Node.js(三)node.js的常用内置模块
前言
因为Node.js是运行在服务区端的JavaScript环境,服务器程序和浏览器程序相比,最大的特点是没有浏览器的安全限制了,而且,服务器程序必须能接收网络请求,读写文件,处理二进制内容,所以,Node.js内置的常用模块就是为了实现基本的服务器功能。这些模块在浏览器环境中是无法被执行的,因为它们的底层代码是用C/C++在Node.js运行环境中实现的。
global
在前面的JavaScript课程中,我们已经知道,JavaScript有且仅有一个全局对象,在浏览器中,叫window对象。而在Node.js环境中,也有唯一的全局对象,但不叫window,而叫global,这个对象的属性和方法也和浏览器环境的window不同。进入Node.js交互环境,可以直接输入:
> global.console Console { log: [Function: bound ], info: [Function: bound ], warn: [Function: bound ], error: [Function: bound ], dir: [Function: bound ], time: [Function: bound ], timeEnd: [Function: bound ], trace: [Function: bound trace], assert: [Function: bound ], Console: [Function: Console] }
process
process也是Node.js提供的一个对象,它代表当前Node.js进程。通过process对象可以拿到许多有用信息:
> process === global.process; true > process.version; 'v5.2.0' > process.platform; 'darwin' > process.arch; 'x64' > process.cwd(); //返回当前工作目录 '/Users/michael' > process.chdir('/private/tmp'); // 切换当前工作目录 undefined > process.cwd(); '/private/tmp'
JavaScript程序是由事件驱动执行的单线程模型,Node.js也不例外。Node.js不断执行响应事件的JavaScript函数,直到没有任何响应事件的函数可以执行时,Node.js就退出了。
如果我们想要在下一次事件响应中执行代码,可以调用process.nextTick():
// test.js // process.nextTick()将在下一轮事件循环中调用: process.nextTick(function () { console.log('nextTick callback!'); }); console.log('nextTick was set!');
用Node执行上面的代码node test.js,你会看到,打印输出是:
nextTick was set! nextTick callback!
这说明传入process.nextTick()的函数不是立刻执行,而是要等到下一次事件循环。
Node.js进程本身的事件就由process对象来处理。如果我们响应exit事件,就可以在程序即将退出时执行某个回调函数:
// 程序即将退出时的回调函数: process.on('exit', function (code) { console.log('about to exit with code: ' + code); });
判断JavaScript执行环境
有很多JavaScript代码既能在浏览器中执行,也能在Node环境执行,但有些时候,程序本身需要判断自己到底是在什么环境下执行的,常用的方式就是根据浏览器和Node环境提供的全局变量名称来判断:
if (typeof(window) === 'undefined') { console.log('node.js'); } else { console.log('browser'); }
后面,我们将介绍Node.js的常用内置模块。
一、fs
Node.js内置的fs模块就是文件系统模块,负责读写文件。
和所有其它JavaScript模块不同的是,fs模块同时提供了异步和同步的方法。
回顾一下什么是异步方法。因为JavaScript的单线程模型,执行IO操作时,JavaScript代码无需等待,而是传入回调函数后,继续执行后续JavaScript代码。比如jQuery提供的getJSON()操作:
$.getJSON('http://example.com/ajax', function (data) { console.log('IO结果返回后执行...'); }); console.log('不等待IO结果直接执行后续代码...');
而同步的IO操作则需要等待函数返回:
// 根据网络耗时,函数将执行几十毫秒~几秒不等: var data = getJSONSync('http://example.com/ajax');
同步操作的好处是代码简单,缺点是程序将等待IO操作,在等待时间内,无法响应其它任何事件。而异步读取不用等待IO操作,但代码较麻烦。
异步读文件
按照JavaScript的标准,异步读取一个文本文件的代码如下:
'use strict'; var fs = require('fs'); fs.readFile('sample.txt', 'utf-8', function (err, data) { if (err) { console.log(err); } else { console.log(data); } });
请注意,sample.txt文件必须在当前目录下,且文件编码为utf-8。
异步读取时,传入的回调函数接收两个参数,当正常读取时,err参数为null,data参数为读取到的String。当读取发生错误时,err参数代表一个错误对象,data为undefined。这也是Node.js标准的回调函数:第一个参数代表错误信息,第二个参数代表结果。后面我们还会经常编写这种回调函数。
由于err是否为null就是判断是否出错的标志,所以通常的判断逻辑总是:
if (err) { // 出错了 } else { // 正常 }
如果我们要读取的文件不是文本文件,而是二进制文件,怎么办?
