服务端如何识别是selenium在访问以及解决方案参考二
有不少朋友在开发爬虫的过程中喜欢使用Selenium + Chromedriver,以为这样就能做到不被网站的反爬虫机制发现。
先不说淘宝这种基于用户行为的反爬虫策略,仅仅是一个普通的小网站,使用一行Javascript代码,就能轻轻松松识别你是否使用了Selenium + Chromedriver模拟浏览器。
我们来看一个例子。
使用下面这一段代码启动Chrome窗口:
from selenium.webdriver import Chrome
driver = Chrome()现在,在这个窗口中打开开发者工具,并定位到Console选项卡,如下图所示。
现在,在这个窗口输入如下的js代码并按下回车键:
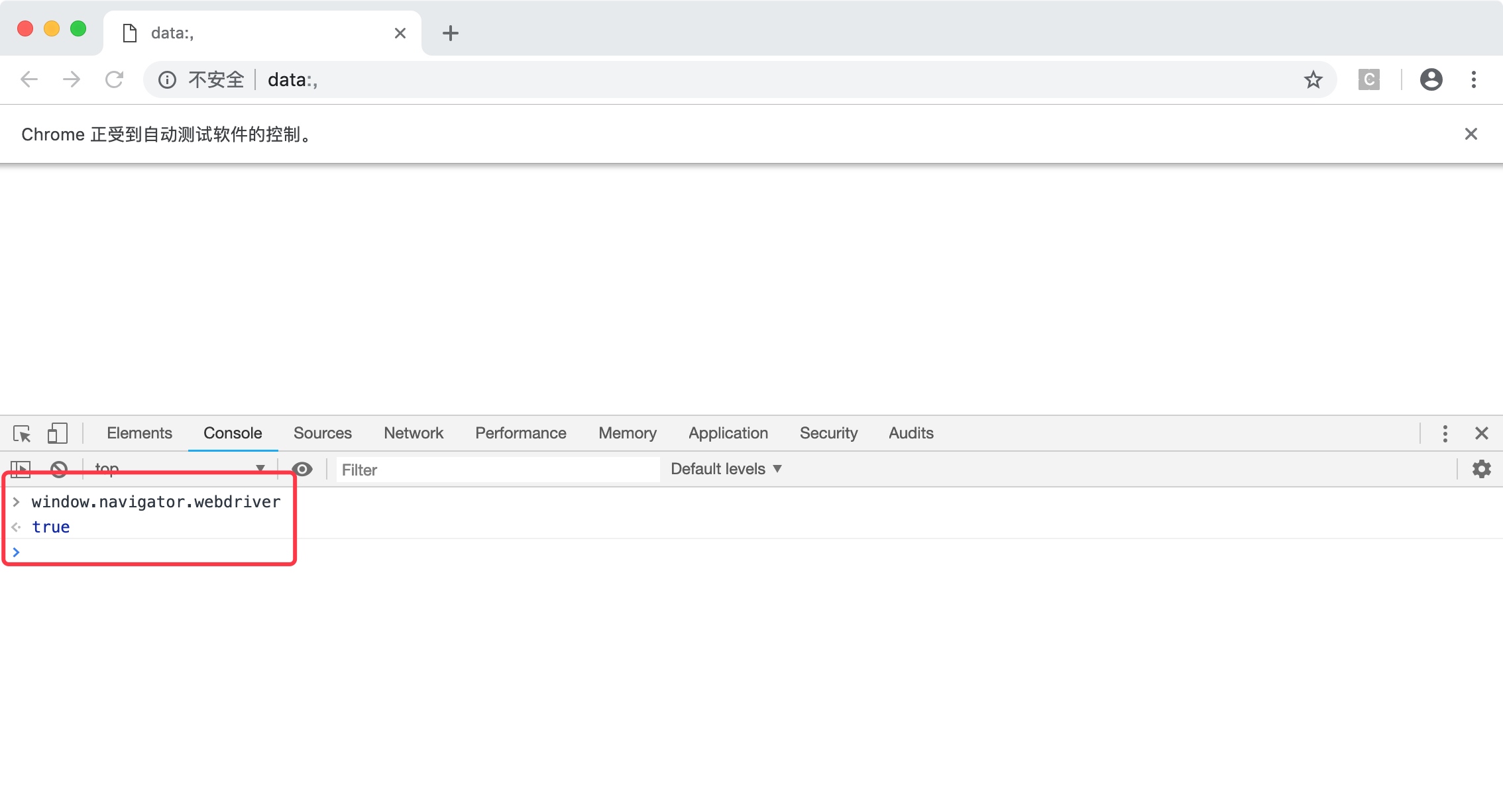
