【转】locust-线状图分析
博文转发自:
https://erain-997.github.io/none/2022/05/20/locust%E4%B8%AD%E7%9A%84%E7%BA%BF%E7%8A%B6%E5%9B%BE%E5%88%86%E6%9E%90/
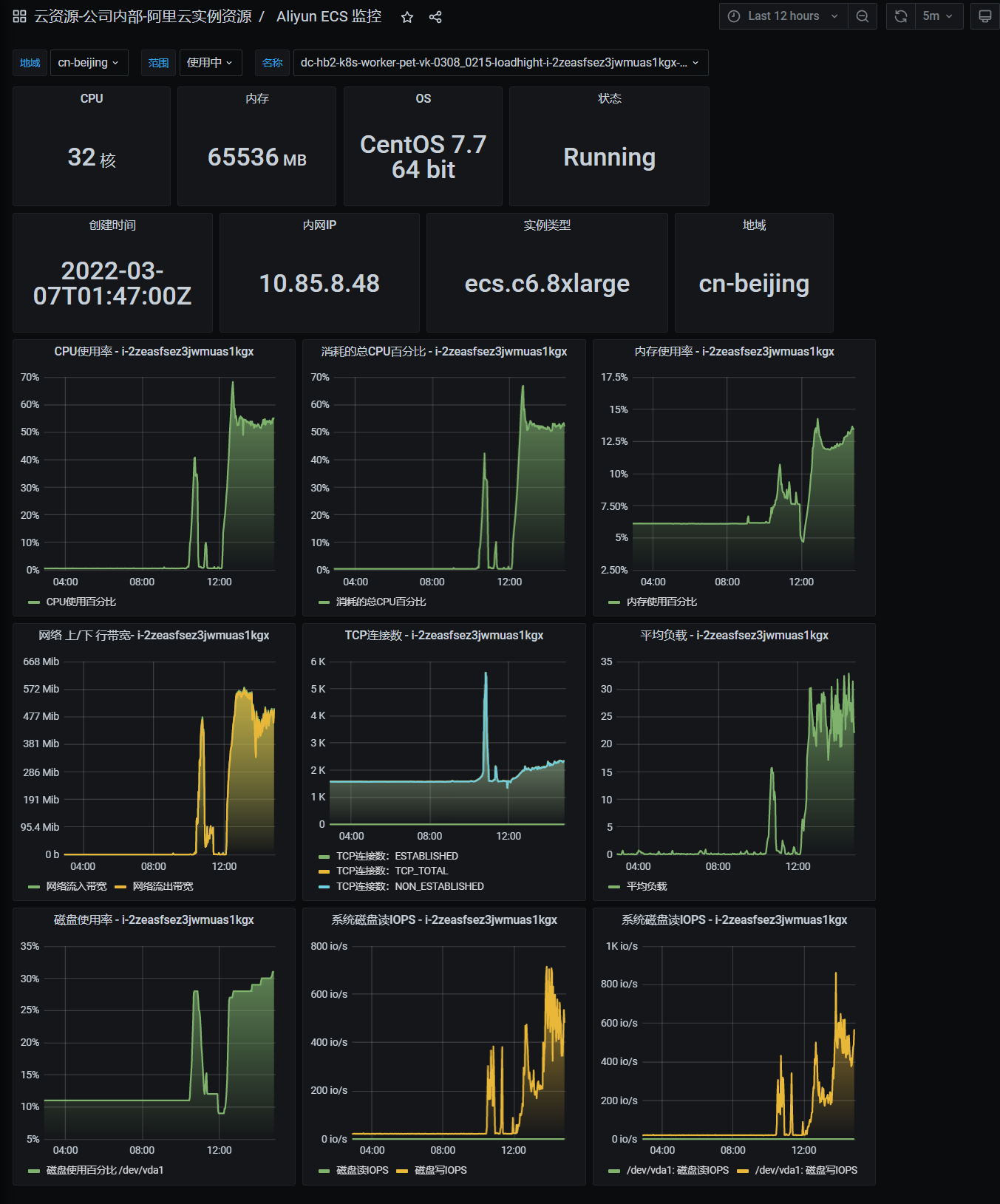
Charts面板说明
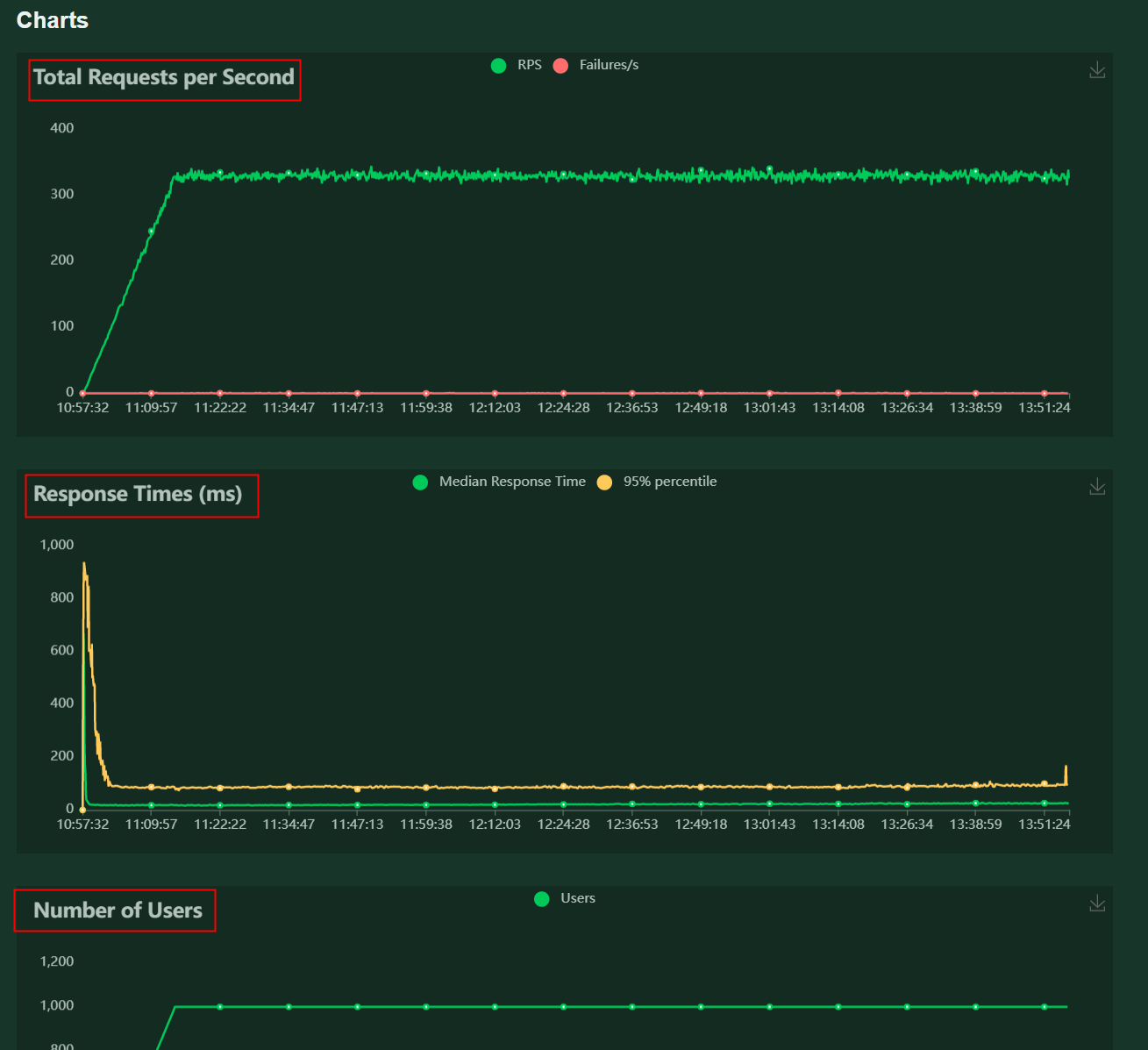
名词定义:
- RPS(Total Requests per Second):每秒发起请求的数量
- RT(Response Times):响应时间(ms)
- PCU(Number of Users):同时在线的虚拟用户数
线状图分析
以下分析以游戏的性能压测为例。
-
