
Impala原理及其调优
Impala介绍
Impala支持的文件格式
Impala可以对Hadoop中大多数格式的文件进行查询。它能通过create table和insert的方式将一部分格式的数据加载到table中,但值得注意的是,有一些格式的数据它是无法写入的(write to)。对于Impala无法写入的数据格式,我们只能通过Hive建表,通过Hive进行数据的写入,然后使用Impala来对这些保存好的数据执行查询操作。
|
文件类型 |
文件格式 |
压缩编码 |
能否CREATE ? |
能否INSERT ? |
|
Parquet |
结构化 |
Snappy GZIP |
能 |
能 |
|
Text |
非结构化 |
LZO |
能。 如果建表时没有指定存储类型,默认采用未压缩的text,字段由ASCII编码的0x01字符串分割。 |
能。 如果使用了LZO压缩,则只能通过Hive建表和插入数据。 |
|
Avro |
结构化 |
Snappy GZIP Deflate BZIP2 |
在Impala 1.4.0 或者更高的版本上支持,之前的版本只能通过Hive来建表。 |
不能。 只能通过LOAD DATA的方式将已经转换好格式的数据加载进去,或者使用Hive来插入数据。 |
|
RCFile |
结构化 |
Snappy GZIP Deflate BZIP2 |
能 |
不能。 只能通过LOAD DATA的方式将已经转换好格式的数据加载进去,或者使用Hive来插入数据。 |
|
SequenceFile |
结构化 |
Snappy GZIP deflate BZIP2 |
能 |
不能。 只能通过LOAD DATA的方式将已经转换好格式的数据加载进去,或者使用Hive来插入数据。 |
Impala支持以下压缩编码:
- Snappy – 推荐的编码,因为它在压缩率和解压速度之间有很好的平衡性,Snappy压缩速度很快,但是不如GZIP那样能节约更多的存储空间。Impala不支持Snappy压缩的text file。
- GZIP – 压缩比很高能节约很多存储空间,Impala不支持GZIP压缩的text file。
- Deflate – Impala不支持GZIP压缩的text file。
- BZIP2 - Impala不支持BZIP2压缩的text file。
- LZO – 只用于text file,Impala可以查询LZO压缩的text格式数据表,但是不支持insert数据,只能通过Hive来完成数据的insert。
Impapla如何执行查询
下面这个图表示了Impala在Hadoop集群中所处的位置:

Impala由以下的组件组成:
- Clients – Hue、ODBC clients、JDBC clients、和Impala Shell都可以与Impala进行交互,这些接口都可以用在Impala的数据查询以及对Impala的管理。
- Hive Metastore – 存储Impala可访问数据的元数据。例如,这些元数据可以让Impala知道哪些数据库以及数据库的结构是可以访问的,当你创建、删除、修改数据库对象或者加载数据到数据表里面,相关的元数据变化会自动通过广播的形式通知所有的Impala节点,这个通知过程由catalog service完成。
- Cloudera Impala – Impala的进程运行在各个数据节点(Datanode)上面。每一个Impala的实例都可以从Impala client端接收查询,进而产生执行计划、协调执行任务。数据查询分布在各个Impala节点上,这些节点作为worker,并行执行查询。
