ElasticSearch 7.8.1 从入门到精通
学前导读
- ElasticSearch对电脑配置要求较高,内存至少4G以上,空闲2G内存,线程数4018+
- 学习的时候,推荐将ElasticSearch安装到Linux或者mac上,极度不推荐装Windows上(坑太多,服务器部署的时候,也不会部署到Window上,学习用Windows上玩,不是耽误自个时间麽)。如果是Window用户想学这个,电脑自身至少16G,然后装虚拟机,在虚拟机上搞个Linux玩
- Linux系统不建议装6/6.5版本的(启动的时候,会检查内核是否3.5+,当然可以忽略这个检查),推荐装7+
- 自身电脑配置不高的话,怎么办呢?土豪做法,去买个云服务器叭,在云服务器上玩
注意事项
上面第1、2点未满足,又舍不得去买云服务器的小伙伴,就不要往下面看了,看了也白看,ElasticSearch对电脑配置要求较高,前置条件未满足的话,服务是起不来的。
演示环境说明
我演示的时候,是用的mac系统,上面装了个虚拟机,虚拟机版本Centos6.5,jdk用的13,ElasticSearch用的版本是 7.8.1。这些我使用的包我下面也会提供,为了学习的话,尽量和我使用的版本一致,这样大家碰到的问题都一样,安装过程中,我也猜了不少坑,都总结出来了,仔细阅读文档就可以捣鼓出来。
什么是搜索引擎?
常用的搜索网站:百度、谷歌
数据的分类
结构化数据
指具有固定格式或有限长度的数据,如数据库,元数据等。对于结构化数据,我们一般都是可以通过关系型数据库(mysql、oracle)的table的方法存储和搜索,也可以建立索引。通过b-tree等数据结构快速搜索数据
非结构化数据
全文数据,指不定长或无固定格式的数据,如邮件,word等。对于非结构化数据,也即对全文数据的搜索主要有两种方式:顺序扫描法,全文搜索法
顺序扫描法
我们可以了解它的大概搜索方式,就是按照顺序扫描的方式查找特定的关键字。比如让你在一篇篮球新闻中,找出“科比”这个名字在那些段落出现过。那你肯定需要从头到尾把文章阅读一遍,然后标出关键字在哪些地方出现过
这种方式毋庸置疑是最低效的,如果文章很长,有几万字,等你阅读完这篇新闻找到“科比”这个关键字,那得花多少时间
全文搜索
对非结构化数据进行顺序扫描很慢,我们是否可以进行优化?把非结构化数据想办法弄得有一定结构不就好了嘛?将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对这些有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这种方式就构成了全文搜索的基本思路。这部分从非结构化数据提取出的然后重新组织的信息,就是索引。
什么是全文搜索引擎
根据百度百科中的定义,全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每个词,对每个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户。
常见的搜索引擎
Lucene
- Lucene是一个Java全文搜索引擎,完全用Java编写。lucene不是一个完整的应用程序,而是一个代码库和API,可以很容易地用于向应用程序添加搜索功能
- 通过简单的API提供强大的功能
- 可扩展的高性能索引
- 强大,准确,高效的搜索算法
- 跨平台解决方案
- Apache软件基金会
- 在Apache软件基金会提供的开源软件项目的Apache社区的支持
- 但是Lucene只是一个框架,要充分利用它的功能,需要使用Java,并且在程序中集成Lucene。需要很多的学习了解,才能明白它是如何运行的,熟练运用Lucene确实非常复杂
Solr
- Solr是一个基于Lucene的Java库构建的开源搜索平台。它以友好的方式提供Apache Lucene的搜索功能。它是一个成熟的产品,拥有强大而广泛的用户社区。它能提供分布式索引,复制,负载均衡以及自动故障转移和恢复。如果它被正确部署然后管理的好,他就能够成为一个高可用,可扩展且容错的搜索引擎
- 强大功能
- 全文搜索
- 突出
- 分面搜索
- 实时索引
- 动态集群
- 数据库集成
- NoSQL功能和丰富的文档处理
ElasticSearch
- ElasticSearch是一个开源,是一个机遇Apache Lucene库构建的Restful搜索引擎
- ElasticSearch是Solr之后几年推出的。它提供了一个分布式,多租户能力的全文搜索引擎,具有HTTP Web页面和无架构JSON文档。ElasticSearch的官方客户端提供Java、Php、Ruby、Perl、Python、.Net和JavaScript
- 主要功能
- 分布式搜索
- 数据分析
- 分组和聚合
- 应用场景
- 维基百科
- Stack Overflow
- GitHub
- 电商网站
- 日志数据分析
- 商品价格监控网站
- BI系统
- 站内搜索
- 篮球论坛
搜索引擎的快速搭建
环境准备
注意,我使用的linux搭建的,当然Window(极度不推荐,坑太多)也能搭建,ElasticSearch安装前需要先安装jdk,这里我使用的是jdk13,因为linux自带jdk版本,需要先将之前的jdk版本卸载(点我直达),在安装指定的jdk版本!!!
开发环境,建议关闭防火墙,避免不必要的麻烦!!!!生产环境,视情况开启端口号!!!!
service iptables stop 命令关闭防火墙,但是系统重启后会开启
chkconfig iptables off--关闭防火墙开机自启动
「注意事项」
ElasticSearch是强依赖jdk环境的,所以一定要安装对应的jdk版本,并配置好相关的环境变量,比如ES7.X版本要装jdk8以上的版本,而且是要官方来源的jdk。启动的时候有可能会提示要装jdk11,因为ES7以上官方都是建议使用jdk11,但是一般只是提示信息,不影响启动。
ES官网推荐JDK版本兼容地址:点我直达

ES强依赖JVM,也很吃内存,所以一定要保证你的机器至少空闲出2G以上内存。推荐使用Linux,可以本地搭建虚拟机。
启动一定要使用非root账户!!!!这是ES强制规定的。ElasticSearch为了安全考虑,不让使用root启动,解决办法是新建一个用户,用此用户进行相关的操作。如果你用root启动,会报错。如果是使用root账户安装ES,首先给安装包授权,比如chown -R 777 安装包路径。然后再使用非root账户启动,具体的权限配置,根据自己想要的配置。
补充
高版本的ElasticSearch自带jdk版本的,Linux中我安装的是jdk13,没用ElasticSearch自带的jdk,有兴趣的小伙伴可以去研究下。
下载
官网地址:点我直达
我使用的包(推荐和我版本保持一致)
链接: https://pan.baidu.com/s/1jjNEErHtBu93HmvxKCT5Sw 密码: kbcs

