


canal实时同步mysql数据到redis或ElasticSearch
一、Canal架包下载上传
(一)下载
官网架包地址为:https://github.com/alibaba/canal/releases/tag/canal-1.1.5-alpha-2
本人百度云盘下载地址:
链接:https://pan.baidu.com/s/1MM5YGubaTW3Y2hy1tvBmPw
提取码:jiur
(二)上传解压
创建canal文件夹
cd /usr/local mkdir canal
将下载好的canal上传至Linux服务器 /usr/local/canal目录下进行解压。
tar -zxvf canal.deployer-1.1.5-SNAPSHOT.tar.gz
二、配置MySQL文件
(一)修改MySQL my.cnf配置文件
1.查找MySQL在Linux环境中的my.cnf
mysql --help|grep 'my.cnf'
如图:

2.修改my.cnf
vi /etc/my.cnf
log-bin=mysql-bin #添加这一行就ok binlog-format=ROW #选择row模式 server_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复
(二)重启 MySQL
查看MySQL启动状态 service mysqld status(5.0版本是mysqld) service mysql status(5.5.7版本是mysql) 重启MySQL service mysqld restart service mysql restart (5.5.7版本命令)
(三)查看MySQL binlog文件是否开启
1.在Linux中登录MySQL
mysql -u 用户名 -p 如:mysql -u root -p 输入密码对应的账号密码
2.查看binlog文件是否开启
show variables like 'log_%';
效果如下:
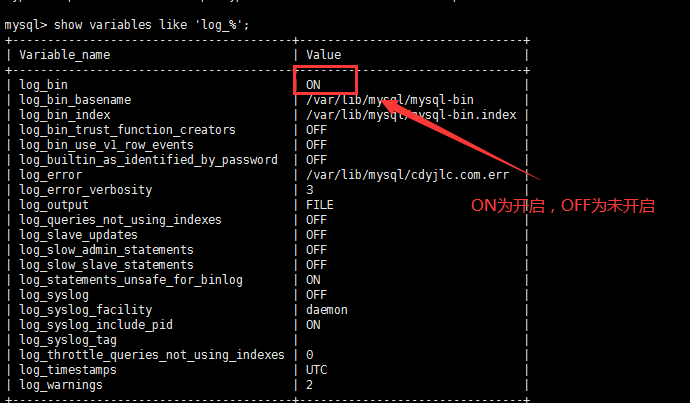
三、创建canal账号
(一)设置canal账号并赋权
drop user 'canal'@'%'; CREATE USER 'canal'@'%' IDENTIFIED BY 'canal'; -- 创建canal用户 grant all privileges on *.* to 'canal'@'%' identified by 'canal'; -- 为canal用户赋予repication权限 flush privileges;
如果出现以下情况,说明MySQL设置了密码难度,需要修改MySQL设置,如果没有出现则调过以下步骤
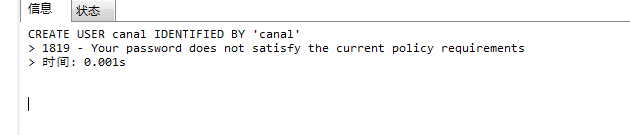
1.查看MySQL的策略
SHOW VARIABLES LIKE 'validate_password%';
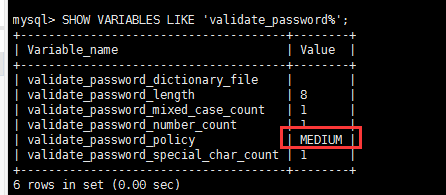
2.设置MySQL密码验证强调的策略
set global validate_password_policy=LOW;
