


tika怎样加载Parser实现类的,怎样根据文档的mime类型调用相应的Parser实现类,本文接着分析
先熟悉一下tika的解析类的相关接口和类的UML模型:
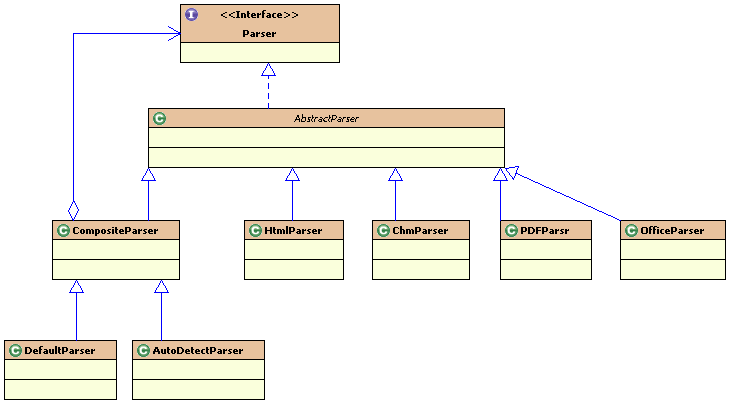
Parser接口的源码如下:
/** * Tika parser interface. */ public interface Parser extends Serializable { /** * Returns the set of media types supported by this parser when used * with the given parse context. * * @since Apache Tika 0.7 * @param context parse context * @return immutable set of media types */ Set<MediaType> getSupportedTypes(ParseContext context); /** * Parses a document stream into a sequence of XHTML SAX events. * Fills in related document metadata in the given metadata object. * <p> * The given document stream is consumed but not closed by this method. * The responsibility to close the stream remains on the caller. * <p> * Information about the parsing context can be passed in the context * parameter. See the parser implementations for the kinds of context * information they expect. * * @since Apache Tika 0.5 * @param stream the document stream (input) * @param handler handler for the XHTML SAX events (output) * @param metadata document metadata (input and output) * @param context parse context * @throws IOException if the document stream could not be read * @throws SAXException if the SAX events could not be processed * @throws TikaException if the document could not be parsed */ void parse( InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException; }
该接口只提供void parse(InputStream stream, ContentHandler handler,Metadata metadata, ParseContext context)方法供其他类调用
抽象类AbstractParser实现了Parser接口,其源码如下:
/** * Abstract base class for new parsers. This method implements the old * deprecated parse method so subclasses won't have to. * * @since Apache Tika 0.10 */ public abstract class AbstractParser implements Parser { /** * Serial version UID. */ private static final long serialVersionUID = 7186985395903074255L; /** * Calls the * {@link Parser#parse(InputStream, ContentHandler, Metadata, ParseContext)} * method with an empty {@link ParseContext}. This method exists as a * leftover from Tika 0.x when the three-argument parse() method still * existed in the {@link Parser} interface. No new code should call this * method anymore, it's only here for backwards compatibility. * * @deprecated use the {@link Parser#parse(InputStream, ContentHandler, Metadata, ParseContext)} method instead */ public void parse( InputStream stream, ContentHandler handler, Metadata metadata) throws IOException, SAXException, TikaException { parse(stream, handler, metadata, new ParseContext()); } }
新增void parse(InputStream stream, ContentHandler handler, Metadata metadata)方法,提供模板方法功能
下面接着贴出CompositeParser的源码,它继承自抽象类AbstractParser
/** * Composite parser that delegates parsing tasks to a component parser * based on the declared content type of the incoming document. A fallback * parser is defined for cases where a parser for the given content type is * not available. */ public class CompositeParser extends AbstractParser { /** Serial version UID */ private static final long serialVersionUID = 2192845797749627824L; /** * Media type registry. */ private MediaTypeRegistry registry; /** * List of component parsers. */ private List<Parser> parsers; /** * The fallback parser, used when no better parser is available. */ private Parser fallback = new EmptyParser(); public CompositeParser(MediaTypeRegistry registry, List<Parser> parsers) { this.parsers = parsers; this.registry = registry; } public CompositeParser(MediaTypeRegistry registry, Parser... parsers) { this(registry, Arrays.asList(parsers)); } public CompositeParser() { this(new MediaTypeRegistry()); } public Map<MediaType, Parser> getParsers(ParseContext context) { Map<MediaType, Parser> map = new HashMap<MediaType, Parser>(); for (Parser parser : parsers) { for (MediaType type : parser.getSupportedTypes(context)) { map.put(registry.normalize(type), parser); } } return map; } /** * Utility method that goes through all the component parsers and finds * all media types for which more than one parser declares support. This * is useful in tracking down conflicting parser