
-
存储器停顿时钟周期数 = 读的次数 \(\times\) 读不命中率 \(\times\)读不命中开销 + 写的次数 \(\times\) 写不命中率 \(\times\) 写不命中开销
-
存储器停顿时钟周期数 = 访存次数 \(\times\) 不命中率 \(\times\)不命中开销
-
CPU时间 = (CPU执行周期数 + 访存次数 \(\times\) 不命中率 \(\times\) 不命中开销) \(\times\)时钟周期时间 -
CPU时间=IC\(\times\) (\(CPI_{execution} + \frac{访存次数}{指令数}\times 不命中率 \times 不命中开销\)) \(\times\) 时钟周期时间 =
IC\(\times\) (\(CPI_{execution}\) + 每条指令的平均访存次数 \(\times\) 不命中率 \(\times\) 不命中开销) \(\times\) 时钟周期时间
Cache不命中对于一个CPI较小而时钟频率较高的CPU来说,影响是双重的。
- \(CPI_{execution}\)越低,固定周期数的
Cache不命中开销的相对影响就越大。 - 在计算
CPI时,不命中开销的单位是时钟周期数,因此即使两台计算机的存储层次完全相同,时钟频率较高的CPU的不命中开销较大,其CPI中存储器停顿这部分也就较大。
因此Cache对于低CPI、高时钟频率的CPU来说更加重要。
改进Cache的性能
平均访存时间 = 命中时间 + 不命中率 \(\times\) 不命中开销
可以从三个方面改进Cache的性能:
- 降低不命中率
- 减少不命中开销
- 减少
Cache命中时间
降低Cache不命中率
三种类型的不命中
三种类型的不命中(3C)
- 强制性不命中:当第一次访问一个块时,该块不在
Cache中,需从下一级存储器中调入Cache,这就是强制性不命中。(冷启动不命中,首次访问不命中) - 容量不命中:如果程序执行时所需的块不能全部调入
Cache中,则当某些块被替换后,若又重新被访问,就会发生不命中,这种不命中称为容量不命中。 - 冲突不命中:在组相联或直接映象
Cache中,若太多的块映象到同一组中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。这就是发生了冲突不命中。 - 相联度越高,冲突不命中就越少
- 强制性不命中和容量不命中不受相联度的影响
- 强制不命中不受
Cache容量的影响,但容量不命中却随着容量的增加而减少
减少三种不命中的方法:
- 强制不命中:增加块大小,预取
- 容量不命中:增加容量 (抖动现象)
- 冲突不命中:提高相联度 (理想情况:全相联)
许多降低不命中率的方法会增加命中时间或不命中开销
增加Cache块大小
不命中率与块大小的关系
- 对于给定的
Cache容量,当块大小增加时,不命中率开始是下降的,后来反而上升了。原因:一方面它减少了强制性不命中;另一方面由于增加块大小会减少Cache中块的数目,所以有可能会增加冲突不命中。 Cache容量越大,使不命中率达到最低的块大小就越大。
增加块大小会增加不命中开销
针对强制不命中的改进
- 对于上述的第二点结论,可以考虑一个极端情况,当
Cache与主存容量相等时,块大小达到主存容量时,不命中率最低,即第一次不命中,后面全命中。 - 块增大,假设总线带宽不变,传输时间变长。
增加Cache的容量
最直接的方法是增加Cache的容量。缺点:增加成本,可能增加命中时间。
这种方法在片外Cache中用得比较多。
提高相联度
采用相联度超过8的方案的实际意义不大。
2 : 1 Cache经验规则:容量为N的直接映象Cache的不命中率和容量为\(\frac{N}{2}\)的两路组相联Cache的不命中率差不多相同。
提高相联度是以增加命中时间为代价的。