修改配置文件
1、修改elasticsearch-x.x.x/config/elasticsearch.yml,主要修改成以下内容
cluster.name: my-application
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
cluster.initial_master_nodes: ["node-1"]
bootstrap.system_call_filter: false
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
2、来到elasticsearch-x.x.x/bin下,执行:sh elasticsearch启动,报错,修改配置文件elasticsearch-env

3、设置用户和组
groupadd elsearch
#添加用户组,语法:groupadd 组名
useradd elsearch -g elsearch -p elasticsearch
#添加用户,并将用户添加到组中,语法:useradd 用户名 -p 密码 -g 组名
chown -R elsearch:elsearch elasticsearch-6.3.0
# 给用户组授权,语法:chown -R 用户:组名 es安装完整路径

注意=================以上root用户操作===============
注意=================以下es用户操作================
注意:若es用户密码登录不上,在回到root用户下,修改es用户的密码,语法:passwd 要修改用户名
4、登录到es用户下,继续启动ElasticSearch,执行:sh elasticsearch
报错如下:
java.lang.UnsupportedOperationException: seccomp unavailable: requires kernel 3.5+ with CONFIG_SECCOMP and CONFIG_SECCOMP_FILTER compiled in
原因:我用的Centos6.5,其linux内核版本为2.6。而Elasticsearch的插件要求至少3.5以上版本。
解决方案:禁用这个插件即可
修改elasticsearch.yml文件,在最下面添加如下配置:
bootstrap.system_call_filter: false
5.继续启动ElasticSearch,执行:sh elasticsearch
修改一下内容需要使用root权限
报错如下4条:
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max number of threads [1024] for user [es] is too low, increase to at least [4096]
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
==========分割线===============
解决办法如下
1、vim /etc/security/limits.conf文件,添加
* soft nofile 65535
* hard nofile 65535
2、vim /etc/security/limits.conf文件,添加
* soft nproc 4096
* hard nproc 4096
3、vim /etc/sysctl.conf 文件,添加
vm.max_map_count=262144
4、vim /var/soft/es7.8.1/elasticsearch-7.8.1/config/elasticsearch.yml 文件,添加
cluster.initial_master_nodes: ["node-1"]
修改完之后,一定要重启,重启,重启,重要的事儿说三遍!!!!!
上面第2条问题,线程数修改不了,可以尝试使用这个方法修改线程数
Elasticsearch7.8.1 [1]: max number of threads [1024] for user [es] is too low, increase to at least [4096]异常
根据linux系统差异,有时候需要来点终极解决方案
新建: /etc/security/limits.d/test-limits.conf
cat>>test-limits.conf
然后加下内容:
* soft nofile 65535
* hard nofile 65535
* soft nproc 4096
* hard nproc 4096
ctrl+d保存即可;
然后重启服务器即可;

配置小结
1、第一次配置过程中,踩了不少坑,我踩过的坑,都在上面记录了
2、如果照我上面哪个方法还解决不了,自行根据ElasticSearch日志,百度去找答案叭····
启动
正常启动
进入软件的安装目录,进入到bin
执行:sh elasticsearch
守护进行启动
进入软件的安装目录,进入到bin
执行:sh elasticsearch -d -p pid
验证
打开浏览器输入:127.0.0.1:9200

ElasticSearch目录结构介绍

| 类型 | 描述 | 默认位置 | 设置 |
|
bin
|
⼆进制脚本包含启动节点的elasticsearch
|
{path.home}/bin
|
|
|
conf
|
配置⽂件包含elasticsearch.yml
|
{path.home}/confifig
|
path.conf
|
|
data
|
在节点上申请的每个index/shard的数据⽂件的位置。
可容纳多个位置
|
{path.home}/data
|
path.data
|
|
logs
|
⽇志⽂件位置
|
{path.home}/logs
|
path.logs
|
|
plugins
|
插件⽂件位置。每个插件将包含在⼀个⼦⽬录中。
|
{path.home}/plugins
|
path.plugins
|
ElasticSearch快速入门
核心概念
前言
传统数据库查询数据的操作步骤是这样的:建立数据库->建表->插入数据->查询
索引(index)
一个索引可以理解成一个关系型数据库
类型(type)
一个type就像一类表,比如user表、order表
注意
1、ES 5.X中一个index可以有多种type
2、ES 6.X中一个index只能有一种type
3、ES 7.X以后已经移除type这个概念
映射(mapping)
mapping定义了每个字段的类型等信息。相当于关系型数据库中的表结构
文档(document)
一个document相当于关系型数据库中的一行记录
字段(field)
相当于关系型数据库表的字段
集群(cluster)
集群由一个或多个节点组成,一个集群由一个默认名称“elasticsearch”
节点(node)
集群的节点,一台机器或者一个进程
分片和副本(shard)
- 副本是分片的副本。分片有主分片(primary Shard)和副本分片(replica Shard)之分
- 一个Index数据在屋里上被分布在多个主分片中,每个主分片只存放部分数据
- 每个主分片可以有多个副本,叫副本分片,是主分片的复制
RESTful风格的介绍
介绍
- RESTful是一种架构的规范与约束、原则,符合这种规范的架构就是RESTful架构
- 先看REST是什么意思,英文Representational state transfer表述性状态转移,其实就是对资源的标书性状态转移,即通过HTTP动词来实现资源的状态扭转
- 资源是REST系统的核心概念。所有的设计都是以资源为中心
- elasticsearch使用RESTful风格api来设计的
方法
| action | 描述 |
| HEAD | 只获取某个资源的头部信息 |
| GET | 获取资源 |
| POST | 创建或更新资源 |
| PUT | 创建或更新资源 |
| DELETE | 删除资源 |
GET /user:列出所有的⽤户
POST /user:新建⼀个⽤户
PUT /user:更新某个指定⽤户的信息
DELETE /user/ID:删除指定⽤户
调试工具
Postman工具(推荐)

curl工具
获取elasticcsearch状态
curl -X GET "http://localhost:9200"
新建一个文档
curl -X PUT "localhost:9200/xdclass/_doc/1" -H 'Content-Type:
application/json' -d' {
"user" : "louis",
"message" : "louis is good"
}
删除一个文档
curl -X DELETE "localhost:9200/xdclass/_doc/1"
索引的使用
新增