definitions. * * @since Apache Tika 0.10 * @see <a href="https://issues.apache.org/jira/browse/TIKA-660">TIKA-660</a> * @param context parsing context * @return media types that are supported by at least two component parsers */ public Map<MediaType, List<Parser>> findDuplicateParsers( ParseContext context) { Map<MediaType, Parser> types = new HashMap<MediaType, Parser>(); Map<MediaType, List<Parser>> duplicates = new HashMap<MediaType, List<Parser>>(); for (Parser parser : parsers) { for (MediaType type : parser.getSupportedTypes(context)) { MediaType canonicalType = registry.normalize(type); if (types.containsKey(canonicalType)) { List<Parser> list = duplicates.get(canonicalType); if (list == null) { list = new ArrayList<Parser>(); list.add(types.get(canonicalType)); duplicates.put(canonicalType, list); } list.add(parser); } else { types.put(canonicalType, parser); } } } return duplicates; } /** * Returns the media type registry used to infer type relationships. * * @since Apache Tika 0.8 * @return media type registry */ public MediaTypeRegistry getMediaTypeRegistry() { return registry; } /** * Sets the media type registry used to infer type relationships. * * @since Apache Tika 0.8 * @param registry media type registry */ public void setMediaTypeRegistry(MediaTypeRegistry registry) { this.registry = registry; } /** * Returns the component parsers. * * @return component parsers, keyed by media type */ public Map<MediaType, Parser> getParsers() { return getParsers(new ParseContext()); } /** * Sets the component parsers. * * @param parsers component parsers, keyed by media type */ public void setParsers(Map<MediaType, Parser> parsers) { this.parsers = new ArrayList<Parser>(parsers.size()); for (Map.Entry<MediaType, Parser> entry : parsers.entrySet()) { this.parsers.add(ParserDecorator.withTypes( entry.getValue(), Collections.singleton(entry.getKey()))); } } /** * Returns the fallback parser. * * @return fallback parser */ public Parser getFallback() { return fallback; } /** * Sets the fallback parser. * * @param fallback fallback parser */ public void setFallback(Parser fallback) { this.fallback = fallback; } /** * Returns the parser that best matches the given metadata. By default * looks for a parser that matches the content type metadata property, * and uses the fallback parser if a better match is not found. The * type hierarchy information included in the configured media type * registry is used when looking for a matching parser instance. * <p> * Subclasses can override this method to provide more accurate * parser resolution. * * @param metadata document metadata * @return matching parser */ protected Parser getParser(Metadata metadata) { return getParser(metadata, new ParseContext()); } protected Parser getParser(Metadata metadata, ParseContext context) { Map<MediaType, Parser> map = getParsers(context); MediaType type = MediaType.parse(metadata.get(Metadata.CONTENT_TYPE)); if (type != null) { // We always work on the normalised, canonical form type = registry.normalize(type); } while (type != null) { // Try finding a parser for the type Parser parser = map.get(type); if (parser != null) { return parser; } // Failing that, try for the parent of the type type = registry.getSupertype(type); } return fallback; } public Set<MediaType> getSupportedTypes(ParseContext context) { return getParsers(context).keySet(); } /** * Delegates the call to the matching component parser. * <p> * Potential {@link RuntimeException}s, {@link IOException}s and * {@link SAXException}s unrelated to the given input stream and content * handler are automatically wrapped into {@link TikaException}s to better * honor the {@link Parser} contract. */ public void parse( InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException { Parser parser = getParser(metadata); TemporaryResources tmp = new TemporaryResources(); try { TikaInputStream taggedStream = TikaInputStream.get(stream, tmp); TaggedContentHandler taggedHandler = new TaggedContentHandler(handler); try { parser.parse(taggedStream, taggedHandler, metadata, context); } catch (RuntimeException e) { throw new TikaException( "Unexpected RuntimeException from " + parser, e); } catch (IOException e) { taggedStream.throwIfCauseOf(e); throw new TikaException( "TIKA-198: Illegal IOException from " + parser, e); } catch (SAXException e) { taggedHandler.throwIfCauseOf(e); throw new TikaException( "TIKA-237: Illegal SAXException from " + parser, e); } } finally { tmp.dispose(); } } }