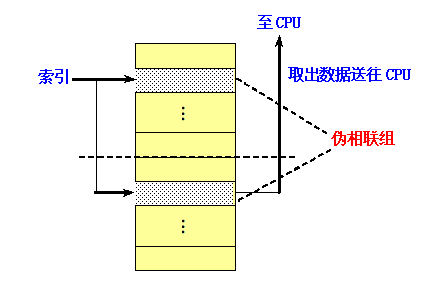
伪相联Cache(列相联Cache)
多路组相联的低不命中率和直接映象的命中速度
| 优点 | 缺点 | |
|---|---|---|
| 直接映象 | 命中时间小 | 不命中率高 |
| 组相联 | 不命中率低 | 命中时间大 |
伪相联Cache的优点:命中时间小,不命中率低。
伪相联实际上是一种直接映象与组相联的折中,可以看作直接映象外补充一层。
基本思路即工作原理
在逻辑上把直接映象Cache的空间上下平分为两个区。对于任何一次访问,伪相联Cache先按直接映象Cache的方式去处理。若命中,则其访问过程与直接映象Cache的情况一样。若不命中,则再到另一区相应的位置去查找。若找到,则发生了伪命中,否则就只好访问下一级存储器。
快速命中与慢速命中:要保证绝大多数命中都是快速命中。
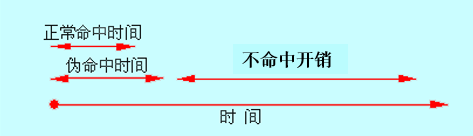
缺点:多种命中时间
硬件预取
指令和数据都可以预取
预取内容既可以放入Cache,也可以放在外缓冲器中。
指令预取通常由Cache之外的硬件完成。
预取应利用存储器的空闲带宽,不能影响对正常不命中的处理,否则可能会降低性能。
编译器控制的预取
在编译时加入预取指令,在数据被用到之前发出预取请求。
按照预取数据所放的位置,可把预取分为两种类型:
- 寄存器预取:把数据取到寄存器中
Cache预取:只将数据取到Cache中
按照预取的处理方式不同,可把预取分为:
- 故障性预取:在预取时,若出现虚地址故障或违反保护权限,就会发生异常。
- 非故障性预取:在遇到这种情况时则不会发生异常,因为这时它会放弃预取,转变为空操作。
- 本部分假定
Cache预取都是非故障性的,也叫做非绑定预取。
在预取数据的同时,处理器应能继续执行:只有这一,预取才有意义 。非阻塞Cache。
编译器控制预取的目的:使执行指令和读取数据能重叠执行。
循环是预取优化的主要对象。
- 不命中开销小时:循环体展开\(1 \sim 2\)次
- 不命中开销大时:循环体展开许多次
每次预取需要花费一条指令的开销
- 保证这种开销不超过预取所带来的收益
- 编译器可以通过把重点放在那些可能会导致不命中的访问上,使程序避免不必要的预取,从而较大程度地减少平均访存时间。
编译器优化
基本思想:通过对软件进行优化来降低不命中率。特点:无需对硬件做任何改动。
程序代码和数据重组
- 可以重新组织程序而不影响程序的正确性
- 把一个程序中的过程重新排序,就可能会减少冲突不命中,从而降低指令不命中率。
- 把基本块对齐,使得程序的入口点与
Cache块的起始位置对齐,就可以减少顺序代码执行时所发生的Cache不命中的可能性。
- 如果编译器知道一个分枝指令很可能会成功转移,那么它就可以通过以下两步来改善空间局部性:
- 将转移目标处的基本块和紧跟着该分支指令后的基本块进行对调。
- 把该分支指令换为操作语义相反的分支指令。
- 数据对存储位置的限制更少,更便于调整顺序。
- 编译优化技术包括:
- 数组合并:将本来相互独立的多个数组合并成为一个符合数组,以提高访问它们的局部性。
- 内外循环交换
- 循环融合:将若干个独立的循环融合为单个的循环。这些循环访问同样的数组,对相同的数据作不同的运算。这样能使得读入
Cache的数据在被替换出去之前,能得到反复的使用。 - 分块
牺牲Cache
一种能减少冲突不命中次数而又不影响时钟频率的方法
基本思想:在Cache和它的下一级存储器调数据的通路之间设置一个全相联的小Cache,称为牺牲Cache。用于存放被替换出去的块,称为牺牲者,以备重用。
作用:对于减小冲突不命中很有效,特别是对于小容量的直接映象数据Cache,作用尤其明显。
减少Cache不命中开销
采用两级Cache
应该把Cache做得更快还是更大?
