Spring Cloud 整合分布式链路追踪系统Sleuth和ZipKin实战,分析系统瓶颈
导读
微服务架构中,是否遇到过这种情况,服务间调用链过长,导致性能迟迟上不去,不知道哪里出问题了,巴拉巴拉....,回归正题,今天我们使用SpringCloud组件,来分析一下微服务架构中系统调用的瓶颈问题~
SpringCloud链路追踪组件Sleuth实战
官网

主要功能:做日志埋点
什么是Sleuth
专门用于追踪每个请求的完整调用链路。
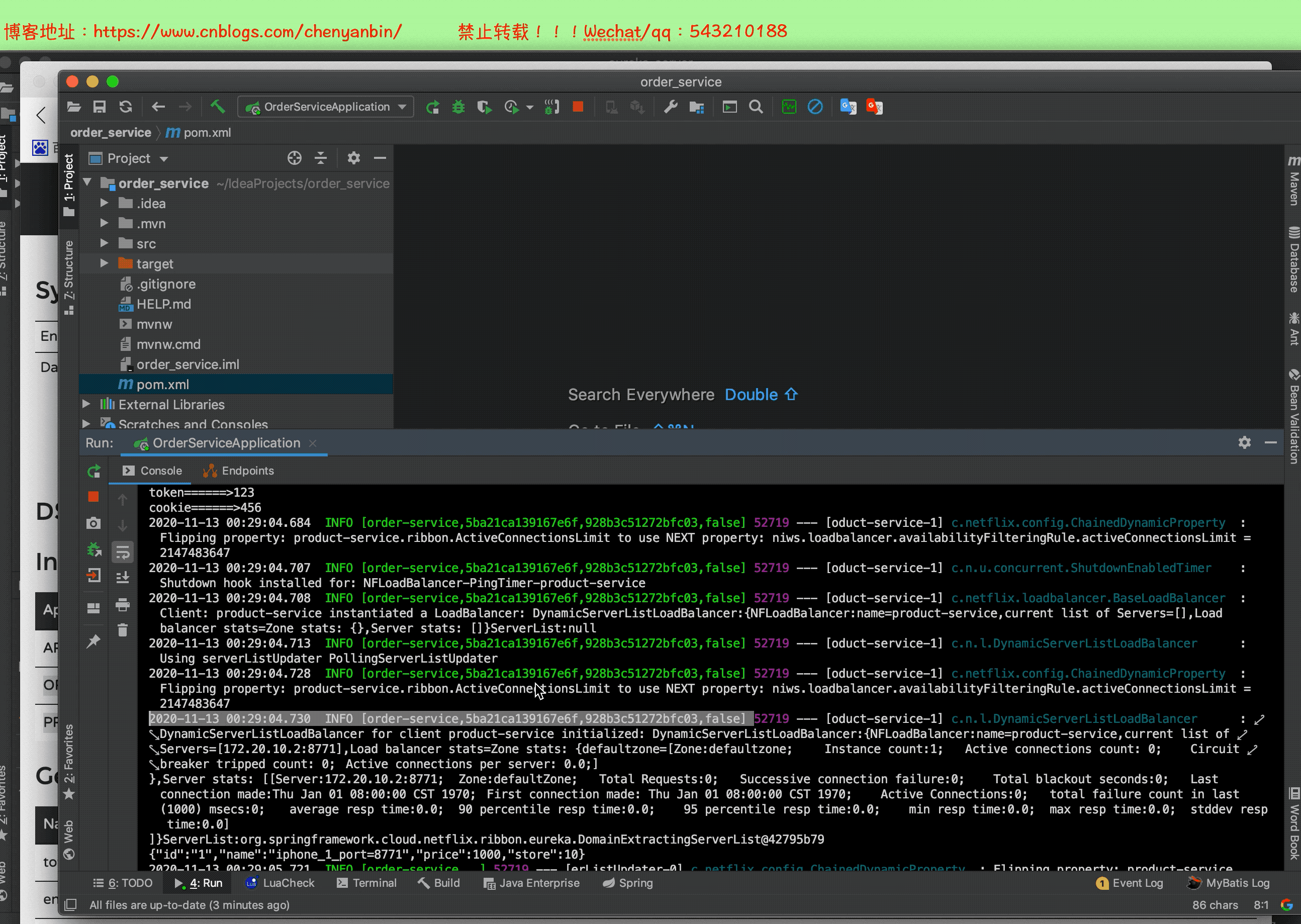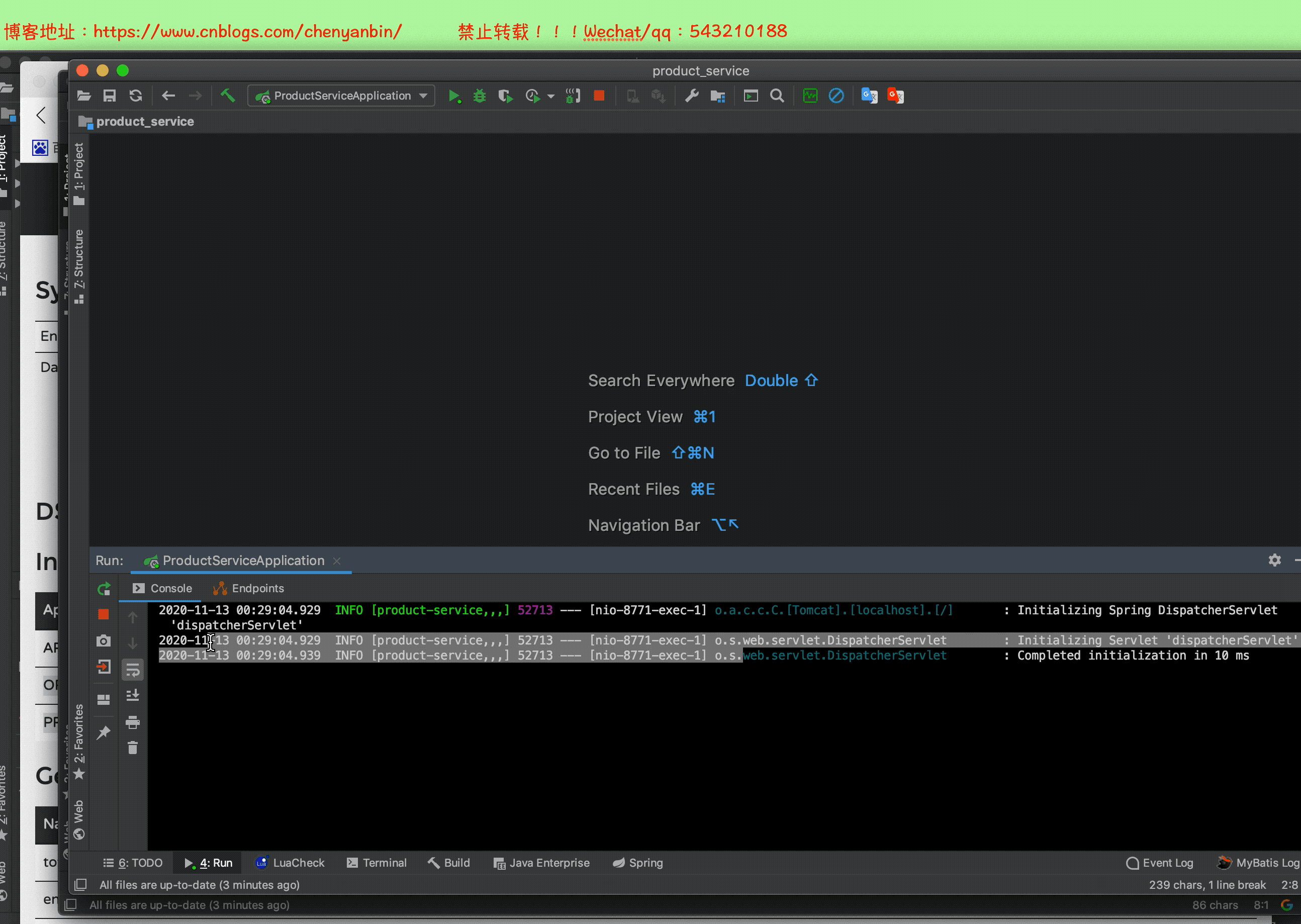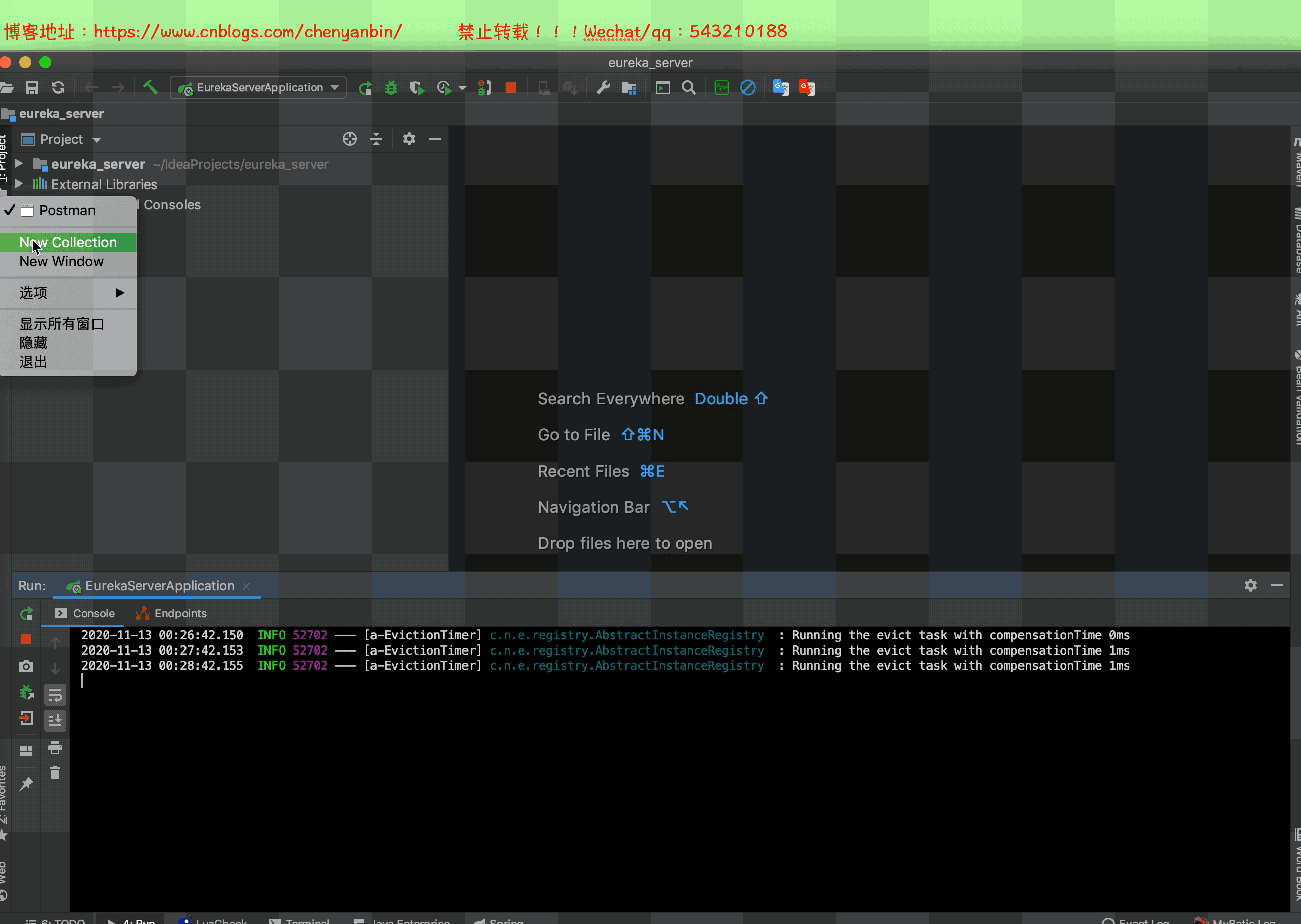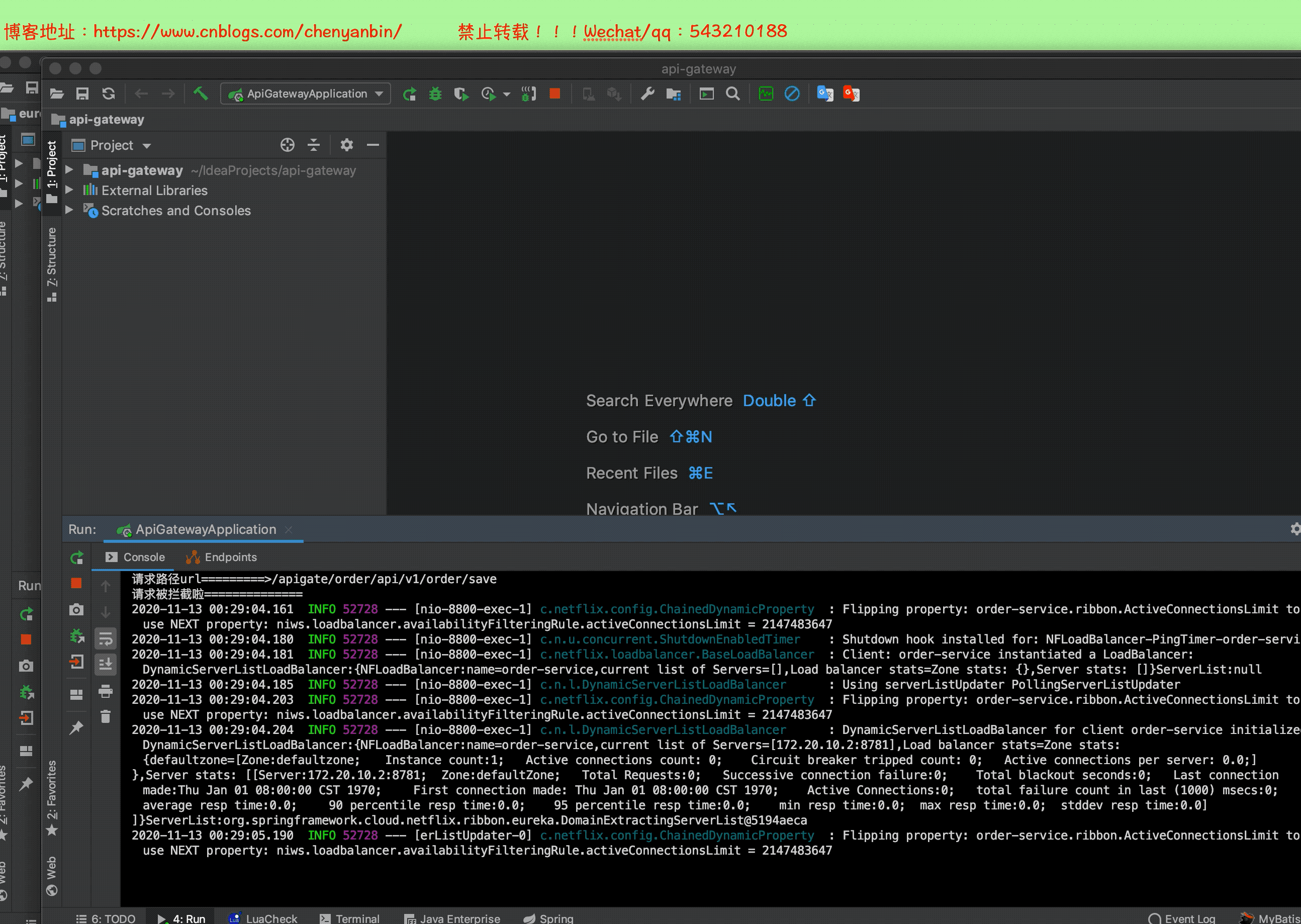
