@String对象的那些事,几行代码就解释得清清楚楚
String是Java中十分常用的类,在面试题中也是出镜率很高的常客,本文将我自己学习中遇到的一些问题进行整理,如果有误,欢迎指正。
String对象判等
千万不要用 == 去判断String对象是否相等,==比较的是地址。JVM只会共享字符串常量,因此,即使是“看起来”值相同的字符串,用==判断也可能不相等。
举例来说,下面这段代码中,变量x和y都指向了常量池中共享的"a",地址相同,但是z是Java堆中的新建对象的引用,其地址与x不同,所以返回了false。
并且每次new一个String对象时,即使字符串内容相同,也会新开辟一片空间存储对象,因此z和zCopy地址也是不用的。
这部分的细节原理在下一部分中解释。总而言之,如果你只是想判断两个String对象的内容是否一样,请使用x.equals(z)的形式。
代码一
String x = "a";
String y = "a";
String z = new String("a");
String zCopy = new String("a");
System.out.println(x==y);//true
System.out.println(x==z);//false
System.out.println(z==zCopy);//falseString与常量池
我们在给String类型的引用赋值的时候会先看常量池中是否存在这个字符串对象的引用,若有就直接返回这个引用,若没有,就在堆里创建这个字符串对象并在字符串常量池中记录下这个引用。
注意:常量池中存放的是引用,并不是实例!!!
下面结合具体代码来理解这段话,看下面这段代码
代码二
String x = "a";
String y = "a" + "b";
String z = "a";用javap -v -c对.class文件进行反编译后,得到如下结果
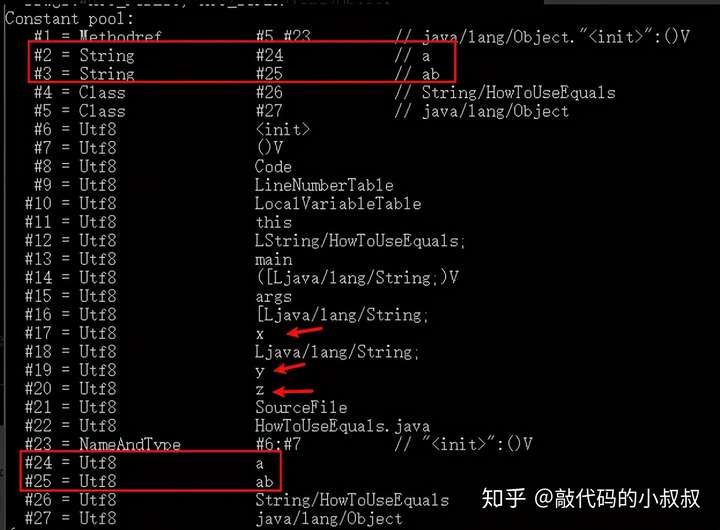
可以看到,常量池中最中只保留了一份"a"的引用。因为在String z = "a";执行时,字符串常量池中已经有"a"的引用了,不会重复创建。
同时我们注意到,对应String y = "a" + "b";这条语句,因为"a"和"b"都是编译器就能确定的常量,所以常量池只保留了最终计算的结果,并没有单独保留"b"。
我们将代码稍作修改,然后再次反编译。
代码三
String witcher = "Geralt";
String sorceress = "Yennefer";
String date = witcher + sorceress;
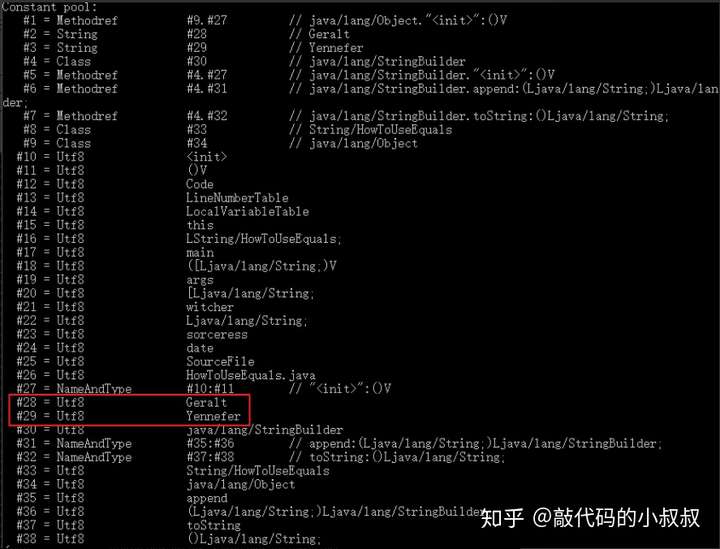
可以看出,最终常量池只存储了"Geralt"和"Yennefer"两个引用,而没有存放拼接的结果。因为witcher和sorceress变量要运行时才能确定。但是如果将变量witcher和sorceress都声明为final,那编译期就可以确定,因此拼接结果的引用信息也会放入常量池。
总结:
对于字符串表达式而言
1、对于编译期能直接确定的值(字面量、声明为final的变量),会直接将表达式的结果放入常量池。
2、如果编译期不能直接直接确定(非final的变量),那么只将已经声明字符串字面常量放入常量池,表达式的结果不放入常量池。
关于常量池的更多介绍欢迎查看我的另一篇博客一张图秒懂JVM内存区域的划分
另一个出镜率很高的问题是如下的这段代码创建了几个对象?