答案:二者兼顾,再增加一级Cache:第一级Cache(L1)小而快,第二级Cache(L2)容量大。
性能分析:
\(平均访存时间 = 命中时间_{L_1} + 不命中率_{L_1} \times 不命中开销_{L_1}\)
\(不命中开销_{L_1} = 命中时间_{L_2} + 不命中率_{L_2} \times 不命中开销_{L_2}\)
局部不命中率与全局不命中率
-
\(局部不命中率 = \frac{该级Cache的不命中次数}{到达该级Cache的访问次数}\)
-
\(全局不命中率 = \frac{该级Cache的不命中次数}{CPU发出的访存的总次数}\)
-
\(全局不命中率_{L_2} = 不命中率_{L_1} \times 不命中率_{L_2}\)
该评价第二级
Cache时,应使用全局不命中率这个指标。它指出了在CPU发出的访存中,究竟有多大比例是穿过各级Cache,最终到达存储器的。
采用两级Cache时,每条指令的平均访存停顿时间为:
\(每条指令的平均访存停顿时间 = 每条指令的平均不命中次数_{L_1} \times 命中时间_{L_2} + 每条指令的平均不命中次数_{L_2} \times 不命中开销_{L_2}\)
对于第二级Cache,我们有以下结论:
- 在第二级
Cache比第一级Cache大得多的情况下,两级Cache的全局不命中率和容量与第二级Cache相同的单级Cache的不命中率非常接近。 - 局部不命中率不是衡量第二级
Cache的一个好指标,因此在评价第二级Cache时,应该使用全局不命中率这个指标。
第二级Cache不会影响CPU的时钟频率,因此其设计有更大的考虑空间
- 它能否降低
CPI中的平均访存时间部分? - 它的成本是多少?
第二级Cache的参数:
- 容量:第二级
Cache的容量一般比第一级的大许多。大容量意味着第二级Cache可能实际上没有容量不命中,只剩下一些强制不命中和冲突不命中。 - 相联度:第二级
Cache可采用较高的相联度或伪相联方法。 - 块大小:第二级