单个获取

批量获取

删除

获取所有
方式一

方式二


判断索引是否存在(存在,返回200,不存在404)


关闭索引

此时再次查询nba时,返回json会多一行

打开索引

关闭索引标记消失

映射的使用
介绍
定义索引的结构,之前定义一个nba索引,但是没有定义他的结构,我们现在开始建立mapping;
type="keyword":是一个关键字,不会被分词
type="text":会被分词,使用的是全文索引
新增

json格式
{
"properties": {
"name": {
"type": "text"
},
"team_name": {
"type": "text"
},
"position": {
"type": "keyword"
},
"play_year": {
"type": "keyword"
},
"jerse_no": {
"type": "keyword"
}
}
}
获取

批量获取

获取所有mapping
方式一

方式二

添加一个字段


文档的操作
新增

不指定索引方式新增
踩坑(要POST请求)

PUT请求改POST

自动创建索引
- 查看auto_create_index开关状态,请求:http://ip:port/_cluster/settings

- 当索引不存在并且auto_create_index为true的时候,新增文档时会自动创建索引
- 修改auto_create_index状态
- put方式:ip:port/_cluster/settings

{
"persistent": {
"action.auto_create_index": "false"
}
}
当auto_create_index=false时,指定一个不存在的索引,新增文档

{
"name":"杨超越",
"team_name":"梦之队",
"position":"组织后卫",
"play_year":"0",
"jerse_no":"18"
}
指定操作类型
PUT请求:ip:port/xxx/_doc/1?op_type=create

文档查看

查看多个文档
方式一

{
"docs": [{
"_index": "nba",
"_type": "_doc",
"_id": "1"
},
{
"_index": "nba",
"_type": "_doc",
"_id": "2"
}
]
}
方式二

方式三

方式四

修改

向_source字段,增加一个字段

{
"script": "ctx._source.age = 18"
}
从source字段,删除一个字段

{
"script": "ctx._source.remove(\"age\")"
}
根据参数值,更新指定文档的字段

upsert当指定的文档不存在时,upsert参数包含的内容将会被插入到索引中,作为一个新文档;如果指定的文档存在,ElasticSearch引擎将会执行指定的更新逻辑。
删除文档

搜索的简单使用
准备工作
删除nba索引

新建一个索引
并指定mapping

{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"team_name": {
"type": "text"
},
"position": {
"type": "text"
},
"play_year": {
"type": "long"
},
"jerse_no": {
"type": "keyword"
}
}
}
}
新增document

192.168.199.170:9200/nba/_doc/1
{
"name": "哈登",
"team_name": "⽕箭",
"position": "得分后卫",
"play_year": 10,
"jerse_no": "13"
}
192.168.199.170:9200/nba/_doc/2
{
"name": "库⾥",
"team_name": "勇⼠",
"position": "控球后卫",
"play_year": 10,
"jerse_no": "30"
}
192.168.199.170:9200/nba/_doc/3
{
"name": "詹姆斯",
"team_name": "湖⼈",
"position": "⼩前锋",
"play_year": 15,
"jerse_no": "23"
}
词条查询(term)
词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时,才匹配搜索。
单条term查询

{
"query": {
"term": {
"jerse_no": "23"
}
}
}
多条term查询

{
"query": {
"terms": {
"jerse_no": [
"23",
"13"
]
}
}
}
全文查询(full text)
ElasticSearch引擎会先分析查询字符串,将其拆分成多个分词,只要已分析的字段中包含词条的任意一个,或全部包含,就匹配查询条件,返回该文档;如果不包含任意一个分词,表示没有任何问的那个匹配查询条件
match_all

{
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
match

{
"query": {
"match": {
"position":"后卫"
}
},
"from": 0,
"size": 10
}
multi_match

{
"query": {
"multi_match": {
"query": "shooter",
"fields": ["title", "name"]
}
}
}
post 192.168.199.170:9200/nba/_update/2
{
"doc": {
"name": "库⾥",
"team_name": "勇⼠",
"position": "控球后卫",
"play_year": 10,
"jerse_no": "30",
"title": "the best shooter"
}
}
match_phrase
类似于词条查询,精准查询

match_phrase_prefix
前缀匹配

{
"query": {
"match_phrase_prefix": {
"title": "the best s"
}
}
}
post 192.168.199.170:9200/nba/_update/3
{
"doc": {
"name": "詹姆斯",
"team_name": "湖⼈",
"position": "⼩前锋",
"play_year": 15,
"jerse_no": "23",
"title": "the best small forward"
}
}
分词器的介绍和使用
什么是分词器
- 将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具
- example:The best 3-points shooter is Curry!
常用的内置分词器
- standard analyzer
- simple analyzer
- whitespace analyzer
- stop analyzer
- language analyzer
- pattern analyzer
standard analyzer
标准分析器是默认分词器,如果未指定,则使用该分词器

{
"analyzer": "standard",
"text": "The best 3-points shooter is Curry!"
}
simple analyzer
simple分析器当他遇到只要不是字母的字符,就将文本解析成term,而且所有的term都是小写的

whitespace analyzer
whitespace分析器,当他遇到空白字符时,就将文本解析成terms

stop analyzer
stop分析器和simple分析器很想,唯一不同的是,stop分析器增加了对删除停止词的支持,默认使用了english停止词
stopwords预定义的停止词列表,比如(ths,a,an,this,of,at)等等

language analyzer

pattern analyzer
用正则表达式将文本分割成sterms,默认的正则表达式是\W+

选择分词器

put 192.168.199.170:9200/my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "whitespace"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"team_name": {
"type": "text"
},
"position": {
"type": "text"
},
"play_year": {
"type": "long"
},
"jerse_no": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}

