贝叶斯与卡尔曼滤波(2)--连续随机变量的贝叶斯公式
离散型变量的贝叶斯公式:
P(X=x|Y=y)=P(Y=y|X=x)P(X=x)P(Y=y)
如果将其用于连续型的变量中:
P(X=<x|Y=y)=P(Y=y|X<x)P(X<x)P(Y=y)
可以看到,首先分母P(Y=y)就是0,其次,P(Y=y|X<x)是一个较为奇怪的概率,因此,这个公式是无法计算的。
贝叶斯公式无法直接运用于连续随机变量。
连续型变量的贝叶斯公式计算,可以使用化积分为求和的方法。
X<x→x∑u=−∞X=u
因此:
P(X<x|Y=y)=x∑u=−∞P(X=u|Y=y)=x∑u=−∞P(Y=y|X=u)P(X=u)P(Y=y)(1)
推导至这一步,我们发现P(X=u),P(Y=y)还是0,不过其实,他们两个不是0,是无穷小。所以可以写成极限
P(X<x|Y=y)=limϵ→0x∑u=−∞P(y<Y<y+ϵ|X=u)P(u<X<u+ϵ)P(y<Y<y+ϵ)=limϵ→0x∑u=−∞∫y+ϵyfY|X(y|u)dy∫x+ϵxfX(x)dx∫y+ϵyfY(y)dy(2)
根据中值定理,可以继续改写为:
P(X<x|Y=y)=limϵ→0x∑u=−∞(fY|X(ξ1|u)⋅ϵ)(fX(ξ2)⋅ϵ)fY(ξ3)⋅ϵ(3)
其中:
⎧⎨⎩ξ1∈(y,y+ϵ)ξ2∈(u,u+ϵ)ξ3∈(y,y+ϵ)
继续化简:
P(X<x|Y=y)=limϵ→0x∑u=−∞fY|X(y|u)fX(u)fY(y)⋅ϵ=∫x−∞fY|X(y|u)fX(u)fY(y)du=∫x−∞fY|X(y|x)fX(x)fY(y)dx(4)
这样我们就得到了连续随机变量的贝叶斯公式
P(X<x|Y=y)=∫x−∞fY|X(y|x)fX(x)fY(y)dx
对其改变一下形式,假设后验概率的概率密度是 fX|Y(x|y),那么可以得到如下公式:
∫x−∞fX|Y(x|y)dx=∫x−∞fY|X(y|x)fX(x)fY(y)dx
fX|Y(x|y)=fY|X(y|x)fX(x)fY(y)
这样我们就完成了连续随机变量的贝叶斯公式。其实与离散型的公式很类似,那么类似的,
能否将fY(y)写成一个常量得到下面这个公式呢?
fX|Y(x|y)=ηfY|X(y|x)fX(x)
答案是可以的。
根据联合概率密度与边缘概率密度的关系可以推导如下:
fY(y)=∫+∞−∞f(y,x)dx=∫+∞−∞fY|X(y|x)f(x)dx=C(5)
可以得到:
η=1∫+∞−∞fY|X(y|x)fX(x)dx
似然概率与狄拉克函数
以一个例子说明。
例:测温度,给出先验概率密度:
fX(x)=1√2πe−(x−10)22
这时我们倾向于今天温度最后可能为10,我们随便给一个方差1,那就是今天的温度可能是9-11之间。给出观测值y=9,那么似然概率该怎么写呢?