Cache可采用较大的块,如64、128、256字节。为减少平均访存时间,可以让容量较小的第一级Cache采用较小的块,而让容量较大的第二级Cache采用较大的块。多级包容性,即需要考虑另一个问题:第一级Cache中的数据是否总是同时存在于第二级Cache中。
让读不命中优先与写
Cache中的写缓冲器导致对存储器访问的复杂化,在读不命中时,所读单元的最新值有可能还在写缓冲器中,尚未写入主存。
解决上述问题的方法:
- 推迟对读不命中的处理,缺点:读不命中的开销增加
- 检查写缓冲器中的内容
在写回法Cache中,也可采用写缓冲器
写缓冲合并
提高写缓冲器的效率
写直达Cache:依靠写缓冲来减少对下一级存储器写操作的时间。
- 如果写缓冲器为空,就把数据和相应地址写入该缓冲器。从
CPU的角度来看,该写操作就算是完成了。 - 如果写缓冲器中已经有了待写入的数据,就要把这次的写入地址与写缓冲器中已有的所有地址进行比较,看是否有匹配的项。如果有地址匹配的而对应的位置又是空闲的,就把这次要写入的数据与该项合并,这就叫写缓冲合并。
- 如果写缓冲器满且又没有能进行写合并的项,就必须等待。
提高了写缓冲器的空间利用率,而且还能减少因写缓冲器满而要进行的等待时间。
请求字处理技术
请求字:从下一级存储器调入Cache的块中,只有一个字是立即需要的。这个字称为请求字。
应尽早把请求字发送给CPU:
- 尽早重启动:调块时,从块的起始位置开始读起。一旦请求字到达,就立即发送给
CPU,让CPU继续执行。 - 请求字优先:调块时,从请求字所在的位置读起。这样,第一个读出的字便是请求字。将之立即发送给
CPU。
该技术在以下情况下效果不大:Cache块较小;下一条指令正好访问同一Cache块的另一部分。
非阻塞Cache技术
非阻塞Cache:Cache不命中时仍允许CPU进行其它的命中访问,即允许“不命中下命中”。
进一步提高性能:多重不命中下命中;不命中下不命中(存储器必须能够处理多个不命中)。
可以同时处理的不命中次数越多,所能带来的性能上的提高就越大。对整数程序来说,重叠次数对性能提高影响不大,简单的一次不命中下命中就几乎可以得到所有的好处。
减少命中时间
命中时间直接影响处理器的时钟频率。在当今的许多计算机中,往往是Cache的访问时间限制了处理器的时钟频率。
