YOLO解读
1. 检测算法
1.1 传统检测算法

传统的检测算法的步骤如上图所示:
- 给定输入,获取候选框(regiion proposal);
- 手动提取候选框的特征;
- 利用传统的机器学习算法(SVM, NN)对候选框进行分类,得到最终的结果;
传统检测算法的缺点是分阶段进行,且在每个阶段中都可能存在误差,且误差存在叠加的可能;
1.2 Two-stage检测算法
Two-Stage的检测算法如下图所示,会隐式地生成一些region proposal,并借助CNN完成目标检测
1. 3 One-Stage检测算法
One-Stage检测算法的思想,可以用下图简单的描述,就是给定输入,经过CNN一系列计算后,直接得到我们想要的输出;

那么,相比于Two-stage检测算法, one-stage有:
- 继承了Two-stage算法端到端的思想
- 去掉生成region proposal的冗余步骤
那么,如何保证算法的效果呢?
2. YOLO v1
YOLO的优势:
- 特别快(18 faster rcnn [ZF] vs 45 yolo)
- 逐渐流行标准化(62.1 mAP vs 63.4)
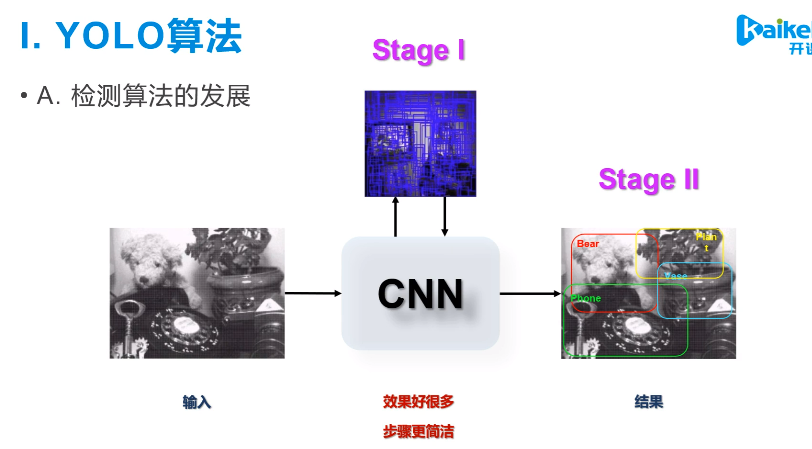
2.1 核心思想
首先,对输入图像进行划分成\(S\times S\)个格子(grid cell),如果物体(object)的中心落在某个cell中,则该cell就负责预测这个物体;
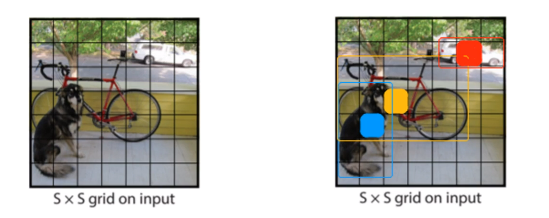
每一个grid cell负责预测B个bounding box, 对于每一个bbx,有:
- bbx的位置信息: x, y, w, h;
- bbx的置信度:
其中,如果bbx中存在object,则\(P_r(object) = 1\), 否则为0;
其中,\(IoU_{pred}^{truth}\)表示,bbx与真实物体框的IoU;
另外,每个grid cell也预测C个类别的条件概率, 表示每一个grid cell属于C个类别的概率;
所以,网络最终的输出维度为:
2.2 损失函数
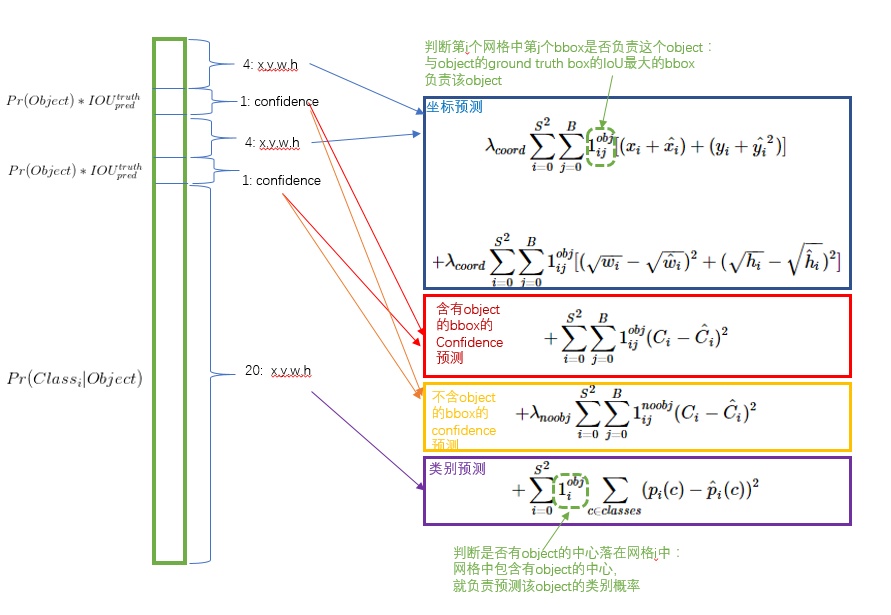
如下图所示,为YOLO算法核心的损失函数,主要包含三个部分的损失:
- bbx坐标预测的损失;
- bbx置信度预测的损失;
- grid cell类别预测的损失;
2.2.1 bbx坐标预测的损失
坐标预测的损失函数部分为(上图有点问题):
其中,
-
\(i \in (0, S^2)\)表示共有\(S^2\)个grid cell, \(j \in (0, B)\)表示每个grid cell包含有\(B\)个bbx;
-
\(1_{ij}^{obj}\)表示第\(i\)个grid cell中的第\(j\)个bbx中,是否负责预测这个物体, 判断是否预测的依据在于B个中的某一个bbx与真实物体Ground Truth的IoU最大; 如果,bbx负责对该物体的预测, 则值为1, 否则为0;;
-
对于坐标\(x, y\)预测的损失,采用均方误差;(基于均方误差最小化来进行模型求解的方法称为"最小二乘法")
-
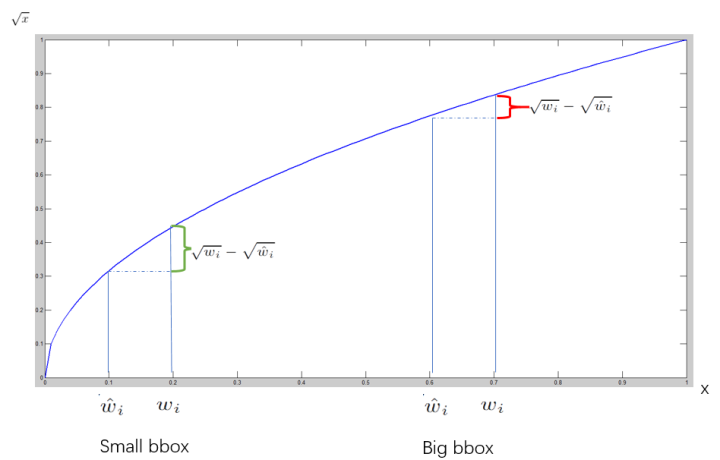
