


项目介绍
Tika是一个内容分析工具,自带全面的parser工具类,能解析基本所有常见格式的文件,得到文件的metadata,content等内容,返回格式化信息。总的来说可以作为一个通用的解析工具。特别对于搜索引擎的数据抓去和处理步骤有重要意义。
Tika是一个目的明确,使用简单的apache的开源项目。下图是Tika诞生的一个历史过程。
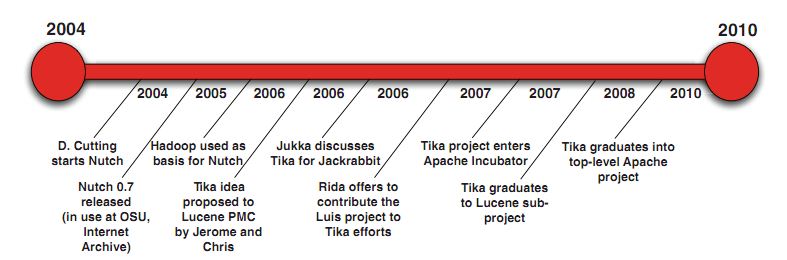
Tika项目之初来源于Nutch项目(大家应该都不陌生),现在是Lucene的子项目,所以也是来源于搜索引擎。其实Nutch这个项目的开发过程中,孕育了不少东西,应该都归功于Doug Cutting。我个人也是觉得这件事情很赞,要搞Nutch这样一个通用的搜索引擎,包括了全文索引和Web爬虫两大块内容,在开发过程中逐渐诞生出一些核心的周边产品,再孕育成子项目,包括hadoop,Lucene,Tika等等这些现代很主流,使用人群很广的通用项目,带给了IT界不少便利。我个人对此非常憧憬,觉得甚是美好。
从源码看功能
通过src里几个包和主要类,看Tika能干什么。跳过core包,tika-parsers展示了Tika能处理的文件类别和内容,

音频,图片,文本,各种格式的文件,tika都有对应的parser类来处理。而且Tika提供给了一些parser接口供扩展。tika-bundle提供Tika结合OSGi容器的能力。tika-app而则是一个在代码外直接使用Tika的jar包,可以在官网直接下载使用,提供gui和cmd使用方式,直观地体验这款产品。下面我会截图展示。
Tika架构
下图解释了Tika的架构以及关键零部件的主要设计目标:由一个解析器框架(中间),MIME检测机制(右侧),语言检测(左侧),和一个facade组件(中间部分的原理图)联系所有组件。外部接口,包括命令行和图形界面(下一节我会简单介绍),允许用户集成到脚本或者应用程序,并与Tika直接交互。在整个结构中,Tika的体系结构是可扩展的,新的解析器可以轻松地添加和删除。

Tika使用
直接使用Tika,只要java -jar tika-app-1.2 --gui即可启动,你可以把打开本地文件或者添加你要解析的url地址,甚至直接把各种文件拖入Tika,查看Tika的解析结果。大家可以直接下载jar包体验下,非常方便。在View内可以选择你想查看的内容(Metadata, text等)。Tika对图片的处理主要是提供一些元信息,并不能分析出图片内的内容,所以图片形式的pdf文件自然是不能查看text信息的。
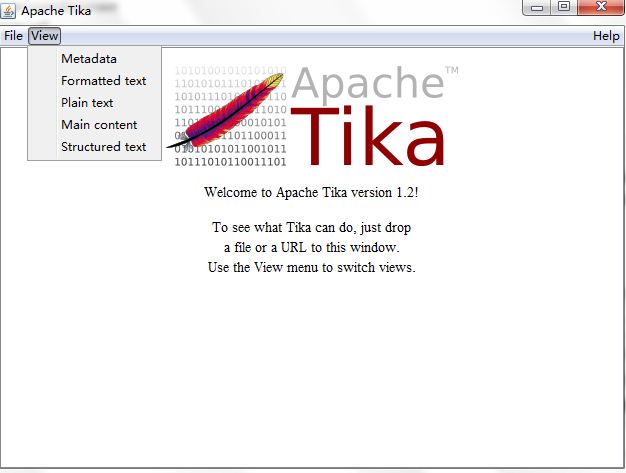
如果是用命令行,类似的语法是这样的:
- java -jar tika-app-1.0.jar --text document.doc
- java -jar tika-app-1.0.jar --encoding=UTF-8 --text document.doc
- java -jar tika-app-1.0.jar --metadata document.doc
想在别的工程中使用Tika,只要在maven项目依赖里添加Tika,new Tika的实例,然后直接调用Tika的解析parser类,即可获取到处理后的信息。给个最简单的例子:
- import java.io.File;
- import org.apache.tika.Tika;
- public class SimpleTextExtractor {
- public static void main(String[] args) throws Exception {
- // Create a Tika instance with the default configuration
- Tika tika = new Tika();
- // Parse all given files and print out the extracted text content
- for (String file : args) {
- String text = tika.parseToString(new File(file));
- System.out.print(text);
- }
- }
- }
总结
介绍Tika出于两个目的:
1. 感觉是一个通用,实用且易用的分析工具,可以与lucene,solr结合,天生服务搜索引擎
2. 感叹Nutch项目发展历史,Apache各种开源项目的紧密,自然,优美的关联性。
更多内容参看 《Tika in action》