3.设置MySQL密码最低长度
set global validate_password_length=5;
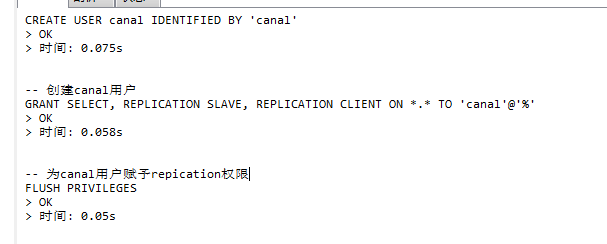
4.重新设置一下账号即可
drop user 'canal'@'%'; CREATE USER 'canal'@'%' IDENTIFIED BY 'canal'; -- 创建canal用户 grant all privileges on *.* to 'canal'@'%' identified by 'canal'; -- 为canal用户赋予repication权限 flush privileges;
如图
四、构建CanalService
(一)修改instance.properties配置
vi /usr/local/canal/conf/example/instance.properties
canal.instance.master.address=127.0.0.1:3306
canal.instance.dbUsername=canal#此处是我们为mysql配置的canal用户 canal.instance.dbPassword=canal#此处是我们为mysql配置的canal用户的密码 canal.mq.topic=mysql-yjlcplatform-topic #mq消息主题
(二)修改canal.properties
vi /usr/local/canal/conf/canal.properties
canal.serverMode = kafka kafka.bootstrap.servers = 192.168.200.7:9092
(三)启动canal
cd /usr/local/canal/bin ./ startup.sh
查看canal启动日志
cat /usr/local/canal/logs/example/example.log
以下效果需要等一会儿

注意:
在启动canal的时候可能会报kafka连接超时,则重新启动kafka即可。
(四)验证MySQL与kafka是否关联成功
下载ZooInspector工具进行验证:
链接:https://pan.baidu.com/s/1SbiszPvYVfbmdDQRsdLAqg
提取码:cyb8
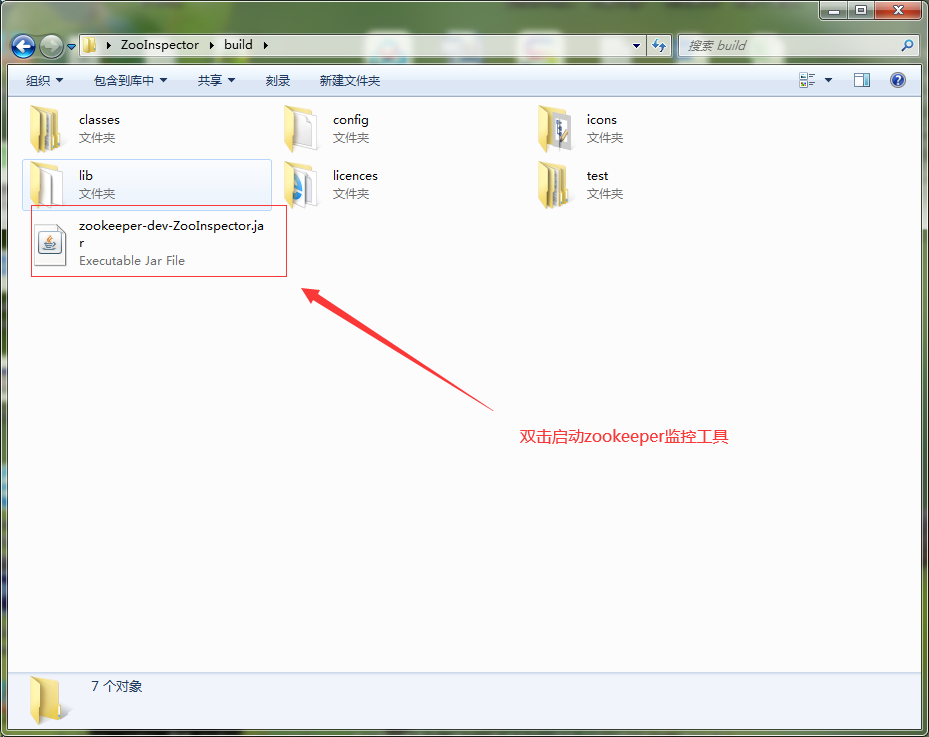
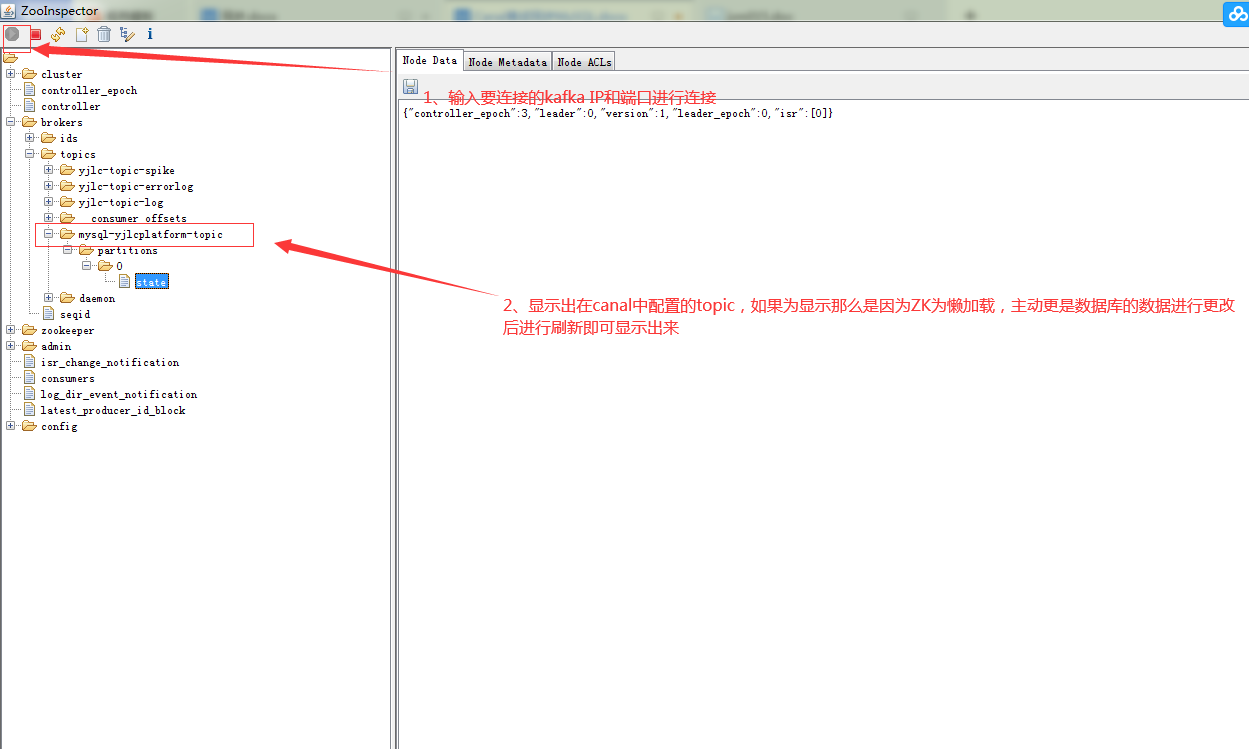
五、后端项目代码
(一)Pom配置文件
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
</dependencies>
(二)bootstrap.yml配置文件
# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
bootstrap-servers: 192.168.200.7:9092
consumer:
# 指定一个默认的组名
group-id: kafka2
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