例如:【order-service,f674cc8202579a50,4727309367e0b514,false】
-
- 第一个值:spring.application.name
- 第二个值,sleuth生成的一个ID,交Trace ID,用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID
- 第三个值:spanid基本的工作单元,获取元数据,如发送一个http请求
- 第四个值:false,是否要将该信息输出到zipkin服务中来收集和展示
添加依赖
牵扯到的服务都得加这个依赖!(我这里是在order-service、product-service加的依赖)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
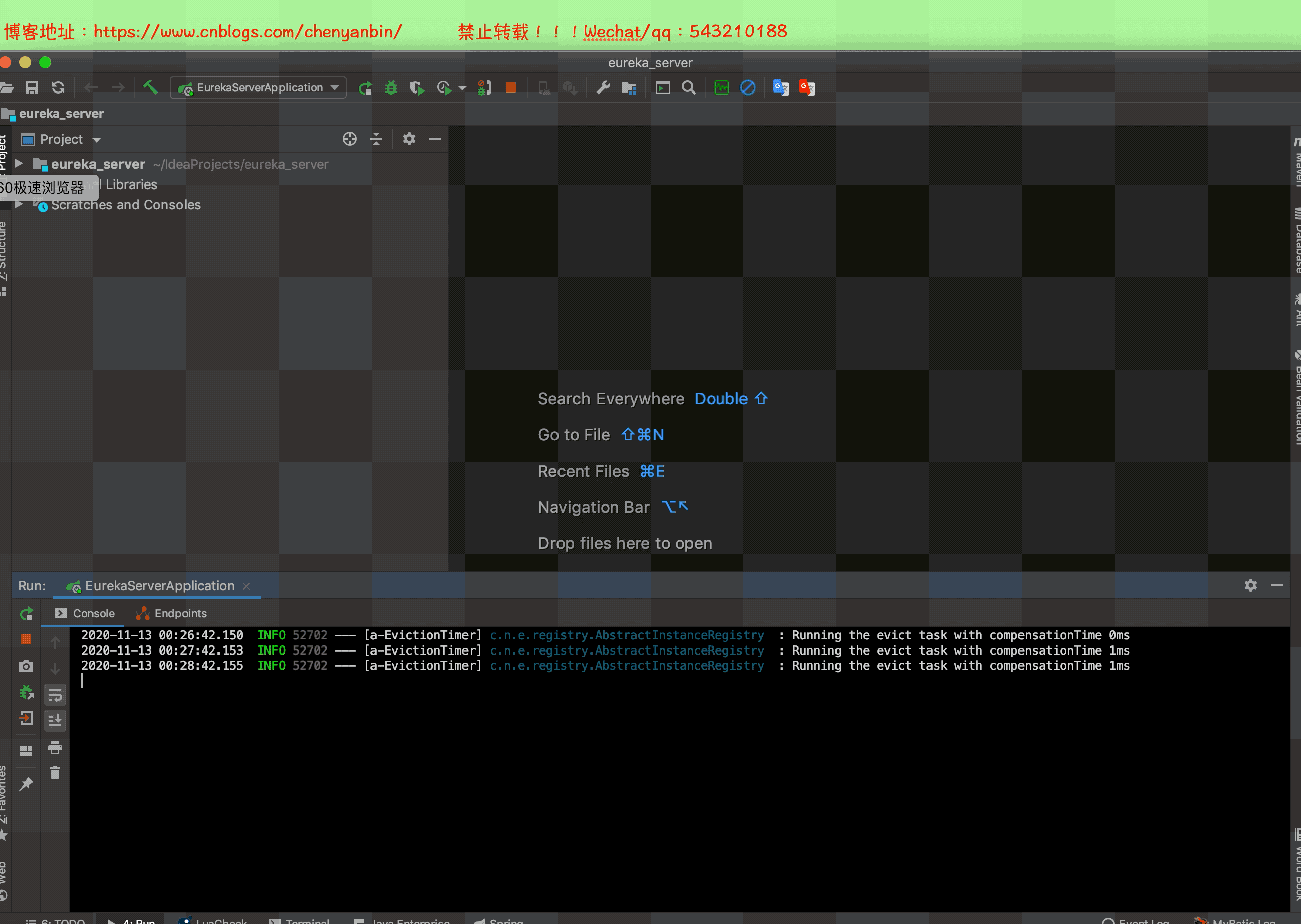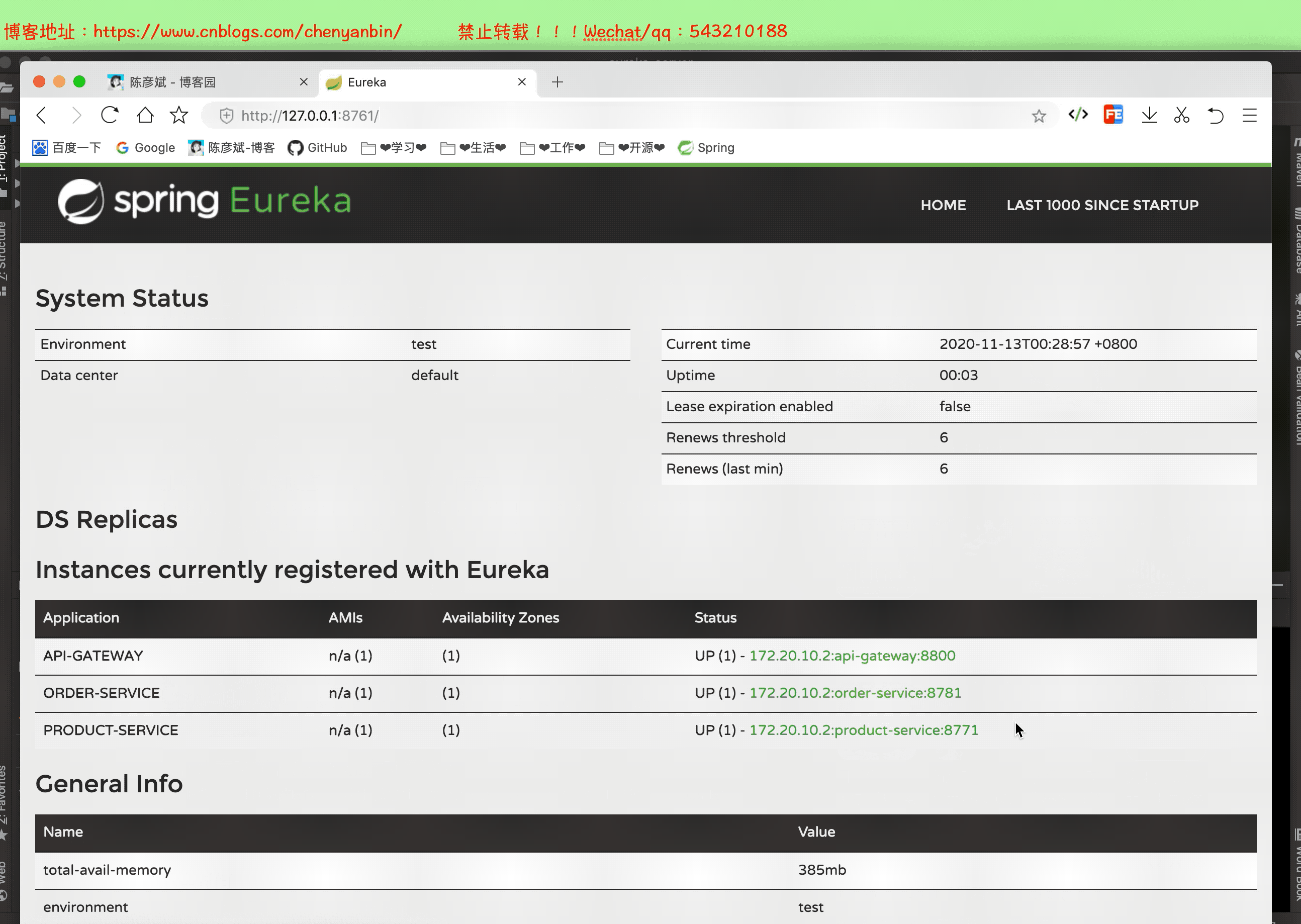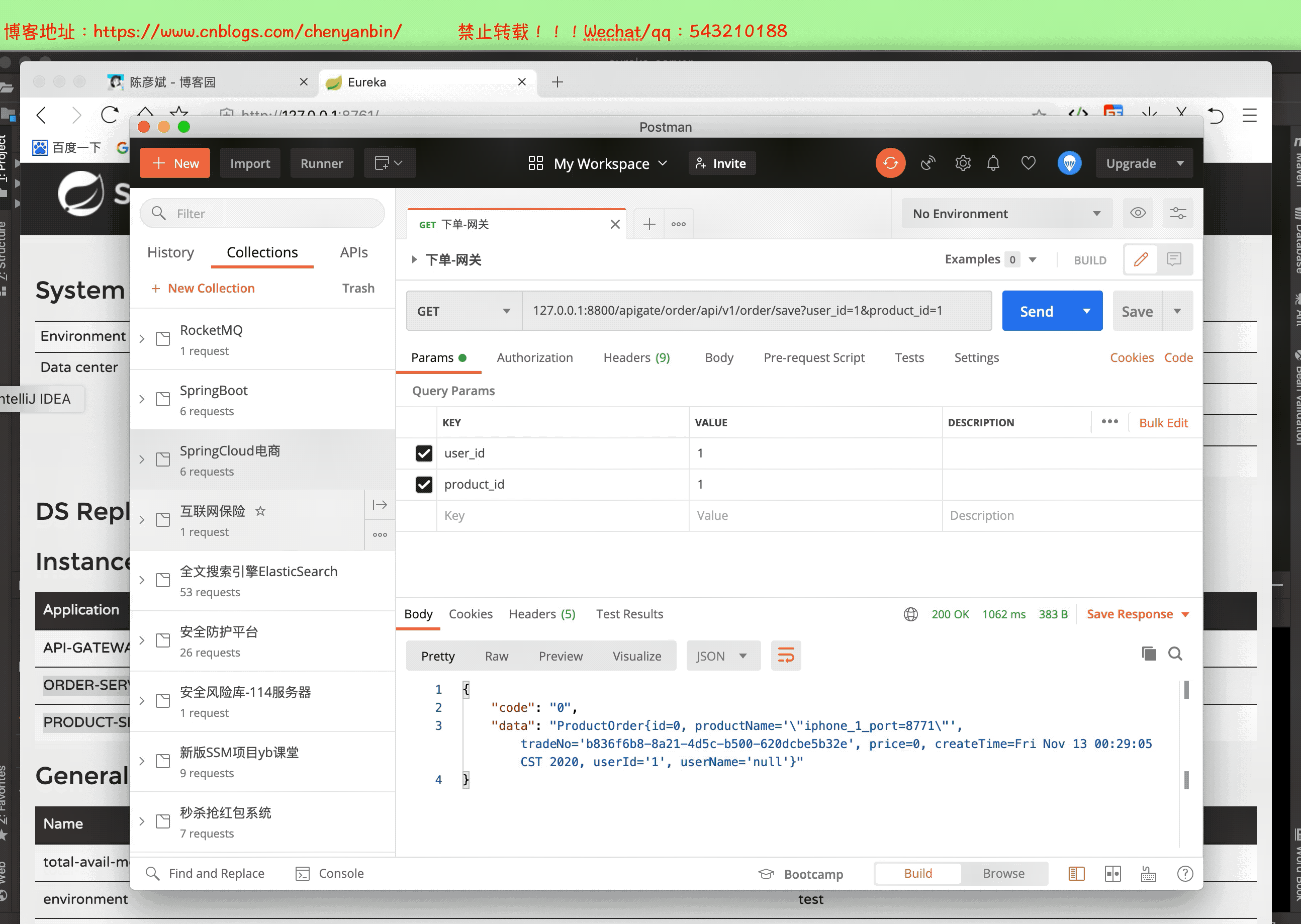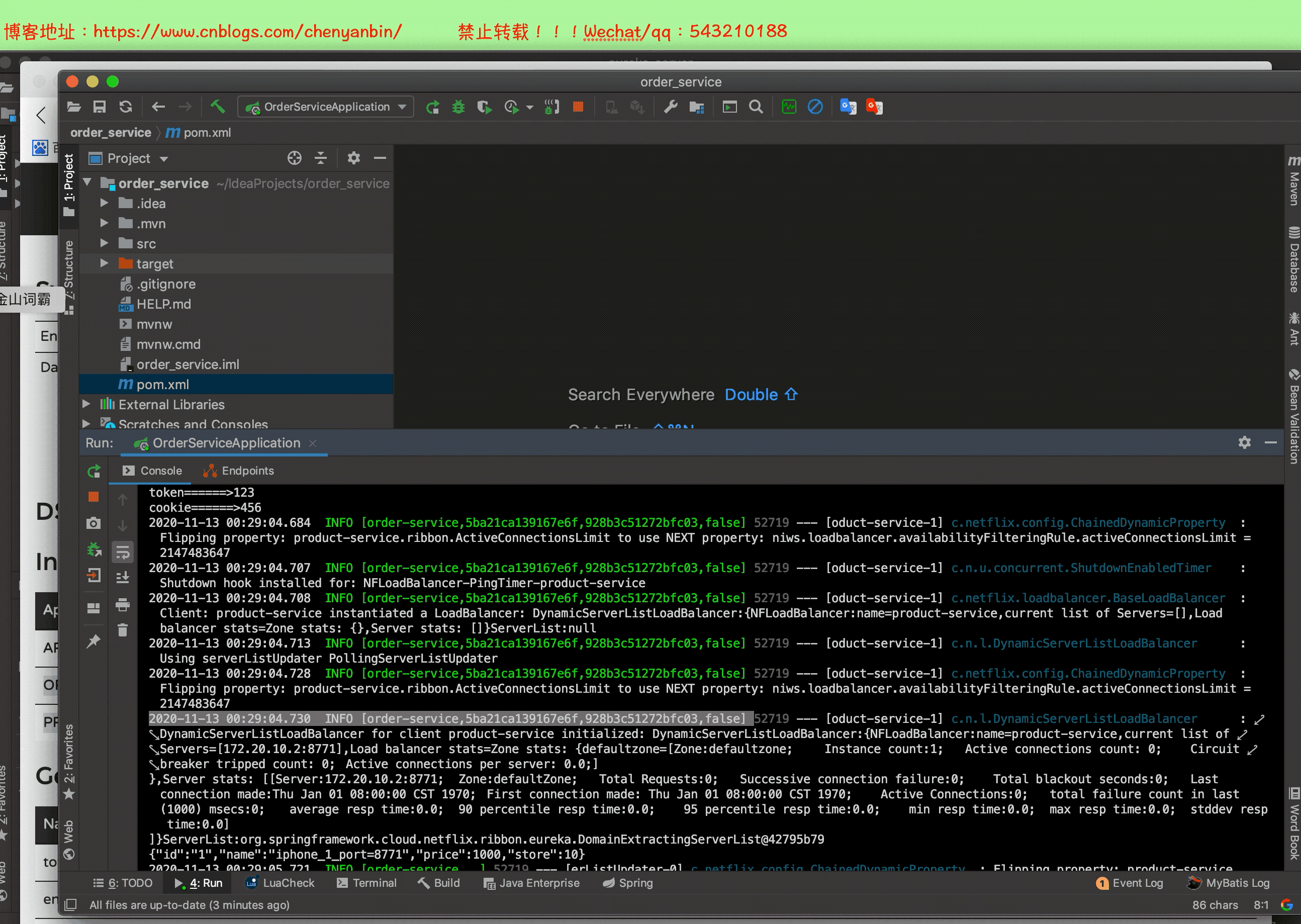
启动整个微服务测试
部署可视化链路追踪Zipkin
简介
大规模分布式系统的APM工具,基于Google Dapper的基础实现,和Sleuth结合可以提供可视化web界面分析调用链路耗时情况。
官网
部署
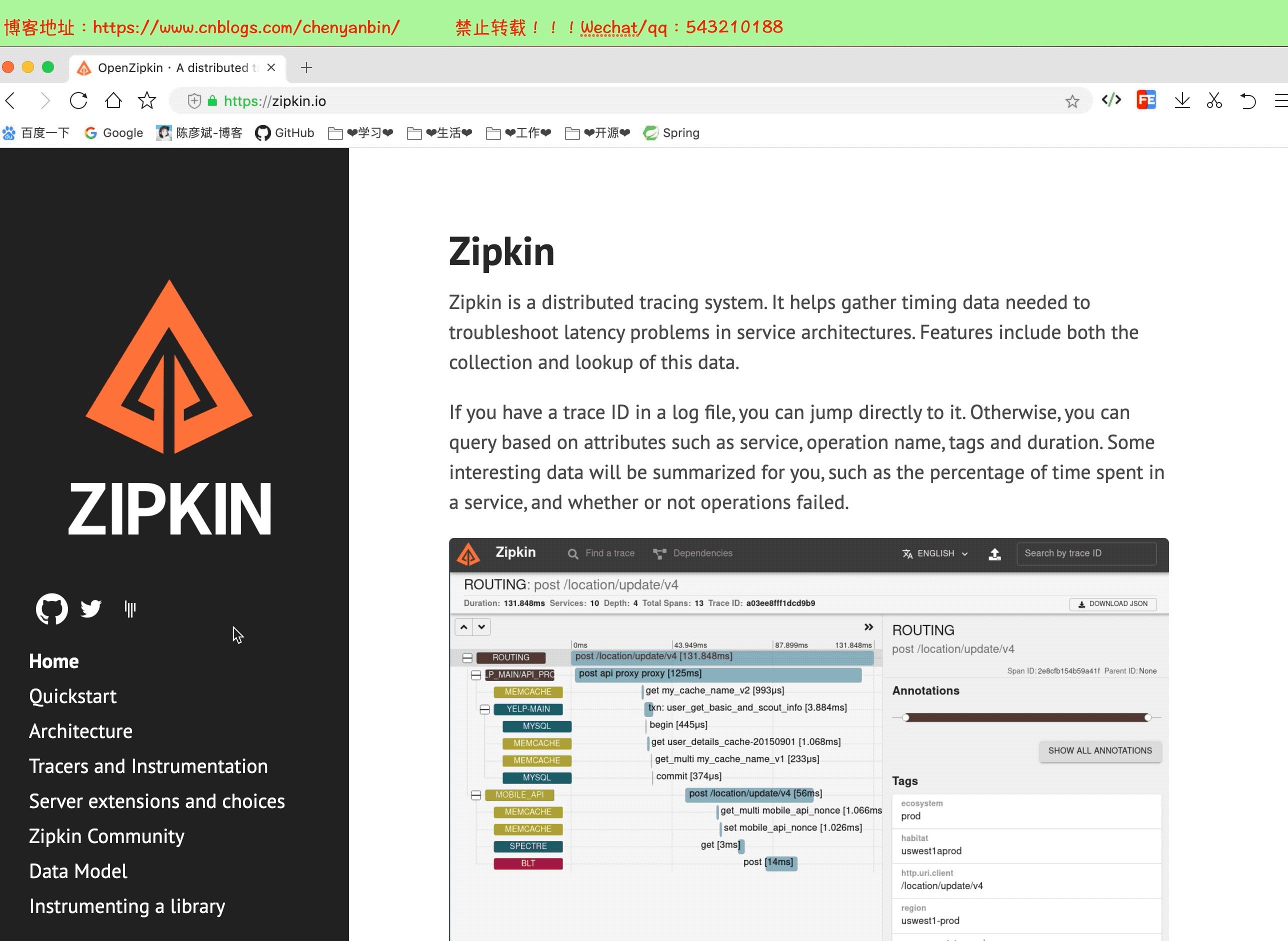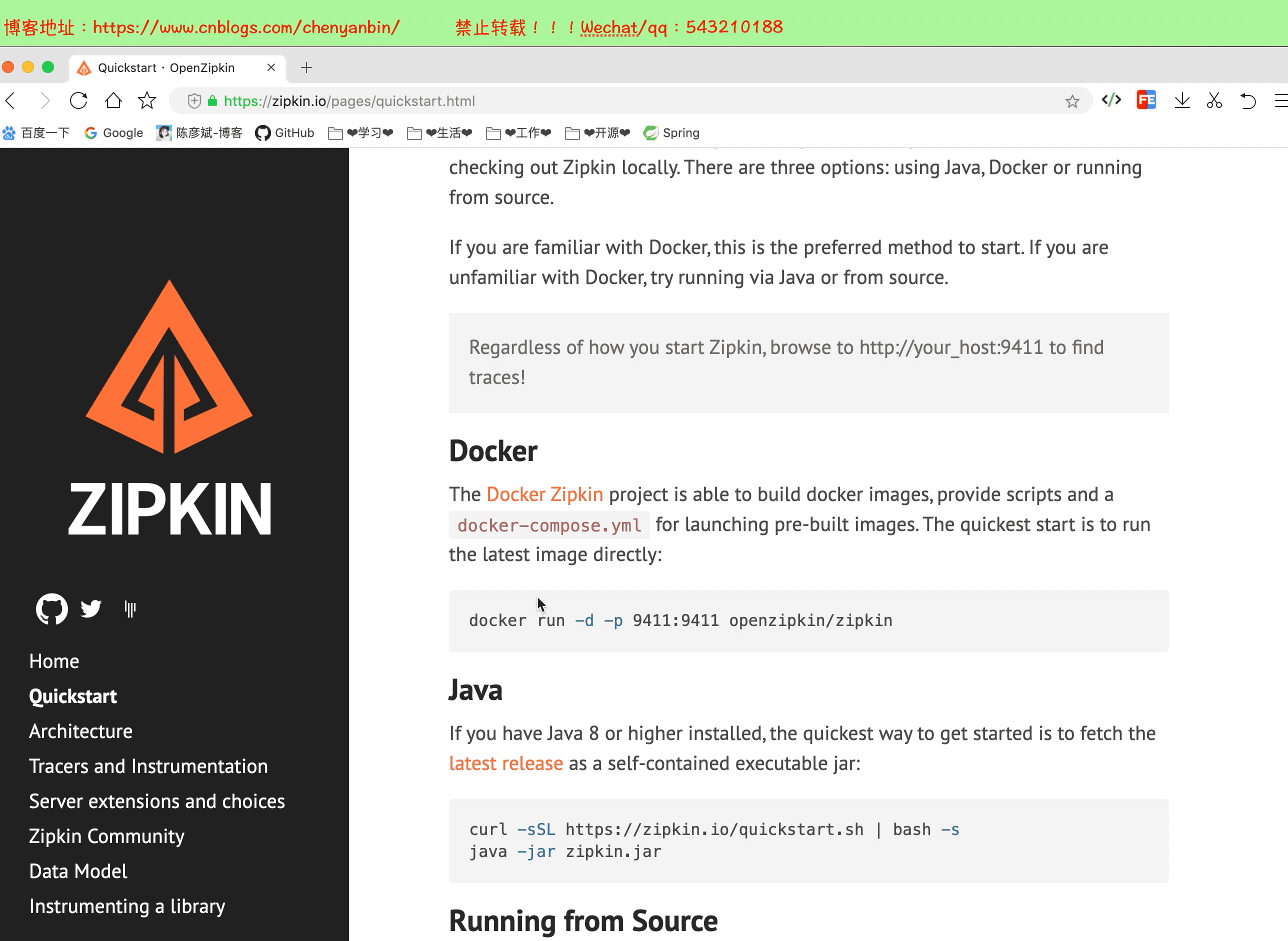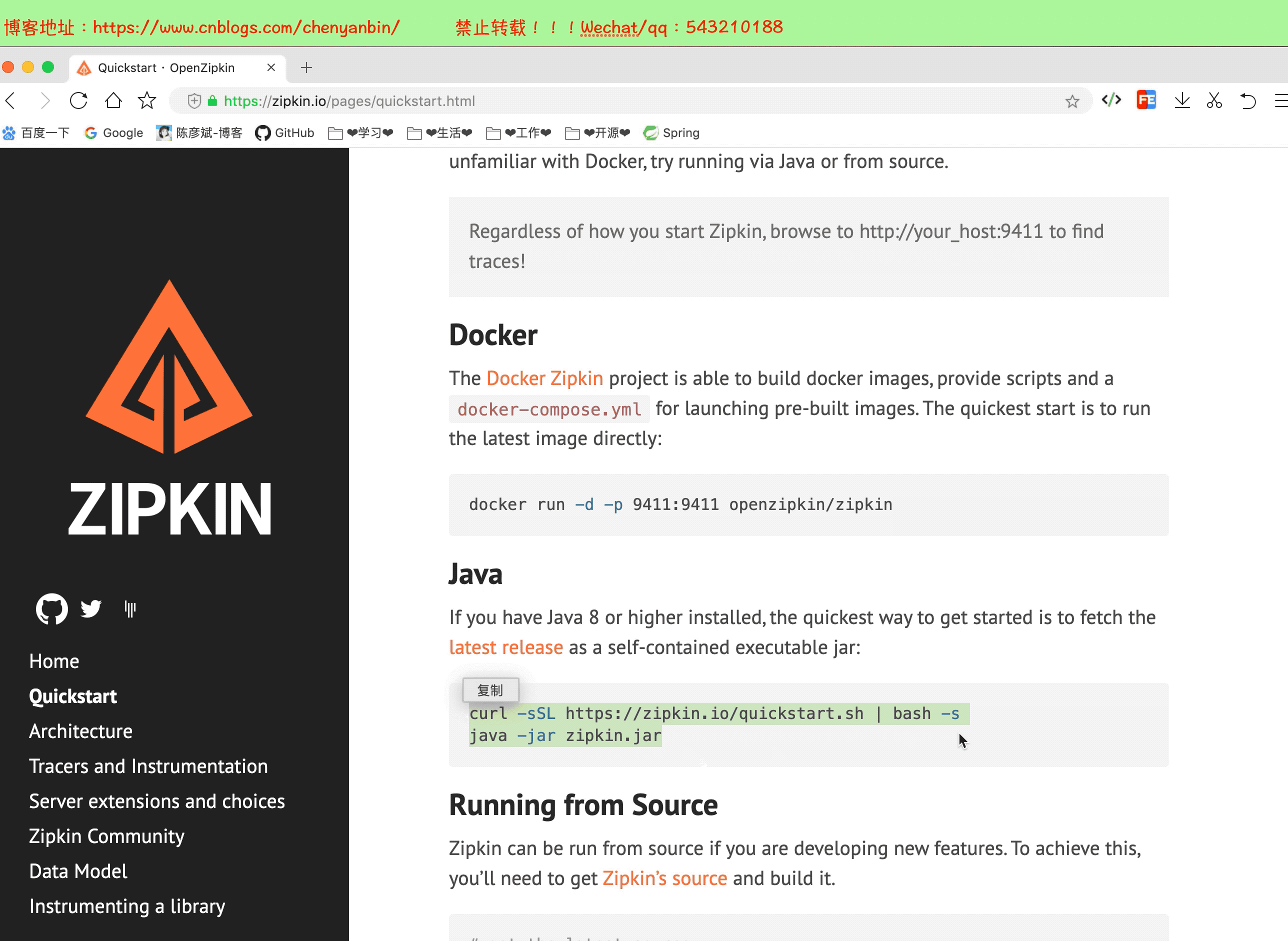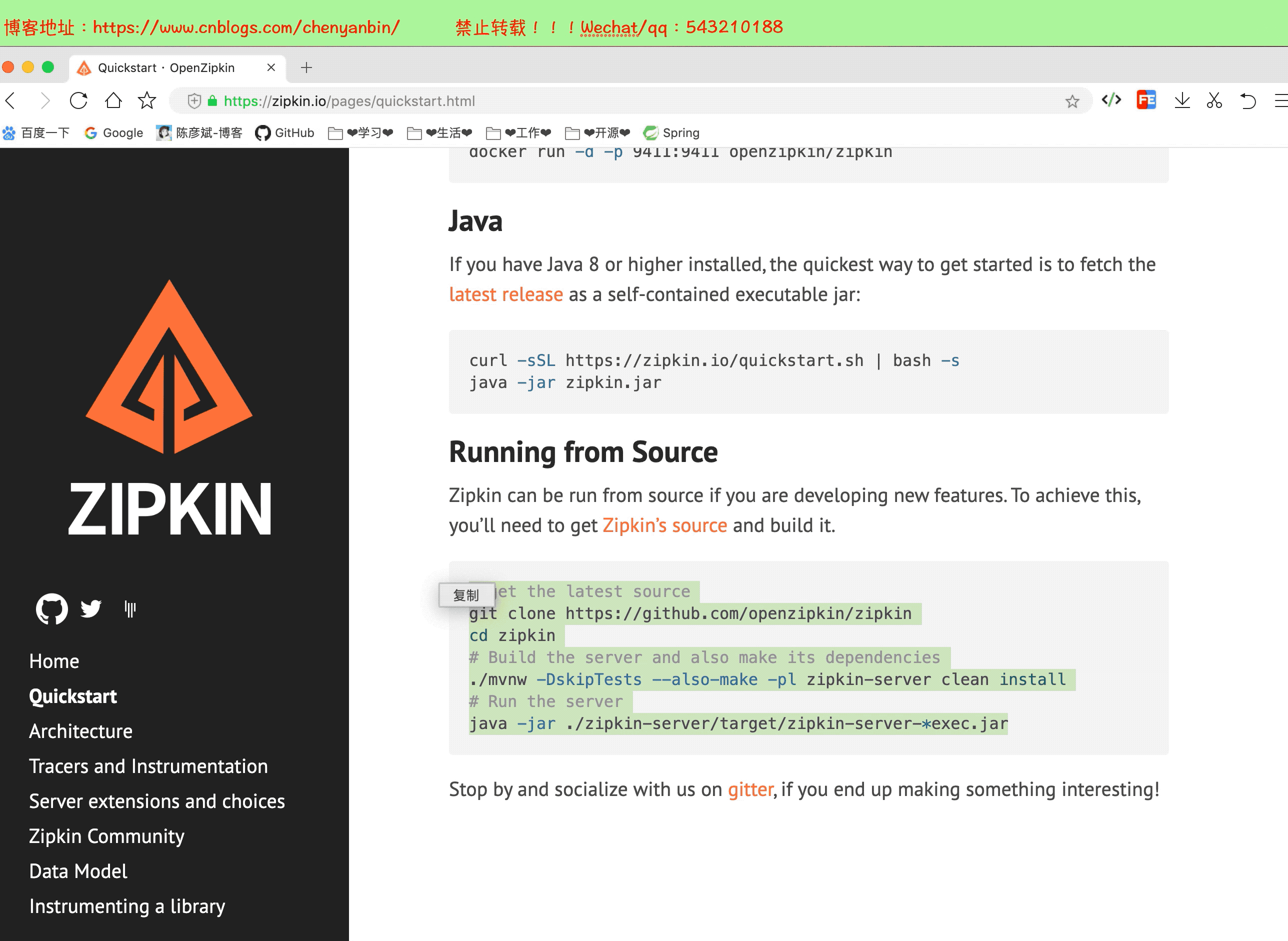
