
Linux环境编程进程间通信机制理解
一、Linux系统调用主要函数
一、Linux系统调用主要函数
首先,认识一下Linux下系统调用的主要函数,为后面进程与通信等做好铺垫。
以下是 Linux 系统调用的一个列表,包含了大部分常用系统调用和由系统调用派生出的函数。
| fork | 创建一个新进程 |
| clone | 按指定条件创建子进程 |
| execve | 运行可执行文件 |
| exit | 中止进程 |
| _exit | 立即中止当前进程 |
| sleep(n) | 睡眠(等待/阻塞),n 为秒的单位 |
| getpid | 获取进程标识号 |
| getppid | 获取父进程标识号 |
| pause | 挂起进程,等待信号 |
| wait(参数) | 等待子进程终止 |
| waitpid | 等待指定子进程终止 |
| kill | 向进程或进程组发信号 |
| pipe | 创建管道 |
二、创建进程
接下来这部分相当于程序设计,通过系统调用创建进程,然后根据执行顺序进行判断,理解主进程和子进程的关系。
1、创建子进程系统调用fork()
#include <unistd.h> #include <sys/types.h> #include<stdio.h> int main () { pid_t pid; /* pid_t 是 short 类型 */ pid=fork(); if (pid < 0) printf("error in fork!"); else if (pid == 0) printf("i am the child process, my process id is %d\n",getpid()); else printf("i am the parent process, my process id is %d\n",getpid()); return 0; }
这个程序很好理解:
fork()返回值0,进入子进程,返回值1,进入父进程,-1则是创建失败。
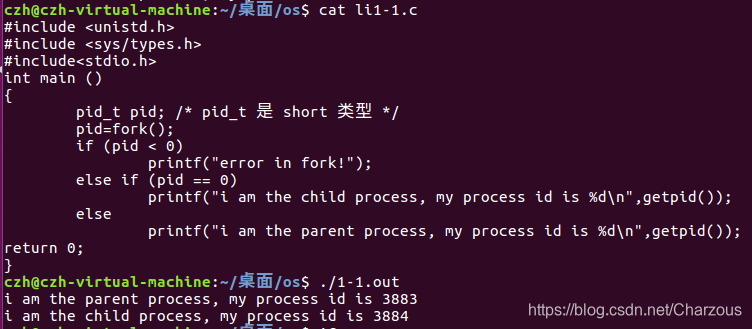
主要理解父子进程执行顺序是否与程序结构(判断语句前后)有关,所以再次进行以下测试,修改了判断语句顺序:
#include <unistd.h> #include <sys/types.h> #include<stdio.h> int main () { pid_t pid; /* pid_t 是 short 类型 */ pid=fork(); if (pid < 0) printf("error in fork!"); else if (pid > 0) printf("i am the parent process, my process id is %d\n",getpid()); else printf("i am the child process, my process id is %d\n",getpid()); return 0; }
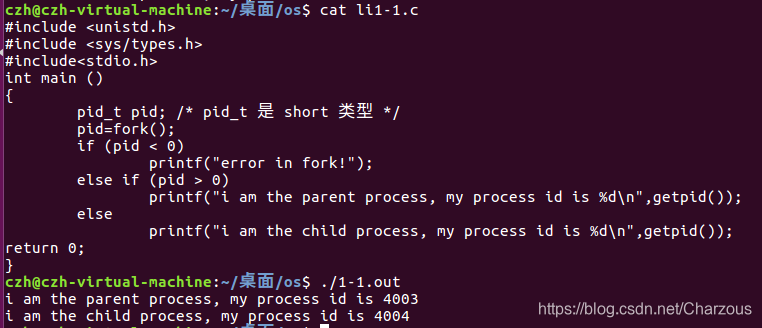
根据实验结果如图,对比之后发现运行结果相同,说明父子进程运行顺序与判断语句次序无关,始终是父进程优先执行。
2、验证fork()创建子进程效果
首先,我们再次对以上程序进行修改,第一次,测试打印语句放于fork()之前,观察结果:
#include <unistd.h> #include <sys/types.h> #include<stdio.h> int main () { pid_t pid; /* pid_t 是 short 类型 */ printf("see the print times\n"); pid=fork(); if (pid < 0) printf("error in fork!"); else if (pid > 0) printf("i am the parent process, my process id is %d\n",getpid()); else printf("i am the child process, my process id is %d\n",getpid()); return 0; }
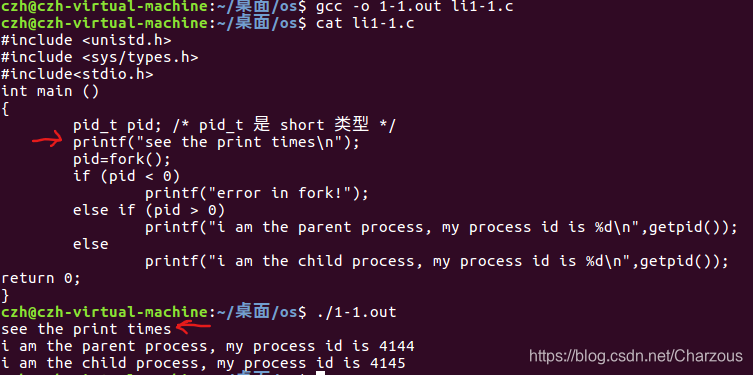
第二次,将打印测试放在fork()之后,结果:
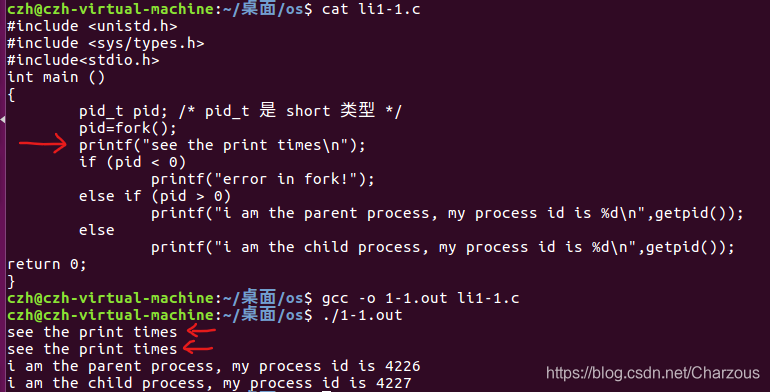
由此可见得,在fork()创建子进程之后,有两个进程进行执行操作,所以执行了两次测试打印。
3、系统调用fork()与挂起系统调用wait()
实现代码如下:
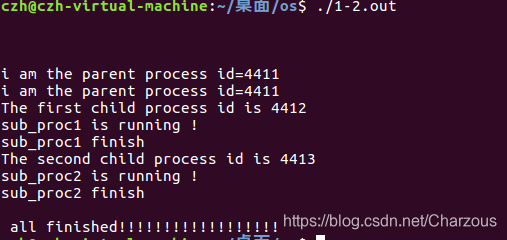
#include <unistd.h> #include <sys/types.h> #include<sys/wait.h> #include<stdio.h> #include<stdlib.h> int i, st; pid_t pid1, pid2; int sub_proc1(int id); int sub_proc2(int id); int main() { printf("\n\n\n"); if ((pid1 = fork()) == 0) { printf("The first child process id is %d\n", getpid()); sub_proc1(1);} else printf("i am the parent process id=%d \n",getpid()); if ((pid2 = fork()) == 0) { printf("The second child process id is %d\n", getpid()); sub_proc2(2);} else printf("i am the parent process id=%d \n",getpid()); i = wait(&st); i = wait(&st); printf("\n all finished!!!!!!!!!!!!!!!!!!\n"); exit(0); return 0; } int sub_proc1(int id) { printf("sub_proc%d is running !\n",id); printf("sub_proc%d finish \n",id); exit(id); } int sub_proc2(int id) { printf("sub_proc%d is running !\n",id); printf("sub_proc%d finish \n",id); exit(id); }
解析:初始化创建了两个主进程,系统调用wait()更直观看出,程序先执行第一个主进程,再执行其子进程;然后执行第二个主进程,再执行其子进程。按照这个执行顺序,感知父子进程直接的关系,以及两个进程之间的执行顺序。证明结果:
三、模拟进程管道通信
我们知道,管道是进程之间的通信方法之一, 接下来通过进程的创建、管道的设置,实现进程间通过管道进行通信,然后认识在 Linux下进程间通过管道通信的编程。
