python编码
编码回顾
先了解一下位,字节和kb是什么?

编码的种类情况
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Shift-JIS 日本字符
- ks_c_5601-1987 韩国编码
- TIS-620 泰国编码
由于每个国家都有自己的字符,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在局限性,即:仅涵盖本国字符,无其他国家字符的对应关系。应运而生出现了万国码,他涵盖了全球所有的文字和二进制的对应关系,
- Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中...
Unicode 起到了2个作用:
- 直接支持全球所有语言,每个国家都可以不用再使用自己之前的旧编码了,用unicode就可以了。(就跟英语是全球统一语言一样)
- unicode包含了跟全球所有国家编码的映射关系,为什么呢?后面再讲
Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。例如:利用unicode表示“Python”需要12个字节才能表示,比原来ASCII表示增加了1倍。
由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的!!!
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符;
总结:UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
字符在硬盘上的存储
无论以什么编码在内存里显示字符,存到硬盘上都是2进制。
ascii编码(美国): l 0b1101100 o 0b1101111 v 0b1110110 e 0b1100101 GBK编码(中国): 老 0b11000000 0b11001111 男 0b11000100 0b11010000 孩 0b10111010 0b10100010 Shift_JIS编码(日本): 私 0b10001110 0b10000100 は 0b10000010 0b11001101 ks_c_5601-1987编码(韩国): 나 0b10110011 0b10101010 는 0b10110100 0b11000010 TIS-620编码(泰国): ฉัน 0b10101001 0b11010001 0b10111001