- HBase和HDFS – 存储用于查询的数据。
Impala执行的查询有以下几个步骤:
- 客户端通过ODBC、JDBC、或者Impala shell向Impala集群中的任意节点发送SQL语句,这个节点的impalad实例作为这个查询的协调器(coordinator)。
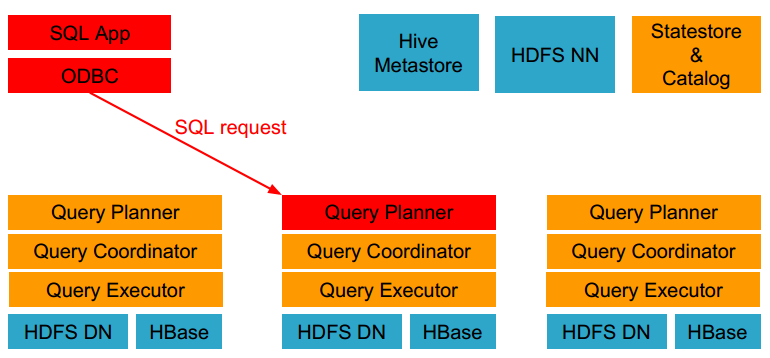
- Impala解析和分析这个查询语句来决定集群中的哪个impalad实例来执行某个任务。
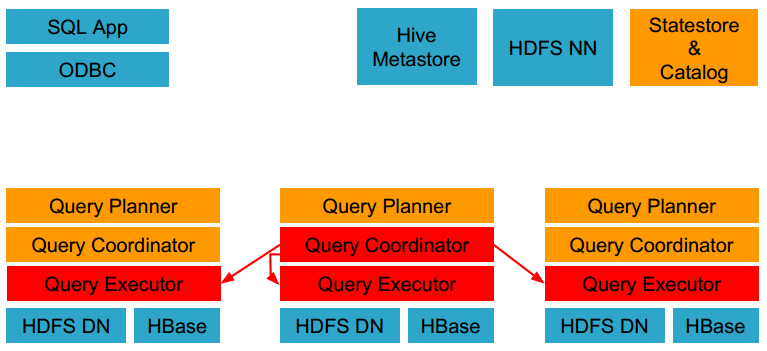
- HDFS和HBase给本地的impalad实例提供数据访问。
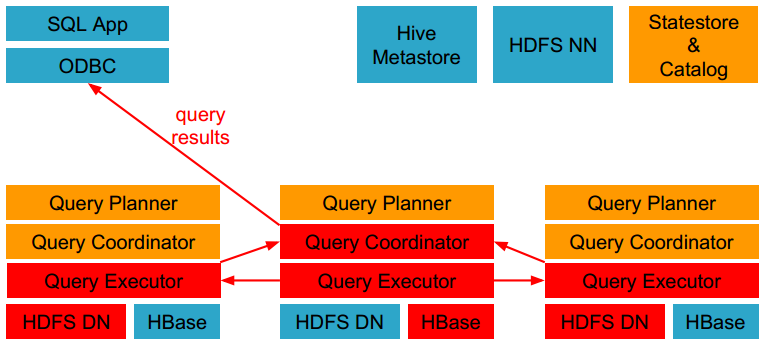
- 各个impalad向协调器impalad返回数据,然后由协调器impalad向client发送结果集。



Impala为什么比Hive速度快
Impala自称数据查询效率比Hive快几倍甚至数十倍,它之所以这么快的原因大致有以下几点:
- 真正的MPP查询引擎。
- 使用C++开发而不是Java,降低运行负荷。
- 运行时代码生成(LLVM IR),提高效率。

- 全新的执行引擎(不是Mapreduce)。
- 在执行SQL语句的时候,Impala不会把中间数据写入到磁盘,而是在内存中完成了所有的处理。
- 使用Impala的时候,查询任务会马上执行而不是生产Mapreduce任务,这会节约大量的初始化时间。
- Impala查询计划解析器使用更智能的算法在多节点上分布式执行各个查询步骤,同时避免了sorting和shuffle这两个非常耗时的阶段,这两个阶段往往是不需要的。
- Impala拥有HDFS上面各个data block的信息,当它处理查询的时候能够在各个datanode上面更均衡的分发查询。
- 另外一个关键原因是,Impala为每个查询产生汇编级的代码,当Impala在本地内存中运行的时候,这些汇编代码执行效率比其它任何代码框架都更快,因为代码框架会增加额外的延迟。
Impala核心组件
Impala Daemon
Impala的核心组件是运行在各个节点上面的impalad这个守护进程(Impala daemon),它负责读写数据文件,接收从impala-shell、Hue、JDBC、ODBC等接口发送的查询语句,并行化查询语句和分发工作任务到Impala集群的各个节点上,同时负责将本地计算好的查询结果发送给协调器节点(coordinator node)。
你可以向运行在任意节点的Impala daemon提交查询,这个节点将会作为这个查询的协调器(coordinator node),其他节点将会传输部分结果集给这个协调器节点。由这个协调器节点构建最终的结果集。在做实验或者测试的时候为了方便,我们往往连接到同一个Impala daemon来执行查询,但是在生产环境运行产品级的应用时,我们应该循环(按顺序)的在不同节点上面提交查询,这样才能使得集群的负载达到均衡。
Impala daemon不间断的跟statestore进行通信交流,从而确认哪个节点是健康的能接收新的工作任务。它同时接收catalogd daemon(从Impala 1.2之后支持)传来的广播消息来更新元数据信息,当集群中的任意节点create、alter、drop任意对象、或者执行INSERT、LOAD DATA的时候触发广播消息。
