接口自动化学习(1)
1.自动化测试具体怎么做的(流程怎么样的?)
// 用什么做的?
// 需要注意什么?
// 核心关键是什么?
● 接口自动化这块,我们当时用的python+requests库来写脚本的,也会用到其他的一些库像pytest、ddt、unittest、xlrd、json、re、pymysql、htmlreport、allure等。
● 另外,我觉得做接口自动化,最关键的还是用例数据的准备,请求数据的组装,及请求发送,和对响应数据的提取处理,与判断校验/做断言。
当然要做自动化,首先就是要搭建好自动化测试环境,之后就准备好用例数据嘛,像用例数据这块的话,公司统一要求用 excel 表格来管理的,这里面主要就是用例标题,url,请求方式,请求头,请求参数,用来做断言的响应数据。其实主要目的就是起到数据与脚本的分离,方便后期的管理。
● 数据准备好了之后,然后就开始写脚本,首先把相关的包导入进来,之后调用封装好的函数来读取excel表格中的用例数据,数据返回出来是一个列表形式。然后就是定义个类,去继承unittest.TestCase基类,并重写其中 setUp,tearDown方法,在setUp方法中主要就是做一些初始化的准备工作,tearDown中主要完成一些回收工作,比如,像连接数据库可以放在 setUp方法中,在tearDown方法关闭数据库的连接然后实现用例函数,用例函数必须要以test开头,这里的话,用例函数中主要就是实现请求数据的组装,还有就是调用requests库中的get或post方法发请求,把相关的参数传进去,请求参数这块我们需要用到ddt模型,去引用前面提取出来的 list中的额数据这边请求发送之后会返回一个响应对象,这里面接下来其实最主要的就是对响应对象中的数据进行提取处理,并判断校验并做断言。
● 断言这块这一块的话,主要就是关注几个点,一个就是状态码,还有就是响应信息,不过,这里面最重要的是响应的正文内容的判断。主要就是判断这几个块与结构文档是否一致。
对于响应的正文内容,可能会比较麻烦一点,因为一般后台会返回两种格式的数据,一种是json格式的数据,其实对于json格式的数据我们需要把它转化为字典形式,治理其实主要就是调用response.json()函数就已经转为字典,然后去提取其中的一些核心信息去做断言判断就可以了。
● 另外,如果返回的是html格式的数据,我们需要用到一个re库,并调用其中的一个函数findall结合正则表达式提取关键信息做断言判断。断言的一些函数,其实都是调用unittest框架中的函数实现,像assertEqual,assertIn,以及做全量对标的话,需要用到assertListEuqal和assertDictEqual,主要就是这些。
● 脚本这块差不多就是这么写的,最后我们需要引入一个htmlreport或allure库去自动生成自动化报告,然后就是对报告进行分析,报告这一块的话,主要有通过,异常,失败几种请情况,如果如果错误的话,基本一般都是脚本问题,这个时候我们需要去重新调试我们的脚本,如果是失败的话,一般来说,我都会先检查自己的脚本是否有问题,如果没有问题基本就可以提 Bug 了。
接口自动化,我们当时就这么做的。
2.request框架有哪些方法?
发送请求
requests.get()
//获取HTML网页的主要方法,对应于HTTP的GET
requests.head()
//获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post()
//向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put()
//向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch()
//向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete()
//向HTML页面提交删除请求,对应于HTTP的DELETE
获取响应数据
reponse.status_code
//HTTP请求的返回状态,200表示连接成功,404表示失败
reponse.text
//HTTP响应内容的字符串形式,即,url对应的页面内容
reponse.json()
//HTTP响应内容的JSON格式化
reponse.headers
//返回HTTP响应头的字典
reponse.cookies
//返回HTTP响应的cookies
3.接口自动化用过哪些库?
Requests 库
//这个里面主要封装了各种发送请求处理请求的方法
Json 库
//这个库主要用来将 json 格式转化为字典,或者将字典转化为 json 格式数据
Re 库
//这个库当时是针对后台返回的是 html 格式,用来提取 html 格式中的数据的
Xlrd 库
//这个库当时主要用来读取 excel 表格数据的
Ddt 库
//这个库主要用来实现数据驱动的
Pymysql 库
//这个库主要就是用来读取数据库,操作数据库的。
htmlreport或allure库
//这两个库主要用于自动生成测试报告
4.如果要传递请求头如何处理?