{
"name": "库⾥",
"team_name": "勇⼠",
"position": "控球后卫",
"play_year": 10,
"jerse_no": "30",
"title": "The best 3-points shooter is Curry!"
}

{
"query": {
"match": {
"title": "Curry!"
}
}
}
常见中文分词器
默认的分词standard

{
"analyzer": "standard",
"text": "⽕箭明年总冠军"
}
常见分词器
- smartCN一个简单的中文或中英文混合文本的分词器
- IK分词器,更智能更友好的中文分词器
安装smartCN
- sh elasticsearch-plugin install analysis-smartcn

校验
安装后重启

{
"analyzer": "smartcn",
"text": "⽕箭明年总冠军"
}
卸载
sh elasticsearch-plugin remove analysis-smartcn
IK分词器
下载地址:点我直达

安装,解压到plugins目录

然后重启

ip:9200/_analyze
{
"analyzer": "ik_max_word",
"text": "⽕箭明年总冠军"
}
常见的字段类型
数据类型
- 核心数据类型
- 复杂数据类型
- 专用数据类型
核心数据类型
字符串
- text:用于全文索引,该类型的字段将通过分词器进行分词
- keyword:不分词,只能搜索该字段的完整的值
数值型
- long、integer、short、byte、double、float、half_float、scaled_float
布尔
- boolean
二进制
- binary:该类型的字段把值当做经过base64编码的字符串,默认不存储,且不可搜索
范围类型
- 范围类型表示值是一个范围,而不是一个具体的值
- integer_range、float_range、long_range、double_range、date_range
- 比如age类型是integer_range,那么值可以是{"gte":20,"lte":40};搜索"term":{"age":21}可以搜索该值
日期-date
由于json类型没有date类型,所以es通过识别字符串是否符合format定义的格式来判断是否为date类型
format默认为:strict_date_optional_time || epoch_millis
格式
从开始纪元(1970年1月1日0点)开始的毫秒数
PUT 192.168.199.170:9200/nba/_mapping
{
"properties": {
"name": {
"type": "text"
},
"team_name": {
"type": "text"
},
"position": {
"type": "text"
},
"play_year": {
"type": "long"
},
"jerse_no": {
"type": "keyword"
},
"title": {
"type": "text"
},
"date": {
"type": "date"
}
}
}
POST 192.168.199.170:9200/nba/_doc/4
{
"name": "蔡x坤",
"team_name": "勇⼠",
"position": "得分后卫",
"play_year": 10,
"jerse_no": "31",
"title": "打球最帅的明星",
"date": "2020-01-01"
}
POST 192.168.199.170:9200/nba/_doc/5
{
"name": "杨超越",
"team_name": "猴急",
"position": "得分后卫",
"play_year": 10,
"jerse_no": "32",
"title": "打球最可爱的明星",
"date": 1610350870
}
POST 192.168.199.170:9200/nba/_doc/6
{
"name": "吴亦凡",
"team_name": "湖⼈",
"position": "得分后卫",
"play_year": 10,
"jerse_no": "33",
"title": "最会说唱的明星",
"date": 1641886870000
}
复杂数据类型
数据类型 Array
- ES中没有专门的数据类型,直接使用[]定义接口,数组中所有的值必须是同一种数据类型,不支持混合数据类型的数组
- 字符串数组["one","two"]
- 整数数组[1,2]
- Object对象数组[{"name":"alex","age":18},{"name":"tom","age":18}]
对象类型Object
POST 192.168.199.170:9200/nba/_doc/8
{
"name": "吴亦凡",
"team_name": "湖⼈",
"position": "得分后卫",
"play_year": 10,
"jerse_no": "33",
"title": "最会说唱的明星",
"date": "1641886870",
"array": [
"one",
"two"
],
"address": {
"region": "China",
"location": {
"province": "GuangDong",
"city": "GuangZhou"
}
}
}
索引方式
"address.region": "China",
"address.location.province": "GuangDong",
"address.location.city": "GuangZhou"
POST 192.168.199.170:9200/nba/_search
{
"query": {
"match": {
"address.region": "china"
}
}
}
专用数据类型
IP类型
IP类型的字段用于存储IPv4和IPv6的地址,本质上是一个长整形字段
POST 192.168.199.170:9200/nba/_mapping
{
"properties": {
"name": {
"type": "text"
},
"team_name": {
"type": "text"
},
"position": {
"type": "text"
},
"play_year": {
"type": "long"
},
"jerse_no": {
"type": "keyword"
},
"title": {
"type": "text"
},
"date": {
"type": "date"
},
"ip_addr": {
"type": "ip"
}
}
}
PUT 192.168.199.170:9200/nba/_doc/9
{
"name": "吴亦凡",
"team_name": "湖⼈",
"position": "得分后卫",
"play_year": 10,
"jerse_no": "33",
"title": "最会说唱的明星",
"ip_addr": "192.168.1.1"
}
POST 192.168.199.170:9200/nba/_search
{
"query": {
"term": {
"ip_addr": "192.168.0.0/16"
}
}
}
kibana工具的安装和使用
简介
可视化工具kibana的安装和使用
下载

赋权限
chown -R es:es781g /var/soft/kibana-7.8.1-linux-x86_64
# 给用户组授权,语法:chown -R 用户:组名 es安装完整路径