这里我使用下载源码的方式
# get the latest source
git clone https://github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
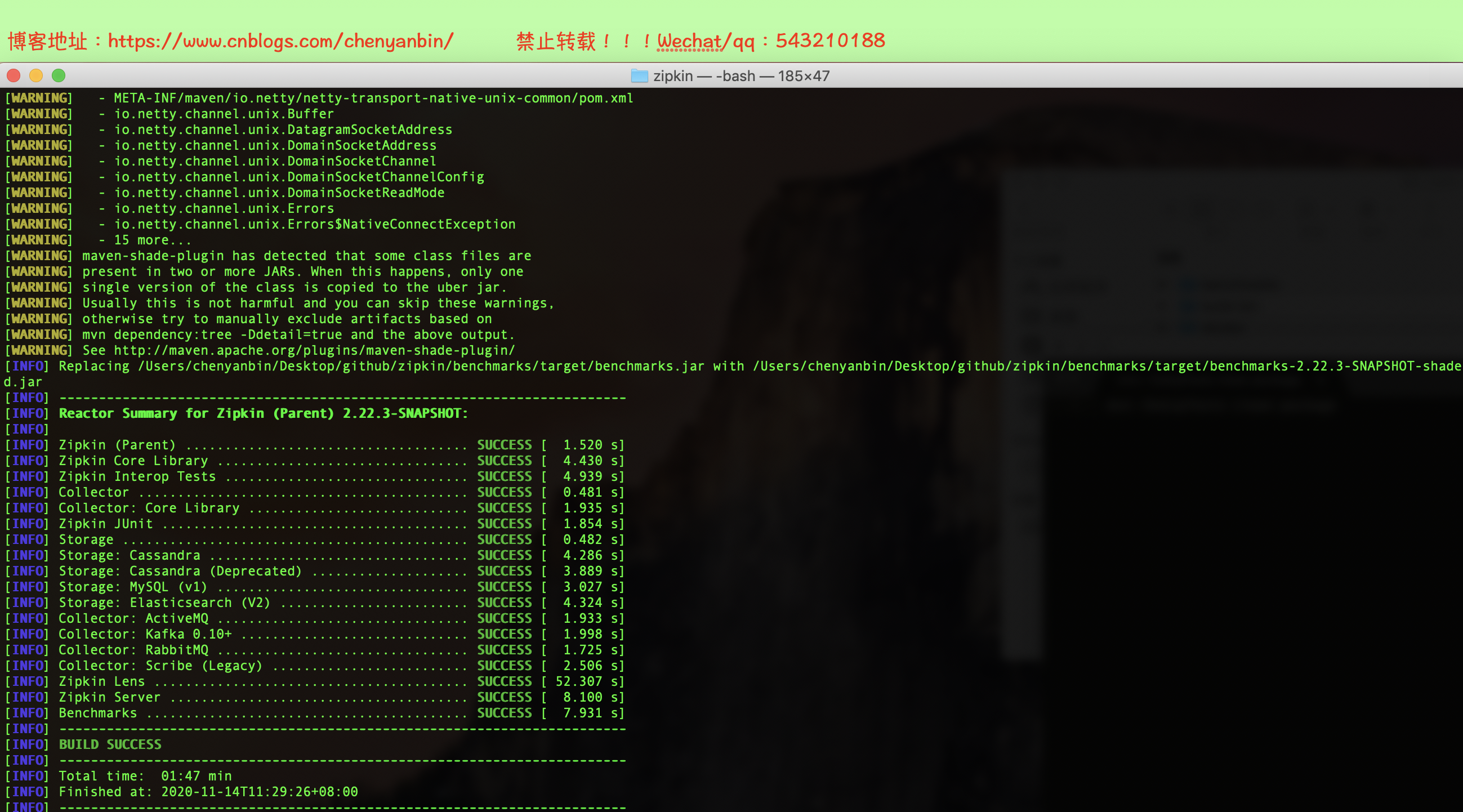
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
备注
因为种种原因,从github上下载这个源码包,非常慢,可以使用这种方式解决:点我直达
git clone https://gitee.com/mirrors/zipkin.git
cd zipkin
mvn -DskipTests clean package
