python使用KNN文本分类
上次爬取的爸爸、妈妈、老师和自己的作文,利用sklearn.neighbors.KNeighborsClassifier进行分类。
import jieba import pandas as pd import numpy as np import os import itertools import matplotlib.pyplot as plt from sklearn.feature_extraction.text import CountVectorizer from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import confusion_matrix from sklearn.decomposition import PCA #读取文件内容 path = 'E:\作文' corpos = pd.DataFrame(columns=['filepath','text','kind']) for root,dirs,files in os.walk(path): for name in files: filepath = root+'\\'+name f = open(filepath,'r',encoding='utf-8') text = f.read() txt = ''.join(text.split('\n')) kind = root.split('\\')[-1] corpos.loc[len(corpos)] = [filepath,text.strip(),kind] #设置停用词,构建词频矩阵 stopwords = pd.read_csv(r'Stopwords.txt', encoding='utf-8',sep='\n') def tokenizer(s): words=[] cut = jieba.cut(s) for word in cut: words.append(word) return words count = CountVectorizer(tokenizer=tokenizer, stop_words=list(stopwords['stopword'])) countvector = count.fit_transform(corpos.iloc[:,1]).toarray() #将类别转化为数字 kind = np.unique(corpos['kind'].values) nkind = np.zeros(700) for i in range(len(kind)): index = corpos[corpos['kind']==kind[i]].index nkind[index] = i+1 #将词频矩阵转化为二维数据,画图 pca = PCA(n_components=2) newvector = pca.fit_transform(countvector) plt.figure() for i,c,m in zip(range(len(kind)),['r','b','g','y'],['o','^','>','<']): index = corpos[corpos['kind']==kind[i]].index x = newvector[index,0] y = newvector[index,1] plt.scatter(x,y,c=c,marker=m,label=kind[i]) plt.legend() plt.xlim(-5,10) plt.ylim(-20,50) plt.xlabel('X Label') plt.ylabel('Y Label') #随机选出测试集 index = np.random.randint(0,700,200) x_test = countvector[index] y_test = corpos.iloc[index,2] #利用knn分类 knn = KNeighborsClassifier() knn.fit(countvector,corpos.iloc[:,2]) y_pred = knn.predict(x_test) knn.score(x_test,y_test) #画knn分类结果的混淆矩阵
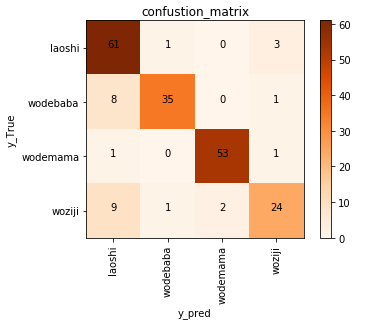
knn_confusion = confusion_matrix(y_test,y_pred)
'''
array([[61, 1, 0, 3],
[ 8, 35, 0, 1],
[ 1, 0, 53, 1],
[ 9, 1, 2, 24]])
'''
plt.imshow(knn_confusion,interpolation='nearest',cmap=plt.cm.Oranges) plt.xlabel('y_pred') plt.ylabel('y_True') tick_marks = np.arange(len(kind)) plt.xticks(tick_marks,kind,rotation=90) plt.yticks(tick_marks,kind) plt.colorbar() plt.title('confustion_matrix') for i,j in itertools.product(range(len(knn_confusion)),range(len(knn_confusion))): plt.text(i,j,knn_confusion[j,i], horizontalalignment="center")
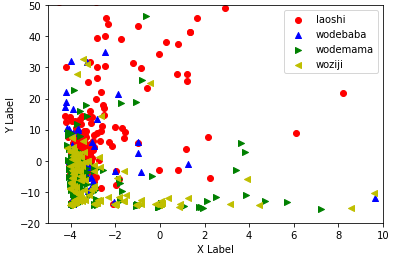
数据散点图如下所示:
knn分类结果的混淆矩阵图如下所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号