kibana.yml
server.port: 5601 #kibana端口
server.host: "10.0.0.169" #绑定的主机IP地址
elasticsearch.hosts: ["http://10.0.0.169:9200"] #elasticsearch的主机IP
kibana.index: ".kibana" #开启此选项
i18n.locale: "zh-CN" #kibana默认文字是英文,变更成中文
启动
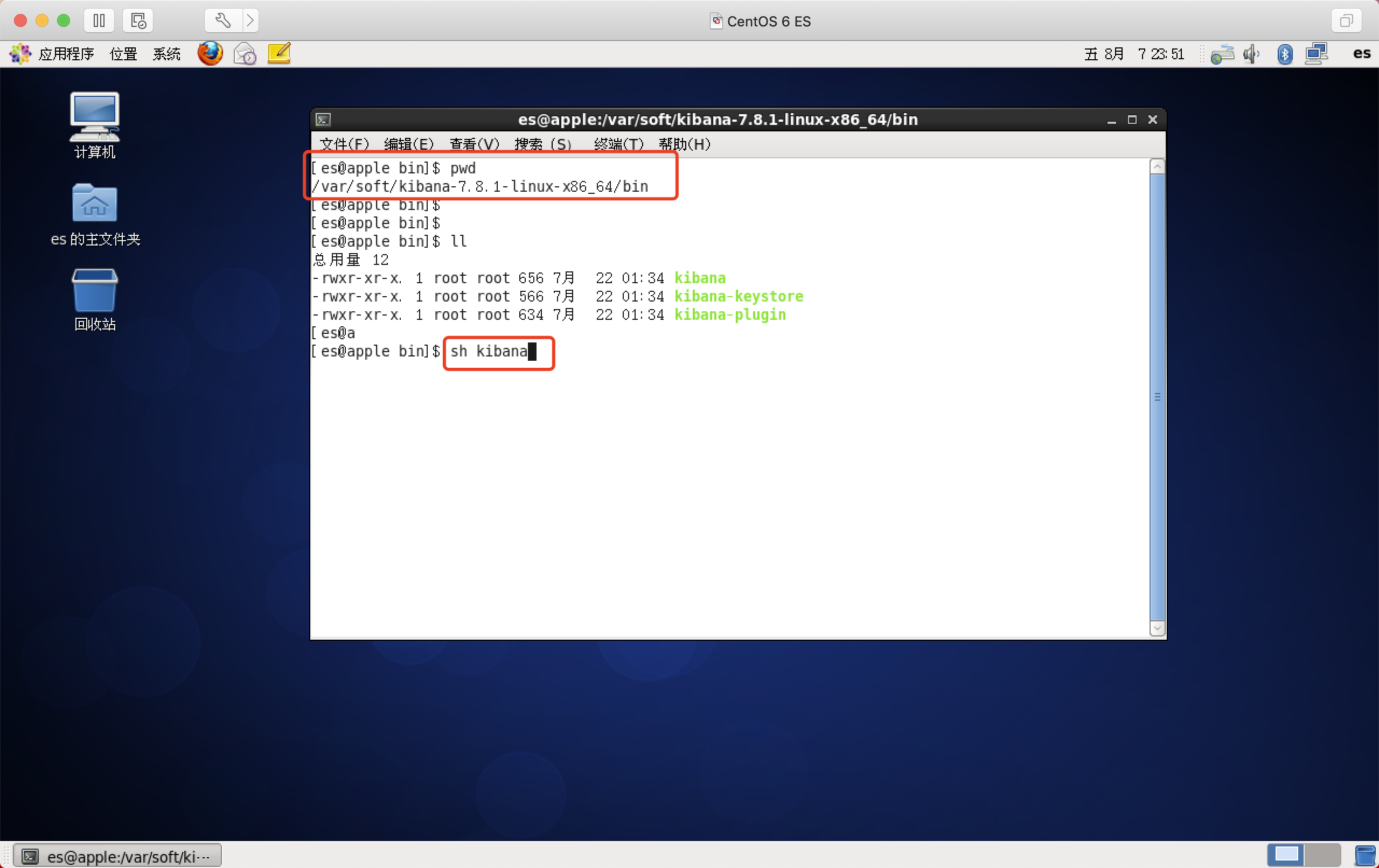
访问
ip:5601

简单使用
后面示例,会大量使用该工具

ES之批量导入数据
简介
手把手教你批量导入数据
Bulk
ES提供了一个叫bulk的API来进行批量操作
批量导入
数据
{"index": {"_index": "book", "_type": "_doc", "_id": 1}}
{"name": "权⼒的游戏"} {"index": {"_index": "book", "_type": "_doc", "_id": 2}}
{"name": "疯狂的⽯头"}

POST bulk
curl -X POST "192.168.199.170:9200/_bulk" -H 'Content-Type: application/json' --data-binary @test


ES之term的多种查询
介绍
- 单词级别查询
- 这些查询通常用于结构化的数据,比如:number,data,keyword等,而不是对text
- 也就是说,全文查询之前要先对文本内容进行分词,而单词级别的查询直接在相应字段的反向索引中精确查找,单词级别的查询一般用于数值、日期等类型的字段上
准备工作
- 删除nba
- 新增nba索引
{"mappings":{"properties":{"birthDay":{"type":"date"},"birthDayStr": {"type":"keyword"},"age":{"type":"integer"},"code": {"type":"text"},"country":{"type":"text"},"countryEn": {"type":"text"},"displayAffiliation":{"type":"text"},"displayName": {"type":"text"},"displayNameEn":{"type":"text"},"draft": {"type":"long"},"heightValue":{"type":"float"},"jerseyNo": {"type":"text"},"playYear":{"type":"long"},"playerId": {"type":"keyword"},"position":{"type":"text"},"schoolType": {"type":"text"},"teamCity":{"type":"text"},"teamCityEn": {"type":"text"},"teamConference": {"type":"keyword"},"teamConferenceEn":{"type":"keyword"},"teamName": {"type":"keyword"},"teamNameEn":{"type":"keyword"},"weight": {"type":"text"}}}}

- 批量导入player
Term query精准匹配查询
POST nba/_search
{
"query": {
"term": {
"jerseyNo": "23"
}
},
"from": 0,
"size": 20
}

Exsit Query在特定的字段中查找非空值的文档(查找队名非空的球员)

Prefix Query查找包含带有指定前缀term的文档(查找队名为Rock开头的球员)

Wildcard Query支持通配符查询,*表示任意字符,?表示任意单个字符(查找火箭队的球员)

Regexp Query正则表达式查询(查找火箭队的球员)

Ids Query(查找id为1和2的球员)

ES的范围查询
查询指定字段在指定范围内包含值(日期、数字或字符串)的文档
查找在nba打球在2年到10年以内的球员

POST nba/_search
{
"query": {
"range": {
"playYear": {
"gte": 2,
"lte": 10
}
}
},
"from": 0,
"size": 20
}
查找1999年到2020年出生的球员