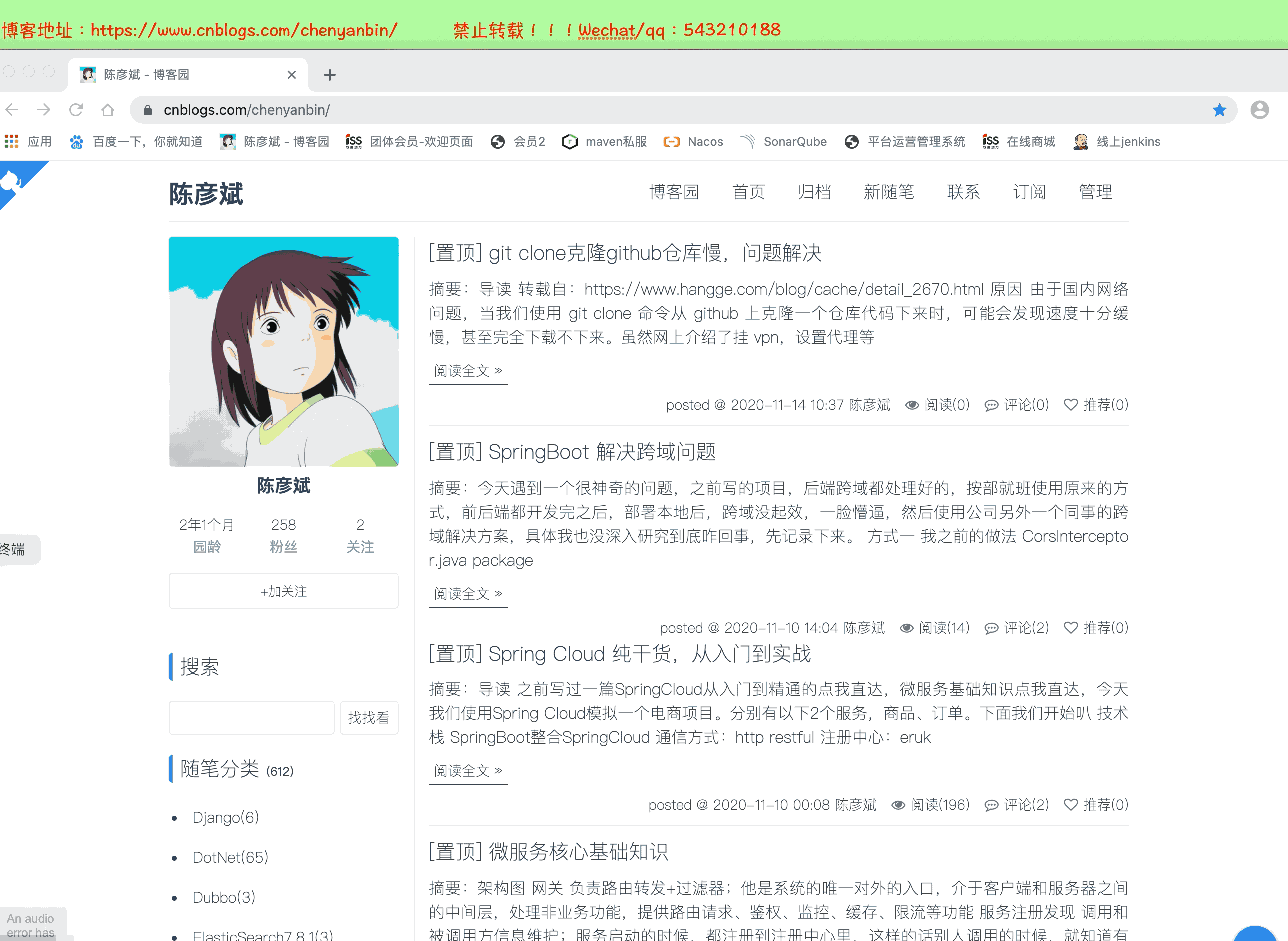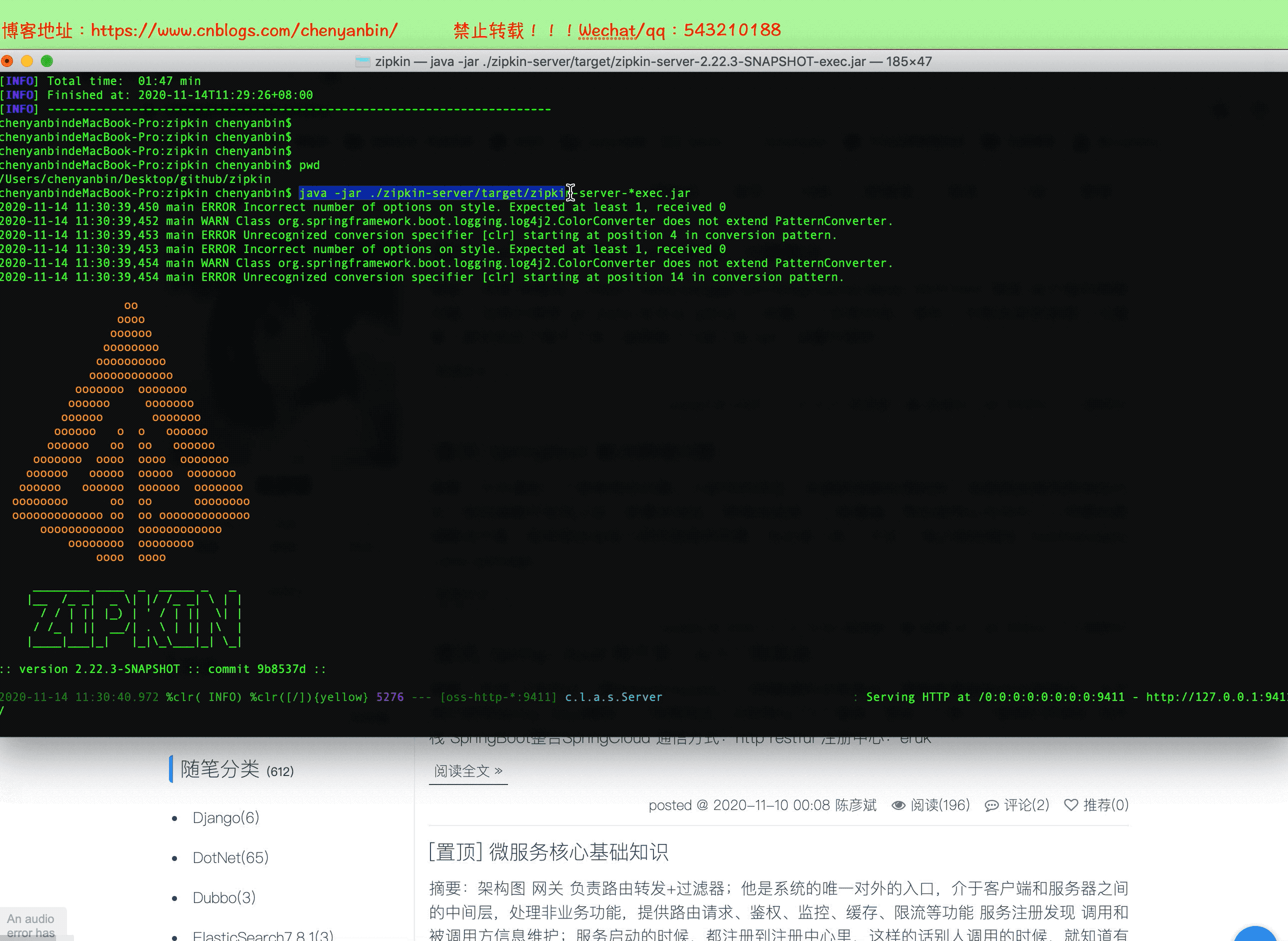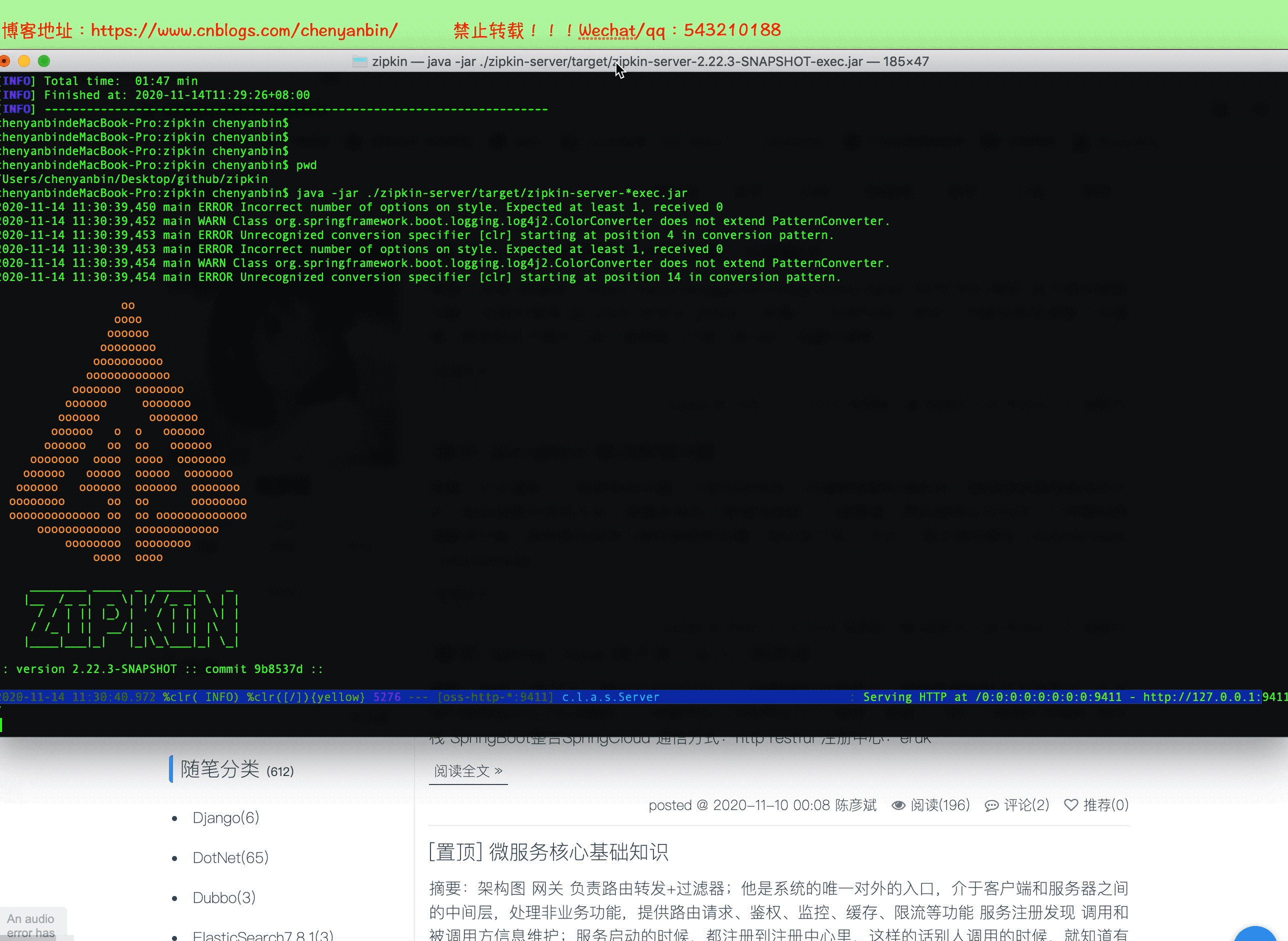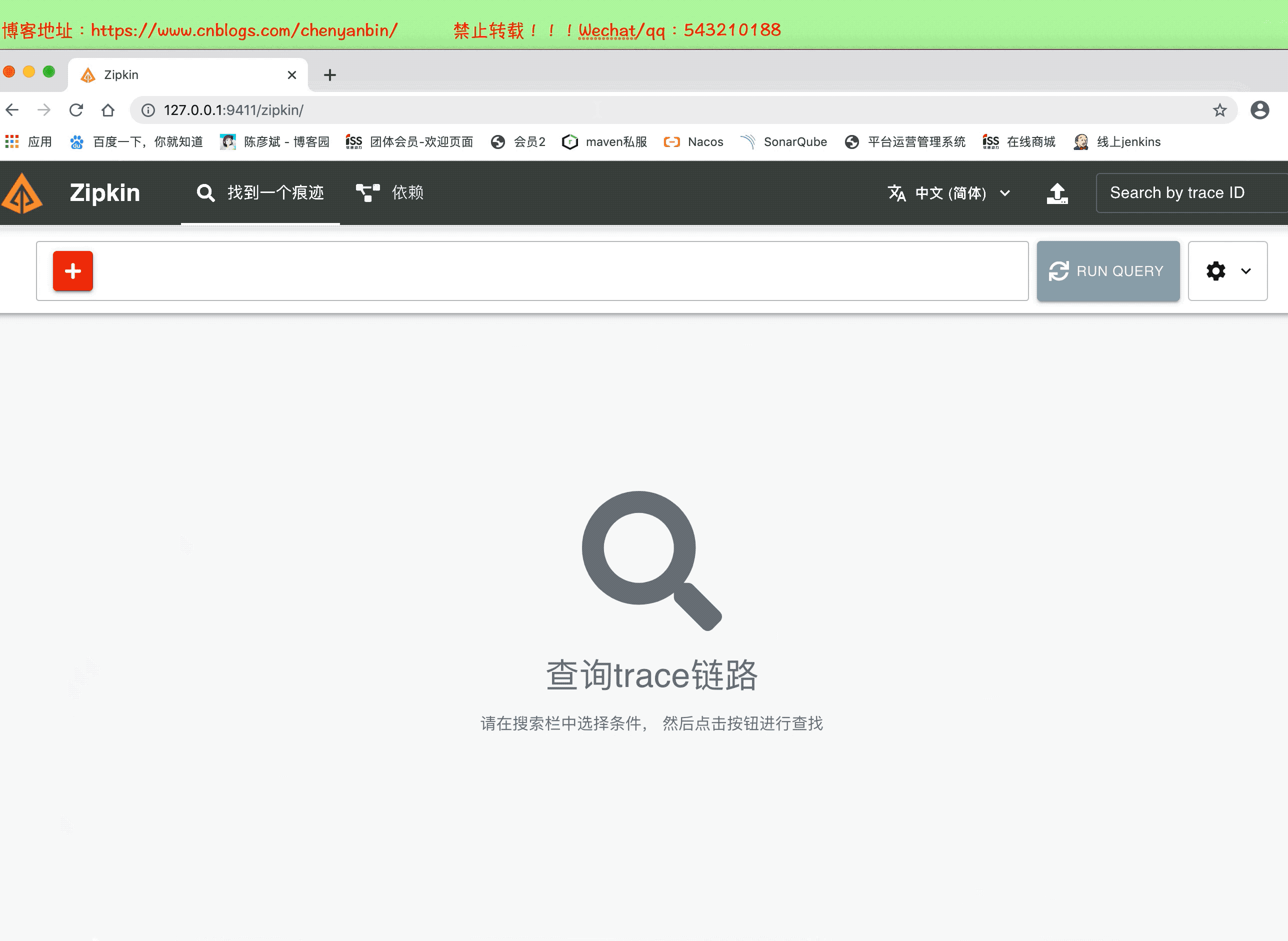
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
启动
地址:ip:9411
Zpikin+Sleuth整合
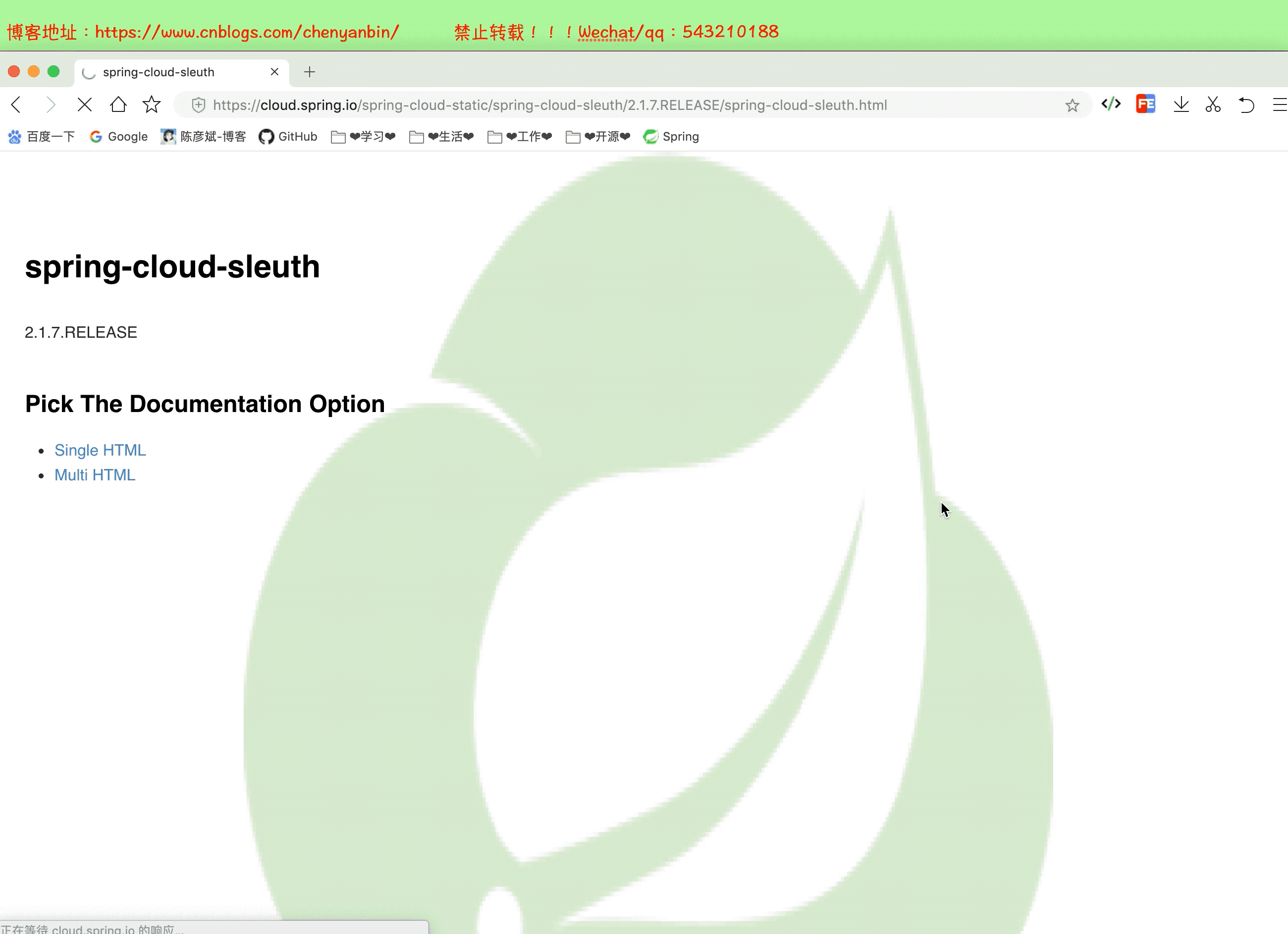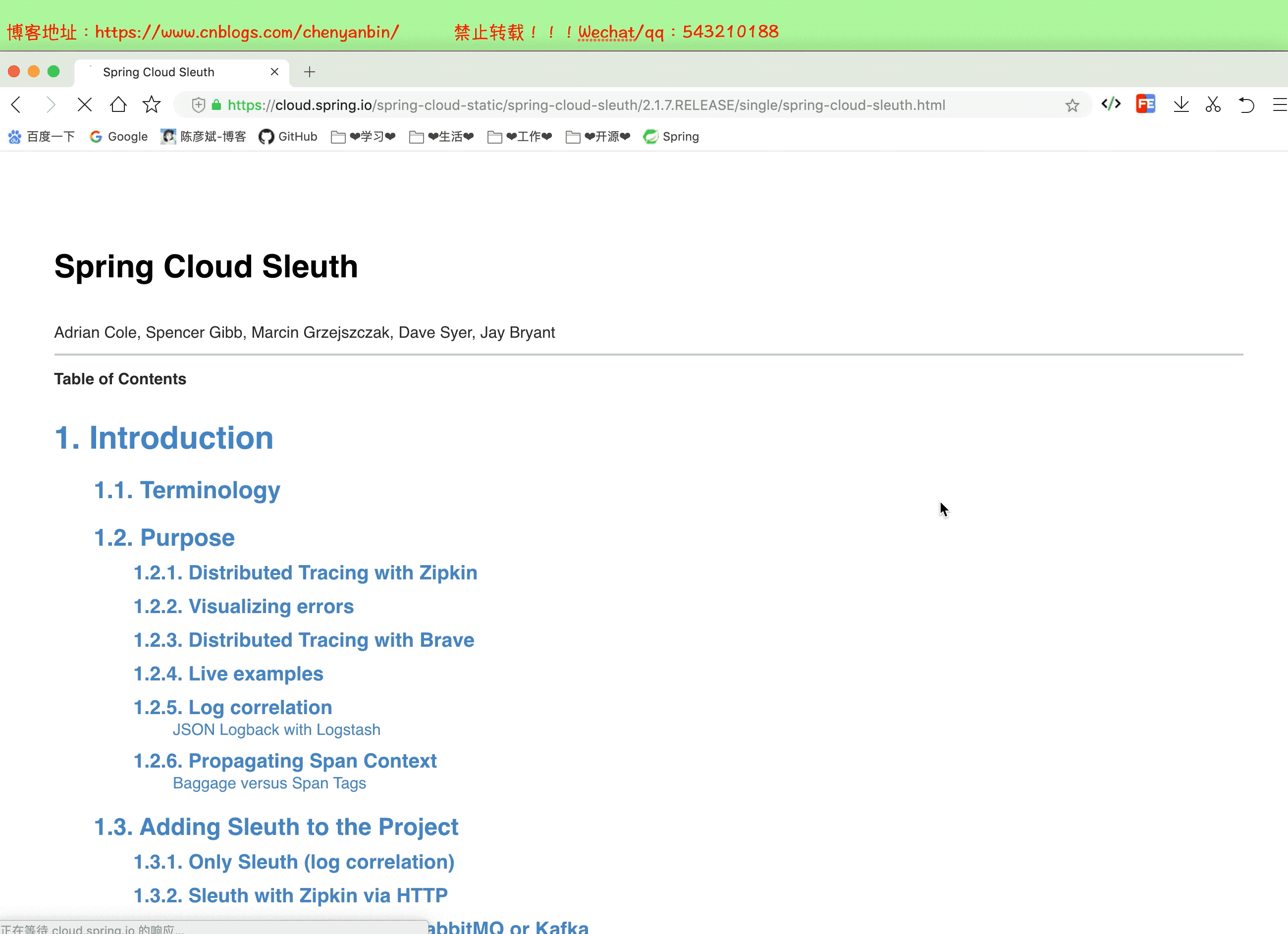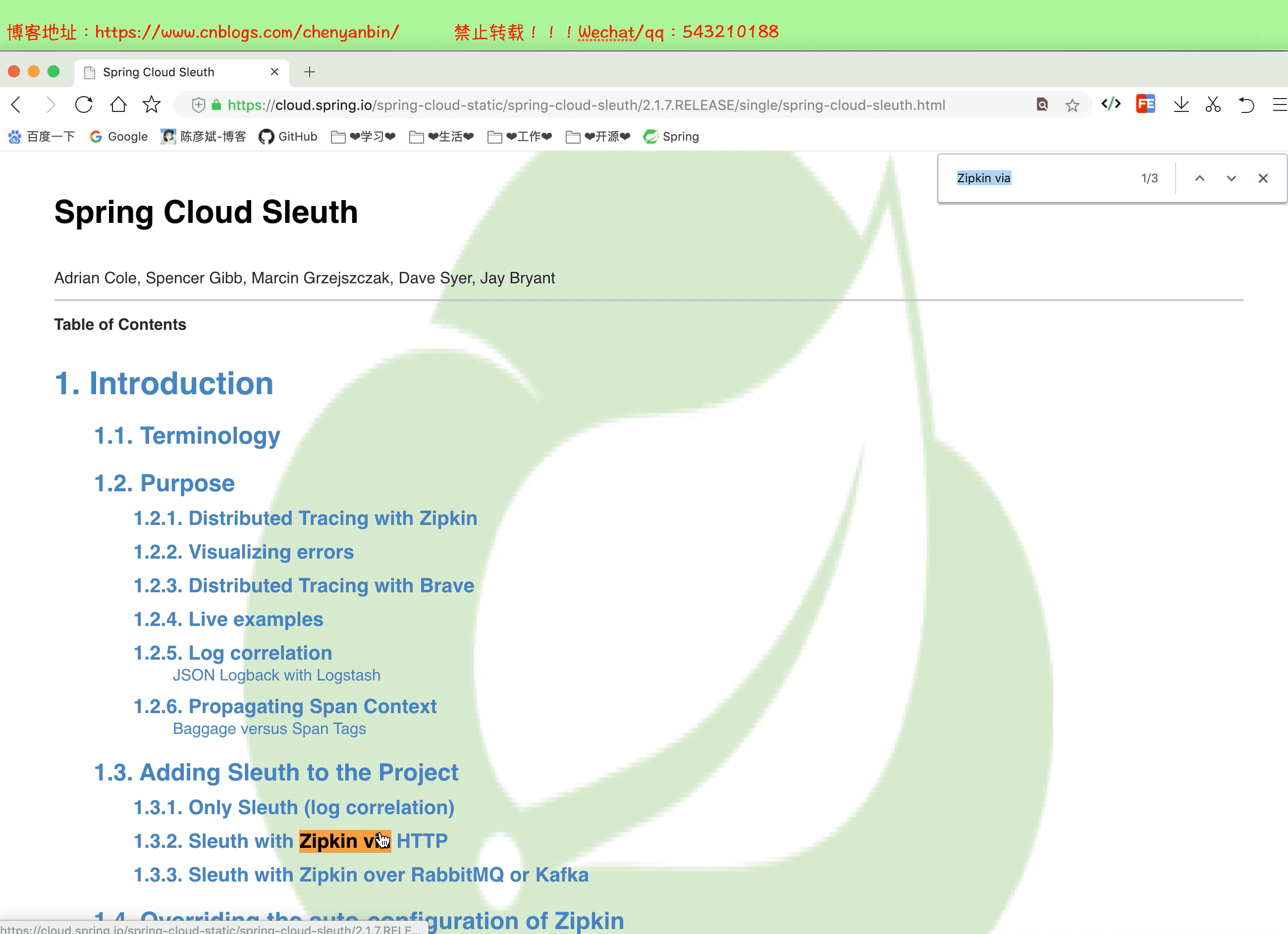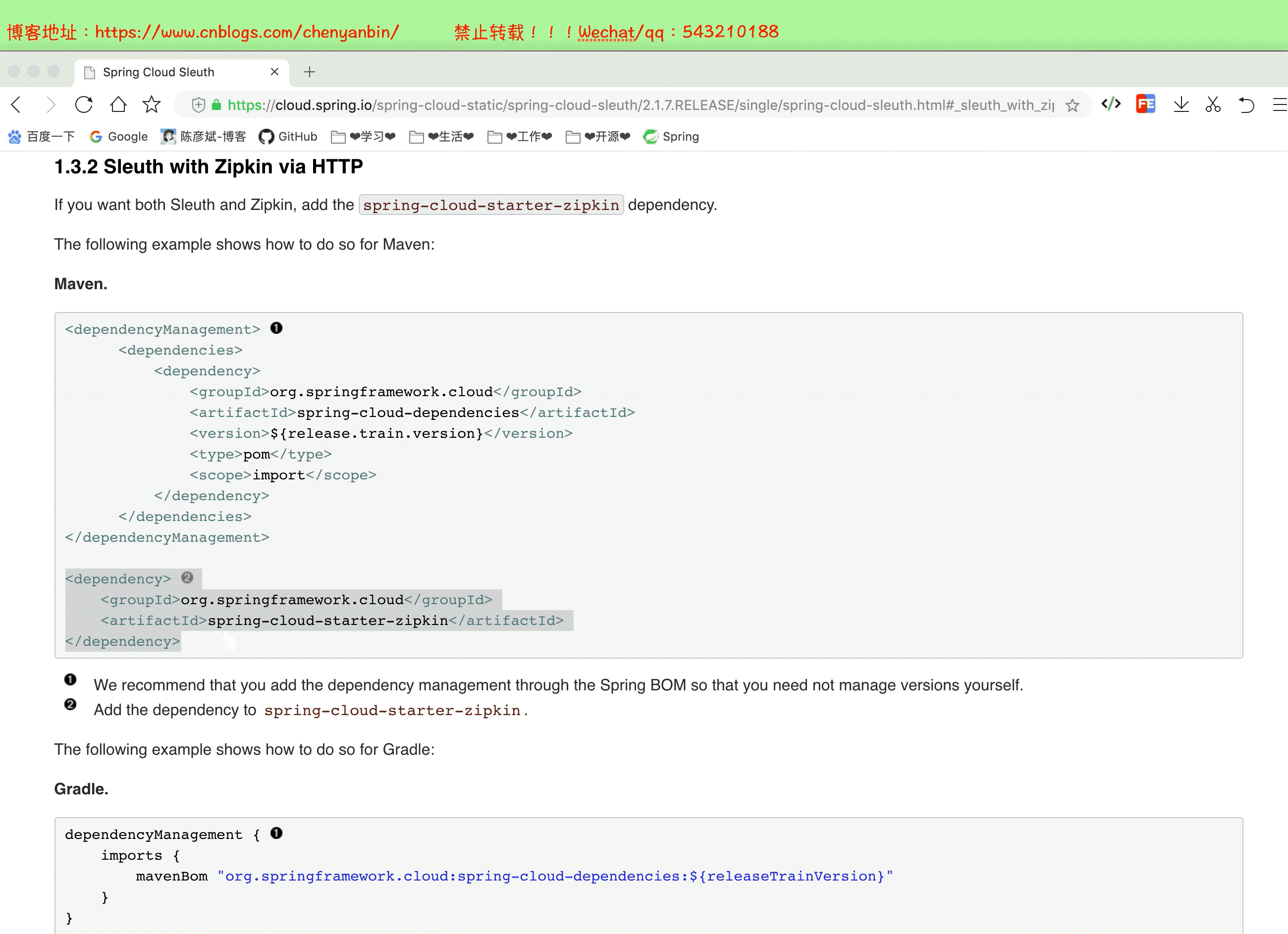