下面的例子演示了如何读取一个图片文件:
'use strict'; var fs = require('fs'); fs.readFile('sample.png', function (err, data) { if (err) { console.log(err); } else { console.log(data); console.log(data.length + ' bytes'); } });
当读取二进制文件时,不传入文件编码时,回调函数的data参数将返回一个Buffer对象。在Node.js中,Buffer对象就是一个包含零个或任意个字节的数组(注意和Array不同)。
Buffer对象可以和String作转换,例如,把一个Buffer对象转换成String:
// Buffer -> String var text = data.toString('utf-8'); console.log(text);
或者把一个String转换成Buffer:
// String -> Buffer var buf = Buffer.from(text, 'utf-8'); console.log(buf);
同步读文件
除了标准的异步读取模式外,fs也提供相应的同步读取函数。同步读取的函数和异步函数相比,多了一个Sync后缀,并且不接收回调函数,函数直接返回结果。
用fs模块同步读取一个文本文件的代码如下:
'use strict'; var fs = require('fs'); var data = fs.readFileSync('sample.txt', 'utf-8'); console.log(data);
可见,原异步调用的回调函数的data被函数直接返回,函数名需要改为readFileSync,其它参数不变。
如果同步读取文件发生错误,则需要用try...catch捕获该错误:
try { var data = fs.readFileSync('sample.txt', 'utf-8'); console.log(data); } catch (err) { // 出错了 }
写文件
将数据写入文件是通过fs.writeFile()实现的:
'use strict'; var fs = require('fs'); var data = 'Hello, Node.js'; fs.writeFile('output.txt', data, function (err) { if (err) { console.log(err); } else { console.log('ok.'); } });
writeFile()的参数依次为文件名、数据和回调函数。如果传入的数据是String,默认按UTF-8编码写入文本文件,如果传入的参数是Buffer,则写入的是二进制文件。回调函数由于只关心成功与否,因此只需要一个err参数。
和readFile()类似,writeFile()也有一个同步方法,叫writeFileSync():
'use strict'; var fs = require('fs'); var data = 'Hello, Node.js'; fs.writeFileSync('output.txt', data);
stat
如果我们要获取文件大小,创建时间等信息,可以使用fs.stat(),它返回一个Stat对象,能告诉我们文件或目录的详细信息:
'use strict'; var fs = require('fs'); fs.stat('sample.txt', function (err, stat) { if (err) { console.log(err); } else { // 是否是文件: console.log('isFile: ' + stat.isFile()); // 是否是目录: console.log('isDirectory: ' + stat.isDirectory()); if (stat.isFile()) { // 文件大小: console.log('size: ' + stat.size); // 创建时间, Date对象: console.log('birth time: ' + stat.birthtime); // 修改时间, Date对象: console.log('modified time: ' + stat.mtime); } } });
运行结果如下:
isFile: true isDirectory: false size: 181 birth time: Fri Dec 11 2015 09:43:41 GMT+0800 (CST) modified time: Fri Dec 11 2015 12:09:00 GMT+0800 (CST)
stat()也有一个对应的同步函数statSync(),请试着改写上述异步代码为同步代码。
异步还是同步
在fs模块中,提供同步方法是为了方便使用。那我们到底是应该用异步方法还是同步方法呢?