如果接口正常响应,在PCU1000时RPS应该在330左右。
预期RPS来源: 压测脚本中每次请求之间有模拟用户思考时间,思考时间在2s~4s随机取值,每个用户平均每隔(3s+Rt)请求一次,如预期RT为平均100ms,则预期RPS=1000/(3+0.1)=332
- 压测启动前期,角色登录与注册以及压测前置作弊器的调用对服务会产生较大压力,所以前期的RT比较高是正常的,目前维京角色的登录耗时在800ms左右,角色注册在500ms左右,所有角色注册登录与前置完成后,目标模块接口的平均RT在300ms以下算合格。RT有两个关注点:
- 稳定的RT,RT不随着压测时间的增加而增加或者有大幅度忽上忽下
- 要关注RT最高值,如果有RT很高的情况存在,虽然最后整次压测的平均RT可能是合格的,但依然有隐患存在
-
PCU如果有下降:
- 检查压测脚本是否panic了,脚本没有正常运行
- 检查运行压测脚本的压力机是否因为某种原因重启了,如果是需要找运维解决
除了分析线状图,还应结合各项负载监控数据进行综合分析,使测试结果更加准确。
案例分析
场景1:RPS骤降
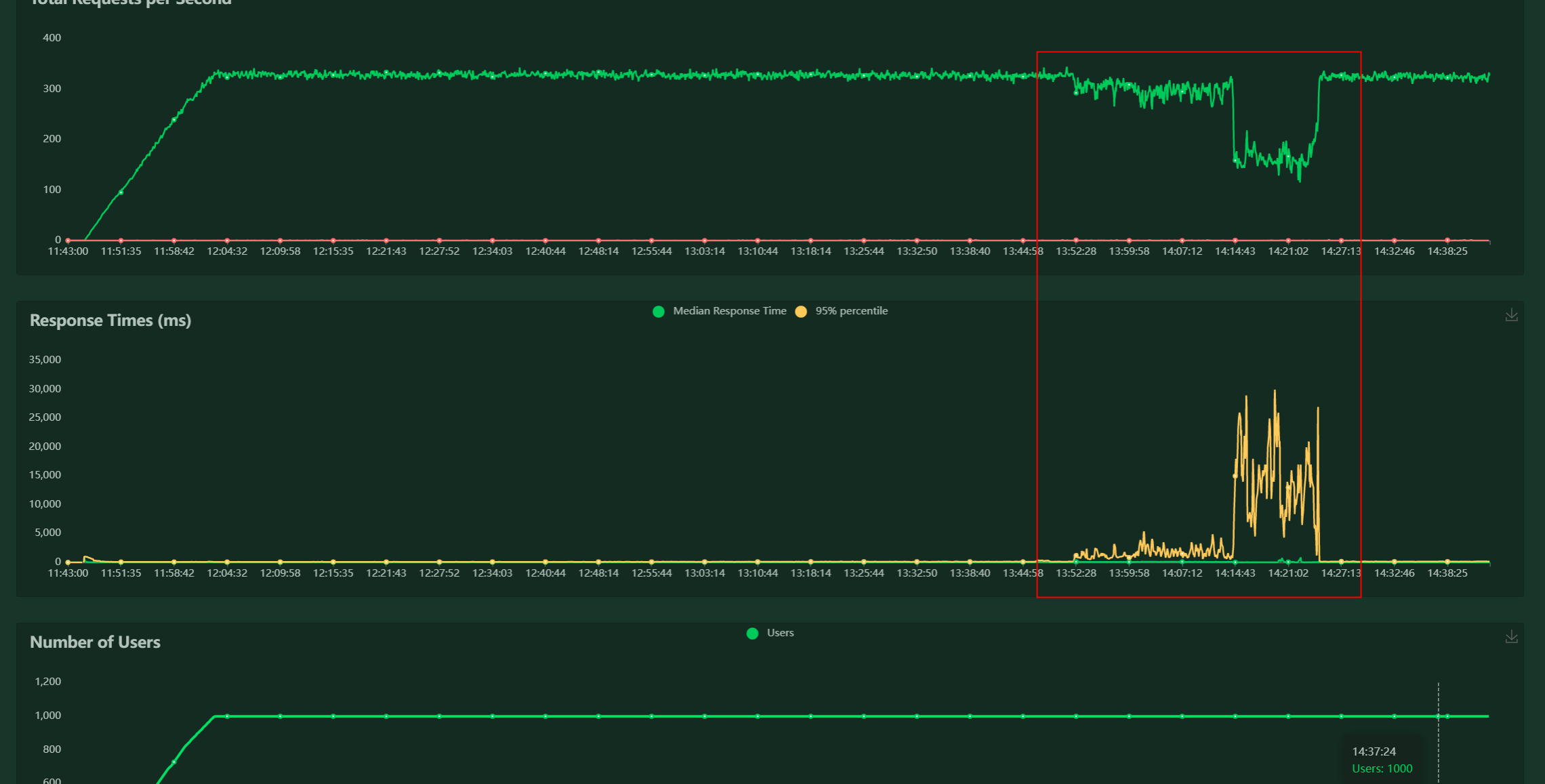
结论:妥妥的被压服务问题
分析:线状图保持了稳定状态一段时间后,RT大幅上升,RPS骤降,RT与RPS的异常波动表明问题极大概率出在被压服务。
问题排查思路
- 配合检查负载监控(如数据库cpu、宿主机cpu等)
- 数据库CPU上升,宿主机也会上升。查询被压服务日志确认问题出现的时间段是否有异常请求,排查一下压测脚本问题,如果脚本没问题,就考虑是被压服务问题,需要提单给对应开发。
- 数据库CPU和宿主机CPU都正常。被压服务业务逻辑有问题,正常请求后被压服务业务处理出现问题。