对于坐标\(w, h\)预测的损失,也是采用均方误差;但是重要的是对值取开方(原因下面会解释);
-
\(\lambda_{coord}\)表示对坐标损失函数权重,该权重大一些,是因为图像中包含物体的cell比较少一些;
在计算坐标\(w, h\)损失取开方的解释如下:
取开方后,对于大的bbx与小的bbx,在相同大小差异条件下,损失差别不大;
2.2.2 bbx置信度预测的损失
bbx预测的置信度损失如下:
对于bbx置信度损失的计算分成两个部分,一部分是某些负责对Object预测的bbx的置信度损失,另一部分是剩下的bbx的置信度损失;
- \(1_{ij}^{obj}\)表示负责预测object的bbx,\(1_{ij}^{noobj}\)表示不负责预测object的bbx;
- \(\lambda_{noobj}=0.5\)表示基于较小的权重,因为这样的bbx很多;
- 另外,bbx置信度的损失也采用均方误差的形式;
2.2.3 grid cell 类别预测的损失
对于每一个grid cell中,类别预测的损失如下:
- 类别损失只针对grid cell,且只计算负责预测object的bbx的损失;
- grid cell类别损失的计算也采用均方误差的形式;
2.3 总结
优点:
- 速度更快;
- 站在全局的角度进行预测,网络的输入是整张图片,更小的背景误差;
- 能够学习到泛化能力更强的特征;
缺点:
- 对密集的小物体检测效果不好;假如多个物体的中心落在同一个grid cell中;
- 难以泛化到新的不常见的长宽比物体; 利用anchor解决
- 损失函数同等对待小的bbx和大的bbx;
- 准确率无法达到state-of-art的水平;
3. YOLO v2
YOLO v2是在YOLO v1的基础上增加了一系列的设定,如下图所示:

3.1 Batch Normalization
加入BN层,移除Dropout,用于模型正则化,正常操作;
3.2 hi-res classifier
引入更高精度的分类器(classifier);
- 使用小的size在ImageNet上做预训练:\(224 \times 224\)
- 用大的size继续finetune:\(448 \times 448\)
- 在customized的数据集上finetune;
- 最终获得\(13 \times 13\)的feature map;
3.3 Anchor
3.3.1 anchor boxes
- Anchor是预设好的虚拟边框;
- 最终的生成框由Anchor回归而来;
(为什么最终的预测框由Anchor回归而来呢?将每一个grid cell都设置一些anchor,那么由这些anchor向真实框进行回归,肯定比初始化预测框向真实框回归简单,因此,由anchor得到预测框;)
因此,网络的输出为:
(Anchor如何起到的作用,下文会描述;)
3.3.2 dimension priors
在Faster R-CNN中,Anchor的选择是根据经验选择的,在训练的过程中会调整Anchor Box的尺寸;
那么,如果一开始就选择了一个更好的、更有代表性的先验Anchor Box,网络就更加容易学到准确的位置;
如何选择呢?