由于Node环境执行的JavaScript代码是服务器端代码,所以,绝大部分需要在服务器运行期反复执行业务逻辑的代码,必须使用异步代码,否则,同步代码在执行时期,服务器将停止响应,因为JavaScript只有一个执行线程。
服务器启动时如果需要读取配置文件,或者结束时需要写入到状态文件时,可以使用同步代码,因为这些代码只在启动和结束时执行一次,不影响服务器正常运行时的异步执行
二、stream
stream是Node.js提供的又一个仅在服务区端可用的模块,目的是支持“流”这种数据结构。
什么是流?流是一种抽象的数据结构。想象水流,当在水管中流动时,就可以从某个地方(例如自来水厂)源源不断地到达另一个地方(比如你家的洗手池)。我们也可以把数据看成是数据流,比如你敲键盘的时候,就可以把每个字符依次连起来,看成字符流。这个流是从键盘输入到应用程序,实际上它还对应着一个名字:标准输入流(stdin)。
如果应用程序把字符一个一个输出到显示器上,这也可以看成是一个流,这个流也有名字:标准输出流(stdout)。流的特点是数据是有序的,而且必须依次读取,或者依次写入,不能像Array那样随机定位。
有些流用来读取数据,比如从文件读取数据时,可以打开一个文件流,然后从文件流中不断地读取数据。有些流用来写入数据,比如向文件写入数据时,只需要把数据不断地往文件流中写进去就可以了。
在Node.js中,流也是一个对象,我们只需要响应流的事件就可以了:data事件表示流的数据已经可以读取了,end事件表示这个流已经到末尾了,没有数据可以读取了,error事件表示出错了。
下面是一个从文件流读取文本内容的示例:
'use strict'; var fs = require('fs'); // 打开一个流: var rs = fs.createReadStream('sample.txt', 'utf-8'); rs.on('data', function (chunk) { console.log('DATA:') console.log(chunk); }); rs.on('end', function () { console.log('END'); }); rs.on('error', function (err) { console.log('ERROR: ' + err); });
要注意,data事件可能会有多次,每次传递的chunk是流的一部分数据。
要以流的形式写入文件,只需要不断调用write()方法,最后以end()结束:
'use strict'; var fs = require('fs'); var ws1 = fs.createWriteStream('output1.txt', 'utf-8'); ws1.write('使用Stream写入文本数据...\n'); ws1.write('END.'); ws1.end(); var ws2 = fs.createWriteStream('output2.txt'); ws2.write(new Buffer('使用Stream写入二进制数据...\n', 'utf-8')); ws2.write(new Buffer('END.', 'utf-8')); ws2.end();
所有可以读取数据的流都继承自stream.Readable,所有可以写入的流都继承自stream.Writable。
pipe
就像可以把两个水管串成一个更长的水管一样,两个流也可以串起来。一个Readable流和一个Writable流串起来后,所有的数据自动从Readable流进入Writable流,这种操作叫pipe。
在Node.js中,Readable流有一个pipe()方法,就是用来干这件事的。
让我们用pipe()把一个文件流和另一个文件流串起来,这样源文件的所有数据就自动写入到目标文件里了,所以,这实际上是一个复制文件的程序:
'use strict'; var fs = require('fs'); var rs = fs.createReadStream('sample.txt'); var ws = fs.createWriteStream('copied.txt'); rs.pipe(ws);
默认情况下,当Readable流的数据读取完毕,end事件触发后,将自动关闭Writable流。如果我们不希望自动关闭Writable流,需要传入参数:
readable.pipe(writable, { end: false });
三、http
Node.js开发的目的就是为了用JavaScript编写Web服务器程序。因为JavaScript实际上已经统治了浏览器端的脚本,其优势就是有世界上数量最多的前端开发人员。如果已经掌握了JavaScript前端开发,再学习一下如何将JavaScript应用在后端开发,就是名副其实的全栈了。
HTTP协议
要理解Web服务器程序的工作原理,首先,我们要对HTTP协议有基本的了解。如果你对HTTP协议不太熟悉,先看一看HTTP协议简介。
HTTP服务器
要开发HTTP服务器程序,从头处理TCP连接,解析HTTP是不现实的。这些工作实际上已经由Node.js自带的http模块完成了。应用程序并不直接和HTTP协议打交道,而是操作http模块提供的request和response对象。
request对象封装了HTTP请求,我们调用request对象的属性和方法就可以拿到所有HTTP请求的信息;
response对象封装了HTTP响应,我们操作response对象的方法,就可以把HTTP响应返回给浏览器。
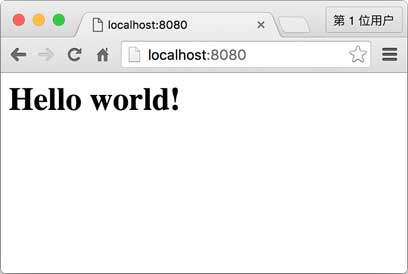
用Node.js实现一个HTTP服务器程序非常简单。我们来实现一个最简单的Web程序hello.js,它对于所有请求,都返回Hello world!:
'use strict'; // 导入http模块: var http = require('http'); // 创建http server,并传入回调函数: var server = http.createServer(function (request, response) { // 回调函数接收request和response对象, // 获得HTTP请求的method和url: console.log(request.method + ': ' + request.url); // 将HTTP响应200写入response, 同时设置Content-Type: text/html: response.writeHead(200, {'Content-Type': 'text/html'}); // 将HTTP响应的HTML内容写入response: response.end('<h1>Hello world!</h1>'); }); // 让服务器监听8080端口: server.listen(8080); console.log('Server is running at http://127.0.0.1:8080/');
在命令提示符下运行该程序,可以看到以下输出:
$ node hello.js Server is running at http://127.0.0.1:8080/
不要关闭命令提示符,直接打开浏览器输入http://localhost:8080,即可看到服务器响应的内容:
同时,在命令提示符窗口,可以看到程序打印的请求信息:
GET: /
GET: /favicon.ico
这就是我们编写的第一个HTTP服务器程序!
文件服务器
让我们继续扩展一下上面的Web程序。我们可以设定一个目录,然后让Web程序变成一个文件服务器。要实现这一点,我们只需要解析request.url中的路径,然后在本地找到对应的文件,把文件内容发送出去就可以了。
解析URL需要用到Node.js提供的url模块,它使用起来非常简单,通过parse()将一个字符串解析为一个Url对象:
'use strict'; var url = require('url'); console.log(url.parse('http://user:pass@host.com:8080/path/to/file?query=string#hash'));
结果如下:
Url { protocol: 'http:', slashes: true, auth: 'user:pass', host: 'host.com:8080', port: '8080', hostname: 'host.com', hash: '#hash', search: '?query=string', query: 'query=string', pathname: '/path/to/file', path: '/path/to/file?query=string', href: 'http://user:pass@host.com:8080/path/to/file?query=string#hash' }
处理本地文件目录需要使用Node.js提供的path模块,它可以方便地构造目录:
'use strict'; var path = require('path'); // 解析当前目录: var workDir = path.resolve('.'); // '/Users/michael' // 组合完整的文件路径:当前目录+'pub'+'index.html': var filePath = path.join(workDir, 'pub', 'index.html'); // '/Users/michael/pub/index.html'
使用path模块可以正确处理操作系统相关的文件路径。在Windows系统下,返回的路径类似于C:\Users\michael\static\index.html,这样,我们就不关心怎么拼接路径了。
最后,我们实现一个文件服务器file_server.js:
'use strict'; var fs = require('fs'), url = require('url'), path = require('path'), http = require('http'); // 从命令行参数获取root目录,默认是当前目录: var root = path.resolve(process.argv[2] || '.'); console.log('Static root dir: ' + root); // 创建服务器: var server = http.createServer(function (request, response) { // 获得URL的path,类似 '/css/bootstrap.css': var pathname = url.parse(request.url).pathname; // 获得对应的本地文件路径,类似 '/srv/www/css/bootstrap.css': var filepath = path.join(root, pathname); // 获取文件状态: fs.stat(filepath, function (err, stats) { if (!err && stats.isFile()) { // 没有出错并且文件存在: console.log('200 ' + request.url); // 发送200响应: response.writeHead(200); // 将文件流导向response: fs.createReadStream(filepath).pipe(response); } else { // 出错了或者文件不存在: console.log('404 ' + request.url); // 发送404响应: response.writeHead(404); response.end('404 Not Found'); } }); }); server.listen(8080); console.log('Server is running at http://127.0.0.1:8080/');
