pytest学习(二) - 用例筛选
如下图所示,我们编写的用例存放在不同的py文件当中
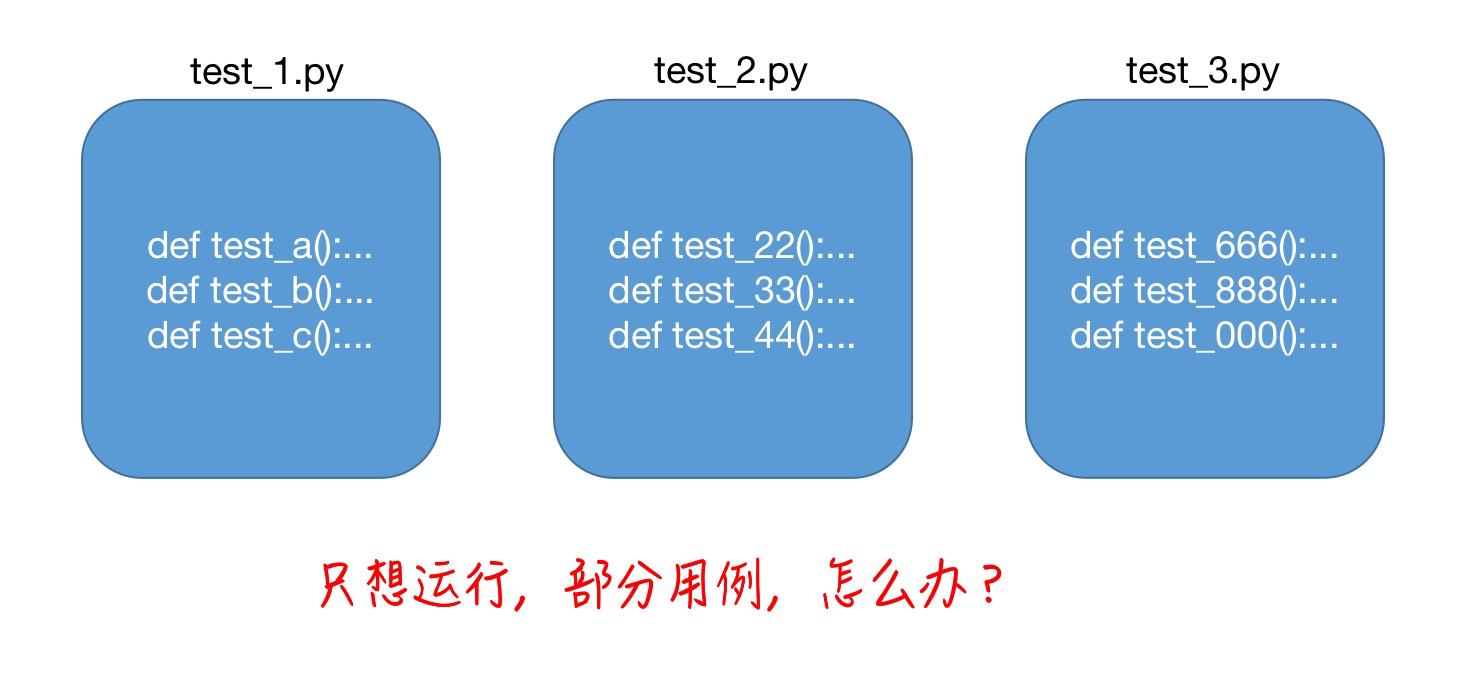
当我们想只运行诸多py文当中的部分用例,怎么办呢?
比如自动化工作当中,选择test_a,test_33,test_000这3个用例来运行的话,如何过滤呢?
