

Heritrix3.1.0系统里面的组件以及对象之间总是存在千丝万缕的联系,本人为了表述某个功能的具体实现总是不得不牵涉到相关的对象及其实现,不然本人无法将该功能实现的逻辑描述清楚;可是在逻辑上本人又不得不考虑到话题的连贯性,本人姑妄言之,读者姑妄听之
本文接下来要分析的是ServerCache类及CrawlHost和CrawlServer类,了解这些类的作用是继续分析的前提
ServerCache是抽象类,在全局上为Heritrix3.1.0系统应用提供CrawlHost对象和CrawlServer对象的注册
/** * Abstract class for crawl-global registry of CrawlServer (host:port) and * CrawlHost (hostname) objects. */ public abstract class ServerCache { public abstract CrawlHost getHostFor(String host); public abstract CrawlServer getServerFor(String serverKey); /** * Utility for performing an action on every CrawlHost. * * @param action 1-argument Closure to apply to each CrawlHost */ public abstract void forAllHostsDo(Closure action); private static Logger logger = Logger.getLogger(ServerCache.class.getName()); /** * Get the {@link CrawlHost} associated with <code>curi</code>. * @param uuri CandidateURI we're to return Host for. * @return CandidateURI instance that matches the passed Host name. */ public CrawlHost getHostFor(UURI uuri) { CrawlHost h = null; try { if (uuri.getScheme().equals("dns")) { h = getHostFor("dns:"); } else if (uuri.getScheme().equals("whois")) { h = getHostFor("whois:"); } else { h = getHostFor(uuri.getReferencedHost()); } } catch (URIException e) { logger.log(Level.SEVERE, uuri.toString(), e); } return h; } /** * Get the {@link CrawlServer} associated with <code>curi</code>. * @param uuri CandidateURI we're to get server from. * @return CrawlServer instance that matches the passed CandidateURI. */ public CrawlServer getServerFor(UURI uuri) { //System.out.println("classname:"+this.getClass().getName()); CrawlServer cs = null; try { String key = CrawlServer.getServerKey(uuri); // TODOSOMEDAY: make this robust against those rare cases // where authority is not a hostname. if (key != null) { cs = getServerFor(key); } } catch (URIException e) { logger.log( Level.FINE, "No server key obtainable: "+uuri.toString(), e); } catch (NullPointerException npe) { logger.log( Level.FINE, "No server key obtainable: "+uuri.toString(), npe); } return cs; } abstract public Set<String> hostKeys(); }
该抽象类相当于模板,外部类通过CrawlServer getServerFor(UURI uuri)模板方法获取CrawlHost对象(根据UURI uuri对象的host值)
CrawlHost getHostFor(UURI uuri)模板方法获取CrawlServer对象(根据UURI uuri对象的key值)
如果我现在说CrawlHost对象和CrawlServer对象是什么,包括你我,都不会很理解它们;我们了解事物总是从具体到抽象,从其表现行为来理解该对象,所以本人先把这两个对象晾到一边
DefaultServerCache类继承自上面的ServerCache抽象类,提供了抽象方法的具体实现,用于获取CrawlHost对象和CrawlServer对象
** * Server and Host cache. * @author stack * @version $Date: 2011-01-20 23:28:38 +0000 (Thu, 20 Jan 2011) $, $Revision: 7067 $ */ public class DefaultServerCache extends ServerCache implements Closeable, Serializable { private static final long serialVersionUID = 1L; @SuppressWarnings("unused") private static Logger logger = Logger.getLogger(DefaultServerCache.class.getName()); /** * hostname[:port] -> CrawlServer. * Set in the initialization. */ protected ObjectIdentityCache<CrawlServer> servers = null; /** * hostname -> CrawlHost. * Set in the initialization. */ protected ObjectIdentityCache<CrawlHost> hosts = null; /** * Constructor. */ public DefaultServerCache() { this( new ObjectIdentityMemCache<CrawlServer>(), new ObjectIdentityMemCache<CrawlHost>()); } public DefaultServerCache(ObjectIdentityCache<CrawlServer> servers, ObjectIdentityCache<CrawlHost> hosts) { this.servers = servers; this.hosts = hosts; } /** * Get the {@link CrawlServer} associated with <code>name</code>. * @param