
【转载】Beautiful Soup库(bs4)入门
该库能够解析HTML和XML
使用Beautiful Soup库:
from bs4 import BeautifulSoup import requests r = requests.get('http://www.23us.so/') html = r.text soup = BeautifulSoup(html,'html.parser') print soup.prettify()
1、Beautiful Soup库的理解:
HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树;因此可以说Beautiful Soup库是解析、遍历、维护“标签树”的功能库。
p标签:<p></p>:标签Tag ——一般,标签名都是成对出现的(位于起始和末尾),例如P;在第一个标签名之后可以有0到多个属性,表示标签的特点
<p class="title">...</p>——中间的class属性,其值为“title ”(属性是由键和值,键值对构成的)
通常,Beautiful Soup库的使用:
from bs4 import BeautifulSoup #主要使用BeautifulSoup类
事实上可以认为:HTML文档和标签树,BeautifulSoup类是等价的
Beautiful Soup库解析器:
bs4的HTML解析器:BeautifulSoup(mk,'html.parser')——条件:安装bs4库
lxml的HTML解析器:BeautifulSoup(mk,'lxml')——pip install lxml
lxml的XML解析器:BeautifulSoup(mk,'xml')——pip install lxml
html5lib的解析器:BeautifulSoup(mk,'html5lib')——pip install html5lib
Beautiful Soup类的基本元素:
1、Tag——标签,最基本的信息组织单元,分别用<>和</>表明开头和结尾
2、Name——标签的名字,<p>...</p>的名字是'p',格式:<tag>.name
3、Attributes——标签的属性,字典形式组织,格式:<tag>.attrs
4、NavigableString——标签内非属性字符串,<>...</>中的字符串,格式:<tag>.string
5、Comment——标签内字符串的注释部分,一种特殊的Comment类型(尖括号叹号表示注释开始:<!--This is a commet-->)
获取标签的方法:
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,'html.parser')
soup.a.name #a标签的名字
soup.a.parent.name #a标签的父标签的名字
soup.a.parent.parent.name #a标签的父标签的父标签名字
tag = soup.a
tag.attrs #a标签的属性
soup.a.string #获得a标签内非属性字符串(NavigableString )注意:soup.b.string也可能是获得Comment标签;可都过类型进行判断
2、基于bs4库的HTML内容遍历方法:
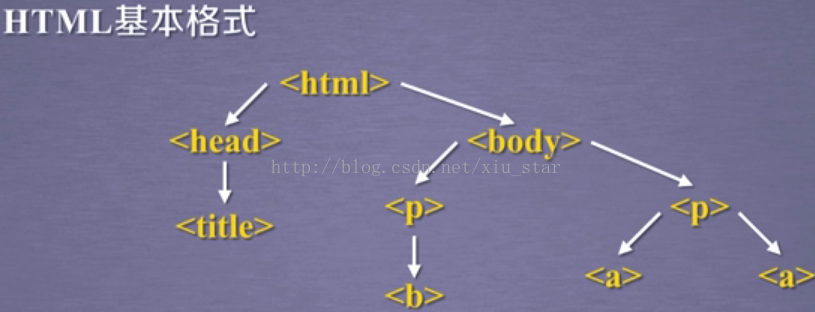
形成了三种遍历:
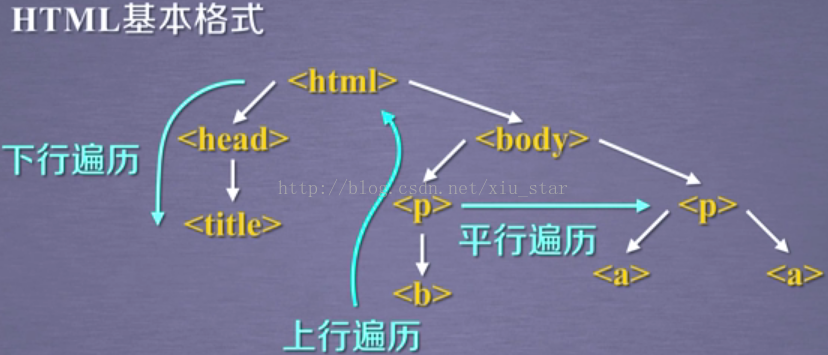
标签树的下行遍历:
- .contents属性:子节点的列表,将<tag>所有儿子节点存入列表
- .children属性:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants属性:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
也就是说:contents和children只获得当前节点的下一节点的信息;而descendants可以获得当前节点的所有后续节点信息
注意:字符串也属于一个节点,例如'\n','and'
遍历儿子节点:
for child in soup.body.children: #迭代类型,需要用循环方式
print(child)
遍历子孙节点:
for child in soup.body.descendants:
print(child)
from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4 import requests r = requests.get('http://python123.io/ws/demo.html') demo = r.text soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser child = soup.body.contents print(child) for child in soup.body.descendants: print(child)
标签树的上行遍历:
- .parent属性:节点的父标签
- parents属性:节点先辈标签的迭代类型,用于循环遍历先辈节点
注意:在遍历一个标签的所有先辈标签时,会遍历到soup本身,而soup的先辈不存在(也就是None),因此也就没有.name信息
标签树的平行遍历:
注意:平行遍历是有条件的,平行遍历必须发生在同一个父节点下的各节点间
soup.a.next_sibling
soup.a.previous_sibling
for sibling in soup.a.next_siblings:
print(sibling)
for sibling in soup.a.previous_siblings:
print(sibling)
3、基于bs4库的HTML格式输出:
如何能够让html内容更加“友好”的显示:
bs4库的prettify()方法:为html文本的标签以及内容增加换行符,也可以对标签做相关处理,例如soup.a.prettify()
该库能够解析HTML和XML
使用Beautiful Soup库:
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>data</p>', 'html.parser') #html解析器:html.parser ,前一个参数则是要解析的内容