似然概率fX|Y(x|y)应该是P(Y<y|X=x)的概率密度,按理说,只需要将概率分布写出来,然后对y求个导就能得到了。
我们已经知道了y=9了,这个时候如果按照对y求导,可以得到:
ddy(∫9−∞fY|X(y|x)dy)=0
fY|X(y|x)是关于y的一个函数,对y积分,y就没了,所以求导为0。
我们可以使用一个小技巧:对似然概率密度乘以一个无穷小
fY|X(y|x)⋅ϵ=P(y<Y<y+ϵ|X=x)
根据概率密度函数的定义,乘无穷小就是一个面积,即在y到y+无穷小的概率。所以:
fY|X(y|x)=limϵ→0P(y<Y<y+ϵ|X=x)ϵ
这个时候,这个公式就有了明确的物理意义,他就代表传感器的精度。
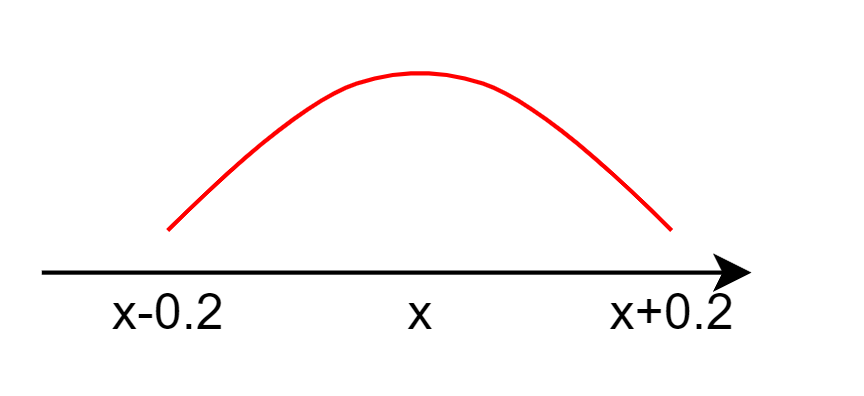
举个例子,温度计精度为±0.2,当真实值为x,那么,
P(x−0.2<Y<x+0.2|X=x)=0.9
继续推导,可以看到:(我们假设传感器测量值在±0.2内的概率为1)
∫y=x+0.2y=x−0.2fY|X(y|x)dy=1
这个积分代表,真实值取x的时候,观测值在x±0.2的概率为1,但是具体到[x−0.2,x+0.2]内,每一个观测值的概率值,很遗憾,我们无从得知。一般来说一个传感器只会提供精度范围,无法提供每一个取值的概率值。
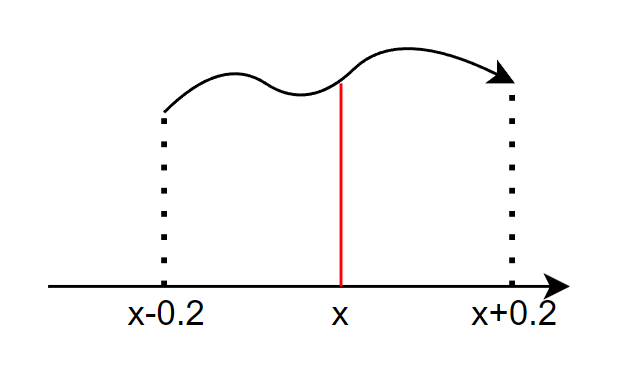
这个时候我们只能使用似然概率模型去人为的假设。一般来说,有下列常用的似然概率模型
-
等可能型
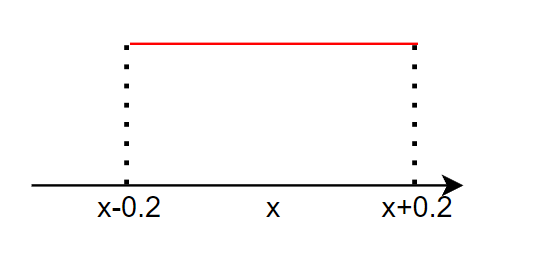
等可能型意味着概率密度函数是一个常数,即fY|X(y|x)=C,
∫y=x+0.2y=x−0.2fY|X(y|x)dy=1
很容易可以得到:
fY|X(y|x)={2.5|y−x|≤0.20|y−x|>0.2
-
阶梯型
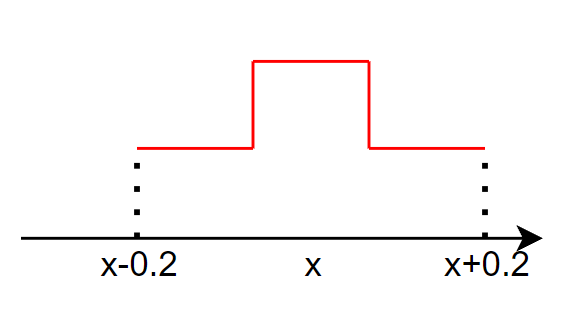
fY|X(y|x)=⎧⎨⎩C1|y−x|≤0.1C20.1<|y−x|<0.20|y−x|>0.2
推广:直方图型:
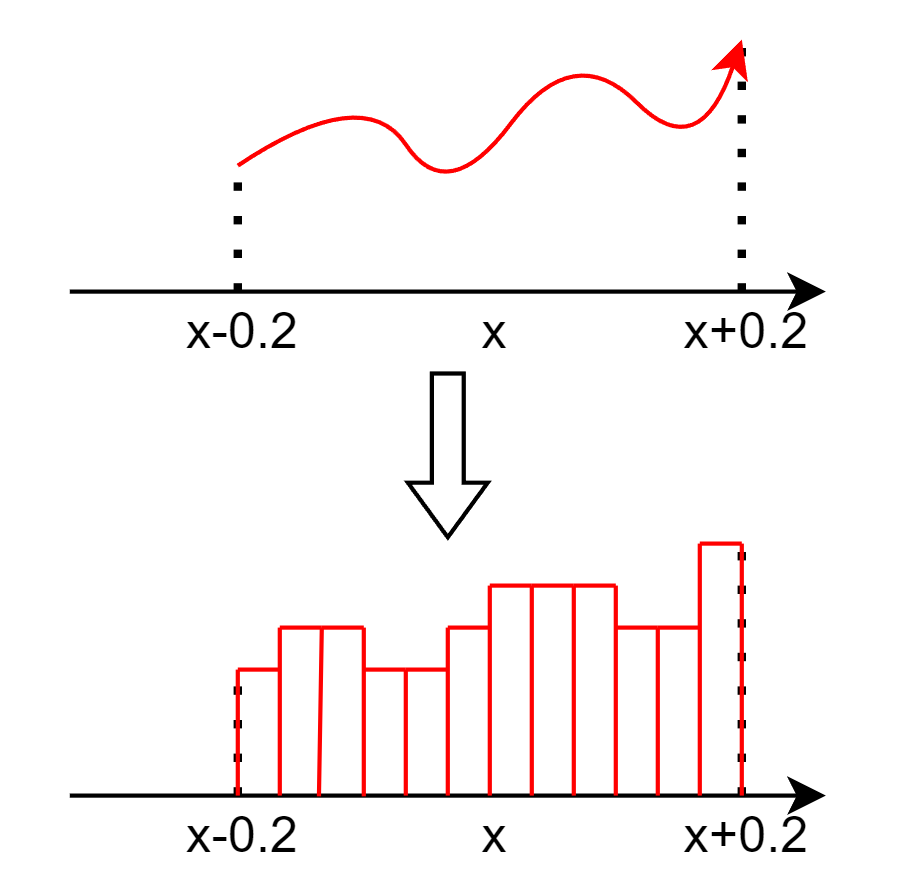
衍生出直方图滤波,它是非线性卡尔曼滤波的一种,与粒子滤波齐名
-
正态分布
正态分布是使用最多的似然概率模型
这是比较科学的一种概率分布模型
它的概率密度函数为:
fY|X(y|x)=1√2πσe−(y−x)22σ2
期望E(Y|X)=x,方差D(Y|X)=σ2
一般来说,σ取传感器的精度就可以了,比如它的精度为±0.2,那σ=0.2就可以了
正态分布的另一个好处是均值和方差比较好控制
回到这个测温度的例子,我们可以假设这个先验概率的概率密度函数满足期望为10,方差为为1的正态分布:
fX(x)=1√2πe−(x−10)22
观测为y=9,那么似然概率密度函数为:
fY|X(y|x)=1√2π⋅0.2e−(x−9)22⋅0.22
那么后验概率:
fX|Y(x|9)=η12π⋅0.2e−12[(x−10)2+(x−9)20.22]
η=(∫+∞−∞12π⋅0.2e−12[(x−10)2+(x−9)20.22]dx)−1
可以得到:
fY|X(x|9)=1√2π⋅0.038e−(x−9−0.0385)22⋅(0.038)2∽N(9.0385,0.0382)
先验概率N(10,1),似然概率N(9,0.22),后验概率N(9.0385,0.0382)
由此引申出一个重要定理:
若先验概率fX(x)∽N(μ1,σ21), 似然概率fY|X(y|x)∽N(μ2,σ22),那么后验概率有如下结论:
fX|Y(x|y)∽N(σ21σ21+σ22μ2+σ22σ21+σ22μ1,σ21σ22σ21+σ22)
若σ21≫σ22,那么更倾向于观测
fX|Y(x|y)∽N(11+σ22σ21μ2+σ22σ211+σ22σ21μ1,σ221+σ22σ21)∽N(μ2,σ22)(6)
若σ21≫σ22,那么更倾向于先验(也可以说预测值)
fX|Y(x|y)∽N(μ1,σ21)(7)
可以观察到,后验概率的方差比先验概率和似然概率都要小。观测和预测都是很不准的东西,但是最后却可以得到一个相对比较准确的结果,这就是贝叶斯滤波的强大之处。
狄拉克函数δ(x)
似然概率密度函数中fY|X(y|x)=1√2πσe−(y−x)22σ2,当σ→0的时候:
fY|X(y|x)=δ(x)
δ(x)的分布如下:
δ(x)={0x≠0∞x=0
并且狄拉克函数有以下性质:
∫+∞−∞δ(x)dx=1
引入狄拉克函数就是为了解决传感器无限精度的问题。想象一下,当传感器没有误差的时候,概率密度该怎么设呢?当传感器的误差无限接近于0的时候,他的概率密度函数就是狄拉克函数。
狄拉克函数还有一个非常重要的性质就是选择性:
∫+∞−∞f(x)δ(x)dx=f(0)
δ(x)的本质是离散型的必然事件的概率密度函数。
设一个离散随机变量P(X=0)=1,那么:
P(X<x)={0x<01x⩾0
这是一个单位阶跃函数。在x=0的时候,突变为1.
设:
H(x)={0x<01x⩾0
那么:
δ(x)=ddxH(x)
证明∫+∞−∞f(x)δ(x)dx=f(0).
I=∫+∞−∞f(x)dH(x)=f(x)H(x)|+∞−∞−∫+∞−∞f′(x)H(x)dx=f(+∞)⋅1−0−(∫+∞0f′(x)dx)=f(+∞)−(f(+∞)−f(0))=f(0)(8)
推论:
-
∫baδ(x)dx=1a<0<b
-
∫baf(x)δ(x)dx=f(0)a<0<b
-
∫cdf(x)δ(x−a)dx=f(a)c<a<d
例:假设先验概率密度函数N(μ,σ2),观测y=10,似然概率密度函数:δ(10−x)
那么后验概率密度函数:
fX|Y(x|y)=η⋅δ(10−x)⋅1√2πσe−(x−μ)22σ2
其中:
η=(∫+∞−∞δ(10−x)1√2πσe−(x−μ)22σ2dx)−1=(1√2πσe−(10−μ)22σ2)−1(9)
得到后验概率密度:
fX|Y(x|y)=(1√2πσe−(10−μ)22σ2)−1⋅δ(10−x)⋅1√2πσe−(x−μ)22σ2=e(10−μ)22σ2−(x−μ)22σ2⋅δ(10−x)(10)
得到概率值
P(X<x|Y=10)=∫x−∞e(10−μ)2−(x−μ)22σ2⋅δ(10−x)dx={0x<101x⩾10(11)
本质上,它是一个必然事件。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异