serverKey Server name we're to return server for. * @return CrawlServer instance that matches the passed server name. */ public CrawlServer getServerFor(final String serverKey) { CrawlServer cserver = servers.getOrUse( serverKey, new Supplier<CrawlServer>() { public CrawlServer get() { String skey = new String(serverKey); // ensure private minimal key return new CrawlServer(skey); }}); return cserver; } /** * Get the {@link CrawlHost} associated with <code>name</code>. * @param hostname Host name we're to return Host for. * @return CrawlHost instance that matches the passed Host name. */ public CrawlHost getHostFor(final String hostname) { if (hostname == null || hostname.length() == 0) { return null; } CrawlHost host = hosts.getOrUse( hostname, new Supplier<CrawlHost>() { public CrawlHost get() { String hkey = new String(hostname); // ensure private minimal key return new CrawlHost(hkey); }}); return host; } /** * @param serverKey Key to use doing lookup. * @return True if a server instance exists. */ public boolean containsServer(String serverKey) { return (CrawlServer) servers.get(serverKey) != null; } /** * @param hostKey Key to use doing lookup. * @return True if a host instance exists. */ public boolean containsHost(String hostKey) { return (CrawlHost) hosts.get(hostKey) != null; } /** * Called when shutting down the cache so we can do clean up. */ public void close() { if (this.hosts != null) { // If we're using a bdb bigmap, the call to clear will // close down the bdb database. this.hosts.close(); this.hosts = null; } if (this.servers != null) { this.servers.close(); this.servers = null; } } /** * NOTE: Should not mutate the CrawlHost instance so retrieved; depending on * the hostscache implementation, the change may not be reliably persistent. * * @see org.archive.modules.net.ServerCache#forAllHostsDo(org.apache.commons.collections.Closure) */ public void forAllHostsDo(Closure c) { for(String host : hosts.keySet()) { c.execute(hosts.get(host)); } } public Set<String> hostKeys() { return hosts.keySet(); } }
该继承类里面的获取CrawlHost对象和CrawlServer对象的方法,我们已经有过相同的分析,可以参考Heritrix 3.1.0 源码解析(七),在这里本人再次该文中的UML模型展示出来,便于我们参照
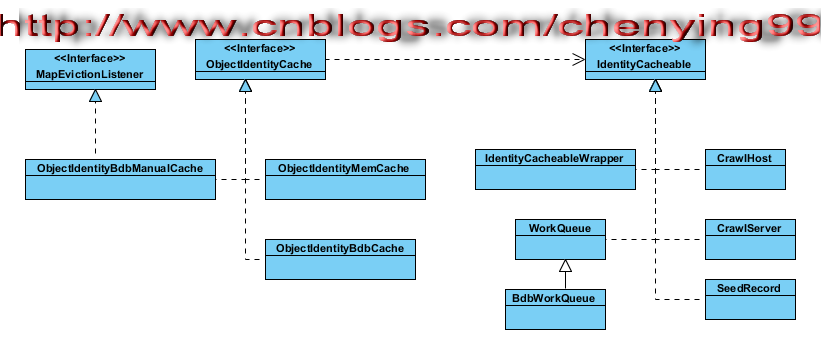
不过DefaultServerCache类用到的用于对象缓存管理类是ObjectIdentityMemCache,将对象缓存在内存中
CrawlHost类和CrawlServer类都实现了IdentityCacheable接口,是可用于缓存的对象的标识接口
BdbServerCache类继承自DefaultServerCache类,将对象存储在BDB数据库里面
/** * ServerCache backed by BDB big maps; the usual choice for crawls. * * @contributor pjack * @contributor gojomo */ public class BdbServerCache extends DefaultServerCache implements Lifecycle { private static final long serialVersionUID = 1L; protected BdbModule bdb; @Autowired public void setBdbModule(BdbModule bdb) { this.bdb = bdb; } public BdbServerCache() { } public void start() { if(isRunning()) { return; } try { this.servers = bdb.getObjectCache("servers", false, CrawlServer.class, CrawlServer.class); this.hosts = bdb.getObjectCache("hosts", false, CrawlHost.class, CrawlHost.class); } catch (DatabaseException e) { throw new IllegalStateException(e); } isRunning = true; } boolean isRunning = false; public boolean isRunning() { return isRunning; } public void stop() { isRunning = false; // TODO: release bigmaps? } }
---------------------------------------------------------------------------
本系列Heritrix 3.1.0 源码解析系本人原创
转载请注明出处 博客园 刺猬的温驯
本文链接 http://www.cnblogs.com/chenying99/archive/2013/04/28/3049817.html