● 传递请求头,其实还是比较简单的,首先要搞清楚这个接口需要传递哪些请求参数,然后订制一个请求头,一般都是组装成一个字典,然后在调用post 或get方法发请求的时候,在这两个函数中有一个参数headers,这个参数就是用来传递请求头的,把组装好的请求头通过headers参数进行传递就可以了。
//示例
# 初始化http请求参数内容
data ={"Id": 2, "type": "1", "price": "200", "quantity": "2"}
# 初始化url地址
url='https://www.xxx.com/order/place'
# 初始化http请求头内容
headers={"Accept":"application/json,text/plain,*/*","Authorization":'bearer {}'.format(self.token),"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/83.0.4103.116 Safari/537.36","Content-Type":"application/json;charset=UTF-8","Host":"www.xxx.com","Connection":"keep-alive","Content-Length":"87","ide":'{}.'.format(t),"Call-Source":"WEB","Origin":"https://www.xxx.com","Sec-Fetch-Site":"same-origin","Sec-Fetch-Mode":"cors","Referer":"https://www.xxx.com/index","Accept-Encoding":"gzip,deflate,br"}
# 调用post请求,请求接口r=requests.post(url=url,json=data,headers=headers,verify=False)
5.你们做接口自动化,用例数据是怎么组织,管理的?
● 用例数据这块,当时公司要求使用excel表格来进行管理,其实这里主要也是为了实现数据与脚本的分离,提高整个工程后期的维护与优化,这里把数据封装到excel表格之后,我们在脚本中通过调用封装好的读取excel表格的数据函数,然后利用ddt模型来引用这些数据组织请求参数或头,发请求。
● 对 excel 表格中的用例数据,我们是这么组织的,会有以下几个字段像用例标题,请求地址,请求方式,请求头,请求参数,响应结果,这个几个部分。对于请求头跟请求参数,因为脚本中发请求都是通过组装成字典的形式来发送的,所以这里我们也是通过类似于字典的形式文本格式来进行组织,主要就是方便后期脚本的提取与引用。
● 其实我觉得,这样去处理的好处就是,后期如果用例数据有变动,或者需要增加或删除部分用例直接针对excel 表格数据进行操作就可以了,不需要改动脚本。
这也就方便整个项目工程的管理与维护了。
6.接口自动化的用例又是怎么管理的?
回答一:
● 自动化用例这块,我们利用unittest框架来编写的,然后利用unittest 帮我们去统一加载执行用例。
● 如果要进行全量执行的话,通过调用unittest里面提供的defaultTestLoader.discover()这个函数来加载test_case 目 录 下 的 所 有 用 例, 如 果 某 条 用 例 没 有 通 过 , 需 要 单 独 调 试 , 可 以 通 过unittest.TestLoader()来创建一个加载器,加载具体的某条用例进行执行,调试即可。
● 最后就是结合HTMLReport这个库最终会自动帮我们生成报告。
回答二:
● 自动化用例的管理,我是用pytest框架进行编写的,在用例编写上,它无需像unittest一样,将测试写在类里, pytest无需继承任何类,它是使用文件名规范来让pytest找到我们写的测试方法的文件。再用pytest.fixtrue标签,对被该标签标记的函数作为其他测试用例的前置函数,类似于“setup”。
● 测试用例参数化我用的是@pytest.mark.parametrize装饰器,它可以遍历传入的列表数据。
● 在用例执行上,我会用MARK标签对用例进行分类筛选,在执行用例时,就可以根据自己的需求执行不同分类的用例。例如smoke(冒烟)、demo(类)、login(登录)、test(调试)等几种标签分类。
● 最后,测试报告的自动化生成我用的是allure库。
7.对于返回的数据,你怎么检查校验?
● 这块的话,首先我们一定得搞清楚后台返回的到底是什么格式的数据,一般都是两种情况,一种就是json格式的数据,一种就是html格式的数据,关注点一般就是"状态码","响应信息"的正确性,最重要的就是"响应内容",如果正文内容是json格式的数据,我们就使用response.json()函数来提取就可以了,如果是正文内容html格式的数据,我们就使用response.text来提取,然后利用re库中findall函数结合正则表达式来提取核心字段进行校验。对于响应内容,我们需要根据接口文档的说明,去检查一些核心的字段信息,去判断就行了。
● 另外,如果有些接口需要检查数据库的话,那我们去连接数据库,查询对应数据,然后去判断校验,断言这块我当时就是这么做的。
8.对于接口响应数据,你是怎么做断言的?