Impala Statestore
Impala Statestore检查集群各个节点上Impala daemon的健康状态,同时不间断地将结果反馈给各个Impala daemon。这个服务的物理进程名称是statestored,在整个集群中我们仅需要一个这样的进程即可。如果某个Impala节点由于硬件错误、软件错误或者其他原因导致离线,statestore就会通知其他的节点,避免其他节点再向这个离线的节点发送请求。
由于statestore是当集群节点有问题的时候起通知作用,所以它对Impala集群并不是有关键影响的。如果statestore没有运行或者运行失败,其他节点和分布式任务会照常运行,只是说当节点掉线的时候集群会变得没那么健壮。当statestore恢复正常运行时,它就又开始与其他节点通信并进行监控。
Impala Catalog
Imppalla catalog服务将SQL语句做出的元数据变化通知给集群的各个节点,catalog服务的物理进程名称是catalogd,在整个集群中仅需要一个这样的进程。由于它的请求会跟statestore daemon交互,所以最好让statestored和catalogd这两个进程在同一节点上。
Impala 1.2中加入的catalog服务减少了REFRESH和INVALIDATE METADATA语句的使用。在之前的版本中,当在某个节点上执行了CREATE DATABASE、DROP DATABASE、CREATE TABLE、ALTER TABLE、或者DROP TABLE语句之后,需要在其它的各个节点上执行命令INVALIDATE METADATA来确保元数据信息的更新。同样的,当你在某个节点上执行了INSERT语句,在其它节点上执行查询时就得先执行REFRESH table_name这个操作,这样才能识别到新增的数据文件。需要注意的是,通过Impala执行的操作带来的元数据变化,有了catalog就不需要再执行REFRESH和INVALIDATE METADATA,但如果是通过Hive进行的建表、加载数据,则仍然需要执行REFRESH和INVALIDATE METADATA来通知Impala更新元数据信息。
Impala与同类工具的性能对比
以下测试环境以及测试数据来自Impala官方博客。
环境配置
集群环境
所有的测试都在同一个集群上面运行,保证硬件环境的一致性。集群有21个节点,每个节点的配置都一样:
- 2个处理器、12核心、Intel Xeon CPU E5-2630L 0 2.00GHz
- 12块磁盘932GB(一个磁盘用于操作系统,其余的用于HDFS)
- 384GB内存
对比环境
- Impala 1.3.0
- Hive-on-Tez: The final phase of the 18-month Stinger initiative (aka Hive 0.13)
- Shark 0.9.2: A port of Hive from UC Berkeley AMPLab that is architecturally similar to Hive-on-Tez, but based on Spark instead of Tez. Shark testing was done on a native in-memory dataset (RDD) as well as HDFS.