要注意的是,存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就乱了
编码的转换
虽然国际语言是英语 ,但大家在自己的国家依然说自已的语言,不过出了国, 你就得会英语
编码也一样,虽然有了unicode and utf-8 , 但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的windows,默认编码依然是gbk,而不是utf-8
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。
若想让中国的软件可以正常的在 美国人的电脑上显示,只有以下2条路可走:
- 让美国人的电脑上都装上gbk编码
- 把你的软件编码以utf-8编码
第1种方法几乎不可能实现,第2种方法比较简单。 但是也只能是针对新开发的软件。 如果你之前开发的软件就是以gbk编码的,上百万行代码可能已经写出去了,重新编码成utf-8格式也会费很大力气。
so , 针对已经用gbk开发完毕的项目,以上2种方案都不能轻松的让项目在美国人电脑上正常显示,难道没有别的办法了么?
有, 还记得我们讲unicode其中一个功能是其包含了跟全球所有国家编码的映射关系,意思就是,你写的是gbk的“路飞学城”,但是unicode能自动知道它在unicode中的“路飞学城”的编码是什么,如果这样的话,那是不是意味着,无论你以什么编码存储的数据 ,只要你的软件在把数据从硬盘读到内存里,转成unicode来显示,就可以了。
由于所有的系统、编程语言都默认支持unicode,那你的gbk软件放到美国电脑 上,加载到内存里,变成了unicode,中文就可以正常展示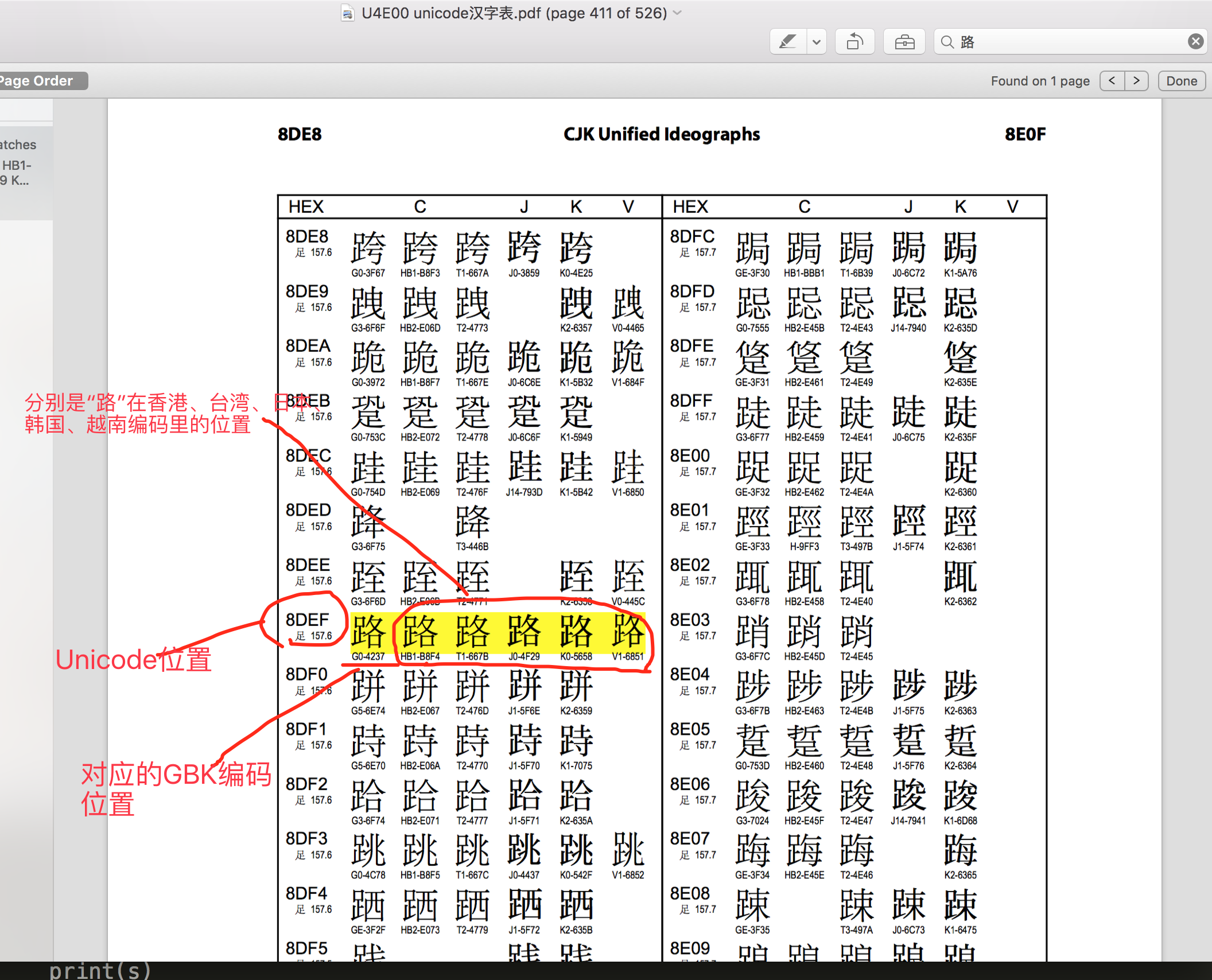
Python3的执行过程
python3 执行代码的过程
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明
编码转换过程
实际代码演示,在py3上 把你的代码以utf-8编写, 保存,然后在windows上执行

python2
