第一次个人编程作业
GitHub链接
计算模块接口的设计与实现过程
流程图
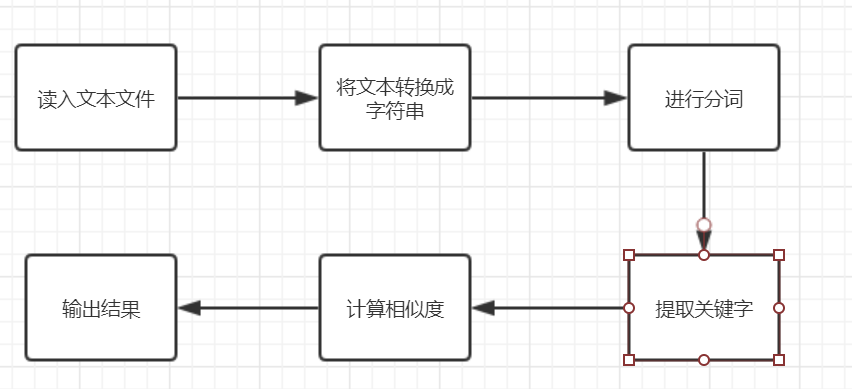
通过使用jieba库中的jieba.cut(s)函数进行分词。并将分词的结果保存在words中。计算词频,依次确定向量的每个位置的值,得到向量
分词
def get_vector(text1,text2):
words1 = jieba.cut(text1)
words2 = jieba.cut(text2)
list_word1 = (','.join(words1)).split(',')
list_word2 = (','.join(words2)).split(',')
列出所有的词,取并集
key_word = list(set(list_word1 + list_word2))
# 给定形状和类型的用0填充的矩阵存储向量
vector1 = np.zeros(len(key_word))
vector2 = np.zeros(len(key_word))
计算词频
依次确定向量的每个位置的值
for i in range(len(key_word)):
# 遍历key_word中每个词在句子中的出现次数
for j in range(len(list_word1)):
if key_word[i] == list_word1[j]:
vector1[i] += 1
for k in range(len(list_word2)):
if key_word[i] == list_word2[k]:
vector2[i] += 1
# 输出向量
return vector1,vector2
计算余弦相似度函数,求出两个文本的相似度
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。

对于两个向量,如果他们之间的夹角越小,那么我们认为这两个向量是越相似的。余弦相似性就是利用了这个理论思想。它通过计算两个向量的夹角的余弦值来衡量向量之间的相似度值。余弦相似性推导公式如下:



def numerator(vector1, vector2):
#分子
return sum(a * b for a, b in zip(vector1, vector2))
def denominator(vector):
#分母
return math.sqrt(sum(a * b for a,b in zip(vector, vector)))
def run(vector1, vector2):
return numerator(vector1,vector2) / (denominator(vector1) * denominator(vector2))
def get_similarity(text1,text2):
vectors = get_vector(text1,text2)
# 相似度
similarity = run(vector1=vectors[0], vector2=vectors[1])
return similarity
计算模块部分单元测试展示
if name == 'main':
s1 = "E:\软件工程\sim_0.8\orig.txt"
s2 = "E:\软件工程\sim_0.8\orig_0.8_add.txt"
s3 = "E:\软件工程\sim_0.8\orig_0.8_del.txt"
s4 = "E:\软件工程\sim_0.8\orig_0.8_dis_1.txt"
s5 = "E:\软件工程\sim_0.8\orig_0.8_dis_3.txt"
s6 = "E:\软件工程\sim_0.8\orig_0.8_dis_7.txt"
s7 = "E:\软件工程\sim_0.8\orig_0.8_dis_10.txt"
s8 = "E:\软件工程\sim_0.8\orig_0.8_dis_15.txt"
s9 = "E:\软件工程\sim_0.8\orig_0.8_mix.txt"
s10 = "E:\软件工程\sim_0.8\orig_0.8_rep.txt"
print("orig_0.8_add.txt:{:.2f}".format(get_similarity(s1, s2)))
print("orig_0.8_del.txt:{:.2f}".format(get_similarity(s1, s3)))
print("orig_0.8_dis_1.txt:{:.2f}".format(get_similarity(s1, s4)))
print("orig_0.8_dis_3.txt:{:.2f}".format(get_similarity(s1, s5)))
print("orig_0.8_dis_7.txt:{:.2f}".format(get_similarity(s1, s6)))
print("orig_0.8_dis_10.txt:{:.2f}".format(get_similarity(s1, s7)))
print("orig_0.8_dis_15.txt:{:.2f}".format(get_similarity(s1, s8)))
print("orig_0.8_mix.txt:{:.2f}".format(get_similarity(s1, s9)))
print("orig_0.8_rep.txt:{:.2f}".format(get_similarity(s1, s10)))

PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 120 | 120 |
| Development | 开发 | 1980 | 2000 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 180 |
| · Design Spec | · 生成设计文档 | 120 | 90 |
| · Design Review | · 设计复审 | 60 | 50 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 60 |
| · Design | · 具体设计 | 240 | 200 |
| · Coding | · 具体编码 | 900 | 1000 |
| · Code Review | · 代码复审 | 120 | 140 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 300 | 280 |
| Reporting | 报告 | 450 | 460 |
| · Test Repor | · 测试报告 | 300 | 300 |
| · Size Measurement | · 计算工作量 | 60 | 60 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 90 | 100 |
| · 合计 | 2550 | 2580 |
6.总结
刚开始看到题目的时候十分懵,完全没有头绪,后来不断的查阅资料,有时候网页都会开好几个挤得满满的,也借鉴参考了有些同学提交的作业后,慢慢有了思路。通过这次作业,体现出我知识量存储不够,掌握技能不全,但我感觉我学习到了许多,了解到许多以前完全没有接触的模块,虽然这次作业做得磕磕碰碰,但相信在不断的练习下,总会慢慢掌握并且熟练运行这些功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号