
陈烨---第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/ |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 爬取评论信息、对评论进行分词和将评论信息展示成词云图 |
| 作业源代码 | https://github.com/cychenye/first-personal-work |
| 学号 | 211806207 |
| 过程 | 花费时间 |
|---|---|
| 爬取评论 | 2h |
| 数据处理 | 2h |
| 数据展示 | 3h |
| 提交代码 | 1h |
一、爬取评论
-
进入《在一起》的评论页面,发现评论页是采用异步加载方式。
-
按 F12,点击 Network 查看,分析第一页和第二页的网址变化规律。
第一页:https://coral.qq.com/article/5963120294/comment/v2?callback=article5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=1&=1614119428712
第二页:https://coral.qq.com/article/5963120294/comment/v2?callback=article5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6716706003418103507&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=1&=1614119428713对比两个链接,发现只有 cursor 和 _ 不同。其中 _ 是加 1 操作,cursor 在访问第一页的网址后发现,对应的是 last 字段的值。
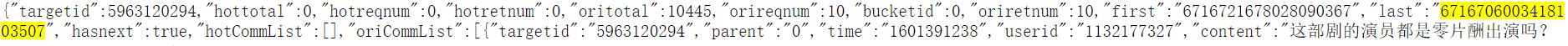
-
接下来查找评论内容,发现评论内容对应了 content 字段,就利用正则来提取评论内容。

def getCurrentPageComments(html): pat = '"content":"(.*?)"' return re.compile(pat,re.S).findall(html) -
然后从当前评论页面 last 字段中获取下一页的 cursor 的值,再爬取下一页,这样重复操作。
def getNextCursor(html): pat = '"last":"(.*?)",' return re.compile(pat,re.S).findall(html)[0] -
最后把评论内容都保存到了 comments.txt 文件当中。
二、分词
-
首先把 comments.txt 中的评论内容读出来,然后用 jieba 分词的精确模式进行分词。
data = open("comments.txt", "r", encoding="utf-8").read() words = jieba.lcut(data) -
看到一些同学用了停用词做过滤,我也去整了一个。遍历 jieba 分词后的结果,只保存不在停用词中的词语。
lists = [] for word in words: if word not in stopWords: lists.append(word) return lists -
将过滤后的结果转成 {"name":word,"value":cnt} 的格式,然后写到 word.json 文件中。
三、数据展示
-
建个 index.html 文件,导入相关的 JavaScript 文件:echarts.min.js、echarts-wordcloud.min.js、jquery-3.5.1.js。
-
把本地的 word.json 文件也导进来。参考了网上的资料,然后使用了 jQuery 中的 $.getJSON() 方法,结果发现好像前端无法直接读取本地 JSON 文件,然后在 CSDN 上找到了解决方法,打开 index.html 前先执行 serve.py,以此来创建一个临时的本地代理服务器。
$.getJSON("http://localhost:8000/word.json", "", function (res) { // 访问本地代理服务器获取 JSON 数据 }) -
看到网上有现成的模板,拿来改一下参数直接用上了。

四、提交代码
-
在文件夹右键,点击 Git Bash Here。
-
输入 git init,进行初始化。
-
输入 git remote add origin 仓库地址,来连接仓库。
-
输入 git clone 仓库地址,将远程仓库的内容克隆到本地仓库。
-
输入 cd first-personal-work,进入文件夹。
-
输入 git checkout -b crawl,切换分支。
-
输入 git add 文件名,将文件添加到暂存区。
-
输入 git commit -m "注释",提交到版本库。
-
输入 git push -u origin crawl,推送到远程仓库。
-
按上述步骤依次将文件提交到远程仓库。
-
输入 git checkout master,切换分支。
-
输入 git merge crawl 和 git merge chart,合并分支。
五、总结
-
没有学习多少前端知识,读取 JSON 文件那里卡了很久。
-
ECharts 官网好像示例里好像没有给词云图的内容,然后去百度了一套模板。
-
这次作业很多都是新东西,有挺多收获的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号