添加依赖
涉及到的服务都得加!(我这里是在order-service、product-service加的依赖)
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>

注意
之前加过Sleuth依赖,现在加zipkin依赖,2.x的zipkin已经包含sleuth了,这里可以把之前的sleuth依赖去掉
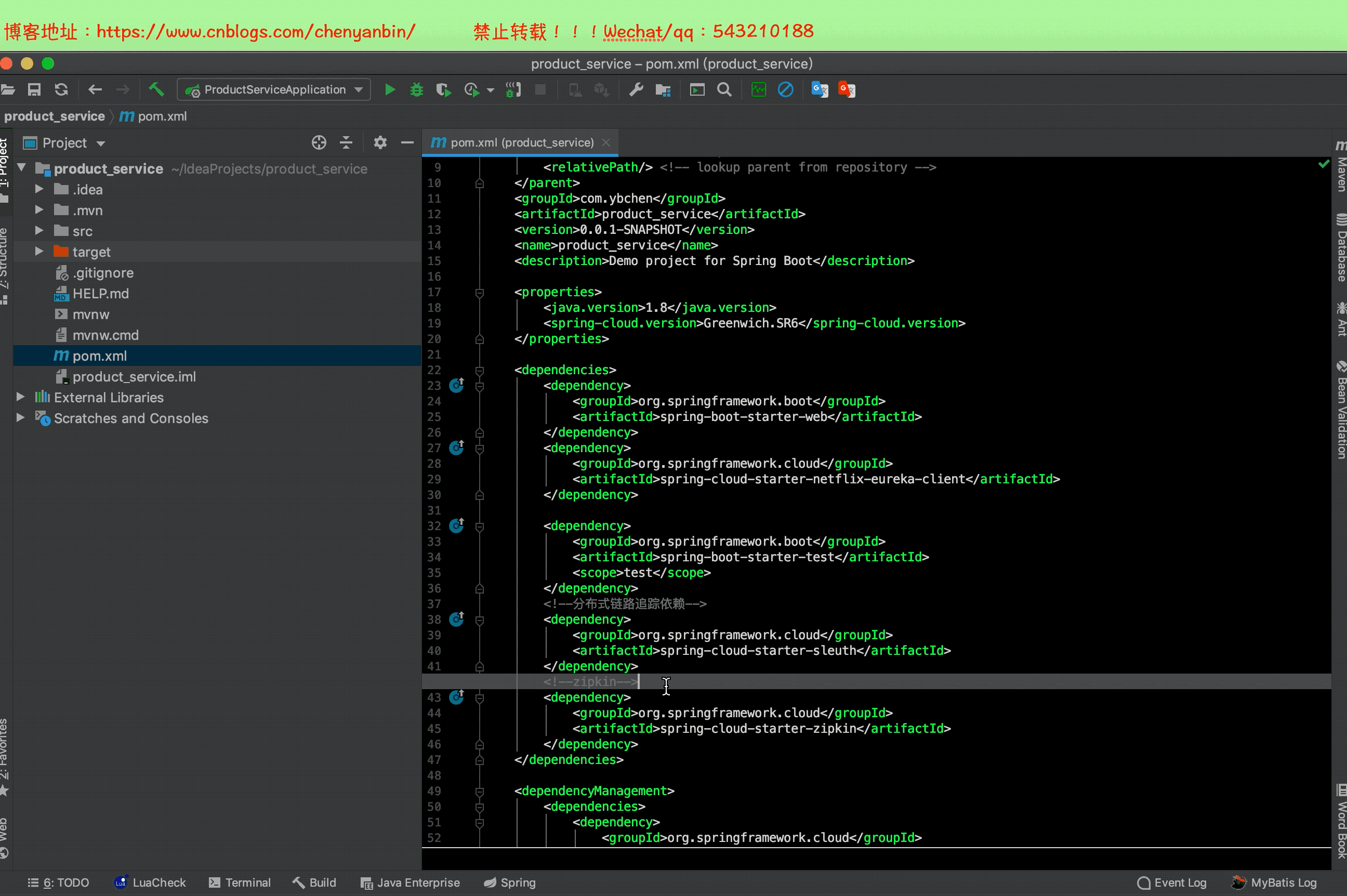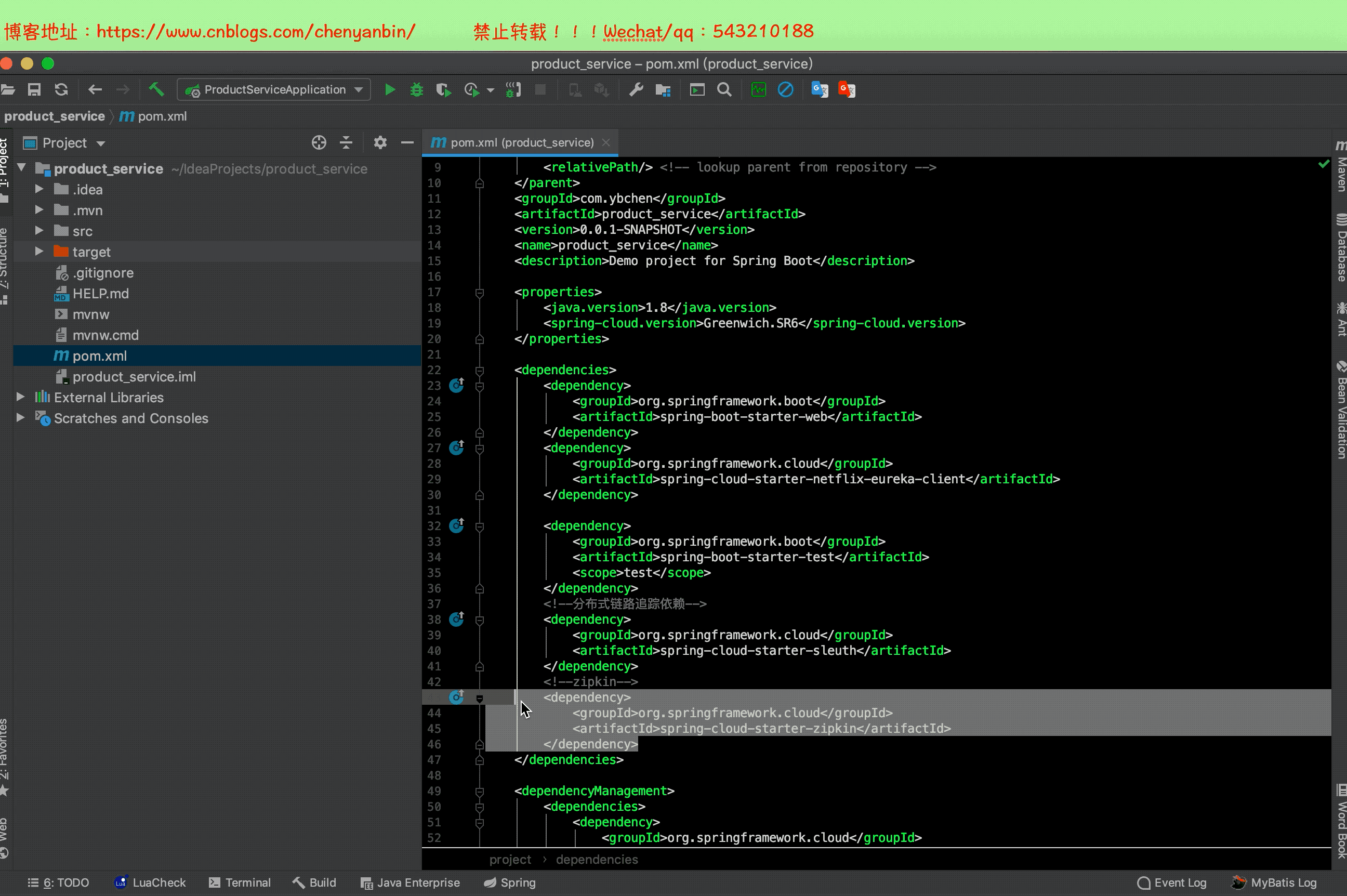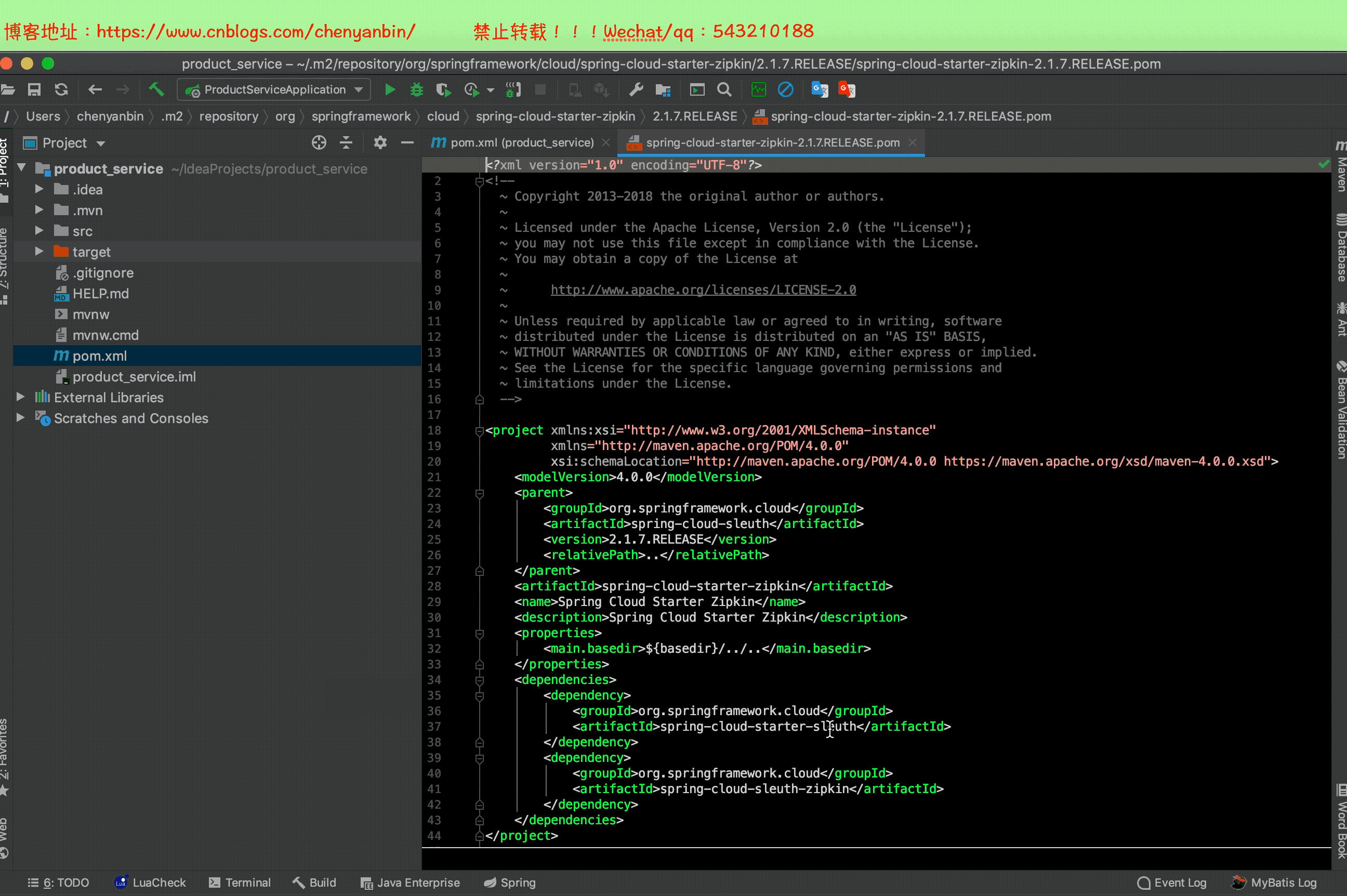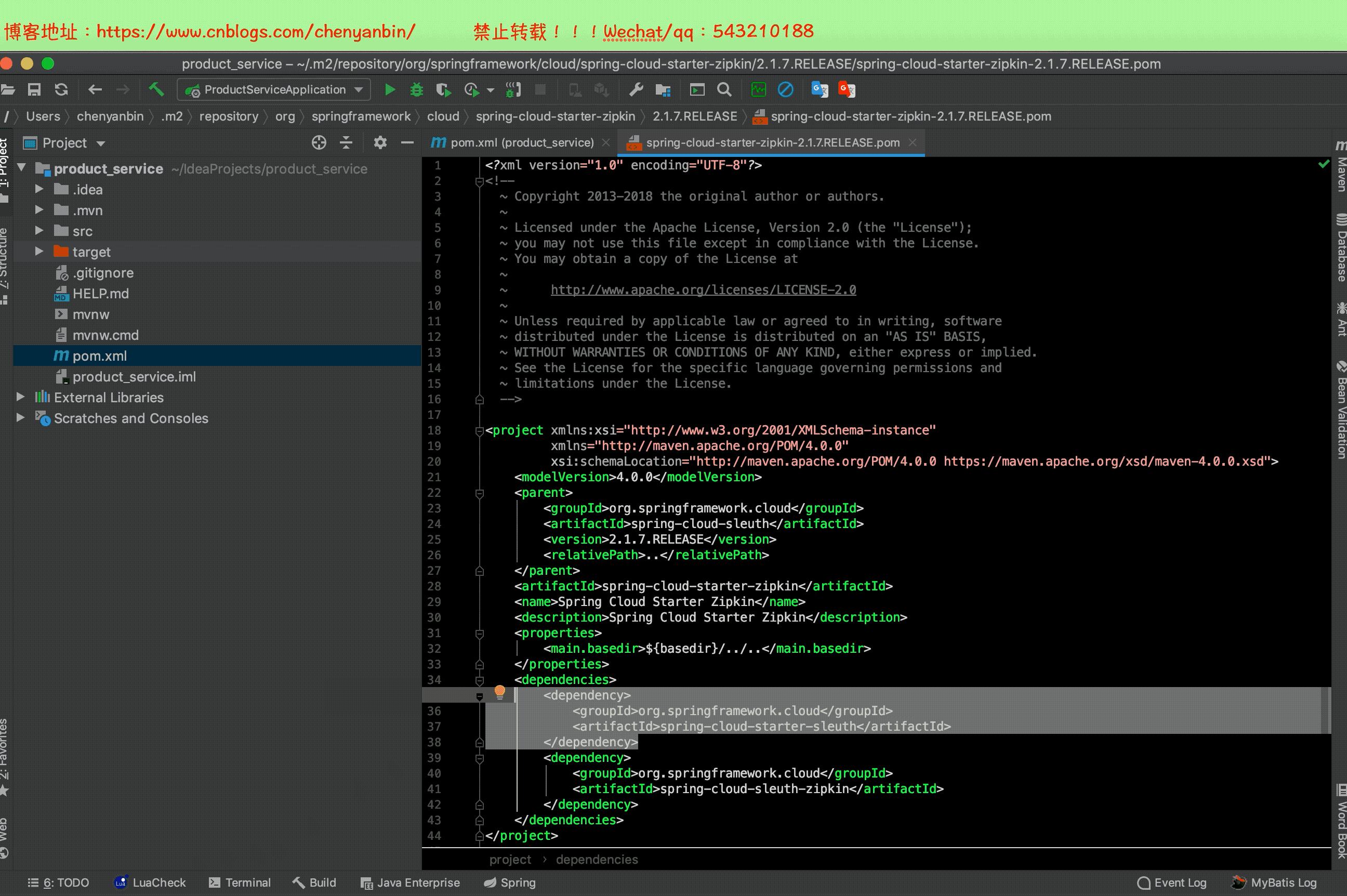