pytest.mark一下
在pytest当中,先给用例打标记,在运行时,通过标记名来过滤测试用例。

步骤1:给用例打标签
给用例打标记分为2个步骤:
1)注册标签名
官方提供的注册方式有2种,这里只提供一种最简单直接的方式:
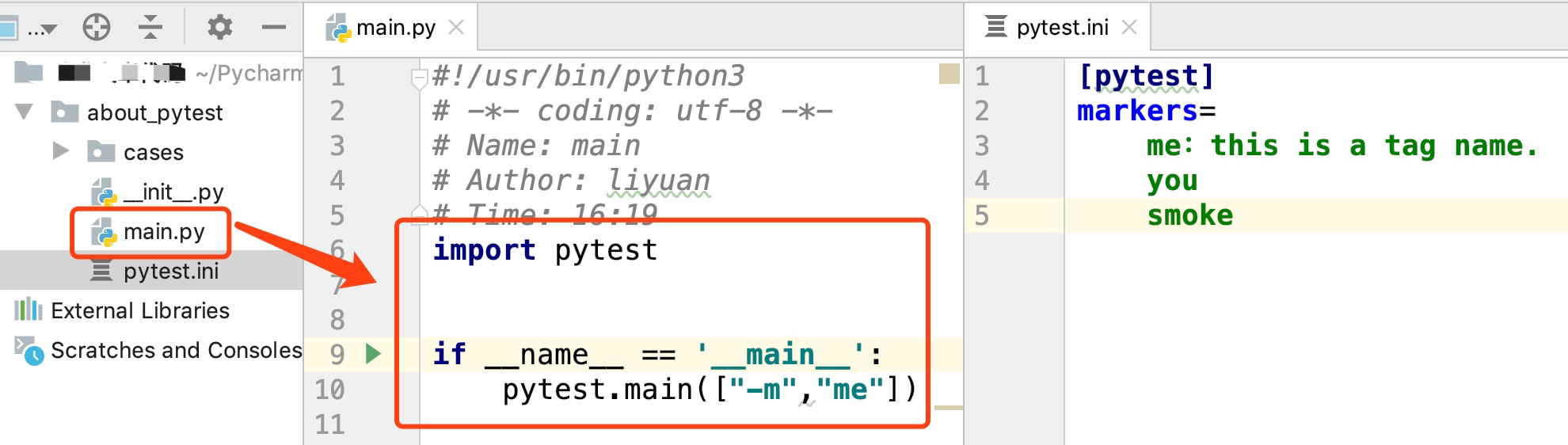
通过pytest.ini配置文件注册。在pytest.ini文件当中:
[pytest] # 固定的section名
markers= # 固定的option名称
标签名1: 标签名的说明内容。
标签名2
标签名N
示例如下:

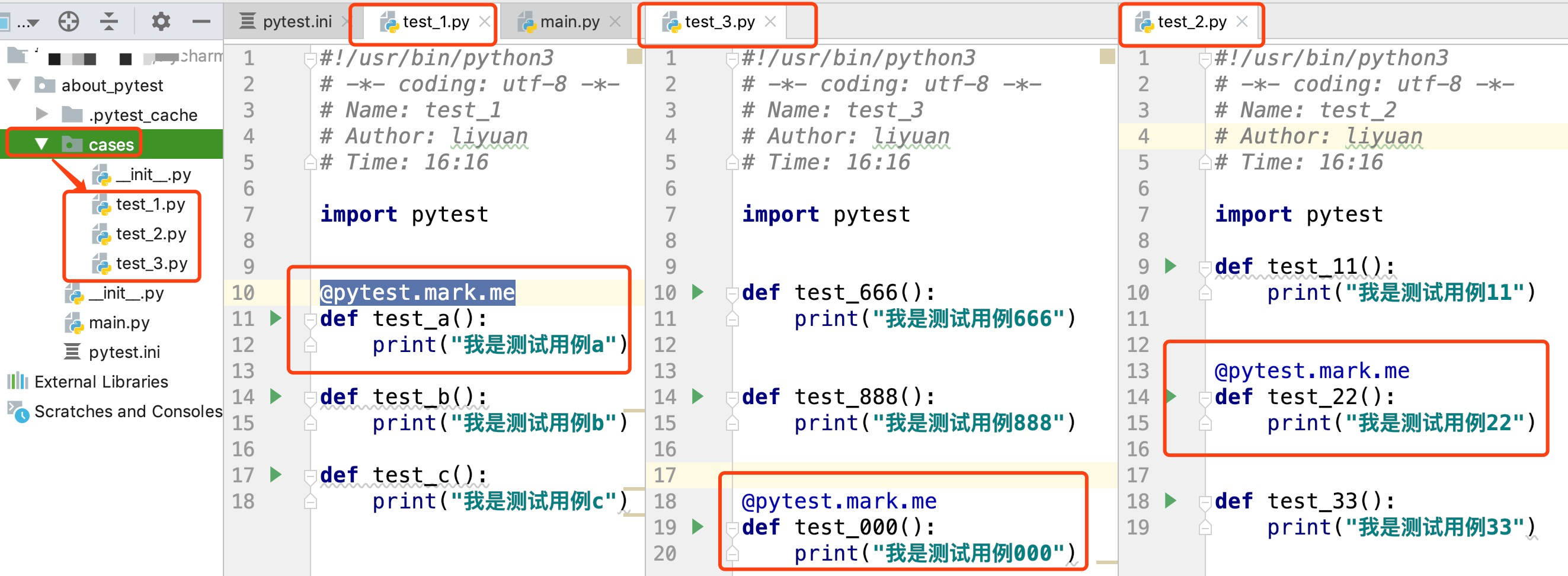
2)在测试用例/测试类中给用例打标记(只能使用已注册的标记名)