没有必要手动读取文件内容。由于response对象本身是一个Writable Stream,直接用pipe()方法就实现了自动读取文件内容并输出到HTTP响应。
在命令行运行node file_server.js /path/to/dir,把/path/to/dir改成你本地的一个有效的目录,然后在浏览器中输入http://localhost:8080/index.html:

只要当前目录下存在文件index.html,服务器就可以把文件内容发送给浏览器。观察控制台输出:
200 /index.html 200 /css/uikit.min.css 200 /js/jquery.min.js 200 /fonts/fontawesome-webfont.woff2
第一个请求是浏览器请求index.html页面,后续请求是浏览器解析HTML后发送的其它资源请求。
练习
在浏览器输入http://localhost:8080/时,会返回404,原因是程序识别出HTTP请求的不是文件,而是目录。请修改file_server.js,如果遇到请求的路径是目录,则自动在目录下依次搜索index.html、default.html,如果找到了,就返回HTML文件的内容。
var fs = require('fs'); var url = require('url'); var http = require('http'); var path = require('path'); /** forecast.html所在目录(C:\Users\1\Desktop\Prac\demoWeb_Temp\vue-learn\forecast) */ var root = path.resolve(process.argv[2] || '.'); var server = http.createServer(function (request, response){ var pathname = url.parse(request.url).pathname; var filepath = path.join(root, pathname); var defaultPath = ['/default.html', '/forecast.html']; fs.stat(filepath, function (err, stat){ if(!err && stat.isFile()){ console.log("200" + request.url); response.writeHead(200); /** 将文件流导向response */ /**没有必要手动读取文件内容。由于response对象本身是一个Writable Stream, * 直接用pipe()方法就实现了自动读取文件内容并输出到HTTP响应。 */ fs.createReadStream(filepath).pipe(response); }else if(!err && stat.isDirectory()){ for(var i = 0; i < defaultPath.length; i++){ var tempPath = fs.existsSync(path.join(filepath, defaultPath[i])); if(tempPath){ console.log("200" + request.url); response.writeHead(200); fs.createReadStream(path.join(filepath, defaultPath[i])).pipe(response); break; } } }else{ console.log("404" + request.url); response.writeHead(404); response.end("404 Not Found!"); } }); }); server.listen(8080); console.log('Server is running at http://127.0.0.1:8080/');
参考源码
http服务器代码(含静态网站)
四、crypto
crypto模块的目的是为了提供通用的加密和哈希算法。用纯JavaScript代码实现这些功能不是不可能,但速度会非常慢。Nodejs用C/C++实现这些算法后,通过cypto这个模块暴露为JavaScript接口,这样用起来方便,运行速度也快。
MD5和SHA1
MD5是一种常用的哈希算法,用于给任意数据一个“签名”。这个签名通常用一个十六进制的字符串表示:
const crypto = require('crypto'); const hash = crypto.createHash('md5'); // 可任意多次调用update(): hash.update('Hello, world!'); hash.update('Hello, nodejs!'); console.log(hash.digest('hex')); // 7e1977739c748beac0c0fd14fd26a544
update()方法默认字符串编码为UTF-8,也可以传入Buffer。
如果要计算SHA1,只需要把'md5'改成'sha1',就可以得到SHA1的结果1f32b9c9932c02227819a4151feed43e131aca40。
还可以使用更安全的sha256和sha512。
Hmac
Hmac算法也是一种哈希算法,它可以利用MD5或SHA1等哈希算法。不同的是,Hmac还需要一个密钥:
const crypto = require('crypto'); const hmac = crypto.createHmac('sha256', 'secret-key'); hmac.update('Hello, world!'); hmac.update('Hello, nodejs!'); console.log(hmac.digest('hex')); // 80f7e22570...