修改配置文件
默认指向的zipkin地址为本机地址:http://localhost:9411/
默认收集百分比为:10%
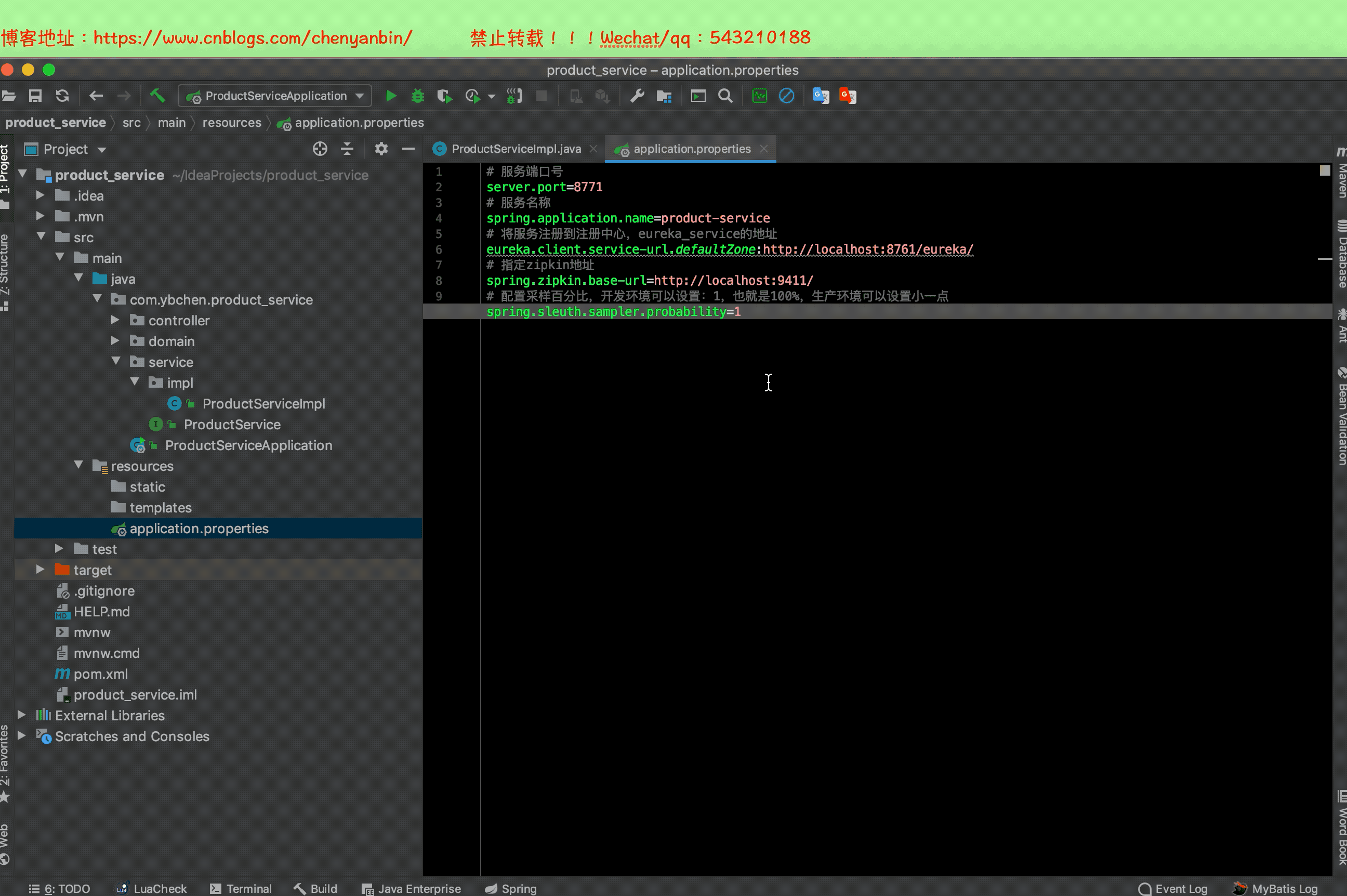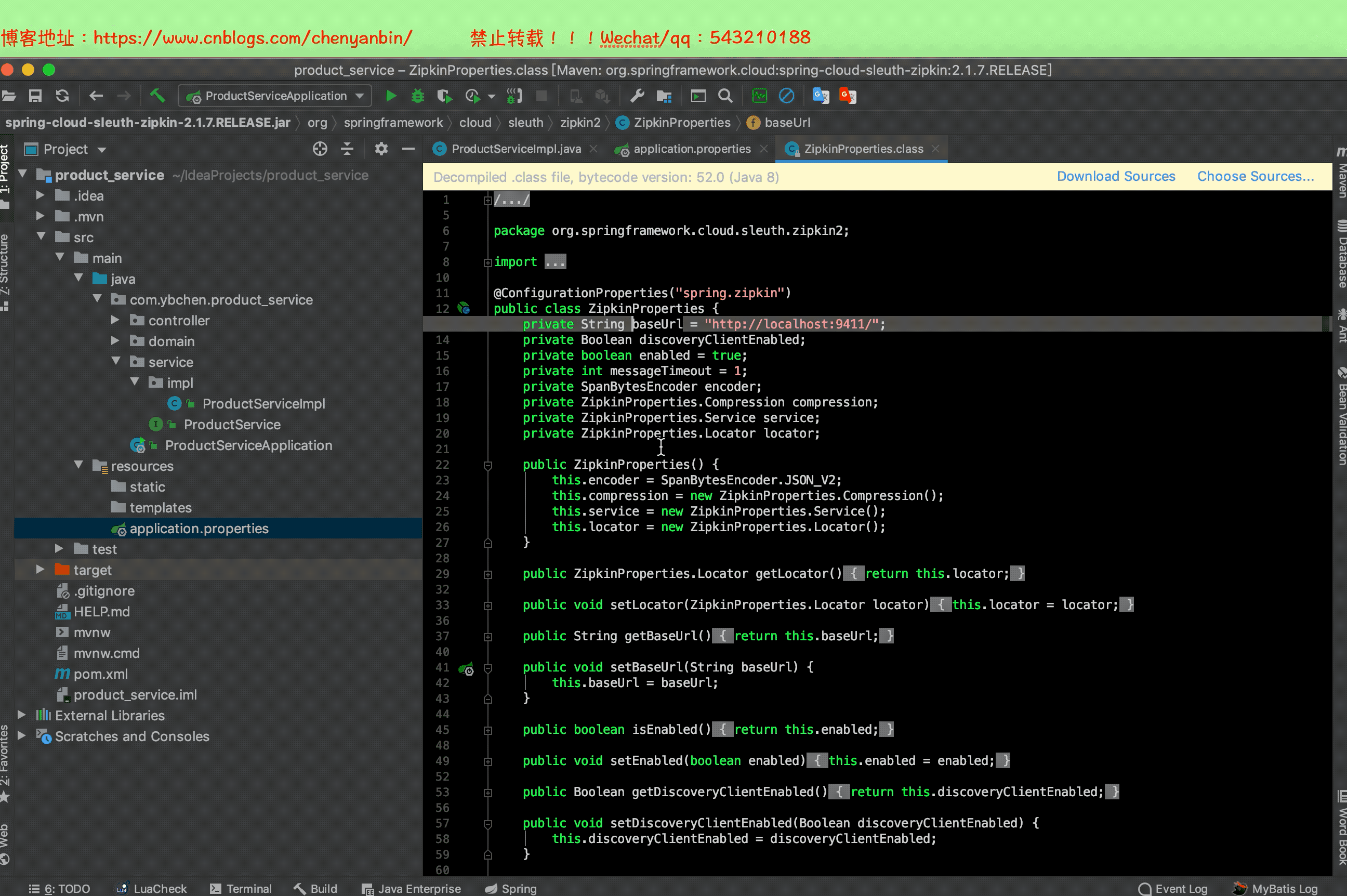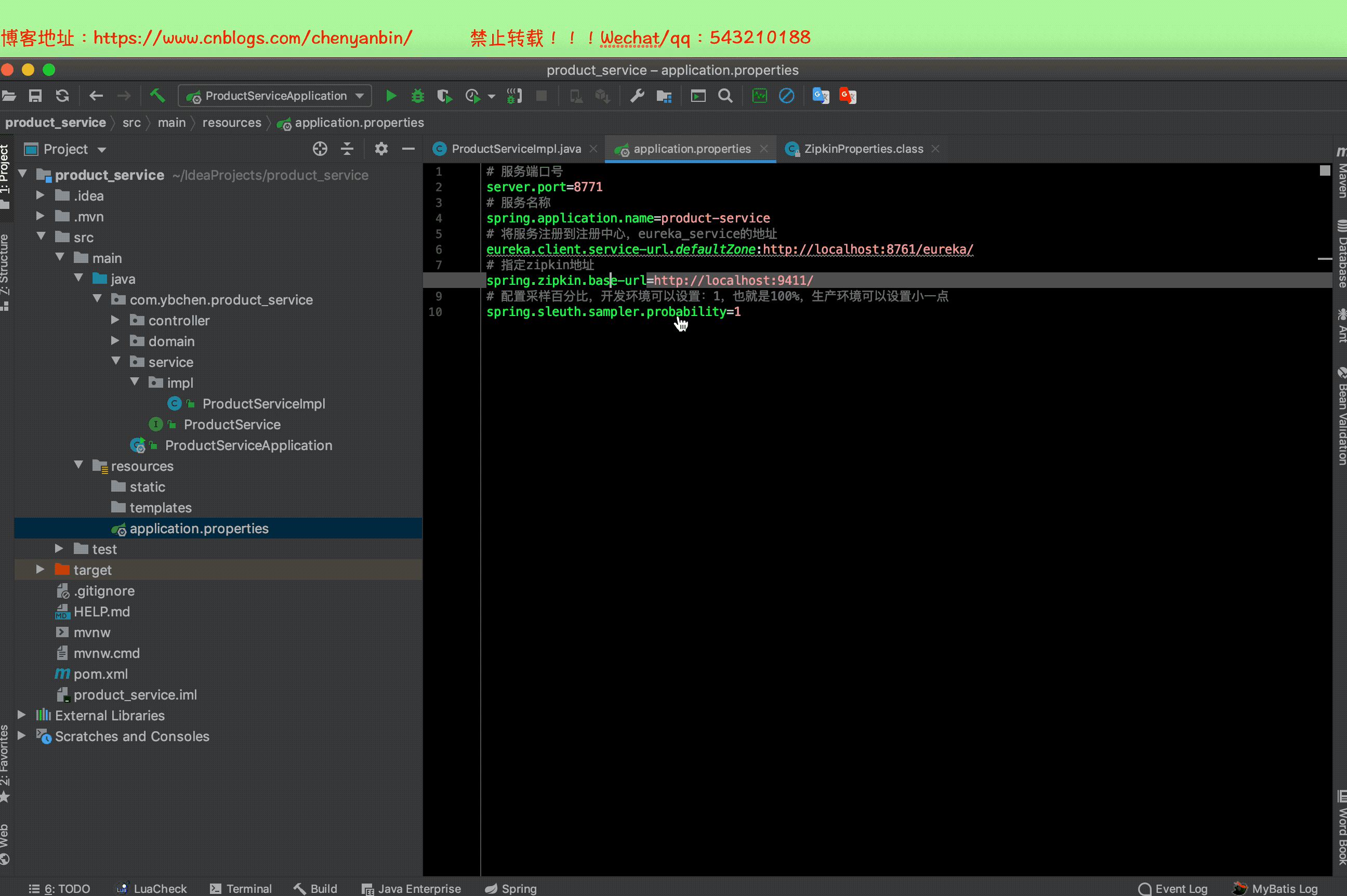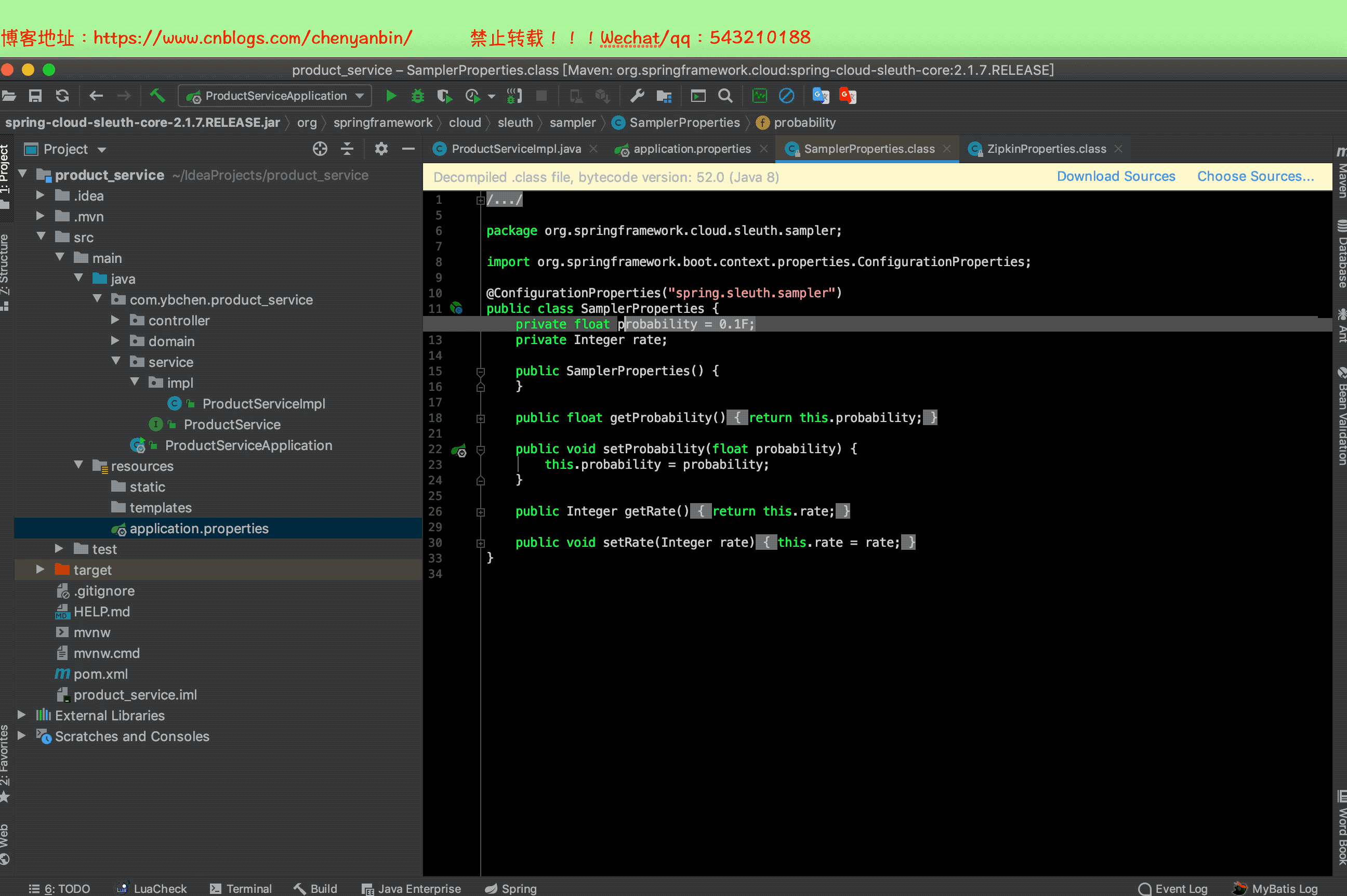
application.properties
# 指定zipkin地址
spring.zipkin.base-url=http://localhost:9411/
# 配置采样百分比,开发环境可以设置:1,也就是100%,生产环境可以设置小一点
spring.sleuth.sampler.probability=1