● 我首先确定需要检查的键是否存在,assertIn去判断键是否存在,如果键存在,然后根据键去获取其中的值,如果值是变化的,有可能有,有可能没有,或者值本身在发生变化,这里需要读取数据库中的实际对应的字段值,然后判断返回结果中的对应字段的值与数据库中读取出来的值是否一致。
9.你写了多少接口自动化用例 你们接口自动化用例是怎么跑的?
● 自动化用例,也没有具体数过,当时我负责的所有模块的接口的自动用例都是我这边独立完成的,有模块的用例会多一点,有些会少一点,这具体看接口的参数有多少,参数多限制条件多的,一般用例会比较多一点,我负责的模块大概有100多条用例是有的吧!
● 自动化用例一般我们都是全量跑的,如果要全量跑,我们一般都是加载用例目录也就是testcase下的所有用例文件这里主要就是调用 defaultTestLoader.discover(用例目录的路径,匹配规则)函数进行加载所有用例文件。有时候如果只是某个模块的用例执行不通过,需要单独执行调试某个模块的用例。这里可以先创建一个套件,调用 unittest.testsuite()来进行创建然后调用unittest.testLoader()函数来创建一个加载器然后在加载具体某个模块的具体用例去执行调试。如果要定时全量跑所有的用例,一般我们都是在每周五下午会定时全量跑所有的用例,然后周一过来看报告分析报告,这里就需要用到持续集成,我们当时用的jenkins,从git上检出自动化脚本,然后让jenkins自动帮我们去跑。
10.有没有了解过数据驱动?
● 数据驱动就是把用例数据与脚本代码进行分离,把用例数据进行独立出来嘛,它的好处就在于方便后台的管理维护。这样的话,如果数据后期发生变化,只要维护修改excel表格中的数据就可以,比如,需要增加数据或者需要删除某条用例数据,或者修改数据就变得比较方便。
● 对于自动化用例数据我们公司当时要求放在Excel表格中来管理的,然后保存在工程中的data目录下,之后就是通过调用封装好的函数去读取数据,然后利用ddt模型来实现数据的驱动,对于ddt模型,它所采用的就是python装饰器的原理来引用数据的。
另外,对于一些其他的一些常量数据,比如:文件的路径,用例的路径,邮件的配置信息,数据库的一些配置信息,我们都是通过配置文件来管理的,我们会在工程中创建一个config目录,然后把配置文件都是放在这个目录下的。
当时数据驱动这块就是这么来实现的。
11.有没有自己封装过函数?
● 也有自己封装过,但是不很多,大部分都调用公司封装好的函数来进行实现的像当时那个数据操作的相关模块这边是我封装,另外,像读取Excel表格数据的模块也是我这边封装,除了这个之外,还封装过一些其他函数,比如获取cookie值,获取手机验证码的函数等,这边都是有封装过的。