YOLO v2采用K-means聚类的方式训练数据集中的Ground Truth Box,用于得到Anchor Box的维度;
而一般k-means算法采用的是均方误差用于距离度量,这样会导致大的Box会产生更多的误差,聚类结果会产生偏离,因此使用IoU值作为距离度量函数;
3.3.3 location prediction
在YOLO v2中,没有直接对Bounding boxes求回归(即直接得到box的中心位置和长宽),其中心点可能会在图像中的任意位置,这样可能会导致模型训练不稳定;
在这个检测任务中,共包含:Anchor Box、Ground Truth Box、Prediction Box;其中,Anchor Box和Ground Truth Box是不变的,前者是人为设定的,后者是真实存在的;因此,在训练的过程中,变化的只是Prediction Box;
因为Anchor Box与Ground Truth Box的尺寸比较接近,因此由Anchor Box回归得到最终的Prediction Box更简单一些;
因此,我们则希望Prediction Box与Anchor Box的位置偏差,趋近于Ground Truth Box与Anchor Box的位置偏差;
那么,Prediction Box与Anchor Box的位置偏差表示为:
其中,\(x_p, y_p, w_p, h_p\)表示Prediction Box的位置信息,\(x_a, y_a, w_a, h_a\)表示Anchor Box的位置信息;
Ground Truth Box与Anchor Box的位置偏差表示为:
其中,\(x_g, y_g, w_g, h_g\)表示Ground Truth的位置信息;
网络的输出是\(x_p, y_p, w_p, h_p\),再结合Anchor Box即可得到最终的bbx位置信息,即:
然而,上面这种计算方式是没有约束的;即:假如\(t_x ^p = 1\),则边界框的位置则向右移动先验框的一个宽度大小;当\(t_x^p = -1\),则边界框的位置则向左移动先验框的一个宽度大小;所以每个位置的预测的边界框可以落在图片的任何位置,这将导致模型不稳定,需要长时间才能预测出正确的offset;
解决方法就是预测边界框的中心点对于对应grid cell左上角位置的相对偏移;为了将边界框中心点约束再grid cell中,使用sigmoid处理偏移值;因此,边界框的实际位置计算方式为:
其中,\(b_x, b_y, b_w, b_h\)就是最终边界框的位置信息;\(c_x, c_y\)表示当前grid cell的左上角坐标(相对于feature map);
\(p_w, p_h\)表示先验框的宽度与长度,它们的值也是相对于特征图大小的;