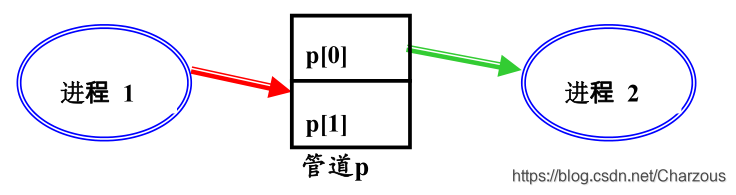
原理:pipe() 把 p[ ] 与两个文件描述符紧密联系起来:
p[0] 用于从管道读
p[1]用于向管道写
使用到系统调用函数pipe() 和 fork()
#include <stdio.h> #include<stdlib.h> #include <sys/types.h> #include <unistd.h> #include <sys/wait.h> #define MSGSIZE 16 int pipe(int p[2]); char *msg1="hello, world #1"; char *msg2="hello, world #2"; char *msg3="hello, world #3"; int main() { char inbuf[MSGSIZE]; int p[2], i, pid; if (pipe(p) < 0) /* 打开管道 */ { perror("pipe error!"); /* 无法打开一个管道错*/ exit(1); } if ( (pid = fork()) < 0) { perror("fork"); exit(2); } if (pid > 0) /* 父进程 */ { close(p[0]); /* 关闭读端(连接) */ write(p[1], msg1, MSGSIZE); write(p[1], msg2, MSGSIZE); write(p[1], msg3, MSGSIZE); wait((int *)0); } if (pid == 0) /* 子进程 */ { close(p[1]); /* 关闭写端 */ for (i=0; i < 3; i++) { read(p[0], inbuf, MSGSIZE); printf("%s\n", inbuf); } } return 0; }
结果实现不同进行之间的通信,通过不同管道进行读写操作:

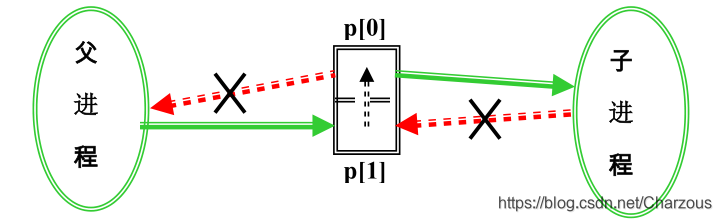
进程管道通信需要注意下面几个问题:
(1)关闭了一个方向
(2)管道的大小(Size)
每个管道都有一个大小限制,通常大约为 5k (5120) 个字节
(3)写问题:
write() 将被挂起(阻塞),如果管道中无法存放正文(容量不够),可能在写的过程中发生阻塞;
如果向一个没有读连接的管道写,将返回 -1, 且 errno 被置成 EPIPE。errno 是一个全局变量。
(4)读问题:
read() 将被阻塞,如果管道空,且有一个 写连接开放,read() 将返回 0 。
如果为空,且没有任何写连接,就此, 读进程可以知道通信结束。
四、pipe()下生产者与消费者问题
经典同步互斥问题,现在初始化有一个生产者,两个消费者,只有生产者有生产物资后,消费者才能使用,否则进入等待。


#include<sys/types.h> #include<sys/file.h> #include<string.h> #include<sys/wait.h> #include<unistd.h> #include<stdlib.h> #include <stdio.h> char r_buf[4]; //读缓冲 char w_buf[4]; //写缓冲 int pipe_fd[2]; pid_t pid1, pid2; int producer(int id); int consumer(int id); int i,pid,status; /* status 用来表示进程退出的状态 */ int main() { if(pipe(pipe_fd)<0) { printf("pipe create error \n"); exit(-1); } else { printf("pipe is created successfully!