window.navigator.webdriver可以看到,开发者工具返回了true。如下图所示。
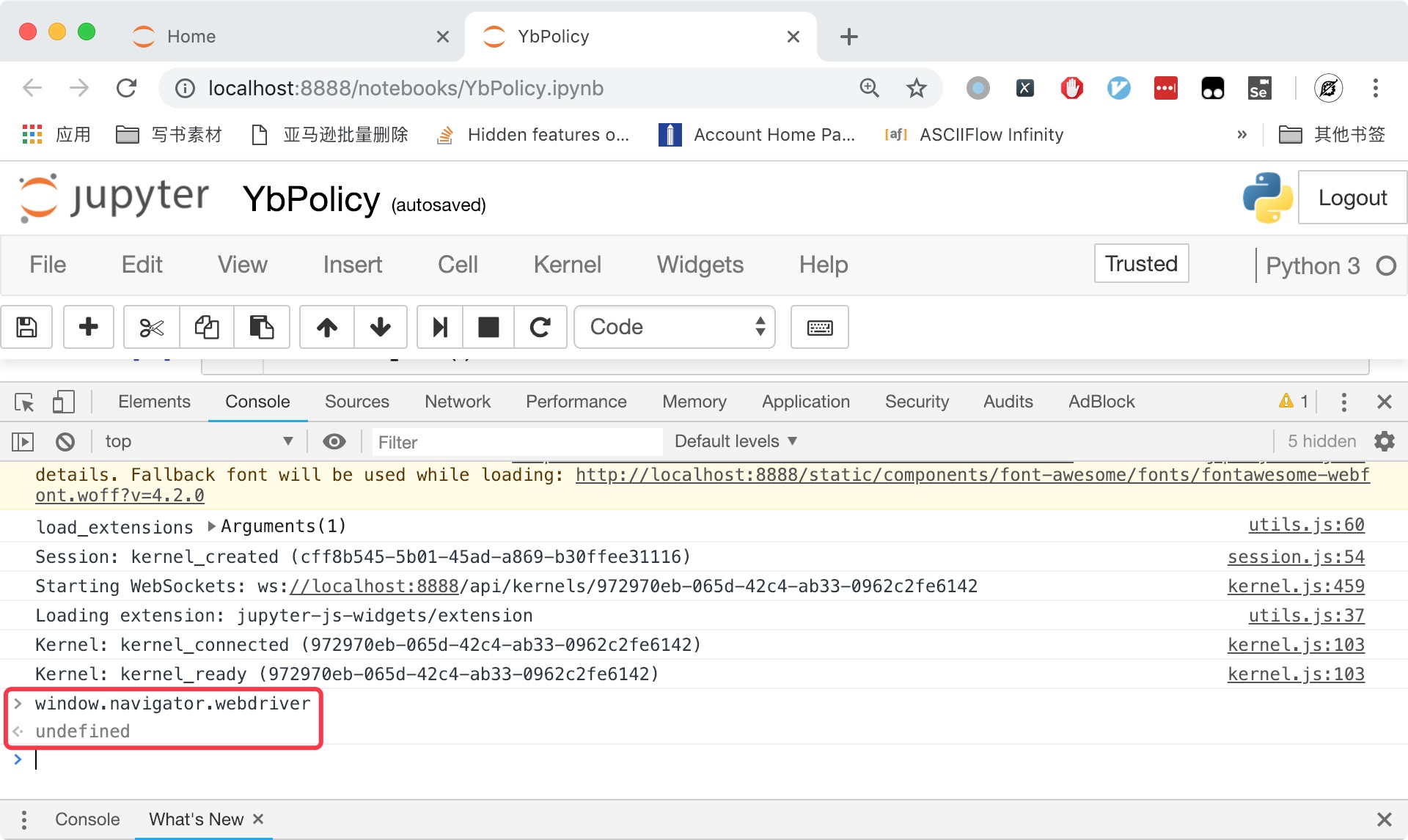
但是,如果你打开一个普通的Chrome窗口,执行相同的命令,可以发现这行代码的返回值为undefined,如下图所示。
所以,如果网站通过js代码获取这个参数,返回值为undefined说明是正常的浏览器,返回true说明用的是Selenium模拟浏览器。一抓一个准。这里给出一个检测Selenium的js代码例子:
webdriver = window.navigator.webdriver;
if(webdriver){
console.log('你这个傻逼你以为使用Selenium模拟浏览器就可以了?')