在 测试用例的前面加上:@pytest.mark.已注册标签名
如下图,对3个测试文件当中的,要筛选出来的用例,都打了me标签 。
步骤2:运行时,根据用例标签过滤(-m 标签名)
pytest提供了命令行参数来配置运行时的条件。
在命令行当中,输入pytest --help来查看所有可用的参数。

也可以调用pytest.main()函数,将运行时的参数以列表传进去,同样也可以达到命令行运行的效果。
根据标签名过滤用例的参数为:-m 标签名
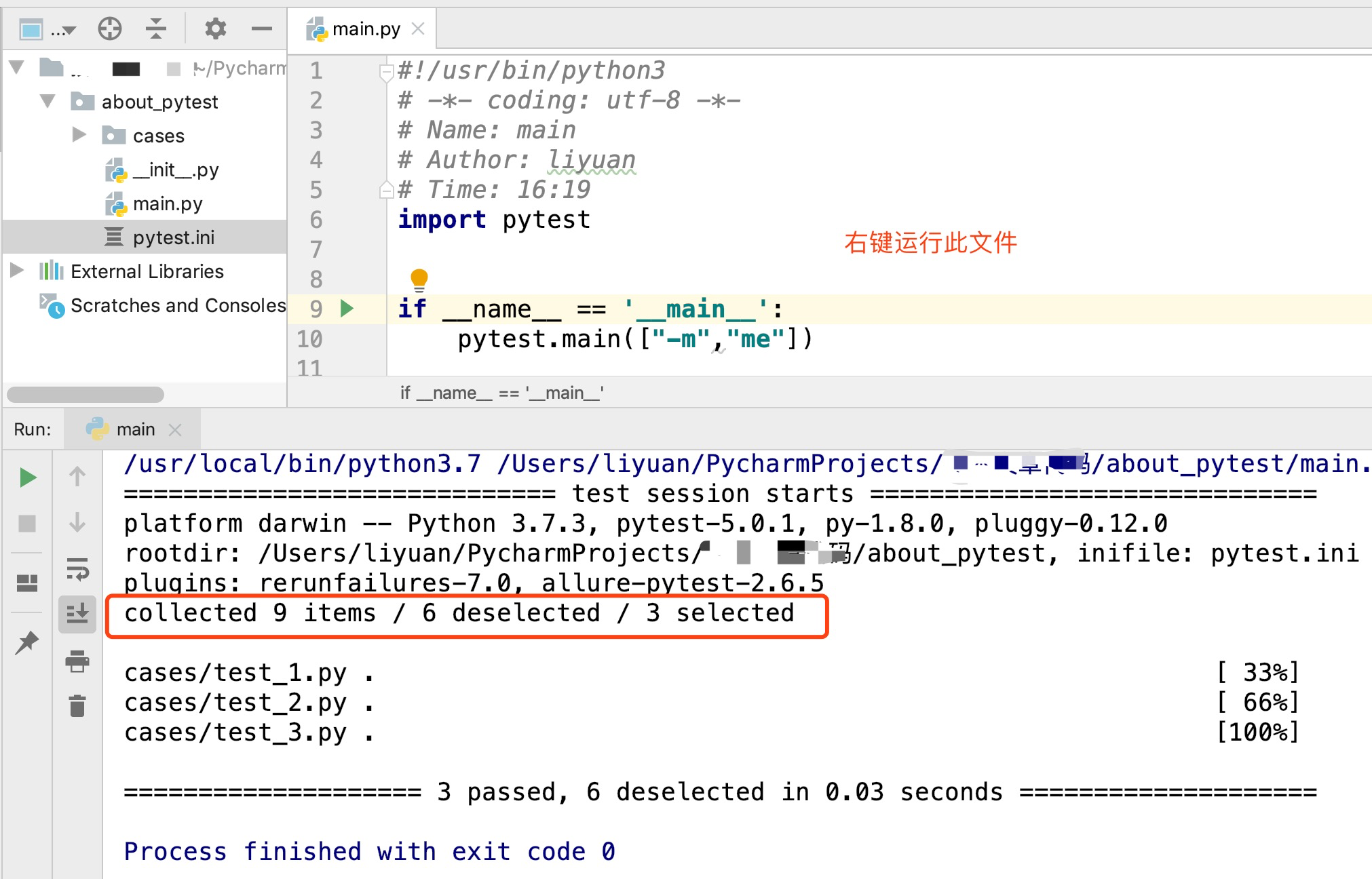
运行此文件的结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号