Python+Faker+Pandas数据库造数
今日分享一些Python常用的东西,整理一些小笔记,比如Faker的使用,panda的使用
一、faker库--造假数据能手
简介
测试工作中,经常会遇到需要制造大量测试数据的时候,如果手动造数据必然会浪费大量时间
Faker是一个制造数据的强大的python库,可以制造姓名、电话、身份证、地址、邮箱等等各种各样伪数据
安装faker
pip install Faker -i http://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
faker的使用
faker可以提供的标准数据:
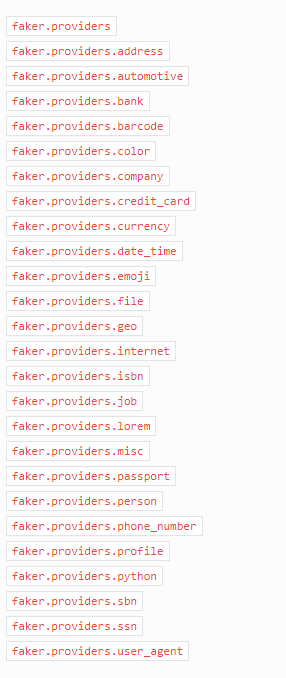
faker在中国可以提供的区域数据:
faker.address
faker.automotive
faker.bank
faker.company
faker.date_time
faker.internet
faker.job
faker.lorem
faker.person
faker.phone_number
faker.ssn
更多内容请参考官方文档:https://faker.readthedocs.io/en/master/
常用的faker库



# coding:utf-8 # author:Achen_blog import csv from faker import Faker def get_data(): # 实例化,传入指定区域代码 fake = Faker(locale='zh_CN') fake_list = [] for i in range(1,11): fake_data = {} name = fake.name() phone = '1279'+ str(i).zfill(7) id_num = fake.ssn() #生成身份证号 fake_data['姓名'] = name fake_data['联系电话'] = phone + '\t' # 字符串+'\t'在写入表格文件打开时,避免自动变成科学计数法 fake_data['身份证号'] = id_num + '\t' fake_list.append(fake_data) return fake_list def write_date(data_list:list): with open('test.csv','w',newline='',encoding='utf-8-sig') as data: FildNames = ['姓名','联系电话','身份证号'] writer = csv.DictWriter(data,fieldnames=FildNames) writer.writeheader() writer.writerows(data_list) data.close() if __name__ == '__main__': data = get_data() write_date(data)

