re正则匹配模块_python
一、re模块
1、模块功能
通过re模块的接口接入正则表达式语言,主要用于匹配字符串。
2、正则表达式元字符以及意义
. 代表任意一个字符(除了换行符\n)
^ 以什么开头
$ 以什么结尾
* 重复匹配*前面的字符出现0到多次 【0,正无穷】
+ 重复匹配+前面的字符1到多次【1,正无穷】
? 重复匹配?前面的字符0或1次【0,1】
{数字} 代表前面的匹配次数,如'b{3}'
{数字n,数字m} 代表前面的匹配次数n次到m次
"|" 或
'(abc){2}' 将abc括成一个整体,分组匹配
[] 代表字符集中的字符,或的关系,如'[a-z]',还有取消元字符意义的特殊功能,
如'[^123]',^放在[]里的最前面,代表取反。
如[1-5],-放在[]里面,代表一个范围
\与普通字符,代表一定意义如[\d],具体代表意义如下;(但\与特殊自字符,取消特殊性,如[\^])
\d 匹配所有的数字,相当于[0-9]
\D 匹配非数字字符,相当于[^0-9]
\w 匹配数字字母下划线,相当于[0-9a-zA-Z_]
\W 匹配非数字字母下划线,相当于[^0-9a-zA-Z_]
\s 匹配任意空白符(空格,换行,回车,换页制表符)相当于[ \f\n\r\t]
\S 匹配任意非空白符,相当于[^ \f\n\r\t]
\A 匹配字符串开始,和^区别:\A只匹配行首,在re.M下也不匹配他行行首
\Z 匹配字符串结束,和$区别:\Z只匹配结束,在re.M下也不匹配他行结束
\b 匹配单词的边界,空格之间
\B 匹配非单词的边界,空格之间
() 做分组,弄成整体字符组进行匹配,如'(bs)'
添加组名分组:根据组名查出

查找网址的例子:
import re
print(re.findall('www.(\w+).com',"www.baidu.com")) #['baidu'],得出中间结果
print(re.findall('www.(?:\w+).com',"www.baidu.com")) #['www.baidu.com'],得出所有结果
匹配身份证例子:

3、模块的方法
findall():所有结果都返回到一个列表里
search():返回匹配到的第一个对象(object),可以调用group()方法返回结果(常用)
print(re.search('www.(\w+).com',"www.baidu.com").group())
match():只在字符串开始匹配,只匹配开头符不符合。也是返回一个对象,也用group()返回结果。
split() :分割字符串
print(re.split('k+','sdfkwerkryy')) #['sdf', 'wer', 'ryy']
sub("替换前","替换后","替换的字符串",替换多少个(不写默认全部替换))
print(re.sub('chen','peng','chenxiaozanchen',1)) #pengxiaozanchen
compile():提高一点点效率,编译规则,再调用
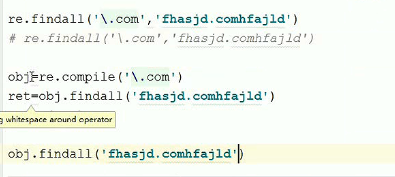
finditer() : 得到的结果不是放到list,而是迭代器


.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号