POST nba/_search
{
"query": {
"range": {
"birthDay": {
"gte": "01/01/1999",
"lte": "2020",
"format": "dd/MM/yyyy||yyyy"
}
}
},
"from": 0,
"size": 20
}
ES的布尔查询
布尔查询
| type | description |
| must | 必须出现在匹配文档中 |
| filter | 必须出现在文档中,但是不打分 |
| must_not | 不能出现在文档中 |
| should | 应该出现在文档中 |
must(查询名字叫做james的球员)

POST nba/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"displayNameEn": "james"
}
}
]
}
},
"from": 0,
"size": 20
}
效果通must,但是不打分(查找名字叫做james的球员)

POST nba/_search
{
"query": {
"bool": {
"filter": [
{
"match": {
"displayNameEn": "james"
}
}
]
}
},
"from": 0,
"size": 20
}
must_not(查找名字叫做James的西部球员)

POST nba/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"displayNameEn": "james"
}
}
],
"must_not": [
{
"term": {
"teamConferenceEn": {
"value": "Eastern"
}
}
}
]
}
},
"from": 0,
"size": 20
}
组合起来含义:一定不在东部的james
should(查找名字叫做James的打球时间应该在11到20年西部球员)
即使匹配不到也返回,只是评分不同

POST nba/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"displayNameEn": "james"
}
}
],
"must_not": [
{
"term": {
"teamConferenceEn": {
"value": "Eastern"
}
}
}
],
"should": [
{
"range": {
"playYear": {
"gte": 11,
"lte": 20
}
}
}
]
}
},
"from": 0,
"size": 20
}
如果minimum_should_match=1,则变成要查出名字叫做James的打球时间在11年到20年西部球员

POST nba/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"displayNameEn": "james"
}
}
],
"must_not": [
{
"term": {
"teamConferenceEn": {
"value": "Eastern"
}
}
}
],
"should": [
{
"range": {
"playYear": {
"gte": 11,
"lte": 20
}
}
}
],
"minimum_should_match": 1
}
},
"from": 0,
"size": 20
}
minimum_should_match代表了最小匹配经度,如果设置minimum_should_match=1,那么should语句中至少需要有一个条件满足
ES的排序
火箭队中按打球时间从大到小排序的球员

POST nba/_search
{
"query": {
"match": {
"teamNameEn": "Rockets"
}
},
"sort": [
{
"playYear": {
"order": "desc"
}
}
],
"from": 0,
"size": 20
}
火箭队中按打球时间从大到小,如果年龄相同则按照身高从高到低排序的球员

POST nba/_search
{
"query": {
"match": {
"teamNameEn": "Rockets"
}
},
"sort": [
{
"playYear": {
"order": "desc"
}
},{
"heightValue": {
"order": "asc"
}
}
],
"from": 0,
"size": 20
}
ES聚合查询之指标聚合
ES聚合查询是什么
- 聚合查询是数据库中重要的功能特性,完成对一个查询得到的数据集的聚合计算,如:找出某字段(或计算表达式的结果)的最大值,最小值,计算和,平均值等。ES作为搜索引擎,同样提供了强大的聚合分析能力
- 对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合
- 而关系型数据库中除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行指标聚合。在ES中称为“桶聚合”
max min sum avg
求出火箭队球员的平均年龄

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"avgAge": {
"avg": {
"field": "age"
}
}
},
"size": 0
}
value_count统计非空字段的文档数
求出火箭队中球员打球时间不为空的数量

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"countPlayerYear": {
"value_count": {
"field": "playYear"
}
}
},
"size": 0
}
查出火箭队有多少名球员

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
}
}
Cardinality值去重计数
查出火箭队中年龄不同的数量

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"countAget": {
"cardinality": {
"field": "age"
}
}
},
"size": 0
}
stats统计count max min avg sum5个值
查出火箭队球员的年龄stats

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"statsAge": {
"stats": {
"field": "age"
}
}
},
"size": 0
}
Extended stats比stats多4个统计结果:平方和、方差、标准差、平均值加/减两个标准差的区间
查询火箭队球员的年龄Extend stats

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"extendStatsAge": {
"extended_stats": {
"field": "age"
}
}
},
"size": 0
}
Percentiles占比百分位对应的值统计,默认返回【1,5,25,50,75,95,99】分位上的值
查出火箭的球员的年龄占比

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"pecentAge": {
"percentiles": {
"field": "age"
}
}
},
"size": 0
}
查出火箭的球员的年龄占比(指定分位值)

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"pecentAge": {
"percentiles": {
"field": "age",
"percents": [
20,
50,
75
]
}
}
},
"size": 0
}
ES聚合查询之桶聚合
ES聚合分析是什么
- 聚合分析是数据库中重要的功能特性,完成对一个查询的数据集中数据的聚合计算,如:找出字段(或计算表达式的结果)的最大值、最小值、计算和、平均值等。ES作为搜索引擎兼容数据库,同样提供了强大的聚合分析能力
- 对一个数据集求最大、最小、和、平均值等指标的聚合,在ES中称为指标聚合
- 而关系型数据库中除了有聚合函数外,还可以对查询出的数据进行分组group by,再在组上进行游标聚合。在ES中称为桶聚合
Terms Aggregation根据字段项分组聚合
火箭队根据年龄进行分组

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"aggsAge": {
"terms": {
"field": "age",
"size": 10
}
}
},
"size": 0
}
Order分组聚合排序
火箭队根据年龄进行分组,分组信息通过年龄从大到小排序(通过指定字段)

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"aggsAge": {
"terms": {
"field": "age",
"size": 10,
"order": {
"_key": "desc"
}
}
}
},
"size": 0
}
火箭队根据年龄进行分组,分组信息通过文档数从大到小排序(通过文档数)

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"aggsAge": {
"terms": {
"field": "age",
"size": 10,
"order": {
"_count": "desc"
}
}
}
},
"size": 0
}
每支球队按该队所有球员的平均年龄进行分组排序(通过分组指标值)

POST /nba/_search
{
"query": {
"term": {
"teamNameEn": {
"value": "Rockets"
}
}
},
"aggs": {
"avgAge": {
"avg": {
"field": "age"
}
}
},
"size": 0
}
筛选分组聚合
湖人和火箭队按球队平均年龄进行分组排序(指定值列表)