它的默认编码是ASCII,想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变量字符串就也是utf-8意味你以utf-8编码的文件,在windows是乱码。
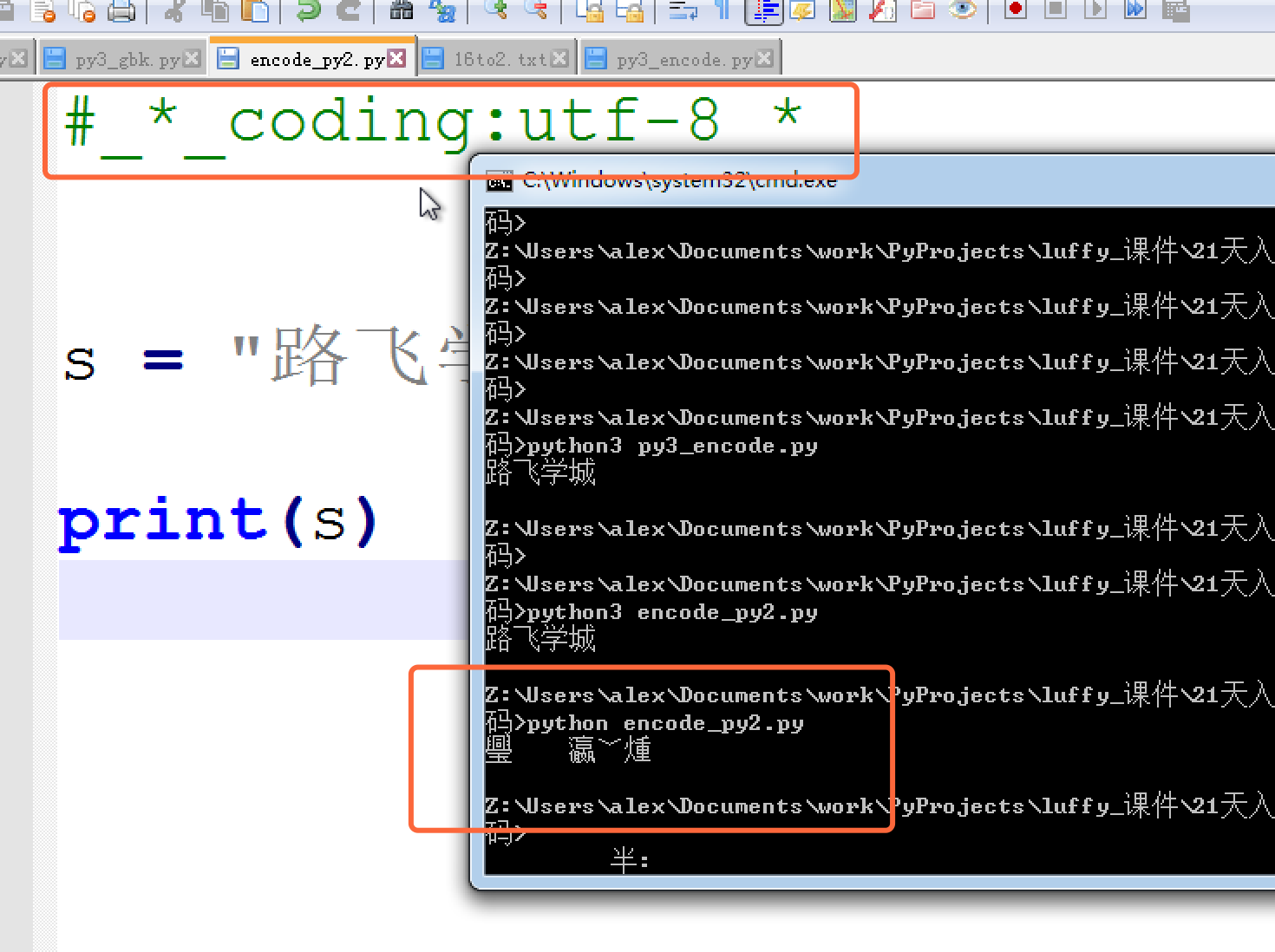
因为只有2种情况 ,你的windows上显示才不会乱
- 字符串以GBK格式显示
- 字符串是unicode编码
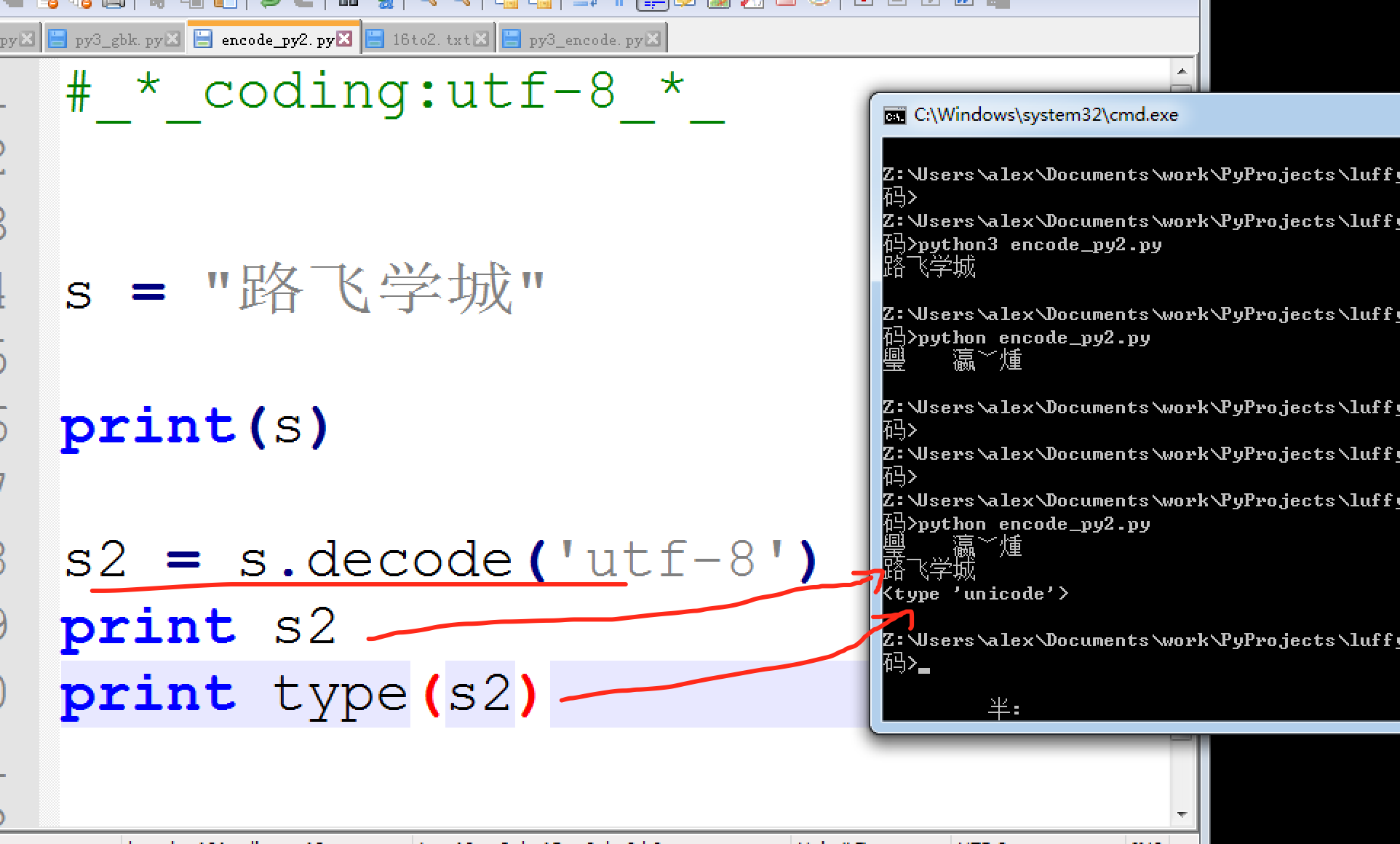
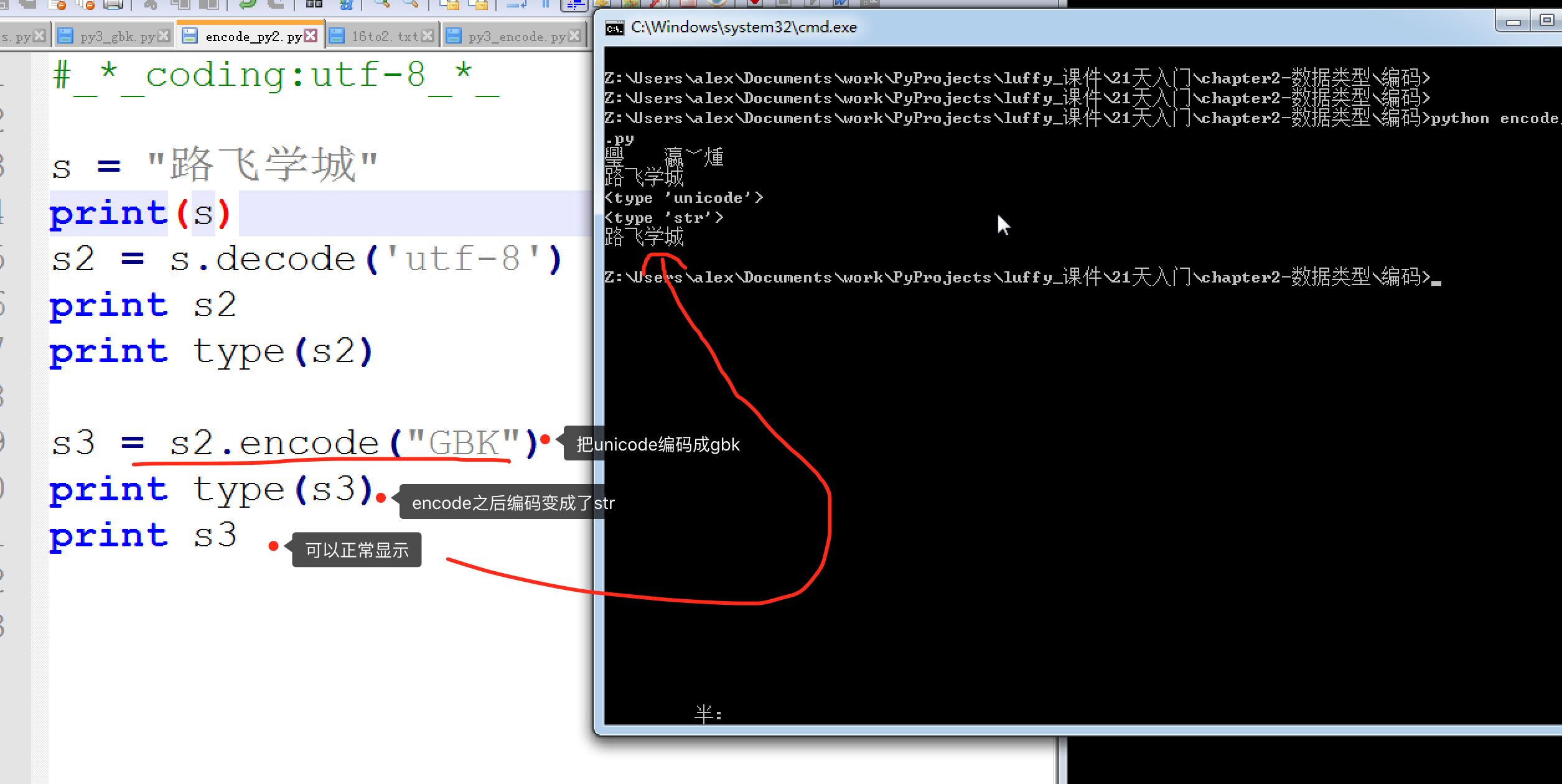
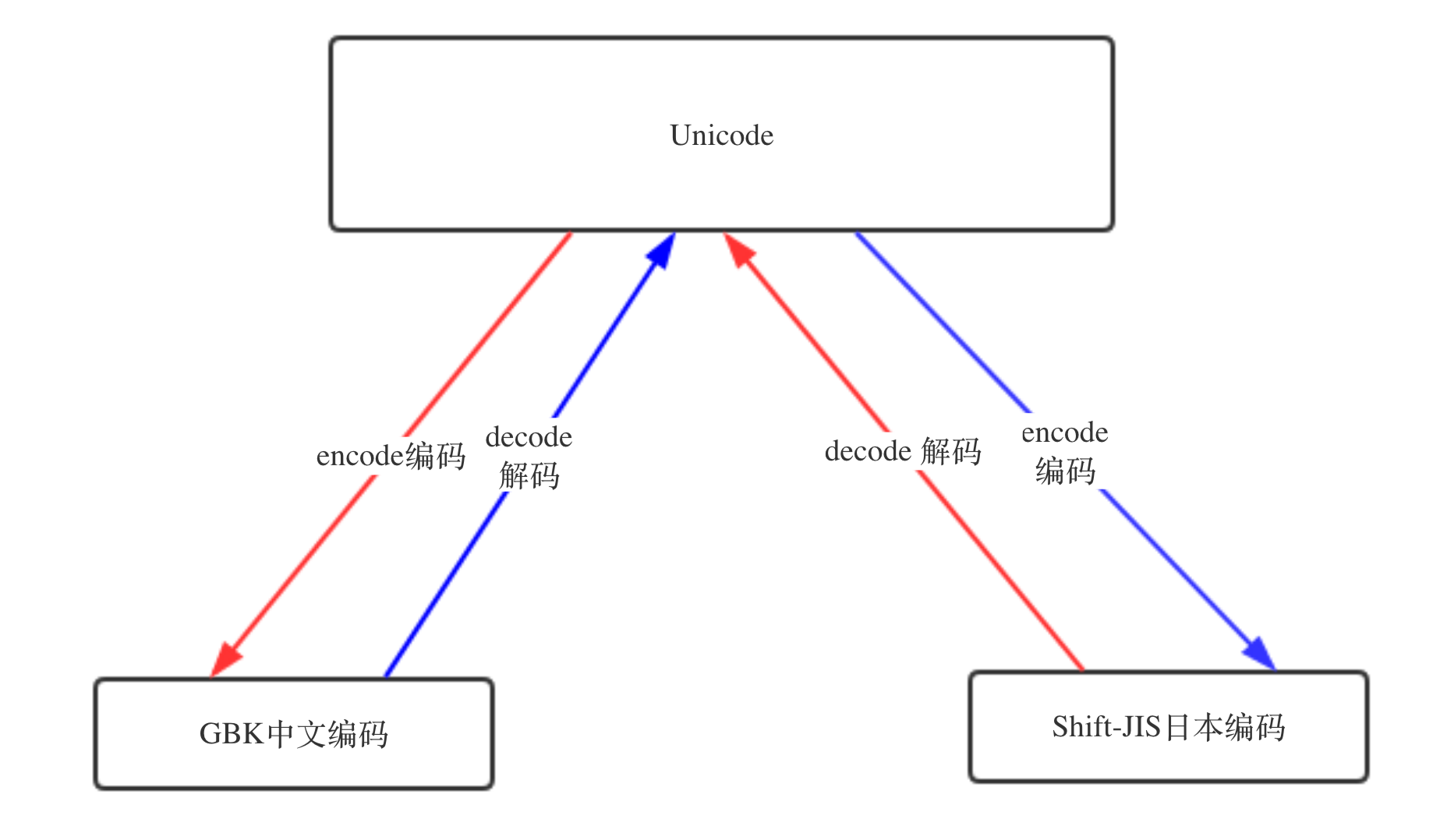
既然Python2并不会自动的把文件编码转为unicode存在内存里, 只能够你自己转。Py3 自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode(编码)
UTF-8 --> decode 解码 --> Unicode
Unicode --> encode 编码 --> GBK / UTF-8 ..
decode示例
encode 示例
编码解码规则
Python只要出现各种编码问题,无非是哪里的编码设置出错了
常见编码错误的原因有:
- Python解释器的默认编码
- Python源文件文件编码
- Terminal使用的编码
- 操作系统的语言设置
掌握了编码之前的关系后,挨个排错就好啦
处理UnicodeEncodeError
多数非 UTF 编解码器只能处理 Unicode 字符的一小部分子集。把文本转换成字节序列时,如果目标编码中没有定义某个字符,那就会抛出UnicodeEncodeError 异常,除非把 errors 参数传给编码方法或函
数,对错误进行特殊处理。
编码成字节序列:成功和错误处理
>>> city = 'São Paulo' >>> city.encode('utf_8') ➊ b'S\xc3\xa3o Paulo' >>> city.encode('utf_16') b'\xff\xfeS\x00\xe3\x00o\x00 \x00P\x00a\x00u\x00l\x00o\x00' >>> city.encode('iso8859_1') ➋ b'S\xe3o