只要密钥发生了变化,那么同样的输入数据也会得到不同的签名,因此,可以把Hmac理解为用随机数“增强”的哈希算法。
AES
AES是一种常用的对称加密算法,加解密都用同一个密钥。crypto模块提供了AES支持,但是需要自己封装好函数,便于使用:
const crypto = require('crypto'); function aesEncrypt(data, key) { const cipher = crypto.createCipher('aes192', key); var crypted = cipher.update(data, 'utf8', 'hex'); crypted += cipher.final('hex'); return crypted; } function aesDecrypt(encrypted, key) { const decipher = crypto.createDecipher('aes192', key); var decrypted = decipher.update(encrypted, 'hex', 'utf8'); decrypted += decipher.final('utf8'); return decrypted; } var data = 'Hello, this is a secret message!'; var key = 'Password!'; var encrypted = aesEncrypt(data, key); var decrypted = aesDecrypt(encrypted, key); console.log('Plain text: ' + data); console.log('Encrypted text: ' + encrypted); console.log('Decrypted text: ' + decrypted);
运行结果如下:
Plain text: Hello, this is a secret message! Encrypted text: 8a944d97bdabc157a5b7a40cb180e7... Decrypted text: Hello, this is a secret message!
可以看出,加密后的字符串通过解密又得到了原始内容。
注意到AES有很多不同的算法,如aes192,aes-128-ecb,aes-256-cbc等,AES除了密钥外还可以指定IV(Initial Vector),不同的系统只要IV不同,用相同的密钥加密相同的数据得到的加密结果也是不同的。加密结果通常有两种表示方法:hex和base64,这些功能Nodejs全部都支持,但是在应用中要注意,如果加解密双方一方用Nodejs,另一方用Java、PHP等其它语言,需要仔细测试。如果无法正确解密,要确认双方是否遵循同样的AES算法,字符串密钥和IV是否相同,加密后的数据是否统一为hex或base64格式。
Diffie-Hellman
DH算法是一种密钥交换协议,它可以让双方在不泄漏密钥的情况下协商出一个密钥来。DH算法基于数学原理,比如小明和小红想要协商一个密钥,可以这么做:
-
小明先选一个素数和一个底数,例如,素数
p=23,底数g=5(底数可以任选),再选择一个秘密整数a=6,计算A=g^a mod p=8,然后大声告诉小红:p=23,g=5,A=8; -
小红收到小明发来的
p,g,A后,也选一个秘密整数b=15,然后计算B=g^b mod p=19,并大声告诉小明:B=19; -
小明自己计算出
s=B^a mod p=2,小红也自己计算出s=A^b mod p=2,因此,最终协商的密钥s为2。
在这个过程中,密钥2并不是小明告诉小红的,也不是小红告诉小明的,而是双方协商计算出来的。第三方只能知道p=23,g=5,A=8,B=19,由于不知道双方选的秘密整数a=6和b=15,因此无法计算出密钥2。
用crypto模块实现DH算法如下:
const crypto = require('crypto'); // xiaoming's keys: var ming = crypto.createDiffieHellman(512); var ming_keys = ming.generateKeys(); var prime = ming.getPrime(); var generator = ming.getGenerator(); console.log('Prime: ' + prime.toString('hex')); console.log('Generator: ' + generator.toString('hex')); // xiaohong's keys: var hong = crypto.createDiffieHellman(prime, generator); var hong_keys = hong.generateKeys(); // exchange and generate secret: var ming_secret = ming.computeSecret(hong_keys); var hong_secret = hong.computeSecret(ming_keys); // print secret: console.log('Secret of Xiao Ming: ' + ming_secret.toString('hex')); console.log('Secret of Xiao Hong: ' + hong_secret.toString('hex'));
