python学习笔记(七)———— 错误、调试和测试
一、错误处理
在程序运行的过程中,如果发生了错误,可以事先约定返回一个错误代码,这样,就可以知道是否有错,以及出错的原因。在操作系统提供的调用中,返回错误码非常常见。比如打开文件的函数open(),成功时返回文件描述符(就是一个整数),出错时返回-1。
用错误码来表示是否出错十分不便,因为函数本身应该返回的正常结果和错误码混在一起,造成调用者必须用大量的代码来判断是否出错:
def foo():
r = some_function()
if r==(-1):
return (-1)
# do something
return r
def bar():
r = foo()
if r==(-1):
print('Error')
else:
pass
一旦出错,还要一级一级上报,直到某个函数可以处理该错误(比如,给用户输出一个错误信息)。
所以高级语言通常都内置了一套 try...except...finally... 的错误处理机制,Python也不例外。
try
让我们用一个例子来看看try的机制:
try:
print('try...')
r = 10 / 0
print('result:', r)
except ZeroDivisionError as e:
print('except:', e)
finally:
print('finally...')
print('END')
当我们认为某些代码可能会出错时,就可以用try来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即except语句块,执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完毕。
上面的代码在计算10 / 0时会产生一个除法运算错误:
try...
except: division by zero
finally...
END
由于没有错误发生,所以except语句块不会被执行,但是finally如果有,则一定会被执行(可以没有finally语句)。
如果发生了不同类型的错误,应该由不同的except语句块处理。没错,可以有多个except来捕获不同类型的错误:
try:
print('try...')
r = 10 / int('a')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
finally:
print('finally...')
print('END')
int()函数可能会抛出ValueError,所以我们用一个except捕获ValueError,用另一个except捕获ZeroDivisionError。
此外,如果没有错误发生,可以在except语句块后面加一个else,当没有错误发生时,会自动执行else语句:
try:
print('try...')
r = 10 / int('2')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
else:
print('no error!')
finally:
print('finally...')
print('END')
Python的错误其实也是class,所有的错误类型都继承自BaseException,所以在使用except时需要注意的是,它不但捕获该类型的错误,还把其子类也“一网打尽”。比如:
try:
foo()
except ValueError as e:
print('ValueError')
except UnicodeError as e:
print('UnicodeError')
第二个except永远也捕获不到UnicodeError,因为UnicodeError是ValueError的子类,如果有,也被第一个except给捕获了。
Python所有的错误都是从BaseException类派生的,常见的错误类型和继承关系看这里:
https://docs.python.org/3/library/exceptions.html#exception-hierarchy
使用try...except捕获错误还有一个巨大的好处,就是可以跨越多层调用,比如函数main()调用bar(),bar()调用foo(),结果foo()出错了,这时,只要main()捕获到了,就可以处理:
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
print('Error:', e)
finally:
print('finally...')
也就是说,不需要在每个可能出错的地方去捕获错误,只要在合适的层次去捕获错误就可以了。这样一来,就大大减少了写try...except...finally的麻烦。
调用栈
如果错误没有被捕获,它就会一直往上抛,最后被Python解释器捕获,打印一个错误信息,然后程序退出。来看看err.py:
# err.py:
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
bar('0')
main()
执行结果:
$ python3 err.py
Traceback (most recent call last):
File "err.py", line 11, in <module>
main()
File "err.py", line 9, in main
bar('0')
File "err.py", line 6, in bar
return foo(s) * 2
File "err.py", line 3, in foo
return 10 / int(s)
ZeroDivisionError: division by zero
出错并不可怕,可怕的是不知道哪里出错了。解读错误信息是定位错误的关键。我们从上往下可以看到整个错误的调用函数链:
错误信息第1行:
Traceback (most recent call last):
告诉我们这是错误的跟踪信息。
第2~3行:
File "err.py", line 11, in <module>
main()
调用main()出错了,在代码文件err.py的第11行代码,但原因是第9行:
File "err.py", line 9, in main
bar('0')
调用bar('0')出错了,在代码文件err.py的第9行代码,但原因是第6行:
File "err.py", line 6, in bar