Paulo' >>> city.encode('cp437') ➌ Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/.../lib/python3.4/encodings/cp437.py", line 12, in encode return codecs.charmap_encode(input,errors,encoding_map) UnicodeEncodeError: 'charmap' codec can't encode character '\xe3' in position 1: character maps to <undefined> >>> city.encode('cp437', errors='ignore') ➍ b'So Paulo' >>> city.encode('cp437', errors='replace') ➎ b'S?o Paulo' >>> city.encode('cp437', errors='xmlcharrefreplace') ➏ b'São Paulo'
❶ 'utf_?' 编码能处理任何字符串。
❷ 'iso8859_1' 编码也能处理字符串 'São Paulo'。
❸ 'cp437' 无法编码 'ã'(带波形符的“a”)。默认的错误处理方式'strict' 抛出 UnicodeEncodeError。
❹ error='ignore' 处理方式悄无声息地跳过无法编码的字符;这样做通常很是不妥。
❺ 编码时指定 error='replace',把无法编码的字符替换成 '?';数据损坏了,但是用户知道出了问题。
❻ 'xmlcharrefreplace' 把无法编码的字符替换成 XML 实体。
处理UnicodeDecodeError
不是每一个字节都包含有效的 ASCII 字符,也不是每一个字符序列都是有效的 UTF-8 或 UTF-16。因此,把二进制序列转换成文本时,如果假设是这两个编码中的一个,遇到无法转换的字节序列时会抛出
UnicodeDecodeError。另一方面,很多陈旧的 8 位编码——如 'cp1252'、'iso8859_1' 和'koi8_r'——能解码任何字节序列流而不抛出错误,例如随机噪声。因此,如果程序使用错误的 8 位编码,解码过程悄无声息,而得到的是无用输出。
