java使用elasticsearch分组进行聚合查询(group by)-项目中实际应用
java连接elasticsearch 进行聚合查询进行相应操作
一:对单个字段进行分组求和
1、表结构图片:
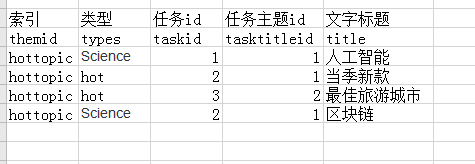
根据任务id分组,分别统计出每个任务id下有多少个文字标题
1.SQL:select id, count(*) as sum from task group by taskid;
java ES连接工具类
public class ESClientConnectionUtil { public static TransportClient client=null; public final static String HOST = "192.168.200.211"; //服务器部署 public final static Integer PORT = 9301; //端口 public static TransportClient getESClient(){ System.setProperty("es.set.netty.runtime.available.processors", "false"); if (client == null) { synchronized (ESClientConnectionUtil.class) { try { //设置集群名称 Settings settings = Settings.builder().put("cluster.name", "es5").put("client.transport.sniff", true).build(); //创建client client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(HOST), PORT)); } catch (Exception ex) { ex.printStackTrace(); System.out.println(ex.getMessage()); } } } return client; } public static TransportClient getESClientConnection(){ if (client == null) { System.setProperty("es.set.netty.runtime.available.processors", "false"); try { //设置集群名称 Settings settings = Settings.builder().put("cluster.name", "es5").put("client.transport.sniff", true).build(); //创建client client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(HOST), PORT)); } catch (Exception ex) { ex.printStackTrace(); System.out.println(ex.getMessage()); } } return client; } //判断索引是否存在 public static boolean judgeIndex(String index){ client= getESClientConnection(); IndicesAdminClient adminClient; //查询索引是否存在 adminClient= client.admin().indices(); IndicesExistsRequest request = new IndicesExistsRequest(index); IndicesExistsResponse responses = adminClient.exists(request).actionGet(); if (responses.isExists()) { return true; } return false; } }
java ES语句(根据单列进行分组求和)
//根据 任务id分组进行求和 SearchRequestBuilder sbuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计出的列别名叫sum TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("sum").field("taskid");
sbuilder.addAggregation(termsBuilder); SearchResponse responses= sbuilder.execute().actionGet(); //得到这个分组的数据集合 Terms terms = responses.getAggregations().get("sum"); List<BsKnowledgeInfoDTO> lists = new ArrayList<>(); for(int i=0;i<terms.getBuckets().size();i++){ //statistics String id =terms.getBuckets().get(i).getKey().toString();//id Long sum =terms.getBuckets().get(i).getDocCount();//数量 System.out.println("=="+terms.getBuckets().get(i).getDocCount()+"------"+terms.getBuckets().get(i).getKey()); }
//分别打印出统计的数量和id值
根据多列进行分组求和
//根据 任务id分组进行求和 SearchRequestBuilder sbuilder = client.prepareSearch("hottopic").setTypes("hot"); //根据taskid进行分组统计,统计出的列别名叫sum TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("sum").field("taskid"); //根据第二个字段进行分组 TermsAggregationBuilder aAggregationBuilder2 = AggregationBuilders.terms("region_count").field("birthplace");
//如果存在第三个,以此类推; sbuilder.addAggregation(termsBuilder.subAggregation(aAggregationBuilder2)); SearchResponse responses= sbuilder.execute().actionGet(); //得到这个分组的数据集合 Terms terms = responses.getAggregations().get("sum"); List<BsKnowledgeInfoDTO> lists = new ArrayList<>(); for(int i=0;i<terms.getBuckets().size();i++){ //statistics String id =terms.getBuckets().get(i).getKey().toString();//id Long sum =terms.getBuckets().get(i).getDocCount();//数量 System.out.println("=="+terms.getBuckets().get(i).getDocCount()+"------"+terms.getBuckets().get(i).getKey()); } //分别打印出统计的数量和id值
对多个field求max/min/sum/avg
SearchRequestBuilder requestBuilder = client.prepareSearch("hottopic").setTypes("hot"); //根据taskid进行分组统计,统计别名为sum TermsAggregationBuilder aggregationBuilder1 = AggregationBuilders.terms("sum").field("taskid")
//根据tasktatileid进行升序排列 .order(Order.aggregation("tasktatileid", true));
// 求tasktitleid 进行求平均数 别名为avg_title
AggregationBuilder aggregationBuilder2 = AggregationBuilders.avg("avg_title").field("tasktitleid");
// AggregationBuilder aggregationBuilder3 = AggregationBuilders.sum("sum_taskid").field("taskid"); requestBuilder.addAggregation(aggregationBuilder1.subAggregation(aggregationBuilder2).subAggregation(aggregationBuilder3)); SearchResponse response = requestBuilder.execute().actionGet(); Terms aggregation = response.getAggregations().get("sum"); Avg terms2 = null; Sum term3 = null; for (Terms.Bucket bucket : aggregation.getBuckets()) { terms2 = bucket.getAggregations().get("avg_title"); // org.elasticsearch.search.aggregations.metrics.avg.InternalAvg term3 = bucket.getAggregations().get("sum_taskid"); // org.elasticsearch.search.aggregations.metrics.sum.InternalSum System.out.println("编号=" + bucket.getKey() + ";平均=" + terms2.getValue() + ";总=" + term3.getValue()); }
如上内容若有不恰当支持,请各位多多包涵并进行点评。技术在于沟通!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号