return foo(s) * 2
原因是return foo(s) * 2这个语句出错了,但这还不是最终原因,继续往下看:
File "err.py", line 3, in foo
return 10 / int(s)
原因是return 10 / int(s)这个语句出错了,这是错误产生的源头,因为下面打印了:
ZeroDivisionError: integer division or modulo by zero
根据错误类型ZeroDivisionError,我们判断,int(s)本身并没有出错,但是int(s)返回0,在计算10 / 0时出错,至此,找到错误源头。
出错的时候,一定要分析错误的调用栈信息,才能定位错误的位置。
记录错误
如果不捕获错误,自然可以让Python解释器来打印出错误堆栈,但程序也被结束了。既然我们能捕获错误,就可以把错误堆栈打印出来,然后分析错误原因,同时,让程序继续执行下去。
Python内置的logging模块可以非常容易地记录错误信息:
# err_logging.py
import logging
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
logging.exception(e)
main()
print('END')
同样是出错,但程序打印完错误信息后会继续执行,并正常退出:
通过配置,logging还可以把错误记录到日志文件里,方便事后排查。
抛出错误
因为错误是class,捕获一个错误就是捕获到该class的一个实例。因此,错误并不是凭空产生的,而是有意创建并抛出的。Python的内置函数会抛出很多类型的错误,我们自己编写的函数也可以抛出错误。
如果要抛出错误,首先根据需要,可以定义一个错误的class,选择好继承关系,然后,用raise语句抛出一个错
误的实例:
(不使用try exception 而是 直接使用raise抛出异常错误)
# err_raise.py
#定义了一个FooError实例 class FooError(ValueError): pass def foo(s): n = int(s) if n==0: raise FooError('invalid value: %s' % s) return 10 / n foo('0')
执行,可以最后跟踪到我们自己定义的错误:
$ python3 err_raise.py
Traceback (most recent call last):
File "err_throw.py", line 11, in <module>
foo('0')
File "err_throw.py", line 8, in foo
raise FooError('invalid value: %s' % s)
__main__.FooError: invalid value: 0
只有在必要的时候才定义我们自己的错误类型。如果可以选择Python已有的内置的错误类型(比如ValueError,TypeError),尽量使用Python内置的错误类型。
最后,我们来看另一种错误处理的方式:
# err_reraise.py
def foo(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
def bar():
try:
foo('0')
except ValueError as e:
print('ValueError!')
raise
bar()
在bar()函数中,我们明明已经捕获了错误,但是,打印一个ValueError!后,又把错误通过raise语句抛出去了,这不有病么?
其实这种错误处理方式不但没病,而且相当常见。捕获错误目的只是记录一下,便于后续追踪。但是,由于当前函数不知道应该怎么处理该错误,所以,最恰当的方式是继续往上抛,让顶层调用者去处理。好比一个员工处理不了一个问题时,就把问题抛给他的老板,如果他的老板也处理不了,就一直往上抛,最终会抛给CEO去处理。
raise语句如果不带参数,就会把当前错误原样抛出。此外,在except中raise一个Error,还可以把一种类型的错误转化成另一种类型:
try:
10 / 0
except ZeroDivisionError:
raise ValueError('input error!')
只要是合理的转换逻辑就可以,但是,决不应该把一个IOError转换成毫不相干的ValueError
from functools import reduce
def str2num(s):
for i in s:
if i == '.':
return float(s)
return int(s)
def calc(exp):
ss = exp.split('+')
ns = map(str2num, ss)
return reduce(lambda acc, x: acc + x, ns)
def main():
try:
r = calc('100 + 200 + 345')
except ValueError as e:
print('Invalid string:',e)
print('100 + 200 + 345 =', r)
try:
r = calc('99 + 88 + 7.6')
except ValueError as e:
print('Invalid string:', e)
print('99 + 88 + 7.6 =', r)
main()
二、调试
程序能一次写完并正常运行的概率很小,基本不超过1%。总会有各种各样的bug需要修正。有的bug很简单,看看错误信息就知道,有的bug很复杂,我们需要知道出错时,哪些变量的值是正确的,哪些变量的值是错误的,因此,需要一整套调试程序的手段来修复bug。
第一种方法简单直接粗暴有效,就是用print()把可能有问题的变量打印出来看看,但是这样会让程序里到处都是print所以我们使用断言
断言
凡是用print()来辅助查看的地方,都可以用断言(assert)来替代:
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
def main():
foo('0')
assert的意思是,表达式n != 0应该是True,否则,根据程序运行的逻辑,后面的代码肯定会出错。
如果断言失败,assert语句本身就会抛出AssertionError:
Traceback (most recent call last):
...