容量小、结构简单的Cache
硬件越简单,速度就越快。
应使Cache足够小,以便可以与CPU一起放在同一块芯片上。
某些设计采用了一种折中的方案:把Cache的标识放在片内,而把Cache的数据存储器放在片外。
虚拟Cache
物理Cache:
- 使用物理地址进行访问的传统
Cache - 标识存储器中存放的是物理地址,进行地址检测也是用物理地址
- 缺点:地址转换和访问
Cache串行进行,访问速度很慢。 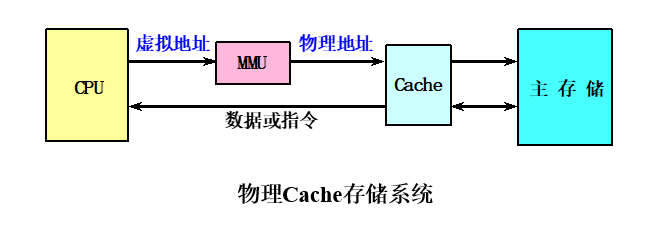
虚拟Cache:
- 可以直接用虚拟地址进行访问的
Cache。标识存储器中存放的是虚拟地址,进行地址检测用的也是虚拟地址。 - 优点:在命中时不需要地址转换,省去了地址转换的时间。即使不命中,地址转换和访问
Cache也是并行进行的,其速度比物理Cache快很多。 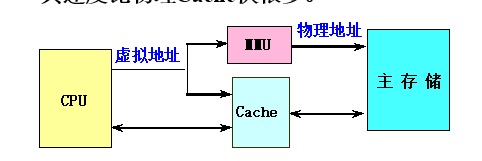
并非都采用虚拟Cache
- 虚拟
Cache的清空问题 解决方法:在地址标识中增加PID字段(进程标识符)。 - 同义和别名 解决方法:反别名法、页着色
- 虚拟索引 + 物理标识:
- 优点:兼得虚拟
Cache和物理Cache的好处 - 局限性:
Cache容量受到限制。\(Cache容量 \leq 页大小 \times 相联度\)。
- 优点:兼得虚拟
另一种方法:硬件散列变换
Cache访问流水化
对第一级Cache的访问按流水方式组织
访问Cache需要多个时钟周期才可以完成
踪迹Cache
开发指令级并行性所遇到的一个挑战是:当要每个时钟周期流出超过4条指令时,要提供足够多条彼此互不相关的指令是很困难的。
一个解决方法:采用踪迹Cache。存放CPU所执行的动态指令序列。包含了由分支预测展开的指令,该分支预测是否正确需要在取到该指令时进行确认。
优缺点:地址映像机制复杂;相同的指令序列可能被当作条件分支的不同选择而重复存放;能够提高指令Cache的空间利用率。
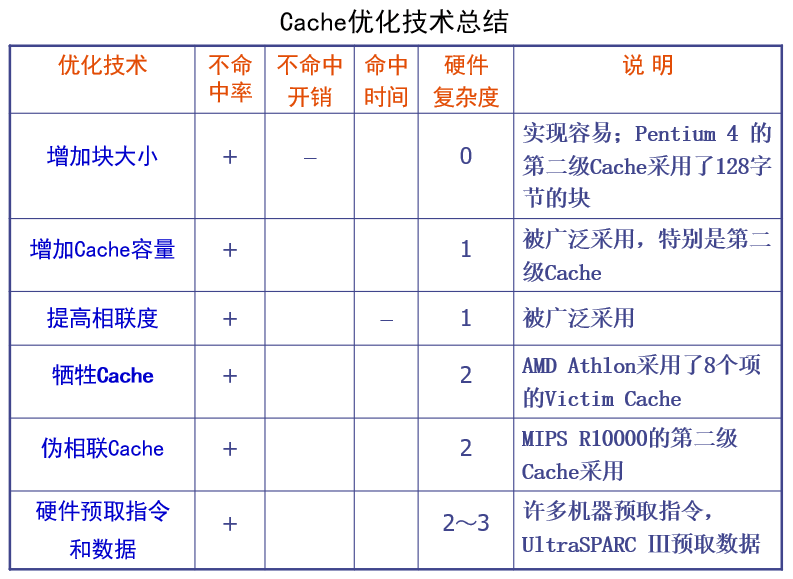
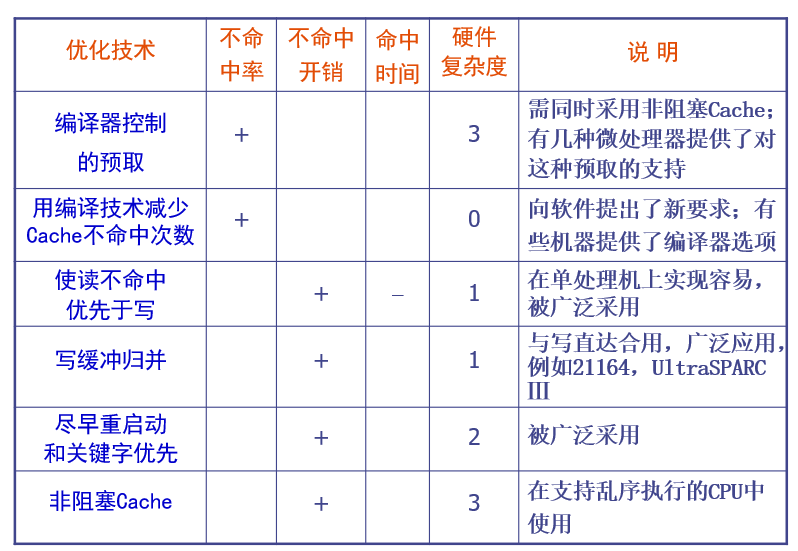