- Presto 0.60: Facebook’s query engine project
查询环境
- 为了确保Hadoop每个节点具有代表性的真实负载,所有的查询在20个节点上的15TB数据集上进行。
- 我们针对不同的处理工具统一采用Snappy压缩,不同的工具选用其性能最佳的数据文件格式,Impala用Apache Parquet、Hive-on-Tez用ORC、Presto用RCFile、Shark用ORC。
- 不同的处理工具都使用标准的测试技巧(多重运行、调优,等等)。
测试结果
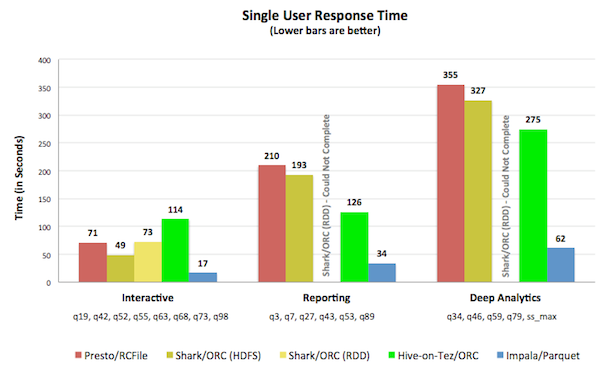
单用户场景
Impala on Parquet运行效率最高,比其后的Shark 0.9.2平均快了5倍。
多用户场景
我们同时测试了单用户和10个用户做对比,测试中Impala更好的体现了其性能优势,比其后的工具快了9.5倍。

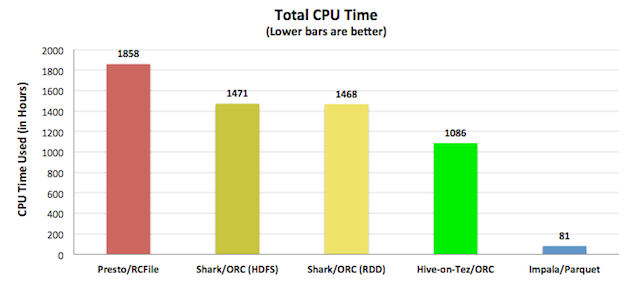
吞吐量和硬件使用率
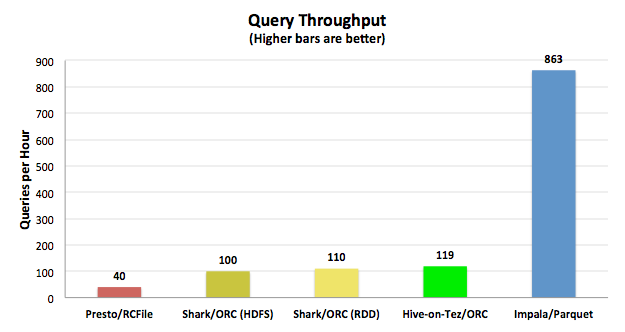
下面的CPU效率解释了为什么Impala能够做到低延迟和高吞吐量,绝大多数的性能和并发性都在于查询引擎自身的CPU利用效率。
Impala调优
表和字段的统计分析
当数据表的统计信息可用的时候,Impala能够更好的对查询进行优化,通过统计信息它能更清楚的知道数据的分布情况,并有效地并行处理和分发工作任务。
在之前,Impala依赖于Hive的机制产生mapreduce任务来收集统计信息。为了更好的用户体验和可靠性,Impala在1.2.2及其之后的版本中实现了自己的COMPUTE STATS语法来进行信息统计,结合使用SHOW TABLE STATS和SHOW COLUMN STATS这两种语法。
用Impala统计表和字段信息的例子如下:
[localhost:21000] > show table stats store;
+-------+--------+--------+--------+
| #Rows | #Files | Size | Format |
+-------+--------+--------+--------+
| -1 | 1 | 3.08KB | TEXT |
+-------+--------+--------+--------+
Returned 1 row(s) in 0.03s
[localhost:21000] > show column stats store;
+--------------------+-----------+------------------+--------+----------+----------+
| Column | Type | #Distinct Values | #Nulls | Max Size | Avg Size |
+--------------------+-----------+------------------+--------+----------+----------+
| s_store_sk | INT | -1 | -1 | 4 | 4 |
| s_store_id | STRING | -1 | -1 | -1 | -1 |
| s_rec_start_date | TIMESTAMP | -1 | -1 | 16 | 16 |
| s_rec_end_date | TIMESTAMP | -1 | -1 | 16 | 16 |
| s_closed_date_sk | INT | -1 | -1 | 4 | 4 |
| s_store_name | STRING | -1 | -1 | -1 | -1 |
| s_number_employees | INT | -1 | -1 | 4 | 4 |
| s_floor_space | INT | -1 | -1 | 4 | 4 |
| s_hours | STRING | -1 | -1 | -1 | -1 |
| s_manager | STRING | -1 | -1 | -1 | -1 |
| s_market_id | INT | -1 | -1 | 4 | 4 |
| s_geography_class | STRING | -1 | -1 | -1 | -1 |
| s_market_desc | STRING | -1 | -1 | -1 | -1 |
| s_market_manager | STRING | -1 | -1 | -1 | -1 |
| s_division_id | INT | -1 | -1 | 4 | 4 |
| s_division_name | STRING | -1 | -1 | -1 | -1 |
| s_company_id | INT | -1 | -1 | 4 | 4 |
| s_company_name | STRING | -1 | -1 | -1 | -1 |
| s_street_number | STRING | -1 | -1 | -1 | -1 |
| s_street_name | STRING | -1 | -1 | -1 | -1 |
| s_street_type | STRING | -1 | -1 | -1 | -1 |