AssertionError: n is zero!
程序中如果到处充斥着assert,和print()相比也好不到哪去。不过,启动Python解释器时可以用-O参数来关闭assert:
$ python -O err.py
Traceback (most recent call last):
...
ZeroDivisionError: division by zero
注意!!这边是英文字母的O 不是 0
关闭后,你可以把所有的assert语句当成pass来看。
在编辑器中只要不运行debug模式则当前不会有断言调试
logging
把print()替换为logging是第3种方式,和assert比,logging不会抛出错误,而且可以输出到文件:
import logging
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)
logging.info()就可以输出一段文本。运行,发现除了ZeroDivisionError,没有任何信息。怎么回事?
别急,在import logging之后添加一行配置再试试:
import logging
logging.basicConfig(level=logging.INFO)
看到输出了:
INFO:root:n = 0
Traceback (most recent call last):
File "err.py", line 8, in <module>
print(10 / n)
ZeroDivisionError: division by zero
这就是logging的好处,它允许你指定记录信息的级别,有debug,info,warning,error等几个级别,当我们指定level=INFO时,logging.debug就不起作用了。同理,指定level=WARNING后,debug和info就不起作用了。这样一来,你可以放心地输出不同级别的信息,也不用删除,最后统一控制输出哪个级别的信息。
logging的另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如console和文件。
pdb (命令行的使用)
第4种方式是启动Python的调试器pdb,让程序以单步方式运行,可以随时查看运行状态。我们先准备好程序:
# err.py
s = '0'
n = int(s)
print(10 / n)
然后启动:
$ python -m pdb err.py
> /Users/michael/Github/learn-python3/samples/debug/err.py(2)<module>()
-> s = '0'
以参数-m pdb启动后,pdb定位到下一步要执行的代码-> s = '0'。输入命令l来查看代码:
(Pdb) l
1 # err.py
2 -> s = '0'
3 n = int(s)
4 print(10 / n)
输入命令n可以单步执行代码:
(Pdb) n
> /Users/michael/Github/learn-python3/samples/debug/err.py(3)<module>()
-> n = int(s)
(Pdb) n
> /Users/michael/Github/learn-python3/samples/debug/err.py(4)<module>()
-> print(10 / n)
任何时候都可以输入命令p 变量名来查看变量值:
(Pdb) p s
'0'
(Pdb) p n
0
输入命令q结束调试,退出程序:
(Pdb) q
这种通过pdb在命令行调试的方法理论上是万能的,但实在是太麻烦了,如果有一千行代码,要运行到第999行得敲多少命令啊。还好,我们还有另一种调试方法。
pdb.set_trace()
这个方法也是用pdb,但是不需要单步执行,我们只需要import pdb,然后,在可能出错的地方放一个pdb.set_trace(),就可以设置一个断点:
# err.py
import pdb
s = '0'
n = int(s)
pdb.set_trace() # 运行到这里会自动暂停
print(10 / n)
运行代码,程序会自动在pdb.set_trace()暂停并进入pdb调试环境,可以用命令p查看变量,或者用命令c继续运行:
$ python err.py
> /Users/michael/Github/learn-python3/samples/debug/err.py(7)<module>()
-> print(10 / n)
(Pdb) p n
0
(Pdb) c
Traceback (most recent call last):
File "err.py", line 7, in <module>
print(10 / n)
ZeroDivisionError: division by zero
这个方式比直接启动pdb单步调试效率要高很多,但也高不到哪去。
IDE
如果要比较爽地设置断点、单步执行,就需要一个支持调试功能的IDE。目前比较好的Python IDE有:
Visual Studio Code:https://code.visualstudio.com/,需要安装Python插件。
PyCharm:http://www.jetbrains.com/pycharm/
另外,Eclipse加上pydev插件也可以调试Python程序。
import logging
logging.basicConfig(
level=logging.DEBUG,
filename="test.log",
datefmt="%Y-%m-%d %H:%M:%S",
format="【%(asctime)s %(levelname)s】 %(lineno)d: %(message)s"
)