POST /nba/_search
{
"aggs": {
"aggsTeamName": {
"terms": {
"field": "teamNameEn",
"include": [
"Lakers",
"Rockets",
"Warriors"
],
"exclude": [
"Warriors"
],
"size": 30,
"order": {
"avgAge": "desc"
}
},
"aggs": {
"avgAge": {
"avg": {
"field": "age"
}
}
}
}
},
"size": 0
}
湖人和火箭队按球队平均年龄进行分组排序(正则表达式匹配值)

POST /nba/_search
{
"aggs": {
"aggsTeamName": {
"terms": {
"field": "teamNameEn",
"include": "Lakers|Ro.*|Warriors.*",
"exclude": "Warriors",
"size": 30,
"order": {
"avgAge": "desc"
}
},
"aggs": {
"avgAge": {
"avg": {
"field": "age"
}
}
}
}
},
"size": 0
}
Range Aggregation范围分组聚合
NBA球员年龄按20,20-35,35这样分组

POST /nba/_search
{
"aggs": {
"ageRange": {
"range": {
"field": "age",
"ranges": [
{
"to": 20
},
{
"from": 20,
"to": 35
},
{
"to": 35
}
]
}
}
},
"size": 0
}
NBA球员年龄按20,20-35,35这样分组(起别名)

Date Range Aggregation时间范围分组聚合
NBA球员按出生年月分组

POST /nba/_search
{
"aggs": {
"birthDayRange": {
"date_range": {
"field": "birthDay",
"format": "MM-yyy",
"ranges": [
{
"to": "01-1989"
},
{
"from": "01-1989",
"to": "01-1999"
},
{
"from": "01-1999",
"to": "01-2009"
},
{
"from": "01-2009"
}
]
}
}
},
"size": 0
}
Date Histogram Aggregation时间柱状图聚合
按天、月、年等进行聚合统计。可按year(1y),quarter(1q),month(1M),week(1w),day(1d),hour(1h),minute(1m),second(1s)间隔聚合
NBA球员按出生年分组

POST /nba/_search
{
"aggs": {
"birthday_aggs": {
"date_histogram": {
"field": "birthDay",
"format": "yyyy",
"interval": "year"
}
}
},
"size": 0
}

ES之query_string查询
简介
query_string查询,如果熟悉lucene的查询语法,我们可以直接用lucene查询语法写一个查询串进行查询,ES中接到请求后,通过查询解析器,解析查询串生成对应的查询。
指定单个字段查询

POST /nba/_search
{
"query": {
"query_string": {
"default_field": "displayNameEn",
"query": "james OR curry"
}
},
"size": 100
}

POST /nba/_search
{
"query": {
"query_string": {
"default_field": "displayNameEn",
"query": "james AND harden"
}
},
"size": 100
}
指定多个字段查询

ElasticSearch的高级使用
别名有什么用
在开发中,随着业务需求的迭代,较老的业务逻辑就要面临更新甚至是重构,而对于es来说,为了适应新的业务逻辑,可能就要对原有的索引做一些修改,比如对某字段做调整,甚至是重构索引。而做这些操作的时候,可能会对业务造成影响,甚至是停机调整等问题。由此,es提供了索引别名来解决这些问题。索引别名就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任意一个需要索引名的API来使用。别名的应用为程序提供了极大地灵活性。
查询别名
GET /nba/_alias
GET /_alias


新增别名

POST /_aliases
{
"actions": [
{
"add": {
"index": "nba",
"alias": "nba_v1.0"
}
}
]
}

删除别名

方式一
POST /_aliases
{
"actions": [
{
"remove": {
"index": "nba",
"alias": "nba_v1.0"
}
}
]
}
方式二
DELETE /nba/_alias/nba_v1.0
重命名别名

POST /_aliases
{
"actions": [
{
"remove": {
"index": "nba",
"alias": "nba_v1.0"
}
},
{
"add": {
"index": "nba",
"alias": "nba_v2.0"
}
}
]
}
为多个索引指定一个别名

POST /_aliases
{
"actions": [
{
"add": {
"index": "nba",
"alias": "nba_v2.0"
}
},{
"add": {
"index": "cba",
"alias": "cba_v2.0"
}
}
]
}
为同个索引指定多个别名

POST /_aliases
{
"actions": [
{
"add": {
"index": "nba",
"alias": "nba_v2.0"
}
},{
"add": {
"index": "nba",
"alias": "cba_v2.2"
}
}
]
}
通过别名读索引
当别名指定了一个索引,则查出一个索引

当别名指定了多个索引,则查出多个索引
GET /nba_v2.2
通过别名写索引
当别名指定了一个索引,则可以做写的操作

POST /nba_v2.0/_doc/566
{
"countryEn": "Croatia",
"teamName": "快船",
"birthDay": 858661200000,
"country": "克罗地亚",
"teamCityEn": "LA",
"code": "ivica_zubac",
"displayAffiliation": "Croatia",
"displayName": "伊维察 祖巴茨哥哥",
"schoolType": "",
"teamConference": "⻄部",
"teamConferenceEn": "Western",
"weight": "108.9 公⽄",
"teamCity": "洛杉矶",
"playYear": 3,
"jerseyNo": "40",
"teamNameEn": "Clippers",
"draft": 2016,
"displayNameEn": "Ivica Zubac",
"heightValue": 2.16,
"birthDayStr": "1997-03-18",
"position": "中锋",
"age": 22,
"playerId": "1627826"
}
当别名指定了多个索引,可以指定写某个索引
POST /_aliases
{
"actions": [
{
"add": {
"index": "nba",
"alias": "national_player",
"is_write_index": true
}
},
{
"add": {
"index": "cba",
"alias": "national_player"
}
}
]
}
POST /national_player/_doc/566
{
"countryEn": "Croatia",
"teamName": "快船",
"birthDay": 858661200000,
"country": "克罗地亚",
"teamCityEn": "LA",
"code": "ivica_zubac",
"displayAffiliation": "Croatia",
"displayName": "伊维察 祖巴茨妹妹",
"schoolType": "",
"teamConference": "⻄部",
"teamConferenceEn": "Western",
"weight": "108.9 公⽄",
"teamCity": "洛杉矶",
"playYear": 3,
"jerseyNo": "40",
"teamNameEn": "Clippers",
"draft": 2016,
"displayNameEn": "Ivica Zubac",
"heightValue": 2.16,
"birthDayStr": "1997-03-18",
"position": "中锋",
"age": 22,
"playerId": "1627826"
}
ES之重建索引
简介
ElasticSearch是一个实时的分布式搜索引擎,为用户提供搜索服务,当我们决定存储某种数据时,在创建索引的时候需要将数据结构完整确定下来,于此同时索引的设定和很多固定配置将不能修改。当需要改变数据结构时,就需要重新建立索引,为此,Elastic团队提供了很多辅助工具帮助开发人员进行重建索引
步骤
- nba取一个别名nba_latest,nba_latest作为对外使用
- 新增一个索引nba_20200810,结构复制于nba索引,根据业务要求修改字段
- 将nba数据同步至nba_20200810
- 给nba_20200810添加别名nba_latest,删除此处nba别名nba_latest
- 删除nba索引