(三)Java文件
1.启动类
/**
* --------------------------------------------------------------
* FileName: AppMemberCanalClient.java
*
* @Description:消费端
* @author: cyb
* @CreateDate: 2020-09-07
* --------------------------------------------------------------
*/
@SpringBootApplication
public class AppMemberCanalClient {
public static void main(String[] args) {
SpringApplication.run(AppMemberCanalClient.class);
}
}
2.后端监听类
package com.yjlc.kafka.client;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Component
public class MembetKafkaConsumer {
@KafkaListener(topics = "mysql-yjlcplatform-topic")
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset() + "," + consumer.value());
String json = (String) consumer.value();
JSONObject jsonObject = JSONObject.parseObject(json);
String type = jsonObject.getString("type");
String pkNames = jsonObject.getJSONArray("pkNames").getString(0);
JSONArray data = jsonObject.getJSONArray("data");
String table = jsonObject.getString("table");
String database = jsonObject.getString("database");
for (int i = 0; i < data.size(); i++) {
JSONObject dataObject = data.getJSONObject(i);
String key = database + ":" + table + ":"+dataObject.getString(pkNames);
switch (type) {
case "UPDATE":
case "INSERT":
break;
case "DELETE":
break;
}
}
}
}
以上功能亲测有效。如对以上内容有疑问的可以留言讨论,转载请说明出处,本人博客地址为:https://www.cnblogs.com/chenyuanbo/
技术在于沟通交流!