logging.debug("debug")
logging.info("info")
logging.warning("warning")
logging.error("error")
三、单元测试
“测试驱动开发”(TDD:Test-Driven Development)
单元测试是用来对一个模块、一个函数或者一个类来进行正确性检验的测试工作。
比如对函数abs(),我们可以编写出以下几个测试用例:
-
输入正数,比如
1、1.2、0.99,期待返回值与输入相同; -
输入负数,比如
-1、-1.2、-0.99,期待返回值与输入相反; -
输入
0,期待返回0; -
输入非数值类型,比如
None、[]、{},期待抛出TypeError。
把上面的测试用例放到一个测试模块里,就是一个完整的单元测试。
如果单元测试通过,说明我们测试的这个函数能够正常工作。如果单元测试不通过,要么函数有bug,要么测试条件输入不正确,总之,需要修复使单元测试能够通过。
单元测试通过后有什么意义呢?如果我们对abs()函数代码做了修改,只需要再跑一遍单元测试,如果通过,说明我们的修改不会对abs()函数原有的行为造成影响,如果测试不通过,说明我们的修改与原有行为不一致,要么修改代码,要么修改测试。
这种以测试为驱动的开发模式最大的好处就是确保一个程序模块的行为符合我们设计的测试用例。在将来修改的时候,可以极大程度地保证该模块行为仍然是正确的。
我们来编写一个Dict类,这个类的行为和dict一致,但是可以通过属性来访问
class Dict(dict):
def __init__(self, **kw):
super().__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Dict' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
编写单元测试 需要引入python自带的unittest模块,
import unittest
from mydict import Dict
class TestDict(unittest.TestCase):
def test_init(self):
d = Dict(a=1, b='test')
self.assertEqual(d.a, 1)
self.assertEqual(d.b, 'test')
self.assertTrue(isinstance(d, dict))
def test_key(self):
d = Dict()
d['key'] = 'value'
self.assertEqual(d.key, 'value')
def test_attr(self):
d = Dict()
d.key = 'value'
self.assertTrue('key' in d)
self.assertEqual(d['key'], 'value')
def test_keyerror(self):
d = Dict()
with self.assertRaises(KeyError):
value = d['empty']
def test_attrerror(self):
d = Dict()
with self.assertRaises(AttributeError):
value = d.empty
编写单元测试时,我们需要编写一个测试类,从unittest.TestCase继承。
以test开头的方法就是测试方法,不以test开头的方法不被认为是测试方法,测试的时候不会被执行。
对每一类测试都需要编写一个test_xxx()方法。由于unittest.TestCase提供了很多内置的条件判断,我们只需要调用这些方法就可以断言输出是否是我们所期望的。最常用的断言就是assertEqual():
self.assertEqual(abs(-1), 1) # 断言函数返回的结果与1相等
另一种重要的断言就是期待抛出指定类型的Error,比如通过d['empty']访问不存在的key时,断言会抛出KeyError:
with self.assertRaises(KeyError):
value = d['empty']
而通过d.empty访问不存在的key时,我们期待抛出AttributeError:
with self.assertRaises(AttributeError):
value = d.empty
运行单元测试
一旦编写好单元测试,我们就可以运行单元测试。最简单的运行方式是在mydict_test.py的最后加上两行代码:
if __name__ == '__main__':
unittest.main()
这样就可以把mydict_test.py当做正常的python脚本运行:
$ python -m unittest mydict_test
.....
----------------------------------------------------------------------
Ran 5 tests in 0.000s
OK
或者是 直接以脚本形式运行
$ python mydict_test.py
setUp与tearDown
可以在单元测试中编写两个特殊的setUp()和tearDown()方法。这两个方法会分别在每调用一个测试方法的前后分别被执行。
setUp()和tearDown()方法有什么用呢?设想你的测试需要启动一个数据库,这时,就可以在setUp()方法中连接数据库,在tearDown()方法中关闭数据库,这样,不必在每个测试方法中重复相同的代码:
class TestDict(unittest.TestCase):
def setUp(self):
print('setUp...')
def tearDown(self):
print('tearDown...')