把字节序列解码成字符串:成功和错误处理
>>> octets = b'Montr\xe9al' ➊ >>> octets.decode('cp1252') ➋ 'Montréal' >>> octets.decode('iso8859_7') ➌ 'Montrιal' >>> octets.decode('koi8_r') ➍ 'MontrИal' >>> octets.decode('utf_8') ➎ Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 5: invalid continuation byte >>> octets.decode('utf_8', errors='replace') ➏ 'Montral'
❶ 这些字节序列是使用 latin1 编码的“Montréal”;'\xe9' 字节对应“é”。
❷ 可以使用 'cp1252'(Windows 1252)解码,因为它是 latin1 的有效超集。
❸ ISO-8859-7 用于编码希腊文,因此无法正确解释 '\xe9' 字节,而且没有抛出错误。
❹ KOI8-R 用于编码俄文;这里,'\xe9' 表示西里尔字母“И”。
❺ 'utf_8' 编解码器检测到 octets 不是有效的 UTF-8 字符串,抛出UnicodeDecodeError。
❻ 使用 'replace' 错误处理方式,\xe9 替换成了“ ”(码位是U+FFFD),这是官方指定的 REPLACEMENT CHARACTER(替换字符),表示未知字符。
为了正确比较而规范化Unicode字符串
因为 Unicode 有组合字符(变音符号和附加到前一个字符上的记号,打印时作为一个整体),所以字符串比较起来很复杂。
例如,“café”这个词可以使用两种方式构成,分别有 4 个和 5 个码位,但是结果完全一样:
>>> s1 = 'café' >>> s2 = 'cafe\u0301' >>> s1, s2 ('café', 'café') >>> len(s1), len(s2) (4, 5) >>> s1 == s2 False
U+0301 是 COMBINING ACUTE ACCENT,加在“e”后面得到“é”。在Unicode 标准中,'é' 和 'e\u0301' 这样的序列叫“标准等价物”(canonical equivalent),应用程序应该把它们视作相同的字符。但
