随机森林总结
根据分类器数目的多少,分类计数可分为单分类器技术和多分类器技术。单分类器技术中比较有代表性的是贝叶斯和决策树。多分类器组合思想起源于 集成学习算法。继承学习算法是机器学习的一种新的学习思想,该学习算法把同一个问题分解到多个不同的模块中,由多个学习器一起学习,共同解决 目标问题,从而提高分类器的泛化能力。将集成学习算法应用到数据挖掘的数据分类领域,最早是boosting和bagging。 一、Bootstrap 非参数统计中的一种重要的估计统计量方差进而进行区间估计的统计方法,也称自助法,其核心思想和基本步骤如下: 1.采用重采样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复采样。 2.根据抽出的样本计算给定的统计量。 3.重复1和2步骤N次,得到N个统计量。 4.计算上述N个统计量的样本方差,得到统计量的方差。 例子 想要知道池塘里有多少条鱼。可先抽取N条,做上记号,放回池塘。进行重复抽样,抽取M次,每次N条,考察每次抽到鱼中标有记号的比例,在 进行统计量的计算。 二、随机森林研究概况 为克服决策树的缺点,结合单分类器组成多分类器的思想很容易想到,也即:生成多棵决策树,这些决策树都有很高的分两类精度,并让所有决策树 通过投票的形式进行决策,这就像多个专家一起开会讨论,最后举手表决一样。这就是随机森林的核心思想:多个弱分类器组成一个强分类器。 RF是利用Bootstrap进行重抽样的组合分类器,本质是Bagging和Random Subspace的组合。理论和实证表明RF具有 1.高预测率 2.不易过拟合 3.容忍异常和噪声。 理论界就随机森林整体性能的优化主要分以下三方面: 1.引入新算法进行优化 2.将数据预处理融入RF 3.针对RF自身构建过程进行优化 三、训练集产生 每棵决策树都对应一个训练子集,要构建n棵决策树,就需要产生对应数量的训练子集,从 原始训练集中生成n个训练子集就涉及到统计抽样技术。 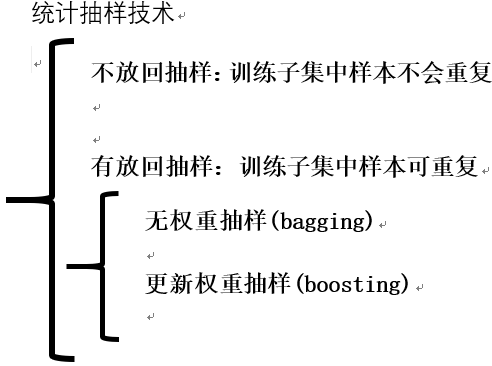 采用bagging或bootstrap生成训练集,子集中存在一定重复,可避免陷入局部最后。每个训练子集大小约为原始集的2/3. 四、随机特征变量的选取 随机特征变量是指RF算法在生成过程中,参与节点分裂特征比较的个数。由于RF在进行节点分裂时,不是所有特征都参与特征指标的计算,而是随机的 选择某几个特征参与比较,参与的个数称为随机特征变量。随机特征变量是为了使每棵树之间的相关性减少,同时提升每棵树的分类精度,从而提升整个 森林的性能而引入的。 在RF中,随机特征变量的产生方法主要有: 1.随机选择输入变量(Forest-RI),对于输入变量随机分组(每组变量的个数是一个定值),然后对于每组变量,利用CART算法产生一棵树,并让其充分 生长,不剪枝。 2.随机组合输入变量(Forest-RC)先将随机特征进行线性组合,然后再作为输入变量来构建RF。 五、随机森林工作过程
采用bagging或bootstrap生成训练集,子集中存在一定重复,可避免陷入局部最后。每个训练子集大小约为原始集的2/3. 四、随机特征变量的选取 随机特征变量是指RF算法在生成过程中,参与节点分裂特征比较的个数。由于RF在进行节点分裂时,不是所有特征都参与特征指标的计算,而是随机的 选择某几个特征参与比较,参与的个数称为随机特征变量。随机特征变量是为了使每棵树之间的相关性减少,同时提升每棵树的分类精度,从而提升整个 森林的性能而引入的。 在RF中,随机特征变量的产生方法主要有: 1.随机选择输入变量(Forest-RI),对于输入变量随机分组(每组变量的个数是一个定值),然后对于每组变量,利用CART算法产生一棵树,并让其充分 生长,不剪枝。 2.随机组合输入变量(Forest-RC)先将随机特征进行线性组合,然后再作为输入变量来构建RF。 五、随机森林工作过程 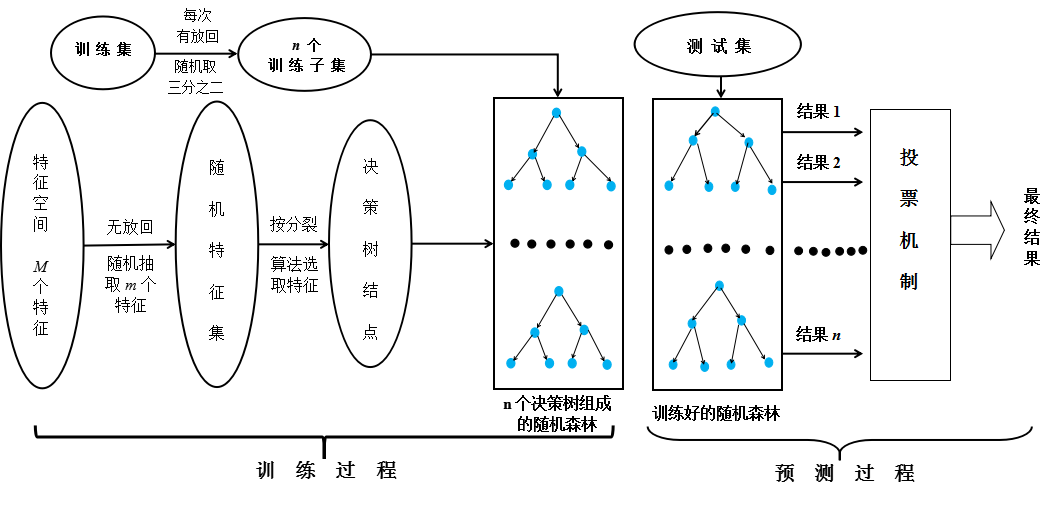 六、随机性的体现 1.训练集随机选取 2.随机特征变量的随机性 3.节点分裂时选择最优特征时随机的。 七、随机森林的优点 1.数据集上表现良好 2.在当前的很多数据集上,相对其它算法有很大优势。 3.能处理高维(特征很多)数据,且不用做特征选择。 4.训练后,能给出哪些特征比较重要。 5.创建森林时,对泛化误差使用无偏估计 6.训练速度快 7.易并行化 8.实现简单 9.训练过程中,能检测到特征间的互相影响。
六、随机性的体现 1.训练集随机选取 2.随机特征变量的随机性 3.节点分裂时选择最优特征时随机的。 七、随机森林的优点 1.数据集上表现良好 2.在当前的很多数据集上,相对其它算法有很大优势。 3.能处理高维(特征很多)数据,且不用做特征选择。 4.训练后,能给出哪些特征比较重要。 5.创建森林时,对泛化误差使用无偏估计 6.训练速度快 7.易并行化 8.实现简单 9.训练过程中,能检测到特征间的互相影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号