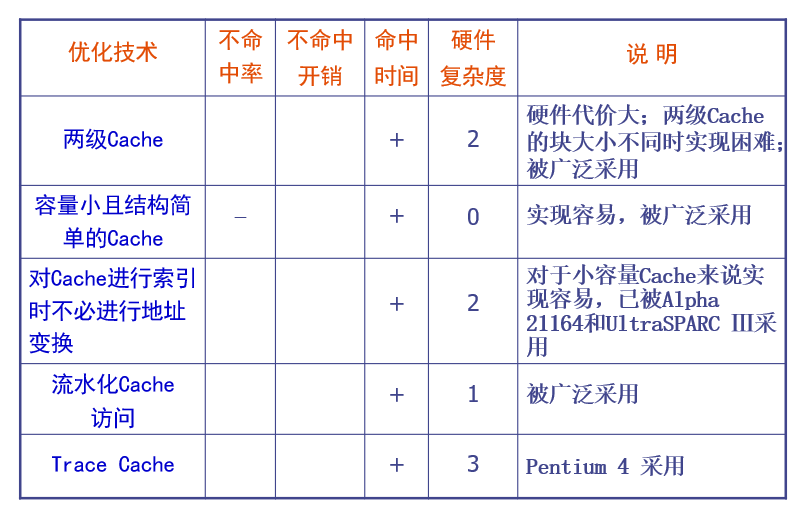
Cache优化技术总结
- ‘+’ 号:表示改进了相应的指标
- ‘-’号:表示它使该指标变差
- 空格栏:表示它对该指标无影响
- 复杂性:
0表示最容易,3表示最复杂
并行主存系统
-
主存的主要性能指标:延迟和带宽
-
以往:
Cache主要关心延迟,I/O主要关心带宽 -
现在:
Cache关心二者 -
并行主存系统是一个访存周期内能并行访问多个存储字的存储器。能有效地提高存储器的带宽。
-
一个单体单字宽的存储器
- 字长与
CPU的字长相同 - 每次只能访问一个存储字。假设该存储器的访问周期是\(T_M\),字长为\(W\)位,则其带宽为:\(B_M = \frac{W}{T_M}\)
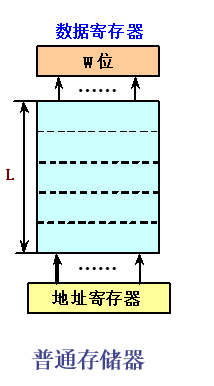
- 字长与
-
在相同的器件条件(即\(T_M\)相同)下,可以采用两种并行存储器结构来提高主存的带宽:单体多字存储器;多体交叉存储器。
单体多字存储器
一个单体\(m\)字(这里\(m = 4\))存储器
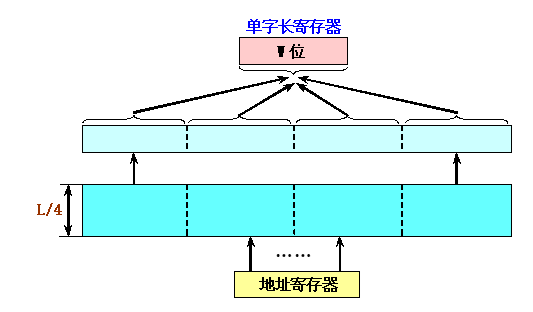
存储器能够每个存储周期读出m个CPU字。因此其最大带宽提高到原来的m倍:
单体多字存储器的实际带宽比最大带宽小
优点:实现简单
缺点:访存效率不高
原因:
- 如果一次读取的\(m\)个指令字中有分支指令,而且分支成功,那么该分支指令之后的指令是无用的。
- 一次取出的\(m\)个数据不一定都是有用的。另一方面,当前执行指令所需要的多个操作数也不一定正好都存放在同一长存储字中。
- 写入有可能变得复杂。
- 当要读出的数据字和要写入的数据字处于同一个长存储字内时,读和写的操作就无法再同一个存储周期内完成。
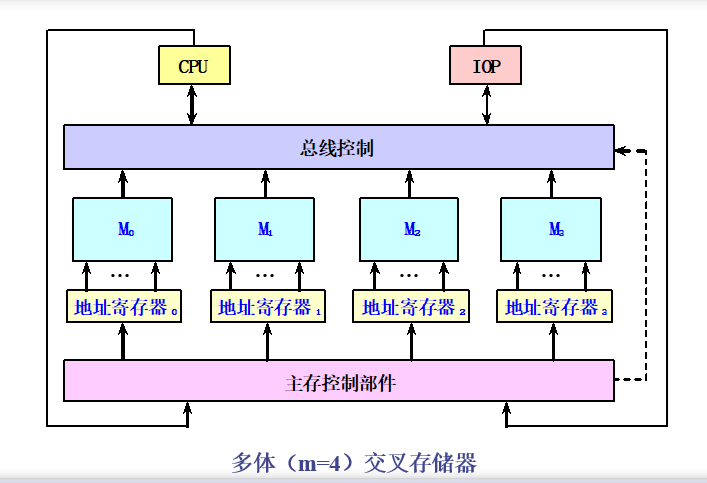
多体交叉存储器
多体交叉存储器:由多个单体字存储体构成,每个存储体都有自己的地址寄存器以及地址译码和读写驱动等电路。
多体存储器如何进行编址?
- 存储器是按顺序线性编址的。如何在二维矩阵和线性地址之间建立对应关系?