\n"); if((pid1=fork())==0) producer(1); if((pid2=fork())==0) consumer(2); } close(pipe_fd[0]);//否则会有读者或者写者永远等待 close(pipe_fd[1]); for(i=0;i<2;i++) pid=wait(&status); /* 等待子进程完成(取返回状态信息),主进程后 面未利用子进程的什么结果,直接在子进程完成后退出 */ exit(0); } int producer(int id) { int i; printf("producer %d is running!\n",id); close(pipe_fd[0]); for(i=1;i<10;i++) { sleep(3); strcpy(w_buf,"aaa\0"); if(write(pipe_fd[1],w_buf,4)==-1) printf("write to pipe error\n"); } close(pipe_fd[1]); printf("producer %d is over!\n",id); exit(id); } int consumer(int id) { close(pipe_fd[1]); printf("consumer %d is running!\n",id); strcpy(w_buf,"bbb\0"); while(1) { sleep(1); strcpy(r_buf,"eee\0"); if(read(pipe_fd[0],r_buf,4)==0) break; printf("consumer %d get %s, while the w_buf is %s\n",id,r_buf,w_buf); } close(pipe_fd[0]); printf("consumer %d is over!\n", id); exit(id); }
进程执行如下:
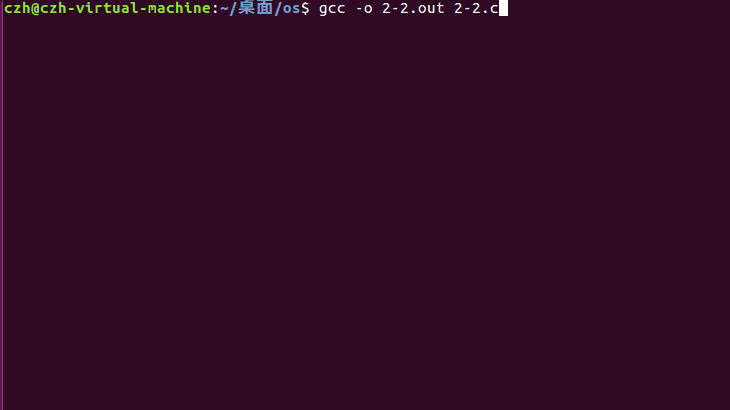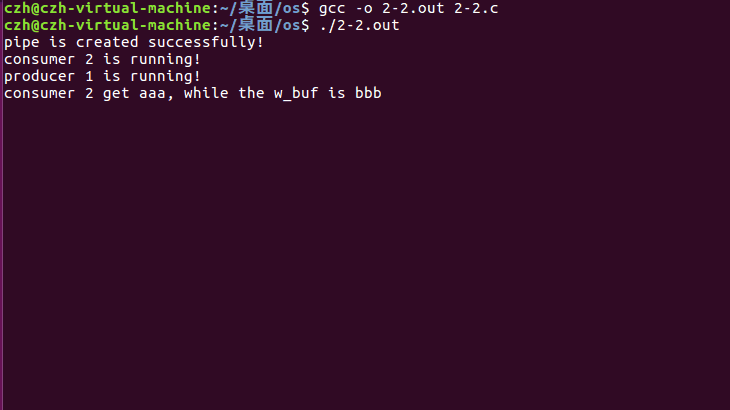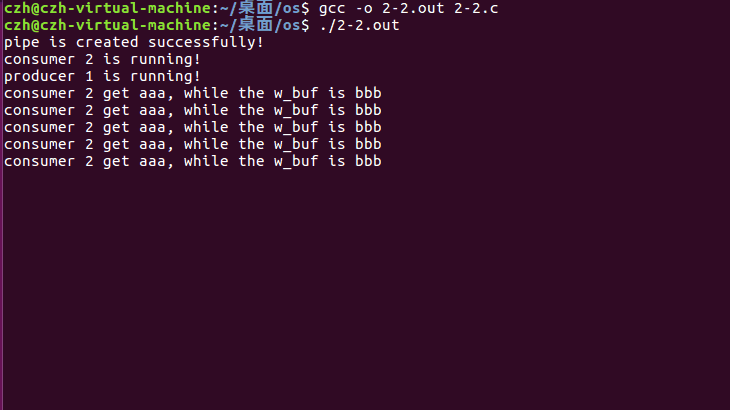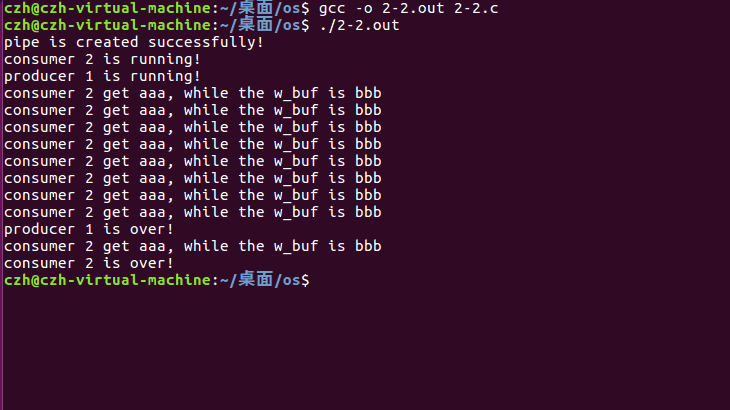
总结
学习之后的一篇总结,玩转Linux编程,更加深刻地去体验其中的原理,掌握基本的知识和操作。这篇记录总结学习,可以认识到程序与进程的区别,还有进程间通信机制,进程的执行顺序和关系。Linux系统调用函数的认识和使用更进一步掌握相关Linux知识。
另外,进程间的通信机制还有其他方法,进程信号中断通信内容,互斥同步问题,银行家算法等期待后续的学习总结记录,学习分享记录每一步,希望也能够帮助到有需要的朋友,大佬也多多指正!
我的CSDN博客:https://blog.csdn.net/Charzous/article/details/108287075
我的博客园:https://www.cnblogs.com/chenzhenhong/p/13580356.html
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/Charzous/article/details/108287075

