docker系列(四) docker的网络模式之外部通信
简介
本篇文章主要给大家讲解,docker的外部通信方式及方案。
跨主机docker网络分类
常见的有以下几种方案:
- host模式: 容器直接使用宿主机的网络,这样天生就可以支持跨主机主机通信。这种方式虽然可以解决跨主机通信问题,但应用场景很有限,容易出现端口冲突,也无法做到隔离网络环境,一个容器崩溃很可能引起整个宿主机的崩溃;
- 端口模式: 通过绑定容器端口到宿主机端口,跨主机通信使用主机IP + 端口的方式访问容器中的服务。显然这种方式仅能支持网络协议栈的4层及以上的应用,并且容器与宿主机紧耦合,很难灵活的处理问题;
- 自定义容器网络: 使用flannel或者calico等第三方sdn工具,为容器构建可以跨主机通信的网络环境。这种方案一般会要求各个宿主机行的docker0网桥的cidr不一样,以避免出现ip冲突的问题,限制容器在宿主机上的ip范围。并且在容器需要对外提供服务时,进行较为复杂的配置,对部署实施人员网络技能要求比较高。
- 直接容器方式通信:什么第三方软件也不使用,我们自己将主机间容器网络给打通,好了基于这几种网络方案,后文我们分别进行说明。
容器网络规范
容器网络发展到现在,形成了两大阵营:
- docker的cnm
- google、coreos、kubernetes主导的cni
CNM 和 CNI 是网络规范或者网络体系,并不是网络实现,因此不关心容器的网络实现方式,CNM 和 CNI 关心的只是网络管理。 - cnm(container network model):CNM 的优势在于原生,容器网络和 Docker 容器生命周期结合紧密;缺点是被 Docker “绑架”。支持 CNM 网络规范的容器网络实现包括:Docker Swarm overlay、Macvlan & IP networkdrivers、Calico、Contiv、Weave等。
- CNI(Container Netork Interface):CNI 的优势是兼容其他容器技术(rkt)以及上层的编排系统(Kubernetes&Mesos)、而且社区活跃势头迅猛;缺点是非 Docker 原生。支持 CNI 的网络规范的容器网络实现包括:Kubernetes、Weave、Macvlan、Calico、Flannel、Contiv、Mesos CNI,因为它们都实现了 CNI 规范,用户无论选择哪种方案,得到的网络模型都一样,即每个 Pod 都有独立的 IP,可以直接通信。区别在于不同方案的底层实现不同,有的采用基于 VxLAN 的 Overlay 实现,有的则是 Underlay,性能上有区别。再有就是是否支持 Network Policy。
docker网络跨主机通信之自定义网络
静态路由
路由拓扑图规划:
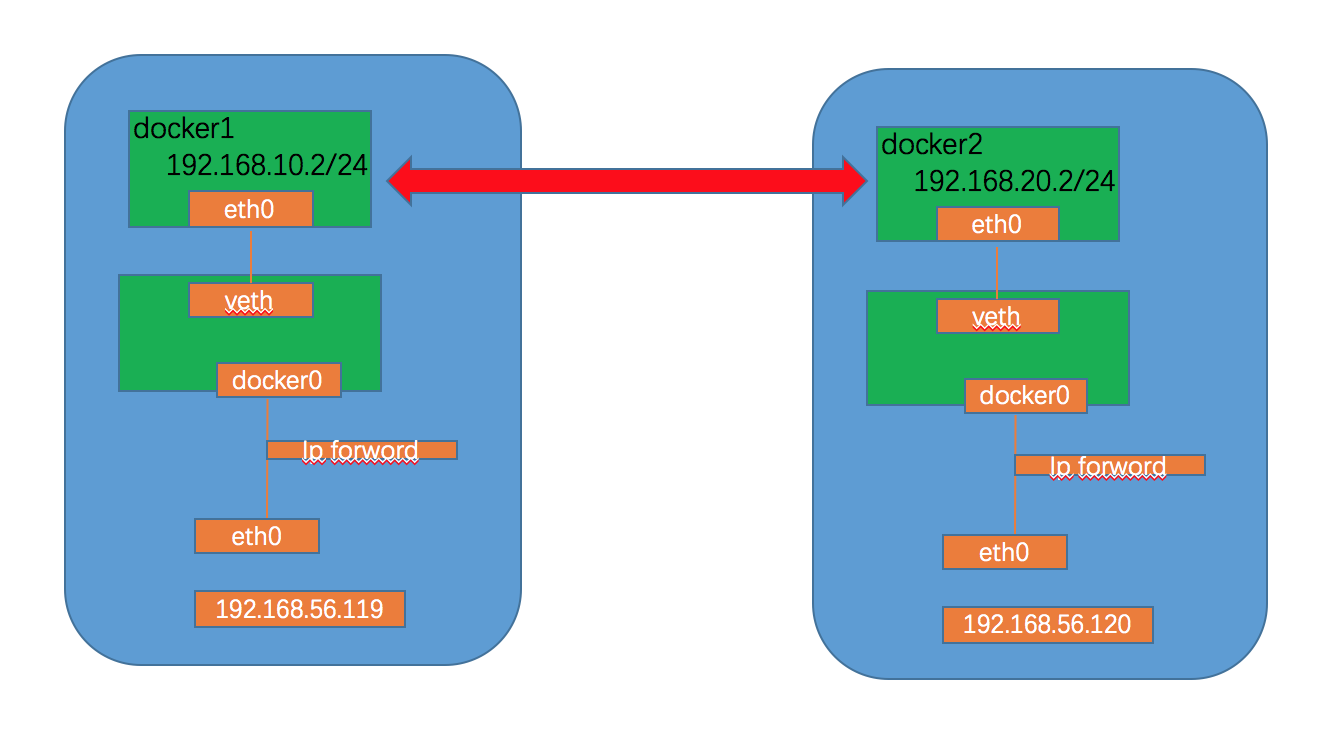
此时两台主机上的container如何通信呢?首先尽心ip地址规划,防止两个机器上的docker地址冲突。
- 主机1的IP地址为192.168.56.119
- 主机2的ip地址为192.168.56.120
- 为主机1上的docker容器分配的子网: 192.168.10.0/24
- 为主机2上的docker容器分配的子网: 192.168.20.0/24
规划好之后,下面进行实验: - 步骤一:修改docker的启动文件
主机1: 修改docker的配置/etc/docker/daemon.json
{"bip":"192.168.10.1/24"}
主机2: 修改docker的配置文件/etc/docker/daemon.json
{"bip":"192.168.20.1/24"}
- 步骤二:重启docker服务
systemctl restart docker
- 步骤三:添加静态路由
在主机1上添加路由:
route add -net 192.168.20.0 netmask 255.255.255.0 gw 192.168.56.120
在主机2上添加路由:
route add -net 192.168.10.0 netmask 255.255.255.0 gw 192.168.56.119
- 步骤四:docker容器已经可以在主机之间被访问到了。
动态路由
动态路由的配置方式,我有时间给大家补充上。
docker网络跨主机通信之sdn
overlay网络
overlay网络是指在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在IP报文之上的新的数据格式。这样不但能够充分利用成熟的ip路由协议进行数据分发,而且在overlay技术中采用扩展的隔离标识位数,能够突破vlan的4000数量限制,支持高达16M的用户,并且在必要时将广播流量转化为组播流量,避免广播数据泛滥。
flannel是由coreos主导的解决方案,flannel为每一个主机的docker deamon分配一个ip段,通过etcd维护一个跨主机的路由表,容器之间的ip是可以互相连通的,当两个跨主机的容器要通信的时候,会在主机上修改数据包的header,修改目的地址和源地址,经过路由表发送到目标主机后解封。封包的方式,可以支持udp/vxlan/host-gw等,但是如果一个容器要暴露服务,还是需要映射ip到主机侧的。下一篇文章专门讲解overlay网络。
calico网络方案
Calico是个年轻的项目,基于BGP协议.完全通过三层路由实现,对网络不熟悉的同学可能都没有听说过。Calico的目标很大,可以应用在虚机,物理机,容器环境中。在Calico运行的主机上可以看到大量由linux路由组成的路由表,这是calico通过自有组件动态生成和管理的。这种实现并没有使用隧道,没有NAT,导致没有性能的损耗,性能很好,从技术上来看是一种很优越的方案。这样做的好处在于,容器的IP可以直接对外部访问,可以直接分配到业务IP,而且如果网络设备支持BGP的话,可以用它实现大规模的容器网络。但BGP带给它的好处的同时也带给他的劣势,BGP协议在企业内部还很少被接受,企业网管不太愿意在跨网络的路由器上开启BGP协议。
docker网络跨主机通信之实际案例
实际情况
- 网络组人力不足以维护一个overlay网络,overlay网络出问题排查复杂,会出现失控情况
- 隧道技术影响性能,不能满足生产环境对网络性能的要求
- 开启bgp对现有网络改动太大,无法接受
- 运维组同学希望能够通过网络桥接的方案解决容器网络
解决方案
除了上面的flannel和calico等解决方案之外我们还可以使用的网络解决方案,供大家参考。
解决方案一
基于docker的bridge模式,将默认的docker bridge替换为linux bridge网络,将linux bridge的网段的ip加入到容器里,实现容器与传统环境应用的互通;
实现思路很简介清晰;
1、首先在该主机上添加一个linux bridge,把主机网卡加入bridge里面,bridge配上网卡原本的管理ip;
2、创建一个新的docker bridge网络,指定bridge子网,并将该网络的网桥绑定到上一步创建的网桥上;
3、每个机器上单独分一个网段进行配置,然后在我们的路由层加一条路由到某个网段的路由的下一跳是我的某个物理机的网卡ip;这样我每添加一台物理机就需要自己添加一条到这个物理机的静态路由在我的网络层里面。
解决方案二
1、步骤一和步骤二同解决方案一;
2、步骤三的时候使用ospf或者bgp的动态路由方案进行解决,每个机器上面启动ospf或者bgp进行全网无脸
总结
网络方案搞定,我们要做的还有很多,比如dns问题,怎么让这些服务动态发现等,欢迎关注下一篇文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号