因此,预测的边界框相对于整张图的位置为:
其中,\(W, H\)表示feature map的宽度和长度;
因此,如果将上述得到的值再乘以原始图像的宽度和长度,则就可以得到最终的预测框的位置了;
3.4 passthrough(Fine-grained feature)
将网络的深层特征与浅层特征连接在一起,将输出的特征包含物理信息和语义信息;
那么,如何连接高分辨特征与低分辨特征呢?作者reorg层,实现从高分辨向地分辨的转换;
那么,连接的部分可以称为short-cut,或者skip-connnection;
(小的feature map变成大的feature map,两种方式:转置卷积、上采样)
3.5 multi-scale
在训练的过程中,每10个epoch,网络会随机选择一个新的输入尺寸进行训练;
尺度分布在:\(320, 352, ..., 608\);
为了保证网络模型能够接入不同尺度的图像,移除了FC层,使其能够承接任意size的输入,提升模型的鲁棒性;
4. YOLO v3
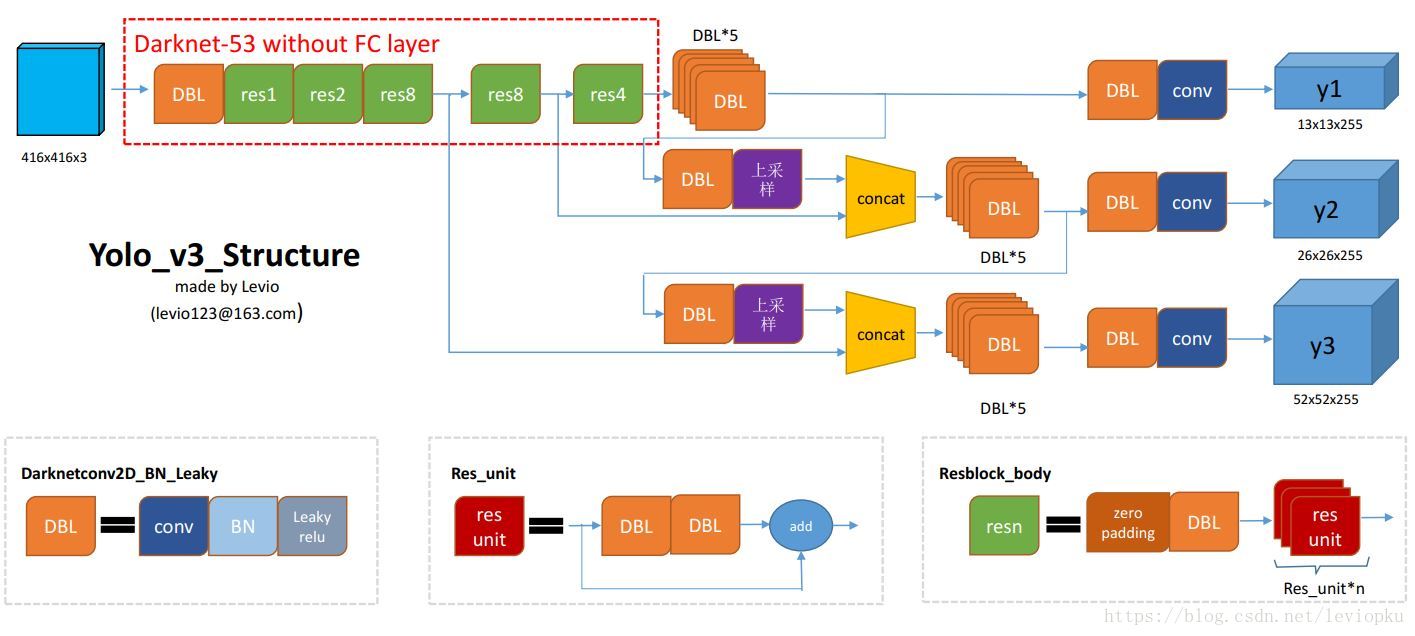
上图表示了YOLO v3整体的网络结构,
-
其中DBL表示Darknet conv2d + BN + Leaky ReLU,是YOLO v3的基本组件;
-
res unit表示残差块
-
concat表示拼接,也可以称为skip connection,short-cut;
4.1 Backbone
在YOLO v3中,没有池化层和全连接层,feature map尺度的降低时通过调整卷积核的步长进行实现的;
YOLO v3的整体结构类似于YOLO v2,但具体细节则存在很大的不同:
相同点:
- 沿用YOLO的“分而治之”的策略,即通过划分单元格来进行检测;
- 从YOLO v2开始,卷积后面一般跟着BN和Leaky ReLU;
- 端到端的训练,即一个loss function;
不同点:
- YOLO v3抛弃了最大池化层,使用步长为2的卷积层代替;
- 引入了残差结构,
- 借鉴了特征金字塔网络(FPN),采用多尺度来对不同的size的目标进行检测;
4.2 Output
如下图所示,可以看得到YOLO v3的输出包含三个尺度的tensor,维度分别为\(13\times 13 \times 255, 26 \times 26 \times 255,52 \times 52 \times 255\);这就是借鉴FPN的思想,特征金字塔:得到不同尺度下的特征,并利用该特征金字塔进行目标检测,越精细的特征可以检测除越精细的物体;
YOLO v3中设定一个grid cell中预测3个bbx;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号