| s_suite_number | STRING | -1 | -1 | -1 | -1 |
| s_city | STRING | -1 | -1 | -1 | -1 |
| s_county | STRING | -1 | -1 | -1 | -1 |
| s_state | STRING | -1 | -1 | -1 | -1 |
| s_zip | STRING | -1 | -1 | -1 | -1 |
| s_country | STRING | -1 | -1 | -1 | -1 |
| s_gmt_offset | FLOAT | -1 | -1 | 4 | 4 |
| s_tax_precentage | FLOAT | -1 | -1 | 4 | 4 |
+--------------------+-----------+------------------+--------+----------+----------+
Returned 29 row(s) in 0.04s
[localhost:21000] > compute stats store;
+------------------------------------------+
| summary |
+------------------------------------------+
| Updated 1 partition(s) and 29 column(s). |
+------------------------------------------+
Returned 1 row(s) in 1.88s
[localhost:21000] > show table stats store;
+-------+--------+--------+--------+
| #Rows | #Files | Size | Format |
+-------+--------+--------+--------+
| 12 | 1 | 3.08KB | TEXT |
+-------+--------+--------+--------+
Returned 1 row(s) in 0.02s
[localhost:21000] > show column stats store;
+--------------------+-----------+------------------+--------+----------+----------------+
| Column | Type | #Distinct Values | #Nulls | Max Size | Avg Size |
+--------------------+-----------+------------------+--------+----------+----------------+
| s_store_sk | INT | 12 | -1 | 4 | 4 |
| s_store_id | STRING | 6 | -1 | 16 | 16 |
| s_rec_start_date | TIMESTAMP | 4 | -1 | 16 | 16 |
| s_rec_end_date | TIMESTAMP | 3 | -1 | 16 | 16 |
| s_closed_date_sk | INT | 3 | -1 | 4 | 4 |
| s_store_name | STRING | 8 | -1 | 5 | 4.25 |
| s_number_employees | INT | 9 | -1 | 4 | 4 |
| s_floor_space | INT | 10 | -1 | 4 | 4 |
| s_hours | STRING | 2 | -1 | 8 | 7.08330011367797 |
| s_manager | STRING | 7 | -1 | 15 | 12 |
| s_market_id | INT | 7 | -1 | 4 | 4 |
| s_geography_class | STRING | 1 | -1 | 7 | 7 |
| s_market_desc | STRING | 10 | -1 | 94 | 55.5 |
| s_market_manager | STRING | 7 | -1 | 16 | 14 |
| s_division_id | INT | 1 | -1 | 4 | 4 |
| s_division_name | STRING | 1 | -1 | 7 | 7 |
| s_company_id | INT | 1 | -1 | 4 | 4 |
| s_company_name | STRING | 1 | -1 | 7 | 7 |
| s_street_number | STRING | 9 | -1 | 3 | 2.83330011367797 |
| s_street_name | STRING | 12 | -1 | 11 | 6.58330011367797 |
| s_street_type | STRING | 8 | -1 | 9 | 4.83330011367797 |
| s_suite_number | STRING | 11 | -1 | 9 | 8.25 |
| s_city | STRING | 2 | -1 | 8 | 6.5 |