该类的注释很清楚,相当于将解析任务委托给了其他的解析组件,而自身提供的parser方法供其他类调用
且分析CompositeParser类是怎样将解析任务委托给其他解析组件的,关键是parser方法的这行代码 Parser parser = getParser(metadata);
它调用了下面的方法:
protected Parser getParser(Metadata metadata) { return getParser(metadata, new ParseContext()); } protected Parser getParser(Metadata metadata, ParseContext context) { Map<MediaType, Parser> map = getParsers(context); MediaType type = MediaType.parse(metadata.get(Metadata.CONTENT_TYPE)); if (type != null) { // We always work on the normalised, canonical form type = registry.normalize(type); } while (type != null) { // Try finding a parser for the type Parser parser = map.get(type); if (parser != null) { return parser; } // Failing that, try for the parent of the type type = registry.getSupertype(type); } return fallback; }
执行流程是首先获取mime类型跟相应的Parser实现类的映射Map<MediaType, Parser> ,然后根据Metadata的Metadata.CONTENT_TYPE属性得到MediaType类型,最后从Map<MediaType, Parser>获取相应的Parser实现类
上面的代码Map<MediaType, Parser> map = getParsers(context)是获取Map<MediaType, Parser>映射
public Map<MediaType, Parser> getParsers(ParseContext context) { Map<MediaType, Parser> map = new HashMap<MediaType, Parser>(); for (Parser parser : parsers) { for (MediaType type : parser.getSupportedTypes(context)) { map.put(registry.normalize(type), parser); } } return map; }
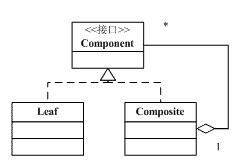
即根据构造方法初始化的List<Parser> parsers组件集合,这里注意的是如果该组件类集合中的成员之一为CompositeParser本身的类型,则该成员提供的可以支持的mime类型同时又来自于该成员的解析组件集合(这里也许是CompositeParser命名的原因,这里用到了Composite模式),我们可以看到它Set<MediaType> getSupportedTypes(ParseContext context)方法:
public Set<MediaType> getSupportedTypes(ParseContext context) { return getParsers(context).keySet(); }
Composite模式的简要UML模型图如下:
我们接下来分析DefaultParser的源码,该类继承自CompositeParser类,用于初始化CompositeParser类的相关成员变量
/** * A composite parser based on all the {@link Parser} implementations * available through the * {@link javax.imageio.spi.ServiceRegistry service provider mechanism}. * * @since Apache Tika 0.8 */ public class DefaultParser extends CompositeParser { /** Serial version UID */ private static final long serialVersionUID = 3612324825403757520L; /** * Finds all statically loadable parsers and sort the list by name, * rather than discovery order. CompositeParser takes the last * parser for any given media type, so put the Tika parsers first * so that non-Tika (user supplied) parsers can take precedence. * * @param loader service loader * @return ordered list of statically loadable parsers */ private static List<Parser> getDefaultParsers(ServiceLoader loader) { List<Parser> parsers = loader.loadStaticServiceProviders(Parser.class); Collections.sort(parsers, new Comparator<Parser>() { public int compare(Parser p1, Parser p2) { String n1 = p1.getClass().getName(); String n2 = p2.getClass().getName(); boolean t1 = n1.startsWith("org.apache.tika."); boolean t2 = n2.startsWith("org.apache.tika."); if (t1 == t2) { return n1.compareTo(n2); } else if (t1) { return -1; } else { return 1; } } }); return parsers; } private transient final ServiceLoader loader; public DefaultParser(MediaTypeRegistry registry, ServiceLoader loader) { super(registry, getDefaultParsers(loader)); this.loader = loader; } public DefaultParser(MediaTypeRegistry registry, ClassLoader loader) { this(registry, new ServiceLoader(loader)); } public DefaultParser(ClassLoader loader) { this(MediaTypeRegistry.getDefaultRegistry(), new ServiceLoader(loader)); } public DefaultParser(MediaTypeRegistry registry) { this(registry, new ServiceLoader()); } public DefaultParser() { this(MediaTypeRegistry.getDefaultRegistry()); } @Override public Map<MediaType, Parser> getParsers(ParseContext context) { Map<MediaType, Parser> map = super.getParsers(context); if (loader != null) { // Add dynamic parser service (they always override static ones) MediaTypeRegistry registry = getMediaTypeRegistry(); for (Parser parser : loader.loadDynamicServiceProviders(Parser.class)) { for (MediaType type : parser.getSupportedTypes(context)) { map.put(registry.normalize(type), parser); } } } return map; } }