小测:
from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4 import requests r = requests.get('http://python123.io/ws/demo.html') demo = r.text soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser print(soup.prettify()) #打印解析好的内容
1、Beautiful Soup库的理解:
HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树;因此可以说Beautiful Soup库是解析、遍历、维护“标签树”的功能库。
p标签:<p></p>:标签Tag ——一般,标签名都是成对出现的(位于起始和末尾),例如P;在第一个标签名之后可以有0到多个属性,表示标签的特点
<p class="title">...</p>——中间的class属性,其值为“title ”(属性是由键和值,键值对构成的)
通常,Beautiful Soup库的使用:
from bs4 import BeautifulSoup #主要使用BeautifulSoup类
事实上可以认为:HTML文档和标签树,BeautifulSoup类是等价的
Beautiful Soup库解析器:
bs4的HTML解析器:BeautifulSoup(mk,'html.parser')——条件:安装bs4库
lxml的HTML解析器:BeautifulSoup(mk,'lxml')——pip install lxml
lxml的XML解析器:BeautifulSoup(mk,'xml')——pip install lxml
html5lib的解析器:BeautifulSoup(mk,'html5lib')——pip install html5lib
Beautiful Soup类的基本元素:
1、Tag——标签,最基本的信息组织单元,分别用<>和</>表明开头和结尾
2、Name——标签的名字,<p>...</p>的名字是'p',格式:<tag>.name
3、Attributes——标签的属性,字典形式组织,格式:<tag>.attrs
4、NavigableString——标签内非属性字符串,<>...</>中的字符串,格式:<tag>.string
5、Comment——标签内字符串的注释部分,一种特殊的Comment类型(尖括号叹号表示注释开始:<!--This is a commet-->)
获取标签的方法:
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,'html.parser')
soup.a.name #a标签的名字
soup.a.parent.name #a标签的父标签的名字
soup.a.parent.parent.name #a标签的父标签的父标签名字
tag = soup.a
tag.attrs #a标签的属性
soup.a.string #获得a标签内非属性字符串(NavigableString )注意:soup.b.string也可能是获得Comment标签;可都过类型进行判断
2、基于bs4库的HTML内容遍历方法:
形成了三种遍历:
标签树的下行遍历:
- .contents属性:子节点的列表,将<tag>所有儿子节点存入列表
- .children属性:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
- .descendants属性:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
也就是说:contents和children只获得当前节点的下一节点的信息;而descendants可以获得当前节点的所有后续节点信息
注意:字符串也属于一个节点,例如'\n','and'
遍历儿子节点:
for child in soup.body.children: #迭代类型,需要用循环方式
print(child)
遍历子孙节点:
for child in soup.body.descendants:
print(child)
from bs4 import BeautifulSoup #beautifulsoup4库使用时是简写的bs4
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
child = soup.body.contents
print(child)
for child in soup.body.descendants:
import requests
r = requests.get('http://python123.io/ws/demo.html')
demo = r.text
soup = BeautifulSoup(demo,'html.parser') #解析器:html.parser
child = soup.body.contents
print(child)
for child in soup.body.descendants:
print(child)
标签树的上行遍历:
- .parent属性:节点的父标签
- parents属性:节点先辈标签的迭代类型,用于循环遍历先辈节点
注意:在遍历一个标签的所有先辈标签时,会遍历到soup本身,而soup的先辈不存在(也就是None),因此也就没有.name信息
标签树的平行遍历:
注意:平行遍历是有条件的,平行遍历必须发生在同一个父节点下的各节点间
soup.a.next_sibling
soup.a.previous_sibling
for sibling in soup.a.next_siblings:
print(sibling)
for sibling in soup.a.previous_siblings:
print(sibling)
3、基于bs4库的HTML格式输出:
如何能够让html内容更加“友好”的显示:
bs4库的prettify()方法:为html文本的标签以及内容增加换行符,也可以对标签做相关处理,例如soup.a.prettify()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号