是,Python 看到的是不同的码位序列,因此判定二者不相等。
这个问题的解决方案是使用 unicodedata.normalize 函数提供的Unicode 规范化。这个函数的第一个参数是这 4 个字符串中的一个:'NFC'、'NFD'、'NFKC' 和 'NFKD'。下面先说明前两个。
NFC(Normalization Form C)使用最少的码位构成等价的字符串,而NFD 把组合字符分解成基字符和单独的组合字符。这两种规范化方式都
能让比较行为符合预期:
>>> from unicodedata import normalize >>> s1 = 'café' # 把"e"和重音符组合在一起 >>> s2 = 'cafe\u0301' # 分解成"e"和重音符 >>> len(s1), len(s2) (4, 5) >>> len(normalize('NFC', s1)), len(normalize('NFC', s2)) (4, 4) >>> len(normalize('NFD', s1)), len(normalize('NFD', s2)) (5, 5) >>> normalize('NFC', s1) == normalize('NFC', s2) True >>> normalize('NFD', s1) == normalize('NFD', s2) True
西方键盘通常能输出组合字符,因此用户输入的文本默认是 NFC 形式。不过,安全起见,保存文本之前,最好使用 normalize('NFC',user_text) 清洗字符串。NFC 也是 W3C 的“Character Model for the
World Wide Web: String Matching and Searching”规范形式。
使用 NFC 时,有些单字符会被规范成另一个单字符。例如,电阻的单位欧姆(Ω)会被规范成希腊字母大写的欧米加。这两个字符在视觉上是一样的,但是比较时并不相等,因此要规范化,防止出现意外:
>>> from unicodedata import normalize, name >>> ohm = '\u2126' >>> name(ohm) 'OHM SIGN' >>> ohm_c = normalize('NFC', ohm) >>> name(ohm_c) 'GREEK CAPITAL LETTER OMEGA' >>> ohm == ohm_c False >>> normalize('NFC', ohm) == normalize('NFC', ohm_c) True
在另外两个规范化形式(NFKC 和 NFKD)的首字母缩略词中,字母 K表示“compatibility”(兼容性)。这两种是较严格的规范化形式,对“兼容字符”有影响。虽然 Unicode 的目标是为各个字符提供“规范的”码位,但是为了兼容现有的标准,有些字符会出现多次。例如,虽然希腊字母表中有“μ”这个字母(码位是 U+03BC,GREEK SMALL LETTER MU),但是 Unicode 还是加入了微符号 'µ'(U+00B5),以便与 latin1 相互转换。因此,微符号是一个“兼容字符”。在 NFKC 和 NFKD 形式中,各个兼容字符会被替换成一个或多个“兼容分解”字符,即便这样有些格式损失,但仍是“首选”表述——理想情况下,格式化是外部标记的职责,不应该由 Unicode 处理。下面举个例子。二分之一 '½'(U+00BD)经过兼容分解后得到的是三个字符序列'1/2';微符号 'µ'(U+00B5)经过兼容分解后得到的是小写字母'μ'(U+03BC)
>>> from unicodedata import normalize, name >>> half = '½' >>> normalize('NFKC', half) '1⁄2' >>> four_squared = '4²' >>> normalize('NFKC', four_squared) '42' >>> micro = 'μ' >>> micro_kc = normalize('NFKC', micro) >>> micro, micro_kc ('μ', 'μ') >>> ord(micro), ord(micro_kc) (181, 956) >>> name(micro), name(micro_kc) ('MICRO SIGN', 'GREEK SMALL LETTER MU')