可以再次运行测试看看每个测试方法调用前后是否会打印出setUp...和tearDown...。
单元测试可以有效地测试某个程序模块的行为,是未来重构代码的信心保证。
单元测试的测试用例要 覆盖常用的输入组合、边界条件和异常。
单元测试代码要非常简单,如果测试代码太复杂,那么测试代码本身就可能有bug。
单元测试通过了并不意味着程序就没有bug了,但是不通过程序肯定有bug。
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def get_grade(self):
if self.score < 0 or self.score > 100:
raise ValueError("Score Value Error! Must between [0~100]!")
if 80 > self.score >= 60:
return 'B'
if self.score >= 80:
return 'A'
return 'C'
单元测试类
import unittest
from Student import *
class TestStudent(unittest.TestCase):
def test_80_to_100(self):
s1 = Student('Bart', 80)
s2 = Student('Lisa', 100)
self.assertEqual(s1.get_grade(),'A')
self.assertEqual(s2.get_grade(), 'B')
def test_60_to_80(self):
s1 = Student('Bart', 60)
s2 = Student('Lisa', 79)
self.assertEqual(s1.get_grade(), 'B')
self.assertEqual(s2.get_grade(),'B')
def test_0_to_60(self):
s1 = Student('Bart', 0)
s2 = Student('Lisa', 59)
self.assertEqual(s1.get_grade(), 'C')
self.assertEqual(s2.get_grade(), 'C')
def test_invalid(self):
s1 = Student('Bart', -1)
s2 = Student('Lisa', 101)
with self.assertRaises(ValueError):
s1.get_grade()
with self.assertRaises(ValueError):
s2.get_grade()
if __name__ == '__main__':
unittest.main()
运行结果记录:
前面得出的是在A范围的 与B不符合
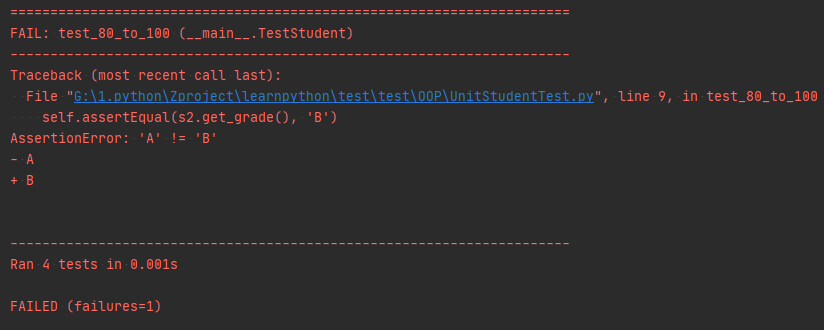
改成正常的预期结果之后 运行没有报错则显示如下
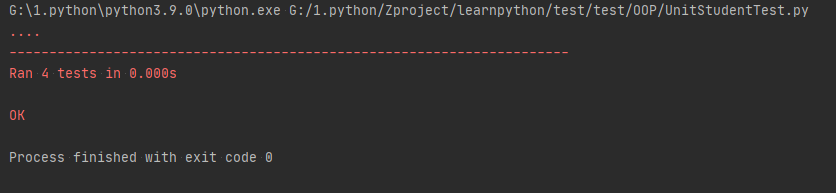
运行程序可能会遇到的问题:
【问题一】
python 单元测试出现 Ran 0 tests in 0.000s OK 可能的原因有下面三个
1、测试的函数没有以test开头
2、在unittest.main()的前面没有 if name == ‘main’:
3、你测试的类没有继承unittest.TestCase
【问题二】
在一个类里面调用另外一个类出现错误 NameError: name 'Student' is not defined——>表示没有调用
或者是TypeError: 'module' object is not callable——>表示调用方式不正确
从一个类中调用另外一个类的方法的导入方式,如 from Student import *
【问题三】
pycharm中代码格式规范的方式
在Settings -> Keymap ->Main menu ->code ->Reformat Code
可以对当前的代码规范的快捷键进行修改
代码规范的快捷键 :ctrl+alt+L
点击“Add Keyboard Shortcut”直接添加的方式之后,会弹出添加快捷键的窗口,将光标放在输入框中,直接在键盘上同时按下对应的键作为快捷键,输入框中将直接显示出来,确认无误后点击确定则新建成功,可以看到并列的两个快捷键,其中有一个是新创建的,再remove掉旧的就可以了。
【问题四】
IndentationError: unindent does not match any outer indentation level
说明当前的代码里面有空格和制表符,不支持空格和tab符的混合使用,这边要排查的话,只能是让当前的软件显示出空格和制表符
在Settings -> Editor -> Appearance ->Show whitespaces 就可以显示
——>显示的就是tab键
.........显示的就是空格
可以使用nodepad 将所有的tab替换成空格 设置->首选项:语言->以空格取代(TAB键)
四、文档测试
doctest是python自带的一个模块。本博客将介绍doctest的两种使用方式:一种是嵌入到python源码中,另外一种是放到一个独立文件。