运行后,可以得到如下输出:
$ node dh.js Prime: a8224c...deead3 Generator: 02 Secret of Xiao Ming: 695308...d519be Secret of Xiao Hong: 695308...d519be
注意每次输出都不一样,因为素数的选择是随机的。
RSA
RSA算法是一种非对称加密算法,即由一个私钥和一个公钥构成的密钥对,通过私钥加密,公钥解密,或者通过公钥加密,私钥解密。其中,公钥可以公开,私钥必须保密。
RSA算法是1977年由Ron Rivest、Adi Shamir和Leonard Adleman共同提出的,所以以他们三人的姓氏的头字母命名。
当小明给小红发送信息时,可以用小明自己的私钥加密,小红用小明的公钥解密,也可以用小红的公钥加密,小红用她自己的私钥解密,这就是非对称加密。相比对称加密,非对称加密只需要每个人各自持有自己的私钥,同时公开自己的公钥,不需要像AES那样由两个人共享同一个密钥。
在使用Node进行RSA加密前,我们先要准备好私钥和公钥。
首先,在命令行执行以下命令以生成一个RSA密钥对:
openssl genrsa -aes256 -out rsa-key.pem 2048
根据提示输入密码,这个密码是用来加密RSA密钥的,加密方式指定为AES256,生成的RSA的密钥长度是2048位。执行成功后,我们获得了加密的rsa-key.pem文件。
第二步,通过上面的rsa-key.pem加密文件,我们可以导出原始的私钥,命令如下:
openssl rsa -in rsa-key.pem -outform PEM -out rsa-prv.pem
输入第一步的密码,我们获得了解密后的私钥。
类似的,我们用下面的命令导出原始的公钥:
openssl rsa -in rsa-key.pem -outform PEM -pubout -out rsa-pub.pem
这样,我们就准备好了原始私钥文件rsa-prv.pem和原始公钥文件rsa-pub.pem,编码格式均为PEM。
下面,使用crypto模块提供的方法,即可实现非对称加解密。
首先,我们用私钥加密,公钥解密:
const fs = require('fs'), crypto = require('crypto'); // 从文件加载key: function loadKey(file) { // key实际上就是PEM编码的字符串: return fs.readFileSync(file, 'utf8'); } let prvKey = loadKey('./rsa-prv.pem'), pubKey = loadKey('./rsa-pub.pem'), message = 'Hello, world!'; // 使用私钥加密: let enc_by_prv = crypto.privateEncrypt(prvKey, Buffer.from(message, 'utf8')); console.log('encrypted by private key: ' + enc_by_prv.toString('hex')); let dec_by_pub = crypto.publicDecrypt(pubKey, enc_by_prv); console.log('decrypted by public key: ' + dec_by_pub.toString('utf8'));
执行后,可以得到解密后的消息,与原始消息相同。
接下来我们使用公钥加密,私钥解密:
// 使用公钥加密: let enc_by_pub = crypto.publicEncrypt(pubKey, Buffer.from(message, 'utf8')); console.log('encrypted by public key: ' + enc_by_pub.toString('hex')); // 使用私钥解密: let dec_by_prv = crypto.privateDecrypt(prvKey, enc_by_pub); console.log('decrypted by private key: ' + dec_by_prv.toString('utf8'));
执行得到的解密后的消息仍与原始消息相同。
如果我们把message字符串的长度增加到很长,例如1M,这时,执行RSA加密会得到一个类似这样的错误:data too large for key size,这是因为RSA加密的原始信息必须小于Key的长度。那如何用RSA加密一个很长的消息呢?实际上,RSA并不适合加密大数据,而是先生成一个随机的AES密码,用AES加密原始信息,然后用RSA加密AES口令,这样,实际使用RSA时,给对方传的密文分两部分,一部分是AES加密的密文,另一部分是RSA加密的AES口令。对方用RSA先解密出AES口令,再用AES解密密文,即可获得明文。
证书
crypto模块也可以处理数字证书。数字证书通常用在SSL连接,也就是Web的https连接。一般情况下,https连接只需要处理服务器端的单向认证,如无特殊需求(例如自己作为Root给客户发认证证书),建议用反向代理服务器如Nginx等Web服务器去处理证书。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号