使用 '1/2' 替代 '½' 可以接受,微符号也确实是小写的希腊字母'µ',但是把 '4²' 转换成 '42' 就改变原意了。某些应用程序可以把'4²' 保存为 '4<sup>2</sup>',但是 normalize 函数对格式一无所
知。因此,NFKC 或 NFKD 可能会损失或曲解信息,但是可以为搜索和索引提供便利的中间表述:用户搜索 '1 / 2 inch' 时,如果还能找到包含 '½ inch' 的文档,那么用户会感到满意
使用 NFKC 和 NFKD 规范化形式时要小心,而且只能在特
殊情况中使用,例如搜索和索引,而不能用于持久存储,因为这两
种转换会导致数据损失。
大小写折叠
大小写折叠其实就是把所有文本变成小写,再做些其他转换。这个功能
由 str.casefold() 方法(Python 3.3 新增)支持。
对于只包含 latin1 字符的字符串 s,s.casefold() 得到的结果与
s.lower() 一样,唯有两个例外:微符号 'µ' 会变成小写的希腊字
母“μ”(在多数字体中二者看起来一样);德语 Eszett(“sharp s”,ß)
会变成“ss”。
>>> micro = 'μ' >>> name(micro) 'MICRO SIGN' >>> micro_cf = micro.casefold() >>> name(micro_cf) 'GREEK SMALL LETTER MU' >>> micro, micro_cf ('μ', 'μ') >>> eszett = 'ß' >>> name(eszett) 'LATIN SMALL LETTER SHARP S' >>> eszett_cf = eszett.casefold() >>> eszett, eszett_cf ('ß', 'ss')
自 Python 3.4 起,str.casefold() 和 str.lower() 得到不同结果的有
116 个码位。Unicode 6.3 命名了 110 122 个字符,这只占 0.11%。
与 Unicode 相关的任何问题一样,大小写折叠是个复杂的问题,有很多
语言上的特殊情况,但是 Python 核心团队尽力提供了一种方案,能满足
大多数用户的需求。
转自https://www.cnblogs.com/alex3714/articles/7550940.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号