该类主要是为基类初始化MediaTypeRegistry registry成员与List<Parser> parsers成员,它本身并没有覆盖void parse(InputStream stream, ContentHandler handler,Metadata metadata, ParseContext context)方法,为的是执行基类的方法(根据mime类型执行具体parser类的parse方法)
最后来分析AutoDetectParser类的源码,它也继承自CompositeParser类:
public class AutoDetectParser extends CompositeParser { /** Serial version UID */ private static final long serialVersionUID = 6110455808615143122L; /** * The type detector used by this parser to auto-detect the type * of a document. */ private Detector detector; // always set in the constructor /** * Creates an auto-detecting parser instance using the default Tika * configuration. */ public AutoDetectParser() { this(TikaConfig.getDefaultConfig()); } public AutoDetectParser(Detector detector) { this(TikaConfig.getDefaultConfig()); setDetector(detector); } /** * Creates an auto-detecting parser instance using the specified set of parser. * This allows one to create a Tika configuration where only a subset of the * available parsers have their 3rd party jars included, as otherwise the * use of the default TikaConfig will throw various "ClassNotFound" exceptions. * * @param detector Detector to use * @param parsers */ public AutoDetectParser(Parser...parsers) { this(new DefaultDetector(), parsers); } public AutoDetectParser(Detector detector, Parser...parsers) { super(MediaTypeRegistry.getDefaultRegistry(), parsers); setDetector(detector); } public AutoDetectParser(TikaConfig config) { super(config.getMediaTypeRegistry(), config.getParser()); setDetector(config.getDetector()); } /** * Returns the type detector used by this parser to auto-detect the type * of a document. * * @return type detector * @since Apache Tika 0.4 */ public Detector getDetector() { return detector; } /** * Sets the type detector used by this parser to auto-detect the type * of a document. * * @param detector type detector * @since Apache Tika 0.4 */ public void setDetector(Detector detector) { this.detector = detector; } public void parse( InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException { TemporaryResources tmp = new TemporaryResources(); try { TikaInputStream tis = TikaInputStream.get(stream, tmp); // Automatically detect the MIME type of the document MediaType type = detector.detect(tis, metadata); metadata.set(Metadata.CONTENT_TYPE, type.toString()); // TIKA-216: Zip bomb prevention SecureContentHandler sch = new SecureContentHandler(handler, tis); try { // Parse the document super.parse(tis, sch, metadata, context); } catch (SAXException e) { // Convert zip bomb exceptions to TikaExceptions sch.throwIfCauseOf(e); throw e; } } finally { tmp.dispose(); } } public void parse( InputStream stream, ContentHandler handler, Metadata metadata) throws IOException, SAXException, TikaException { ParseContext context = new ParseContext(); context.set(Parser.class, this); parse(stream, handler, metadata, context); } }
该类也初始化基类的MediaTypeRegistry registry成员与List<Parser> parsers成员,不过这里的List<Parser> parsers成员有TikaConfig类提供,后者默认提供的Parser实现类为DefaultParser
它的void parse(InputStream stream, ContentHandler handler,Metadata metadata, ParseContext context)方法首先检测文档的mime类型,然后将解析处理委托给CompositeParser基类执行,自身对外提供接口
所以整个解析的流程是
一、AutoDetectParser的parse方法:首先检测文件的mime类型,然后将解析任务交给基类CompositeParser的parse方法
二、AutoDetectParser的基类CompositeParser的parse方法:根据参数里面的mime类型获取解析类DefaultParser(支持所有已经注册的mime类型,由List<Parser> parsers成员提供)
三、调用DefaultParser的parse方法(DefaultParser默认执行父类的parse方法),即基类CompositeParser的parse方法,根据参数里面的mime类型获取具体解析类
四、最后执行具体解析类的parse方法
这里第一次AutoDetectParser初始化基类CompositeParser的parser组件集合是DefaultParser,基类CompositeParser的parse方法委托给DefaultParser
第二次DefaultParser初始化基类的CompositeParser的parser组件集合是具体的parser实现类集合,基类CompositeParser的parse方法委托给具体的parser实现类
这里体现的是Composite模式的运用。