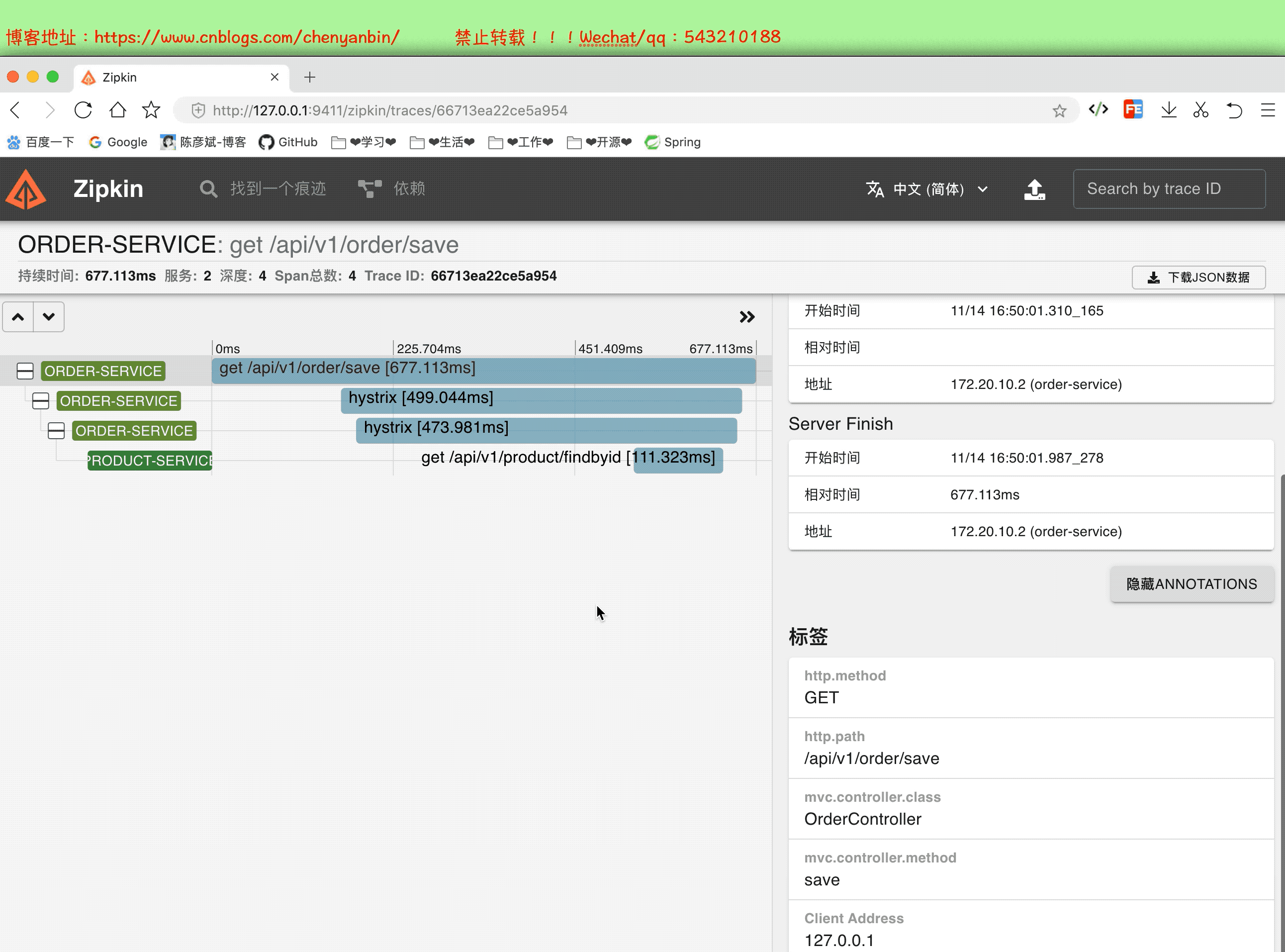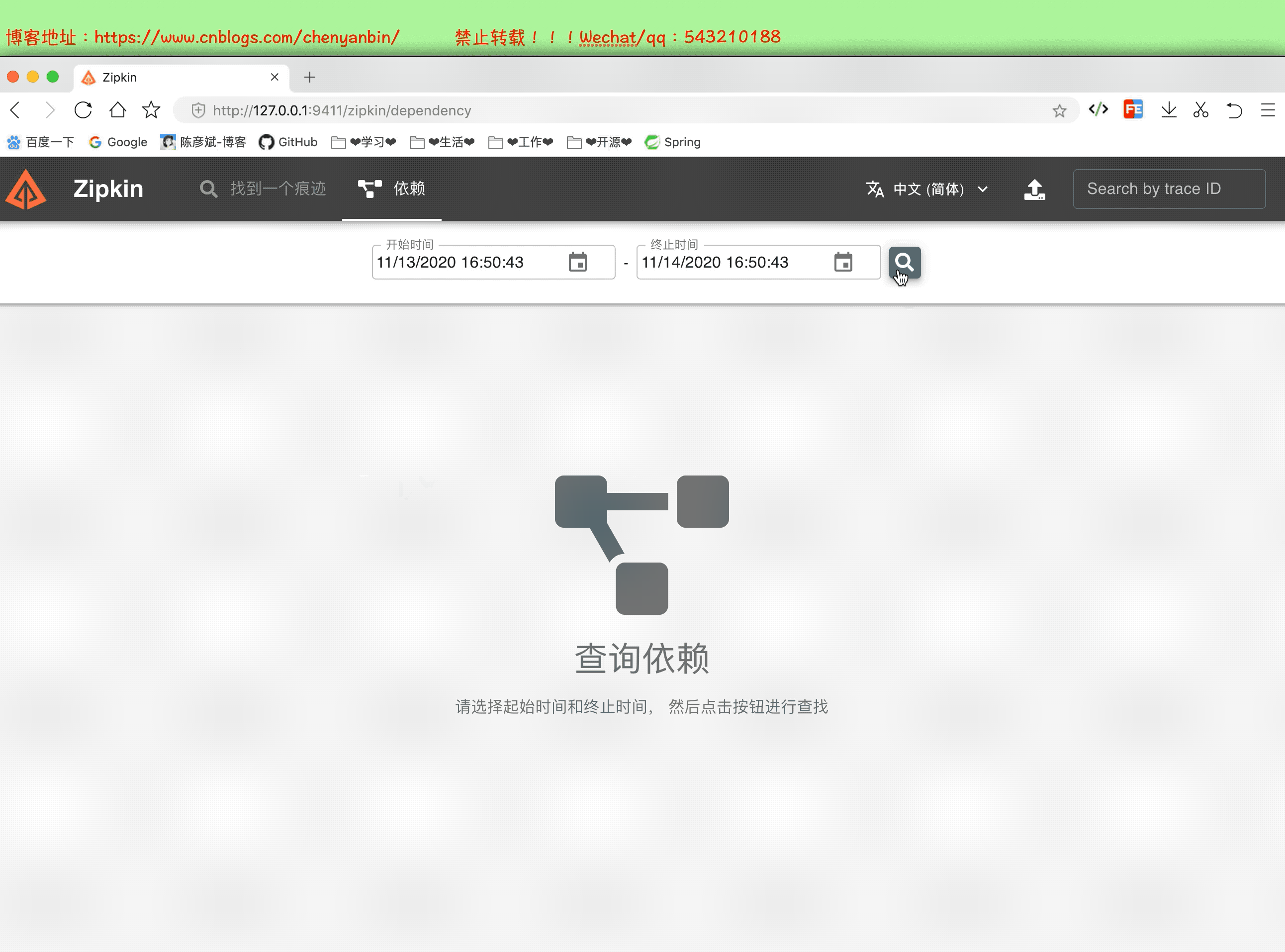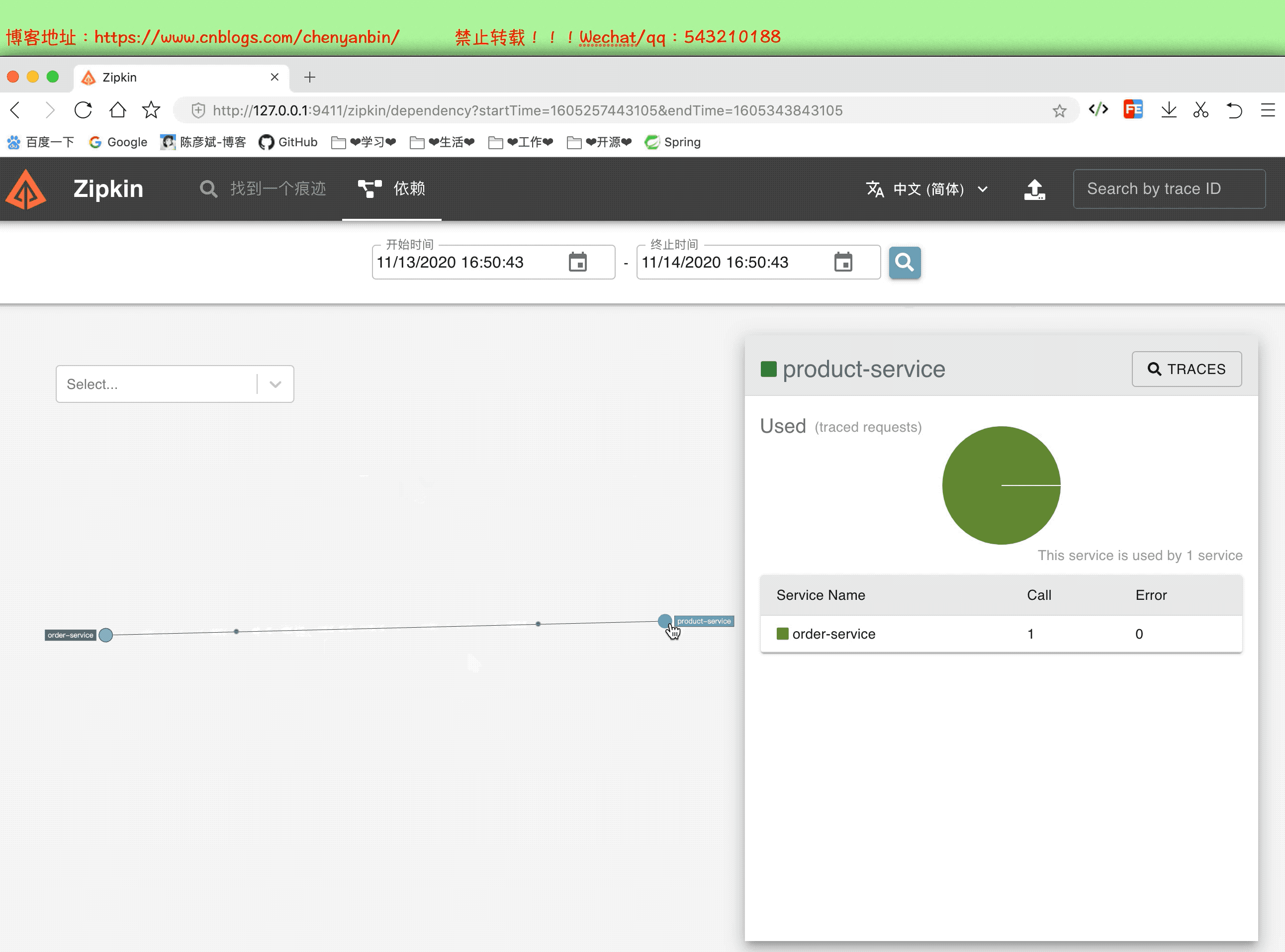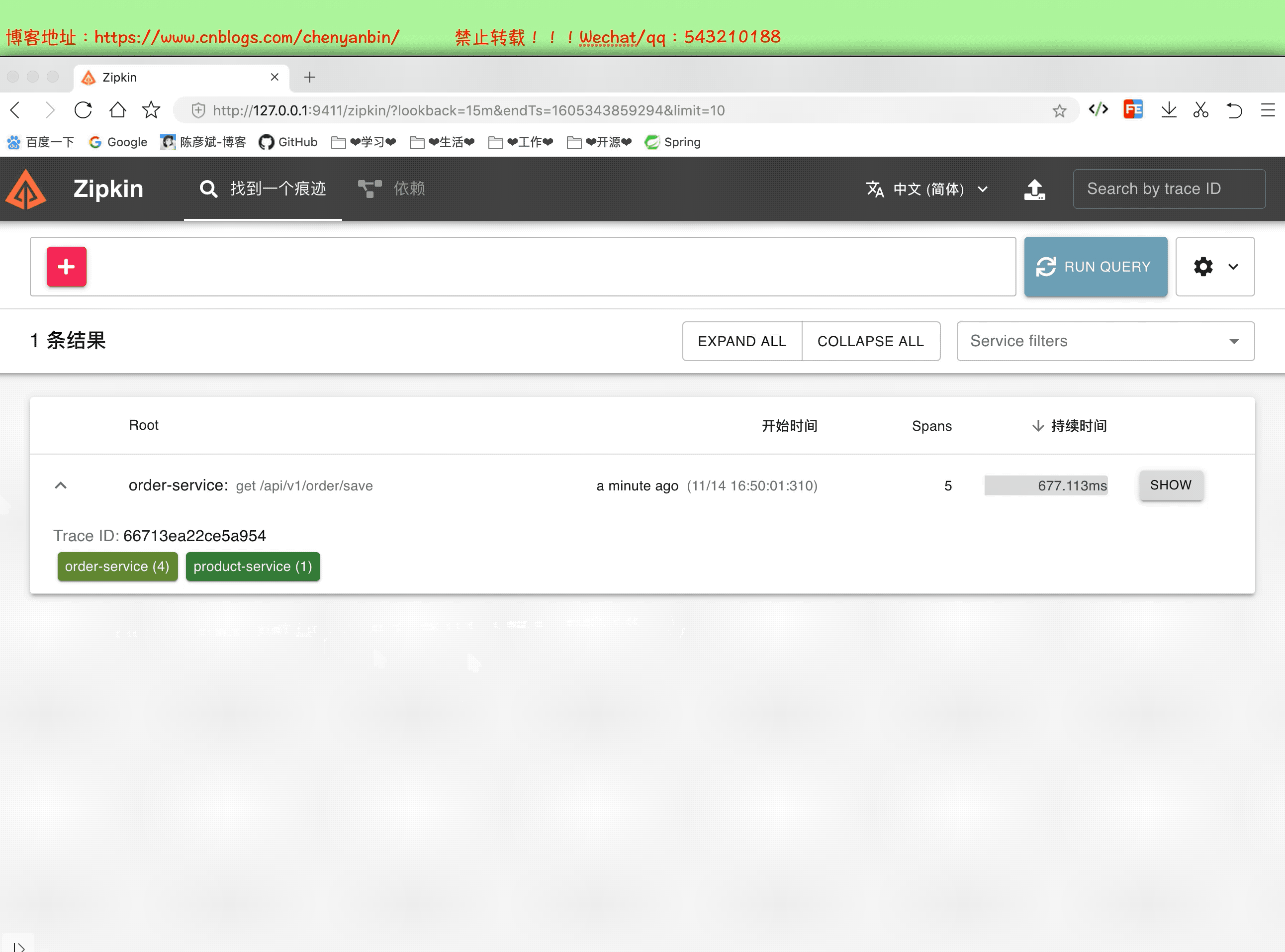
启动并分析数据
通过这个分析,我们可以知道,微服务中那个服务耗时多,可以在这个服务上做性能优化,可以考虑加:缓存、异步、算法等等~
源码下载
好了,今天先到这,只可意会不可言传,自己体会他的好处~
链接: https://pan.baidu.com/s/1c4ZWufjmDgzgAAiOOzRg9A 密码: or12

 浙公网安备 33010602011771号
浙公网安备 33010602011771号