- 两种编址方式:高位交叉编址;低位交叉编址(有效地解决访问冲突问题)。
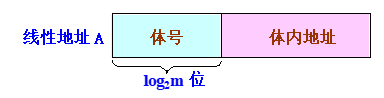
高位交叉编址
-
对存储单元矩阵按列优先的方式进行编址
-
特点:同一存储体中的高\(log_2m\)位都是相同的
-
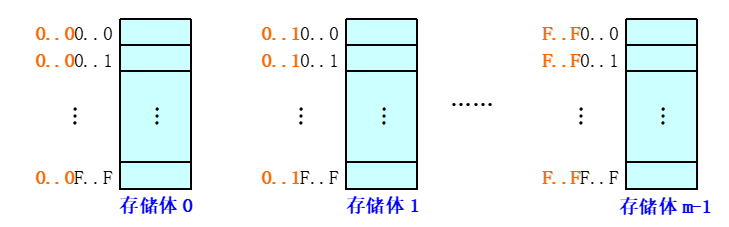
-
处于第\(i\)行第\(j\)列的单元,即存储体号为\(j\)、存储体内地址为\(i\)的单元,其线性地址为\(A = j \times n + i\)。
-
一个单元的线性地址为\(A\),则其存储体号\(j\)和存储体内地址\(i\)为:\(j = \lfloor \frac{A}{N}\rfloor , i = A\;mod\;n\)。
-
把\(A\)表示为二进制数,则其高\(log_2m\)位就是存储体号,而剩下的部分就是体内地址。
低位交叉编址
-
对存储单元矩阵按行优先进行编址
-
特点:同一存储体中的低\(log_2m\)位都是相同的
-
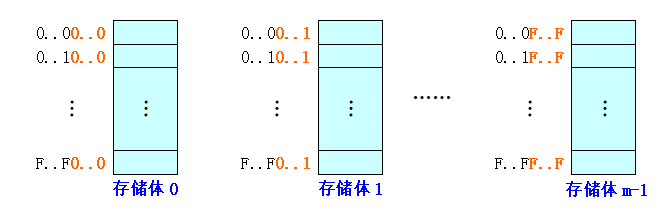
-
处于第\(i\)行第\(j\)列的单元,即存储体号为\(j\),体内地址为\(i\)的单元,其线性地址为:\(A = i \times m + j\)。
-
一个单元的线性地址为\(A\),则其存储体号\(j\)和存储体内地址\(i\)为:\(i = \lfloor \frac{A}{m}\rfloor , j = A\;mod\; m\)。
-
把\(A\)表示为二进制数,则其低\(log_2m\)位就是存储体号,而剩下的部分就是体内地址。

为了提高主存的带宽,需要多个或所有存储体能并行工作。
- 在每一个存储周期内,分时启动
m个存储体。 - 如果每个存储体的访问周期是\(T_M\),则各存储体的启动间隔为\(t = \frac{T_M}{m}\)。
- 增加
m的值就能够提高主存储器的带宽。但是由于存在访问冲突,实际加速比小于m。
避免存储体冲突
存储体冲突:两个请求要访问同一个存储体。
减少存储体冲突次数的一种方法:采用许多存储体。
解决存储图冲突的方法:
- 软件方法(编译器):循环交换优化;扩展数组的大小,使之不是
2的幂。 - 硬件方法:使存储体数为素数,存储体内地址 = 地址 A mod 存储体中的字数。
虚拟存储器
虚拟存储器的基本原理
虚拟存储器是主存-辅存层次进一步发展的结果。
虚拟存储器可以分类两类:页式和段式。
- 页式虚拟存储器把空间划分为大小相同的块。——页面
- 段式虚拟存储器则把空间划分为可变长的块。——段
- 页面是对空间的机械划分,而段则往往是按程序的逻辑意义进行划分。
快速地址转换技术
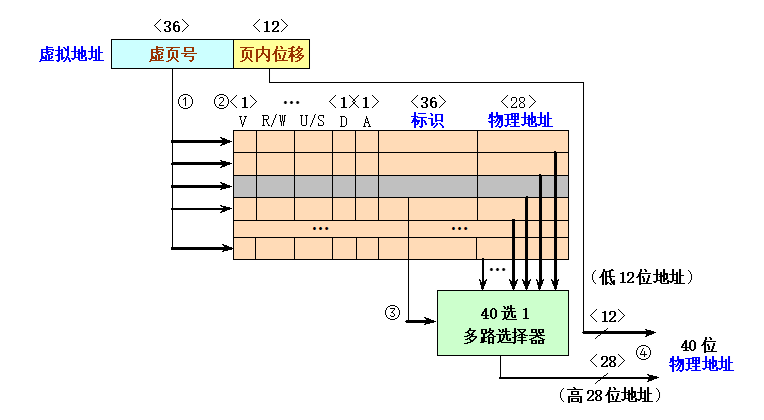
地址变换缓冲器TLB:
TLB是一个专用的高速缓冲器,用于存放近期经常使用的页表项。TLB中的内容是页表部分内容的一个副本TLB也利用了局部性原理
TLB中的项由两部分构成:标识和数据
- 标识中存放的是虚地址的一部分。
- 数据部分中存放的则是物理页帧号、有效位、存储保护信息、使用位、修改位等。
一般TLB比Cache的表示存储器更小、更快。保证TLB的读出操作不会使Cache的命中时间延长。
作者:cherish.
出处:https://home.cnblogs.com/u/cherish-/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号