| s_county | STRING | 1 | -1 | 17 | 17 |
| s_state | STRING | 1 | -1 | 2 | 2 |
| s_zip | STRING | 2 | -1 | 5 | 5 |
| s_country | STRING | 1 | -1 | 13 | 13 |
| s_gmt_offset | FLOAT | 1 | -1 | 4 | 4 |
| s_tax_precentage | FLOAT | 5 | -1 | 4 | 4 |
+--------------------+-----------+------------------+--------+----------+----------------
Returned 29 row(s) in 0.04s
启用block location跟踪
当在Impala上执行查询的时候,会多个datanode上分布式地读取block数据,如果Impala拥有更多的block信息,将会更高效的获取数据并处理。可以通过以下步骤来启用block location跟踪:
- 修改hdfs-site.xml文件添加以下内容:
<property> <name>dfs.datanode.hdfs-blocks-metadata.enabled</name> <value>true</value> </property>
- 拷贝Hadoop集群的hdfs-site.xml和core-site.xml文件到各个Impala节点的配置目录/etc/impala/conf中。
- 重启Hadoop集群中的所有datanode。
启用native checksumming
对大量数据计算校验和(checksum)会带来巨大的时间损耗,因此用本地库(native library)来执行校验和会带来性能上的提升。在Impala中可以采用以下方式来启用本地校验:
- 如果Impala是用Cloudera Manager部署的,默认已经开启了本地校验。
- 如果是手动安装的Impala,你必须手动安装Hadoop本地库libhadoop.so,如果这个本地库找不到,你会在Impala日志中看到这样的信息:"Unable to load native-hadoop library for your platform... using built-in-java classes where applicable"。
允许Impala执行short-circuit read
Short-circuit read意味着会从datanode的本地文件系统直接读取数据,而不用首先与datanode进行通信,这肯定会提高性能。你必须使用Cloudera CDH 4.2或更高的版本来达到快速的short-circuit读取数据。可以通过以下步骤来进行设置:
- 修改各个Impala节点上的hdfs-site.xml文件:
<property> <name>dfs.client.read.shortcircuit</name> <value>true</value> </property> <property> <name>dfs.domain.socket.path</name> <value>/var/run/hadoop-hdfs/dn._PORT</value> </property> <property> <name>dfs.client.file-block-storage-locations.timeout</name> <value>3000</value> </property>
- 确保/var/run/hadoop-hdfs/目录对用户是可写入的。
- 拷贝Hadoop集群的hdfs-site.xml和core-site.xml文件到各个Impala节点的配置目录/etc/impala/conf中。
- 重启Hadoop集群中的所有datanode。
增加更多的Impala节点
事实证明更多的Impala节点会显著地提高性能,这跟Hadoop使用更多的datanode提高性能是一样的。拥有更多的节点会让数据分散到更多的节点上,在执行查询的时候能够分发更多的任务并行执行,从而提高整体执行性能。
执行查询时优化内存的使用
在启动Impala守护进程的时候可以使用-mem_limits参数来限制内存消耗,这个参数只对查询(query)进行内存限制。
查询的执行依赖于内存
如果数据集太大以至于超出了机器的可用内存,这个查询将会失败。Impala对内存的使用并不直接根据数据集的大小决定,它是根据查询的类型而变化的。聚合查询需要的内存跟group之后的数据量一样,连接查询(join)需要的内存量等价于除开最大表之外的所有表的总大小。
采用资源隔离
如果你使用的是Cloudera Manager,可以使用Cloudera Manager的设备控制器(cgroups)机制来实现资源隔离(resource isolation)。更多信息请阅读Cloudera Manager文档中对resource isolation的描述。
----end
本文连接:http://www.cnblogs.com/chenz/articles/3947147.html
作者:chenzheng
联系:vinkeychen@gmail.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号