doctest模块会搜索那些看起来像是python交互式会话中的代码片段,然后尝试执行并验证结果。
1)doctest嵌入源码中
Python内置的“文档测试”(doctest)模块可以直接提取注释中的代码并执行测试。
下面的模块只有一个函数,里面嵌入了两个doctest测试用例。
unnecessary_math.py:
'''
这个例子展示如何在源码中嵌入doctest用例。
'>>>' 开头的行就是doctest测试用例。
不带 '>>>' 的行就是测试用例的输出。
如果实际运行的结果与期望的结果不一致,就标记为测试失败。
'''
def multiply(a, b):
"""
>>> multiply(4, 3)
12
>>> multiply('a', 3)
'aaa'
"""
return a * b
if __name__=='__main__':
import doctest
doctest.testmod(verbose=True)
有两个地方可以放doctest测试用例,一个位置是模块的最开头,另一个位置是函数声明语句的下一行(就像上面的例子这样)。除此之外的其它地方不能放,放了也不会执行。
那个verbose参数,如果设置为True则在执行测试的时候会输出详细信息。默认是False,表示运行测试时,只有失败的用例会输出详细信息,成功的测试用例不会输入任何信息。
运行结果:
G:\1.python\python3.9.0\python.exe G:/1.python/Zproject/learnpython/test/test/OOP/doctestTest.py
Trying:
multiply(4, 3)
Expecting:
12
ok
Trying:
multiply('a', 3)
Expecting:
'aaa'
ok
1 items had no tests:
__main__
1 items passed all tests:
2 tests in __main__.multiply
2 tests in 2 items.
2 passed and 0 failed.
Test passed.
Process finished with exit code 0
上面启动测试的方式是在__main__函数中调用了doctest.testmod()方法。如果__main__函数有其他用途,不方便调用doctest.testmod()方法,那么可以用另外一种执行测试的方法:
这里 -m 表示引用一个模块,-v 等价于 verbose=True。运行输出与上面基本一样。
$ python -m doctest XXX.py
$ python -m doctest -v XXXX.py
可能遇到的问题:
【问题一】AttributeError: module 'doctest' has no attribute 'testmod'
报错原因:保存的文件名是doctest.py,导致doctest模块被重写。修改文件名,并删除文件目录下的__pycache__文件夹后,重新运行即可
【问题二】ValueError: line 3 of the docstring for __main__.fact lacks blank after >>>: '>>>fact(1)'
报错原因:>>>后面有个空格
【问题三】File "E:\LearnPython\doctest1.py", line 14, in __main__.fact
Failed example:
fact(-1)
Exception raised:
Traceback (most recent call last):
File "C:\Program Files\Python36\lib\doctest.py", line 1330, in __run
compileflags, 1), test.globs)
File "<doctest __main__.fact[2]>", line 1, in <module>
fact(-1)
File "E:\LearnPython\doctest1.py", line 20, in fact
raise ValueError()
ValueError
报错原因:Traceback后面有个空格
2)doctest独立文件
如果不想将doctest测试用例嵌入到python的源码中,则可以建立一个独立的文本文件来保存测试用例。
将doctest测试用例从上面的python源码中剥离出来放到test_unnecessary_math.txt文件里。
这个例子展示如何将doctest用例放到一个独立的文件中。
'>>>' 开头的行就是doctest测试用例。
不带 '>>>' 的行就是测试用例的输出。
如果实际运行的结果与期望的结果不一致,就标记为测试失败。
>>> from unnecessary_math import multiply
>>> multiply(3, 4)
12
>>> multiply('a', 3)
'aaa'
注意:from 那一行也要以>>>开头。
在系统的shell中执行:
python -m doctest -v xxxx.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号