} else {
console.log('正常浏览器')
}网站只要在页面加载的时候运行这个js代码,就可以识别访问者是不是用的Selenium模拟浏览器。如果是,就禁止访问或者触发其他反爬虫的机制。
那么对于这种情况,在爬虫开发的过程中如何防止这个参数告诉网站你在模拟浏览器呢?
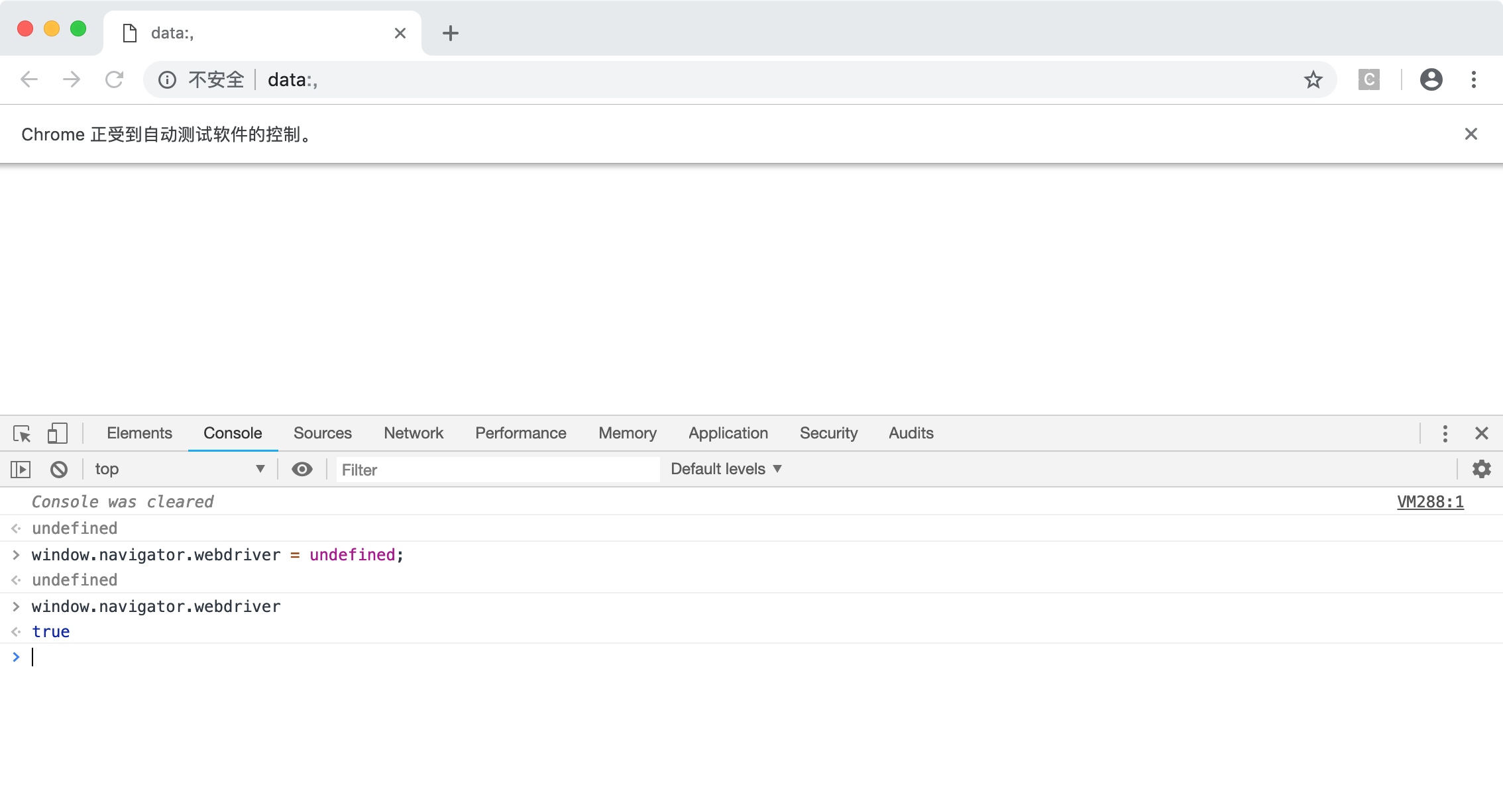
可能有一些会js的朋友觉得可以通过覆盖这个参数从而隐藏自己,但实际上这个值是不能被覆盖的:
对js更精通的朋友,可能会使用下面这一段代码来实现:
Object.defineProperties(navigator, {webdriver:{get:()=>undefined}});运行效果如下图所示:
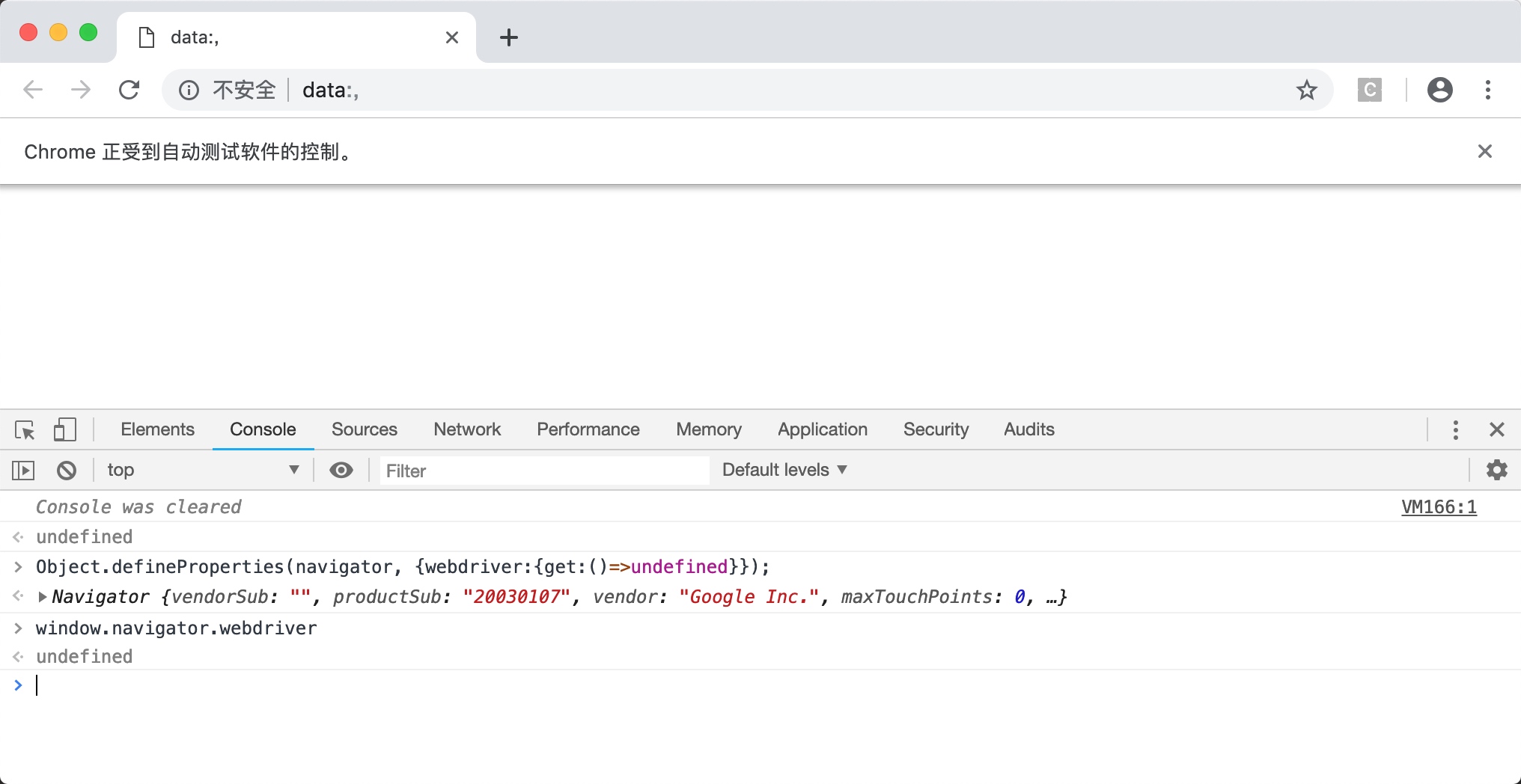
确实修改成功了。这种写法就万无一失了吗?并不是这样的,如果此时你在模拟浏览器中通过点击链接、输入网址进入另一个页面,或者开启新的窗口,你会发现,window.navigator.webdriver又变成了true。如下图所示。
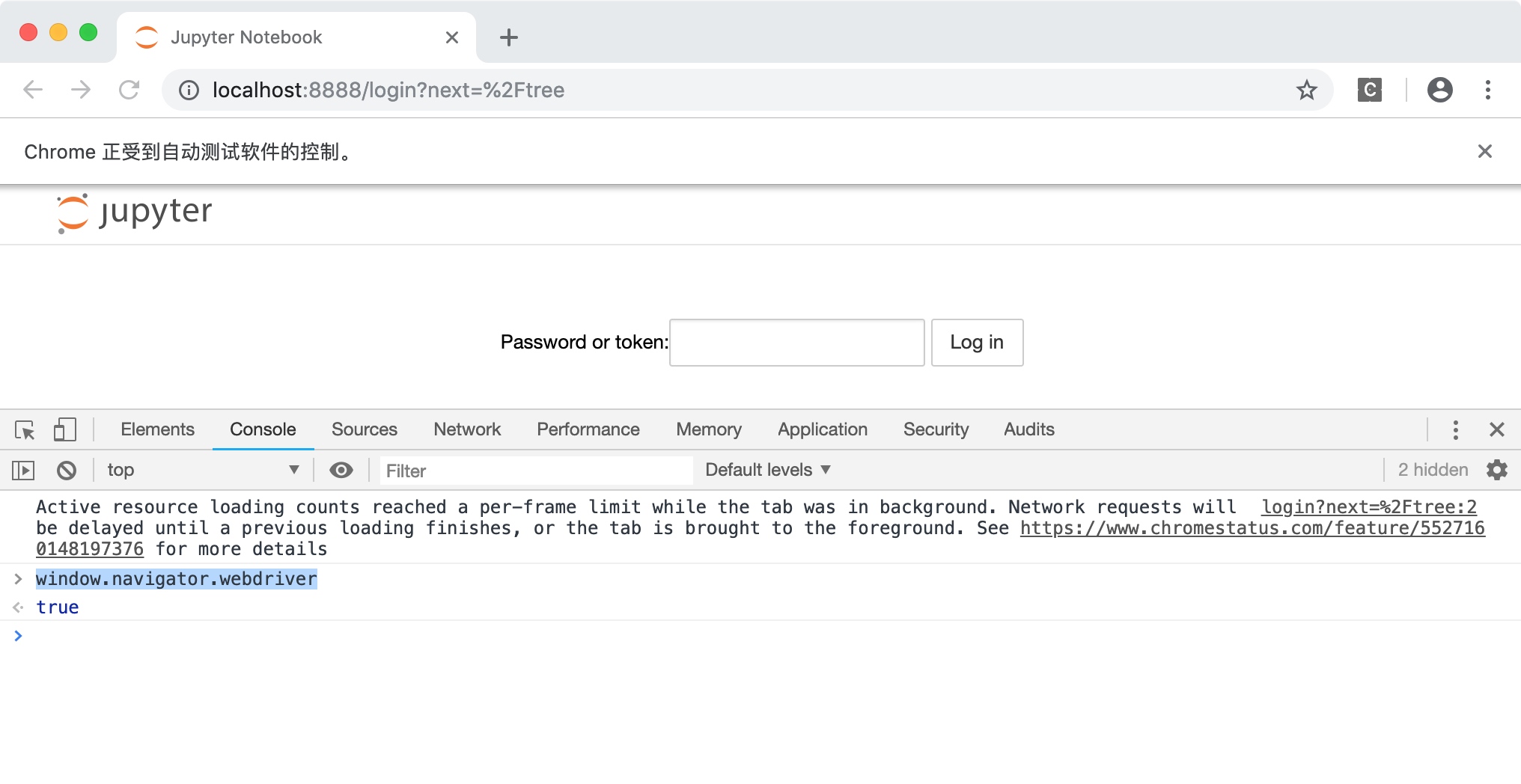
那么是不是可以在每一个页面都打开以后,再次通过webdriver执行上面的js代码,从而实现在每个页面都把window.navigator.webdriver设置为undefined呢?也不行。