//示例
读取 excel 表格数据
# 读取 excel 表格数据
def get_data(filename,tablname):
# 1. 打开 excel 文件
book = xlrd.open_workbook(filename)
# 2. 打开一个表
sheet = book.sheet_by_name(tablname)
print(sheet.nrows)
# 3. 对表操作 列,行,单元格
list = []
for i in range(1,sheet.nrows):
list.append(sheet.row_values(i))
return list
获取cookie值
# 获取 cookie 值
def get_cookie(url,params,method):
# 发登录请求
if method=='POST':
response = requests.post(url, data=params)
else:
response = requests.get(url, params=params)
# 提取其中的cookie值,并返回
return response.cookies
获取验证码
# 获取验证码
def get_reset_pwd_verify(phone):
verfiyUrl = 'http://localhost/fw/mapi/index.php'
par1= { 'act':'send_reset_pwd_code','mobile': phone,'i_type': 1,'r_type': 2 }
res = requests.post(verfiyUrl, data=par1)
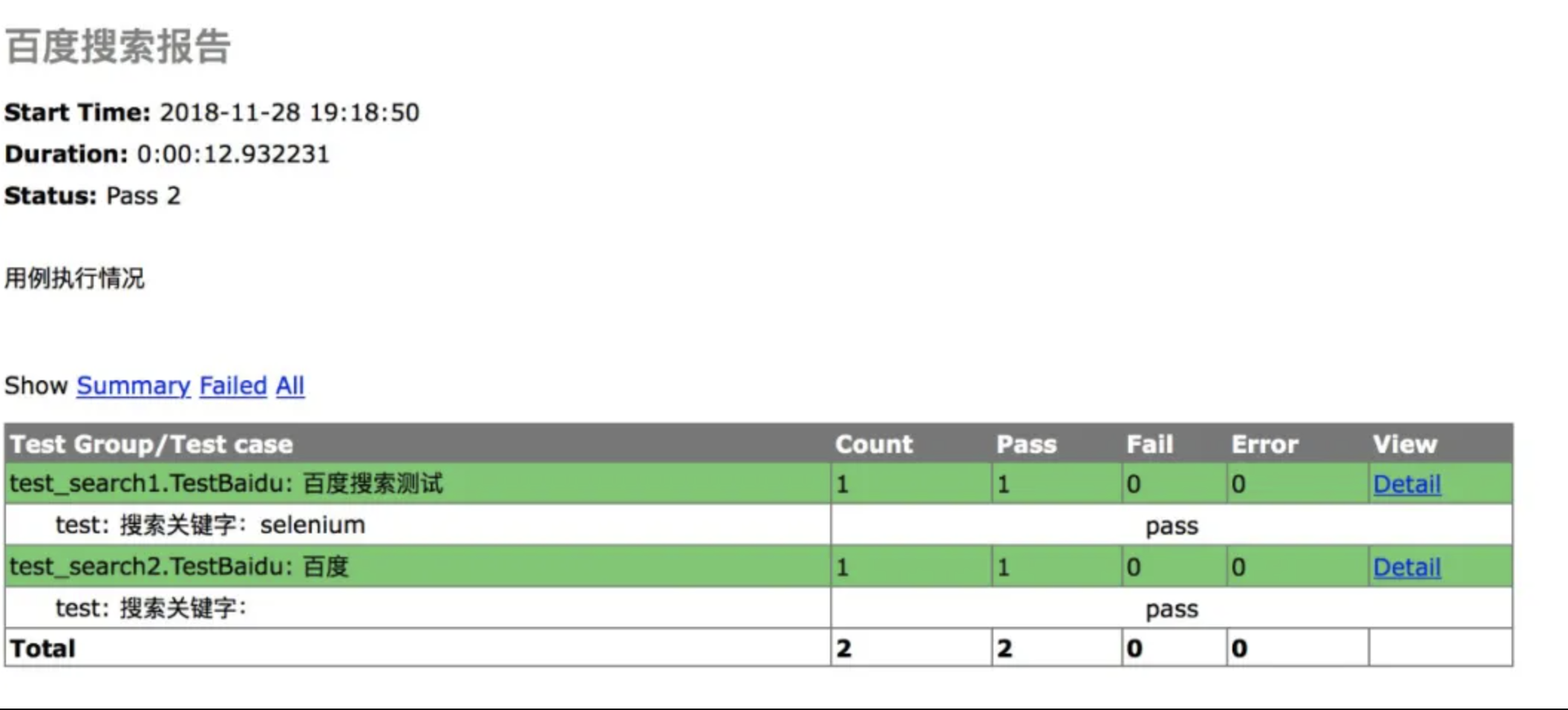
12.接口自动化这块是怎么出报告的?对于报告具体怎么分析的?报告中有哪些内容?
● 报告这一块,我们当时是用那个htmlreport这个库去生成的,首先主要关注运行结果,看有多少用例通过了,有多少执行失败,有多少执行错误。一般报告上都会详细说明,我们主要看失败用例以及错误用例,对于失败的用例跟错误的用例一般在报告上都会有详细细节说明,到底哪里执行没有通过。对于执行错误的用例,一般都是自己的脚本编写有问题,这个我一般会找到对应用例代码去调试查看。
● 对于失败用例,我一般首先怀疑自己的脚本,先检查自己的脚本有没有问题,如果不是自己脚本问题导致的,那这就说明这条用例真的执行失败了,一般就提BUG就可以了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号