# -*- coding: utf-8 -*- import pandas as pd from faker import Faker import random import numpy as np fake = Faker("zh_CN") # 初始化,可生成中文数据 #设置字段 #index = [] for i in range(1,12): exec('x'+str(i)+'=[]') #设置样本 prod_cd = ['W00028','W00021','W00022'] prod_nm = ['微信支付','银联扫码支付','转账'] channel = ['APP','网银','短信'] year = ['2019','2020','2021'] #循环生成数据20行,具体多少行可以根据需求修改 for i in range(20): date = random.choice(year)+fake.date()[4:] x1.append('1'+str(fake.random_number(digits=8))) # 随机数字,参数digits设置生成的数字位数 x2.append(fake.name()) x3.append(fake.ssn()) # 身份证 x4.append(random.choice('男女')) x5.append(random.randint(18,25)) x6.append(fake.job()) x7.append(random.randint(0,1000000)) x8.append(random.choice(prod_cd)) x9.append(random.choice(prod_nm)) x10.append(random.choice(channel)) x11.append(date) #创建数据表 datas = pd.DataFrame({ 'user_id':x1, 'name':x2, 'ID_card':x3, 'gender':x4, 'age':x5, 'job':x6, 'salary':x7, 'product_id':x8, 'product':x9, 'channel':x10, 'prt_dt':x11 }) #DataFrame类的to_csv()方法输出数据内容,不保存行索引和列名 datas.to_csv(r'C:\Users\ASUS2021\Desktop\customer.csv',encoding='utf-8',index=False,header=None)
二、pandas库--数据挖掘能手 ——读写 分析数据
简介
Pandas 是Python的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具
pandas功能比较强大,这里只简单介绍一下要用的数据读写操作
安装pandas
pip install pandas -i http://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
使用pandas读写数据
csv的读取,读取csv一般用pd.read_csv(),写入csv一般用to_csv()
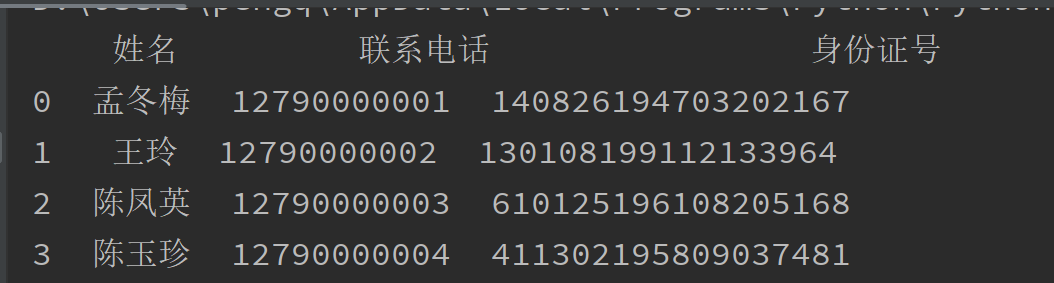
import pandas as pd # 读取csv文件 data = pd.read_csv('test.csv',encoding="utf-8") print(data) # 写入csv文件 data.to_csv('newtest.csv',encoding='utf-8')
默认情况读取csv会自动生成索引,数据行从0开始
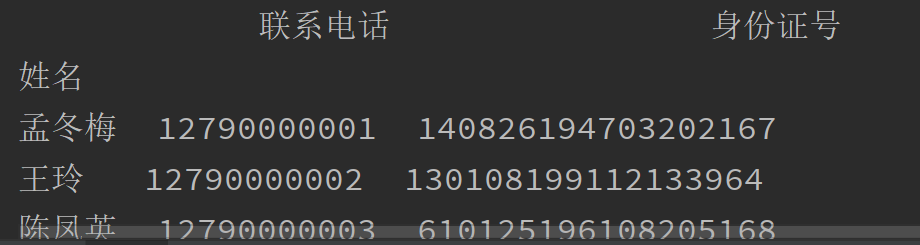
所以可以传入参数,index_col = 0
import pandas as pd # 读取csv文件 data = pd.read_csv('test.csv',encoding="utf-8",index_col=0) print(data) # 写入csv文件 data.to_csv('newtest.csv',encoding='utf-8')
读取的csv返回结果是以列表形式
excel 的读写操作
excel读取采用pd.read_excel,写入则用pd.DataFrame.to_excel
data = pd.read_excel('试点人员名单信息表.xlsx',sheet_name='试点人员名单信息表',index_col=0) print(data)
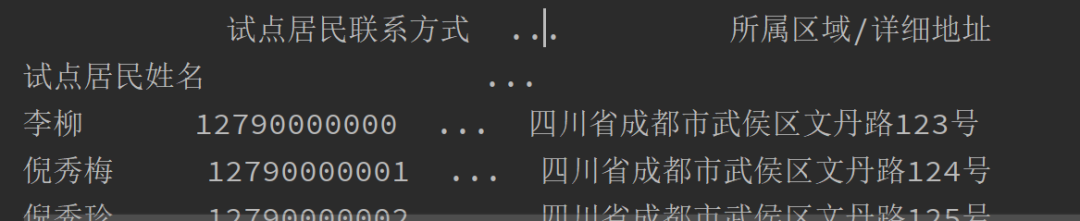
如果不指定sheet_name 默认就是第一个sheet
写入excel
data = pd.read_excel('试点人员名单信息表.xlsx',sheet_name='试点人员名单信息表',index_col=0) # print(data) # 写入excel文档,使用to_excel必须保证文件后缀名为为excel专用后缀 data.to_excel('newexcel.xlsx',sheet_name='test',)
如果要写入多个sheet,就需要生成一个excelwriter对象来传递文件路径,因为直接用to_excel 会覆盖之前的sheet
excel = pd.ExcelWriter('newexcel1.xlsx') # 生成excel对象 data1.to_excel(excel,sheet_name='test1') data2.to_excel(excel,sheet_name='test2') excel.close()
pandas库可以代替冗长的代码
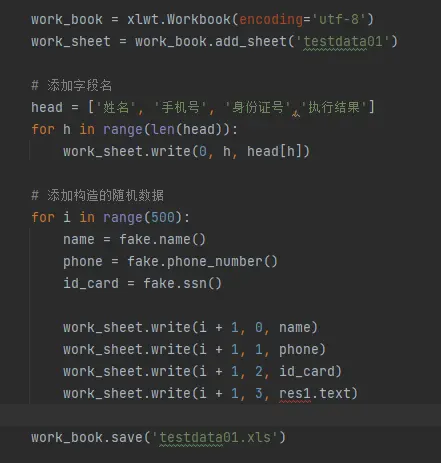
使用pandas库
# list转dataFrame df = pd.DataFrame(data=res, columns=['name', 'phone', 'id_card', 'comp', 'addr', 'bank_card', 'title', 'email']) # 保存到本地excel df.to_excel(file_path, index=False)
三、实例:造注册数据
# 造n条注册好的数据输出到Excel完整j脚本如下: from faker import Faker # 引用faker包 import requests import pandas as pd fake = Faker(locale='zh_CN') def save_to_excel2(file_path, n): res = [] for i in range(n): name = fake.name() phone = fake.phone_number() id_card = fake.ssn() res.append([name, phone, id_card, fake.company(), fake.address(), fake.credit_card_number(), fake.job(), fake.email()]) url = "http://××.×.×.××:××××/api/ideal-new-user/user/register" headers = {"Content-Type": "application/json; charset=utf-8"} data = {"phoneId": phone, "username": name, "idCard": id_card, "password": "a123456"} res1 = requests.post(url,json=data,headers=headers) print(res1.status_code) print(res1.text) # list转dataFrame df = pd.DataFrame(data=res, columns=['name', 'phone', 'id_card', 'comp', 'addr', 'bank_card', 'title', 'email']) # 保存到本地excel df.to_excel(file_path, index=False) save_to_excel2('C:/Users/Administrator/Desktop/test.xls',5)

更多功能以后再分享,大家也可以查阅官方文档
pandas官方文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号