因为当你执行:driver.get(网址)的时候,浏览器会打开网站,加载页面并运行网站自带的js代码。所以在你重设window.navigator.webdriver之前,实际上网站早就已经知道你是模拟浏览器了。
接下来,又有朋友提出,可以通过编写Chrome插件来解决这个问题,让插件里面的js代码在网站自带的所有js代码之前执行。
这样做当然可以,不过有更简单的办法,只需要设置Chromedriver的启动参数即可解决问题。
在启动Chromedriver之前,为Chrome开启实验性功能参数excludeSwitches,它的值为['enable-automation'],完整代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
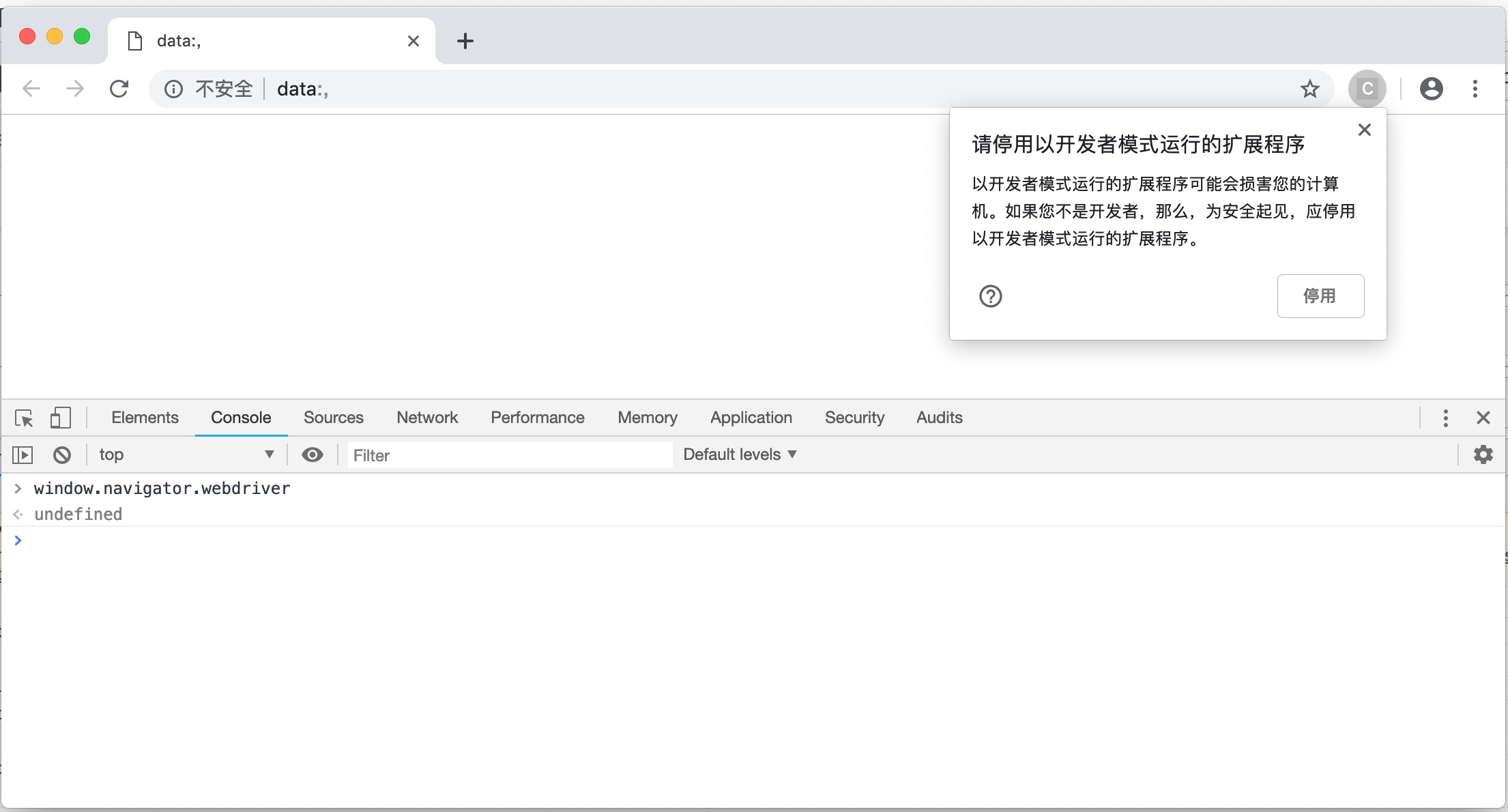
driver = Chrome(options=option)此时启动的Chrome窗口,在右上角会弹出一个提示,不用管它,不要点击停用按钮。
再次在开发者工具的Console选项卡中查询window.navigator.webdriver,可以发现这个值已经自动变成undefined了。并且无论你打开新的网页,开启新的窗口还是点击链接进入其他页面,都不会让它变成true。运行效果如下图所示。
本文转载自:https://www.kingname.info/2019/02/12/hide-webdriver/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号