String s = new String("xyz");关于这个问题网上众说纷纭,这里放上一种比较靠谱的说法。参考自R神的博客请别再拿“String s = new String("xyz");创建了多少个String实例”来面试了吧
首先,换个问法,这段代码在运行时涉及几个String实例?
一种合理的解释是:两个,一个是字符串字面量"xyz"所对应的、驻留(intern)在一个全局共享的字符串常量池中的实例,另一个是通过new String(String)创建并初始化的、内容与"xyz"相同的实例。
StringBuilder与StringBuffer
如果你查看过源码,就会发现String对象是被final修饰的,这意味着它是不可变的。因此,当我们拼接字符串时,会产生新的对象。为此,设计者们提供了StringBuilder类来避免产生过多的中间对象。当我们用+拼接字符串时,编译器会自动帮我们使用StringBuilder进行优化。
这次使用jad对代码二进行反编译(直接用javap -v也可以,但是使用jad产生的结果更容易看懂)
得到如下结果 可以看到编译器自动为我们使用了StringBuilder
String witcher = "Geralt";
String sorceress = "Yennefer";
String date = (new StringBuilder()).append(witcher).append(sorceress).toString();有人会说,既然编译器已经优化,我们就直接使用+拼接字符串就可以啊,为什么还要用StringBuilder?
来看这段代码
代码四
String witcher = "Geralt";
String sorceress = "Yennefer";
String res = "";
for (int i = 0; i < 8; i++) {
res += sorceress;
}对其反编译,可得
String witcher = "Geralt";
String sorceress = "Yennefer";
String res = "";
for(int i = 0; i < 8; i++)
res = (new StringBuilder()).append(res).append(sorceress).toString();可以看出,每一轮的for循环都新建了一个StringBuilder,这是完全没有必要的。因此,我们应该在for循环外部先定义一个StringBuilder对象,这样只新建了一个对象就完成了任务,效率大增。
StringBuffer和StringBuilder基本相同,但是它保证了线程安全,如果有多线程需求,可以按需使用。
String.intern()
我们用下面这段代码来分析intern的作用
代码五
String witcher1 = new String("Geralt");
String witcher2 = "Geralt";
System.out.println(witcher1 == witcher2);//false
System.out.println(witcher1.intern() == witcher2);//true第三行显然是false,这在本文最开始已经解释过。
但是witcher1调用intern之后,地址就与witcher2相同了,这是为什么?
原来,当一个对象调用intern方法时,会查看常量池是否有与当前对象内容相同的字面量,如果有,就直接返回常量池中的引用信息,如果没有,就在常量池中补充当前对象的字面量,然后返回引用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号