

数据挖掘分析租售比
场景:
前几个周末看到一个租售比的数据,于是自己花了一个周末的时间写了个python程序,从链家上爬宁波市区的数据进行分析。
解决:
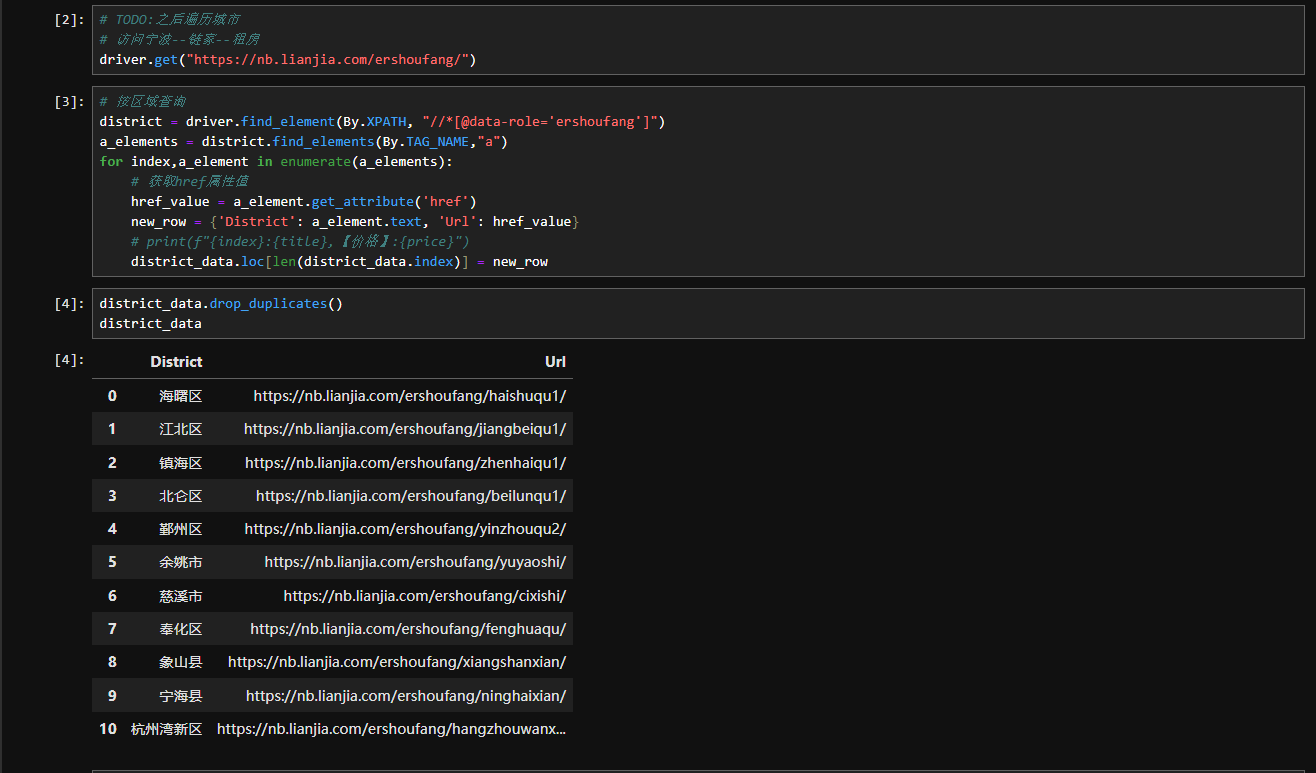
主要思路是这样的:利用Selenium、WebDriver模拟用户在链家上的操作,爬取网页上的租房、二手房的数据(目前只写了这两部分),然后保存在本地。在用python进行对应的数据分析。
一些结果图如下:爬取网页上标题、价格、小区等信息
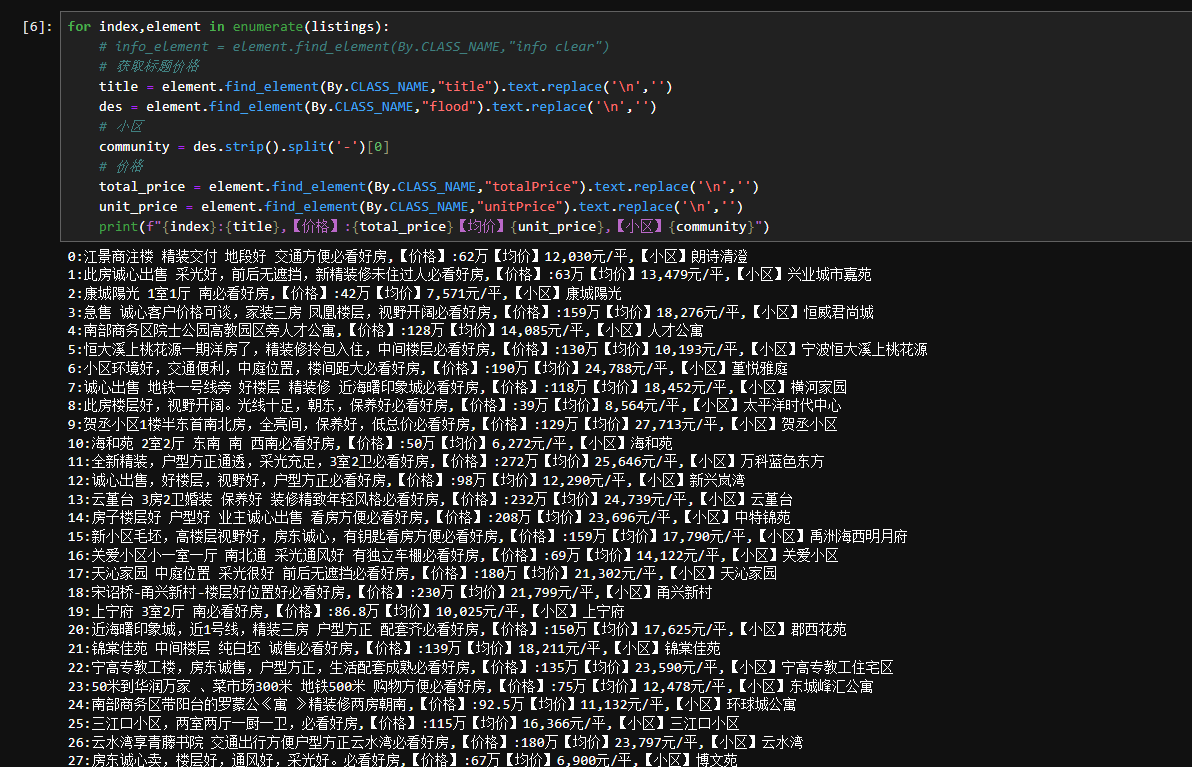
主要函数如下:其实就是找页面上各个元素的值,等加载完后获取数据,然后下一页。

# 获取数据 def get_data(driver,district): begin_page = 1 end_page = 2 page = begin_page data = pd.DataFrame(columns=['Title', 'Price','Community','Area','District','UnitPrice']) page_element = driver.find_element(By.XPATH,"//*[@page-data]") # 获取data-totalpage属性的值 page_data_attr = page_element.get_attribute('page-data') # 使用正则表达式提取 totalPage 的值 match = re.search(r'"totalPage":\s*(\d+)', page_data_attr) if match: end_page = int(match.group(1)) # 将提取到的字符串转换为整数 print(f"共:{end_page} 页数据,开始获取") else: print("未找到 totalPage 值") # 翻页逻辑,这里需要根据实际页面元素进行调整 try: while page < end_page: print(f"进入页数为:{page} 的数据") # 获取当前页面的所有房源信息 #elements = WebDriverWait(driver, 30).until( # EC.find_elements((By.CLASS_NAME, "content__list--item")) #) elements = driver.find_elements(By.XPATH,"//*[@data-lj_action_housedel_id]") for index,element in enumerate(elements): title = element.find_element(By.CLASS_NAME,"title").text.replace('\n','') des = element.find_element(By.CLASS_NAME,"flood").text.replace('\n','') # 小区 community = des.strip().split('-')[0] # 面积 area_text = element.find_element(By.CLASS_NAME,"houseInfo").text.replace('\n','') area_text = area_text.strip().split('|')[1] match = re.search(r'\d+\.\d+|\d+', area_text) if match: area = float(match.group(0)) # 将匹配到的字符串转换为浮点数 else: print("没有找到数字") # 价格 total_price = element.find_element(By.CLASS_NAME,"totalPrice").text.replace('\n','') unit_price = element.find_element(By.CLASS_NAME,"unitPrice").text.replace('\n','').replace('"','') new_row = {'Title': title, 'Price': total_price,'Community':community,'Area':area,'District':district,'UnitPrice': unit_price} # print(f"{new_row}") data.loc[len(data.index)] = new_row try: page_element = driver.find_element(By.XPATH,"//*[@page-data]") # print(f"{page_element}") xpath_expression = "//a[normalize-space(text())='下一页']" next_page_button = page_element.find_element(By.XPATH,xpath_expression) # 滚轮 driver.execute_script("arguments[0].scrollIntoView();", next_page_button) # 执行一些操作,例如点击 next_page_button.click() finally: # 关闭浏览器 # driver.quit() page_element = driver.find_element(By.CSS_SELECTOR,'[class="on"]') page = int(page_element.text) # 避免死循环 # break #print(f"页数为:{page} 的数据获取完毕") except Exception as e: print("发生错误:", e) # 存储开始页数结束页数 print(f"共获取从{begin_page}页到{page}页的数据") # 返回数据 return data
然后用同样的方法获取租房、二手房的数据信息,在小区维度租售比分析:
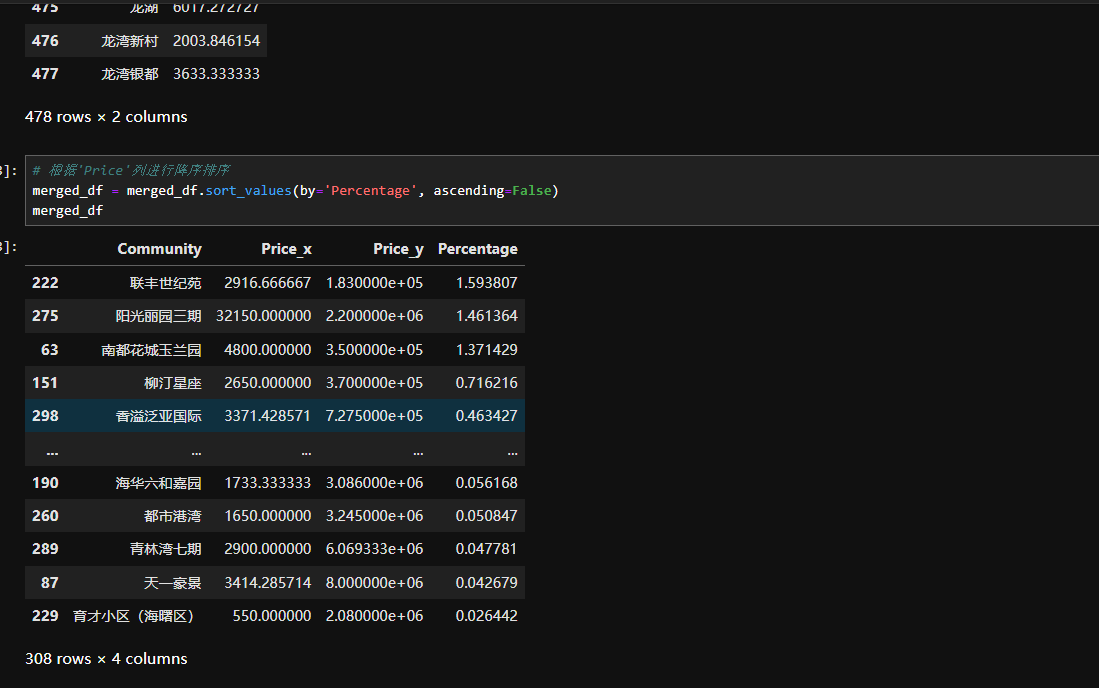
想做的好一些,可以用图表进行绘制,也可以分析不同地区、不同类型房子的租售比。用来学习数据爬虫,还是有点意思的。有需要源码的联系我吧,不过只实现了一个demo。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)