PUT /nba_20220810
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"birthDay": {
"type": "date"
},
"birthDayStr": {
"type": "keyword"
},
"code": {
"type": "text"
},
"country": {
"type": "keyword"
},
"countryEn": {
"type": "keyword"
},
"displayAffiliation": {
"type": "text"
},
"displayName": {
"type": "text"
},
"displayNameEn": {
"type": "text"
},
"draft": {
"type": "long"
},
"heightValue": {
"type": "float"
},
"jerseyNo": {
"type": "keyword"
},
"playYear": {
"type": "long"
},
"playerId": {
"type": "keyword"
},
"position": {
"type": "text"
},
"schoolType": {
"type": "text"
},
"teamCity": {
"type": "text"
},
"teamCityEn": {
"type": "text"
},
"teamConference": {
"type": "keyword"
},
"teamConferenceEn": {
"type": "keyword"
},
"teamName": {
"type": "keyword"
},
"teamNameEn": {
"type": "keyword"
},
"weight": {
"type": "text"
}
}
}
}
将旧索引数据copy到新索引
同步等待,接口将会在reindex结束后返回

POST /_reindex
{
"source": {
"index": "nba"
},
"dest": {
"index": "nba_20220810"
}
}
异步执行,如果reindex时间过长,建议加上“wait_for_completion=false”的参数条件,这样reindex将直接返回taskId
POST /_reindex?wait_for_completion=false
{
"source": {
"index": "nba"
},
"dest": {
"index": "nba_20220810"
}
}
替换别名

POST /_aliases
{
"actions": [
{
"add": {
"index": "nba_20220810",
"alias": "nba_latest"
}
},
{
"remove": {
"index": "nba",
"alias": "nba_latest"
}
}
]
}
删除旧索引
DELETE /nba
通过别名访问新索引

POST /nba_latest/_search
{
"query": {
"match": {
"displayNameEn": "james"
}
}
}
ES之refresh操作
理想的搜索
新的数据一添加到索引中立马就能搜索到,但是真实情况不是这样的
我们使用链式命令请求,先添加一个文档,再立刻搜索
curl -X PUT 192.168.199.170:9200/star/_doc/888 -H 'Content-Type:
application/json' -d '{ "displayName": "蔡徐坤" }'
curl -X GET localhost:9200/star/_doc/_search?pretty
强制刷新
curl -X PUT 192.168.199.170:9200/star/_doc/666?refresh -H 'Content-Type:
application/json' -d '{ "displayName": "杨超越" }'
curl -X GET localhost:9200/star/_doc/_search?pretty
修改默认更新时间(默认时间是1s)
PUT /star/_settings
{
"index": {
"refresh_interval": "5s"
}
}
将refresh关闭
PUT /star/_settings
{
"index": {
"refresh_interval": "-1"
}
}
ES之高亮查询
前言
如果返回的结果集中很多符合条件的结果,那怎么能一眼就能看到我们想要的那个结果呢?比如下面网站所示的那样,我们搜索“科比”,在结果集中,将所有“科比”高亮显示?

高亮查询

POST /nba_latest/_search
{
"query": {
"match": {
"displayNameEn": "james"
}
},
"highlight": {
"fields": {
"displayNameEn": {}
}
}
}
自定义高亮查询
POST /nba_latest/_search { "query": { "match": { "displayNameEn": "james" } }, "highlight": { "fields": { "displayNameEn": { "pre_tags": [ "<h1>" ], "post_tags": [ "</h1>" ] } } } }
ES之查询建议
查询建议是什么
查询建议:是为了给用户提供更好的搜索体验。包括:词条检查,自动补全
词条检查

自动补全

Suggester
- Term suggester
- Phrase suggester
- Completion suggester
字段
| text | 指定搜索文本 |
| field | 获取建议词的搜索字段 |
| analyzer | 指定分词器 |
| size | 每个词返回的最大建议词数 |
| sort |
如何对建议词进行排序,可用选项: score:先按评分排序、再按文档频率排、term顺序 frequency:先按文档频率排,再按评分,term顺序排 |
| suggest_mode |
建议模式,控制提供建议词的方式: missing:仅在搜索的词项在索引中不存在时才提供建议词,默认值; popular:仅建议文档频率比搜索词项高的词 always:总是提供匹配的建议词 |
Term Suggester
term词条建议器,对给输入的文本进行分词,为每个分词提供词项建议
POST /nba_latest/_search
{
"suggest": {
"my-suggestion": {
"text": "jamse hardne",
"term": {
"suggest_mode": "missing",
"field": "displayNameEn"
}
}
}
}
Phrase suggester
phrase短语建议,在term的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻成都,以及词频等
POST /nba_latest/_search
{
"suggest": {
"my-suggestion": {
"text": "jamse harden",
"phrase": {
"field": "displayNameEn"
}
}
}
}
Completion suggester
Completion完成建议
POST /nba_latest/_search
{
"suggest": {
"my-suggestion": {
"text": "Miam",
"completion": {
"field": "teamCityEn"
}
}
}
}
集群的搭建
ES集成SpringBoot和mysql
Spring Boot整合ElasticSearch和Mysql 附案例源码
ES常用语法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号