实例:有些接口要被压服务去请求第三方服务来处理业务,但在这个流程中被压服务与第三方服务处理不当,压测时候第三方服务处理不过来了,导致出现响应超时,RPS就掉下来了。
- 按1中的步骤调查不出问题原因,有可能是网络问题。
解决方法:多压几波,如果是网络问题,就是非必现。
场景2:RPS缓慢下降
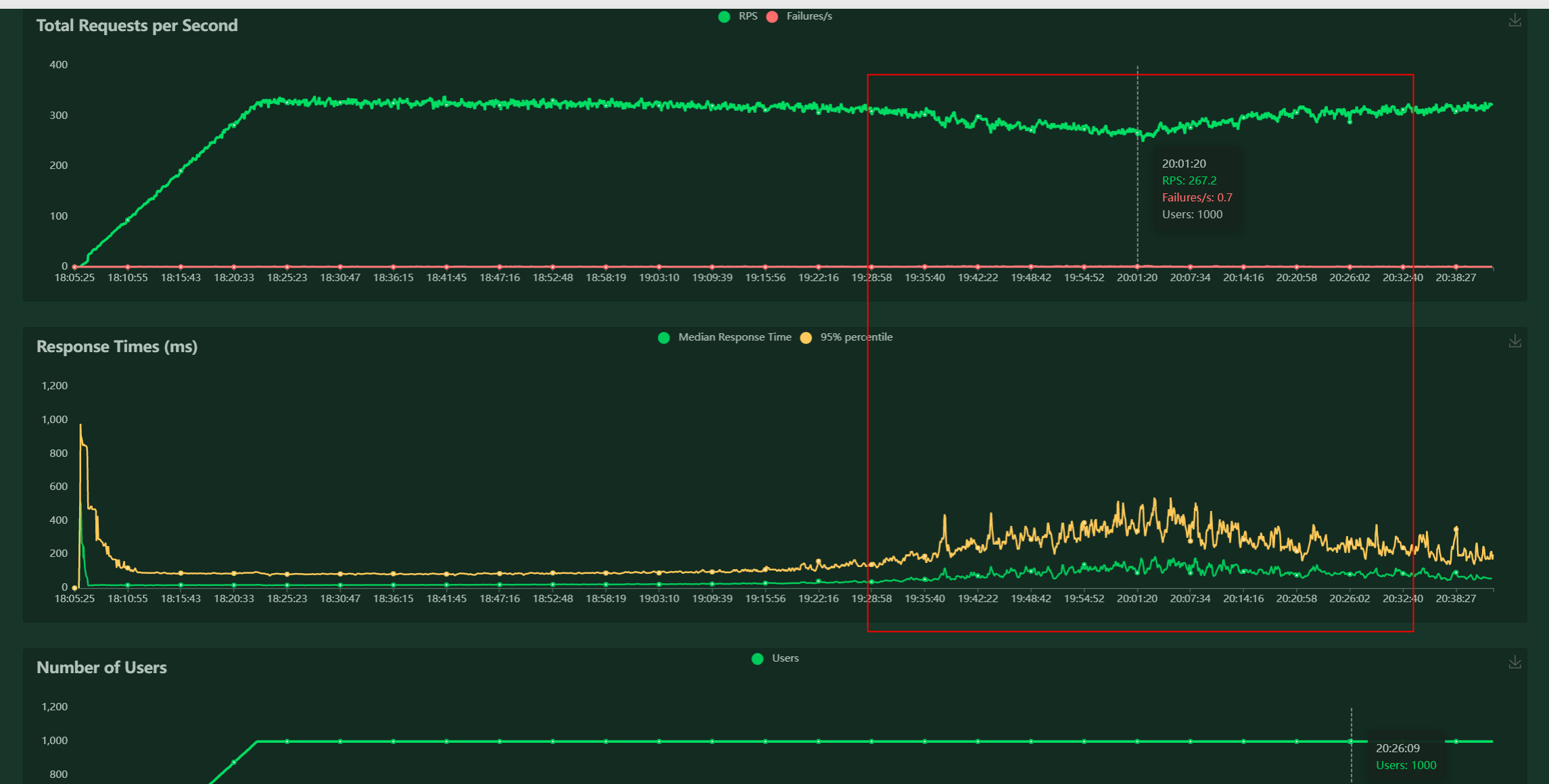 结论:可能有多方面原因,逐步查下各个点:脚本、被压服务、三方服务、数据库
结论:可能有多方面原因,逐步查下各个点:脚本、被压服务、三方服务、数据库
分析:整体体现出RPS逐渐缓慢下降,又逐渐回升的过程,首先怀疑脚本,再者排查数据库,最后是被压服务问题
问题排查思路
-
检查脚本。查询被压服务日志记录,确认该时间段内压测脚本发起的请求时长正常的,如果正常,则怀疑是缺陷,如果是脚本请求不正常,尝试修改压测脚本
-
检查负载。如果发现负载在响应的时间段内有飙升,则调查是否因为负载的上升导致RT高
-
如果脚本、负载都没问题,查日志确认耗时出现在那些步骤
场景3:PCU出现下降
结论:压测脚本或者压力机问题
分析:要么脚本panic了或者脚本把压力机主机搞崩了,要么压力机本身服务有问题
问题排查思路
- 查看压力机控制台打印,看脚本线程有无panic 压力机负载监控,看是否oom(out of memory),是否cpu满了等
- 压力机oom可能是压力机调度、负载均衡问题
- 也可能是脚本内存泄露导致
声明 欢迎转载,但请保留文章原始出处:) 博客园:https://www.cnblogs.com/chenxiaomeng/
如出现转载未声明 将追究法律责任~谢谢合作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号