
locally weighted regression - CS229
欠拟合和过拟合
看下方的三张图
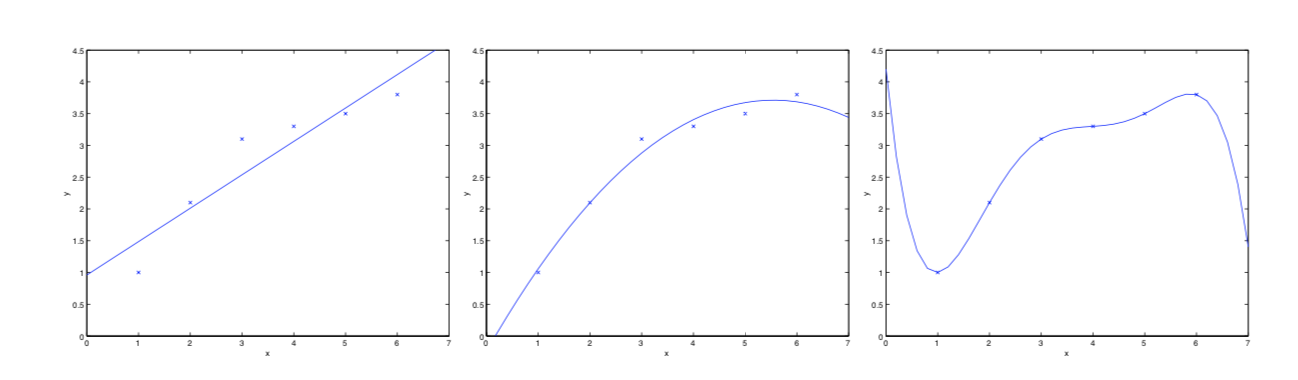
第一幅拟合为了 y=θ0+θ1xy=θ0+θ1x 的一次函数
第二幅拟合为了y=θ0+θ1x+θ2x2y=θ0+θ1x+θ2x2 的二次函数
第三幅拟合为了 y=∑5j=0θjxjy=∑j=05θjxj的五次项函数
最左边的分类器模型没有很好地捕捉到数据特征,不能够很好地拟合数据,我们称为欠拟合
而最右边的分类器分类了所有的数据,也包括噪声数据,由于构造复杂,后期再分类的新的数据时,对于稍微不同的数据都会识别为不属于此类别,我们称为过拟合
局部加权回归
局部加权回归是一种非参数学习算法,这使得我们不必太担心对于自变量最高次项的选择
我们知道,对于普通的线性回归算法,想要预测 xx 点的yy值,我们通过:
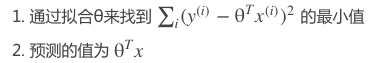
对于局部加权回归算法,我们通过下列步骤预测 y的值:
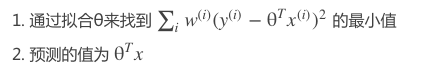
这里的 w(i)是权重,它并非一个定值,我们通过调节w(i)的值来确定不同训练数据对结果的影响力,
当w(i)很小时,它对应的y(i)−θTx(i)也很小,对结果的影响也很小;
而当它很大时,其对应的y(i)−θTx(i)也很大,对结果的影响很大。
w(i)的计算方法有很多种,其中一种公式为: 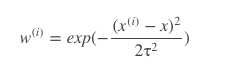
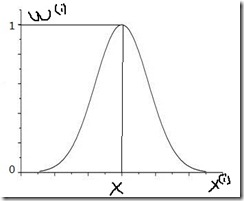
它很像高斯分布,函数图类似下图,要预测的点x对应的中间的顶点处的自变量,可以看出,离xx处越近的地方w(i)值越大,越远的地方w(i)越小,这就使得离x处近的数据对预测结果的影响更大
代码实现
1 from numpy import * 2 import matplotlib.pyplot as plt 3 4 # 加载数据 返回数据和目标值 5 def loadDataSet(fileName): 6 numFeat = len(open(fileName).readline().split('\t')) - 1 7 dataMat = []; labelMat = [] 8 fr = open(fileName) 9 for line in fr.readlines(): 10 lineArr =[] 11 curLine = line.strip().split('\t') 12 for i in range(numFeat): 13 lineArr.append(float(curLine[i])) 14 dataMat.append(lineArr) 15 labelMat.append(float(curLine[-1])) 16 return dataMat,labelMat 17 18 # 利用公式计算回归系数 19 def standRegres(xArr,yArr): 20 xMat = mat(xArr); yMat = mat(yArr).T 21 xTx = xMat.T*xMat # 公式步骤 22 if linalg.det(xTx) == 0.0: 23 print("行列式为0,奇异矩阵,不能做逆") 24 return 25 ws = xTx.I * (xMat.T*yMat) #解线性方程组 26 # ws = linalg.solve(xTx,xMat.T*yMat) # 也可以使用函数来计算 线性方程组 27 return ws 28 29 # 局部加权线性回归 返回该条样本预测值 30 def lwlr(testPoint,xArr,yArr,k=1.0): 31 xMat = mat(xArr); yMat = mat(yArr).T 32 m = shape(xMat)[0] 33 weights = mat(eye((m))) # 创建为单位矩阵,再mat转换数据格式 因为后面是与原数据矩阵运算,所以这里是为了后面运算且不带来其他影响 34 for j in range(m): # 利用高斯公式创建权重W 遍历所有数据,给它们一个权重 35 diffMat = testPoint - xMat[j,:] # 高斯核公式1 36 weights[j,j] = exp(diffMat*diffMat.T/(-2.0*k**2)) # 高斯核公式2 矩阵*矩阵.T 转行向量为一个值 权重值以指数级衰减 37 xTx = xMat.T * (weights * xMat) # 求回归系数公式1 38 if linalg.det(xTx) == 0.0: # 判断是否有逆矩阵 39 print("行列式为0,奇异矩阵,不能做逆") 40 return 41 ws = xTx.I * (xMat.T * (weights * yMat)) # 求回归系数公式2 42 return testPoint * ws 43 44 # 循环所有点求出所有的预测值 45 def lwlrTest(testArr,xArr,yArr,k=1.0): # 传入的k值决定了样本的权重,1和原来一样一条直线,0.01拟合程度不错,0.003纳入太多噪声点过拟合了 46 m = shape(testArr)[0] 47 yHat = zeros(m) 48 for i in range(m): 49 yHat[i] = lwlr(testArr[i],xArr,yArr,k) # 返回该条样本的预测目标值 50 return yHat 51 52 xArr,yArr = loadDataSet('ex0.txt') 53 # 求所有预测值 54 yHat = lwlrTest(xArr,xArr,yArr,0.01) 55 print(yHat) 56 # 绘制数据点和拟合线(局部加权线性回归) 57 xMat = mat(xArr) 58 srtInd = xMat[:,1].argsort(0) # 画拟合线 需要获得所有横坐标从小到大的下标 59 xSort = xMat[srtInd][:,0,:] # 获得排序后的数据 60 61 fig = plt.figure() 62 ax = fig.add_subplot(111) 63 ax.plot(xSort[:,1],yHat[srtInd],color='red') 64 ax.scatter(xMat[:,1].flatten().A[0],mat(yArr).T.flatten().A[0]) 65 plt.show()
