python学习笔记(三)---高级特性
一、切片
取无数多个list元素 不用一个个取得笨方法就用切片
对这种经常取指定索引范围的操作,用循环十分繁琐,因此,Python提供了切片(Slice)操作符,能大大简化这种操作。
对应上面的问题,取前3个元素,用一行代码就可以完成切片:
记住倒数第一个元素的索引是-1,第一个数的索引是0
#1.传统方法
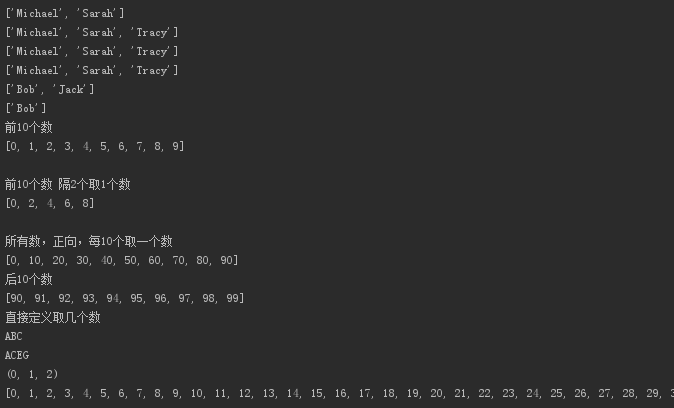
L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
R = []
#取前N个元素,也就是索引为0-(N-1)的元素,可以用循环
n=3
for i in range(n):
R.append(L[i])
print( R )
#2 切片方法
print( L[0:3] )
print( L[:3] )
print( L[-2:] )
print( L[-2:-1] )
#切片操作十分有用。我们先创建一个0-99的数列
L = list(range(100))
print("前10个数")
print ( L[:10])
print("\n前10个数 隔2个取1个数")
print ( L[:10:2])
print("\n所有数,正向,每10个取一个数")
print(L[::10])
print("后10个数")
print(L[-10:])
print('直接定义取几个数')
print ( 'ABCDEFG'[:3] )
print ( 'ABCDEFG'[::2] )
print((0, 1, 2, 3, 4, 5)[:3])
print( L[:] )
其实是substring
二、迭代
给定一个对象(tuple、list、dict、string字符串),我们可以通过for循环来遍历,这种遍历我们称为迭代(Iteration)
在Python中,迭代是通过以下内容来完成的
for ... in
只要当前对象是可迭代对象,则for循环就可正常运行,判断当前对象是否可迭代,且对当前对象进行迭代
# -*- coding: utf-8 -*-
#判断当前对象是否为可迭代对象
from collections import Iterable 运行会出现如下警告
DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.10 it will stop working
from collections import Iterable
弃用警告:从collections中导入ABCs已被弃用,并在python3.8中将停止工作,可使用collections.abc代替它进行使用
from collections.abc import Iterable
#1.str是否可迭代
print(isinstance('abc', Iterable))
#2.list是否可迭代
print(isinstance([1,2,3],Iterable))
#3.tuple是否可迭代
print(isinstance((1,2,3),Iterable))
#1.迭代打印list for i in [4,5,6]: print(i) #2.迭代打印tuple for i in (6,7,8): print (i) #3.迭代打印dict #使用当前的迭代可以输出key、输出value、输出key和value d={'a':1,'b':2,'c':3} for value in d.values(): print(value) for key in d.keys(): print(key) for key,value in d.items(): print (key,value) for x,y in [(1,1),(2,4),(3,9)]: print(x,y) #4.迭代字符串 for i in 'ABC': print (i)
结果:


三、列表生成式
print('1.生成顺序的数字列表生成式')
print( list(range(1,11)) )
print('2.生成循环x的平方列表生成式 并 筛选出偶数的平方')
#出现问题print(x * x for x in range(1,11)if x%2==0) <generator object <genexpr> at 0x000002B0B4E9BF20>
#当前生成list外层需要中括号括起来
a=[x * x for x in range(1,11)if x%2==0]
print(a)
print('3.两层循环 全排列 实现 拼接字符')
b=[x+y for x in 'ABC' for y in 'XYZ']
print(b)
print('4.调用dict输出2个变量 实现 拼接字符')
dict={'A':'x','B':'Y','C':'Z'}
c=[x+y for x,y in dict.items()]
print(c)
print('5.把list的所有字符串变成小写')
d=['ABBY','AMY','BOBBY','JIMMY']
d=[i.lower() for i in d ]
print(d)
print('6.输出文件中的所有文件和目录')
import os
print( [e for e in os.listdir('.')] )
结果:

四、生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
generator是非常强大的工具,在Python中,可以简单地把列表生成式改成generator,也可以通过函数实现复杂逻辑的generator。
要理解generator的工作原理,它是在for循环的过程中不断计算出下一个元素,并在适当的条件结束for循环。对于函数改成的generator来说,遇到return语句或者执行到函数体最后一行语句,就是结束generator的指令,for循环随之结束。
请注意区分普通函数和generator函数,普通函数调用直接返回结果:
>>> r = abs(6)
>>> r
6
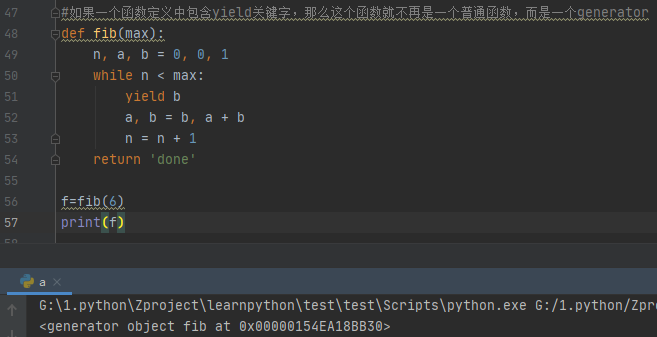
generator函数的“调用”实际返回一个generator对象:
>>> g = fib(6)
>>> g
<generator object fib at 0x1022ef948>fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator
#如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
f=fib(6)
print(f)
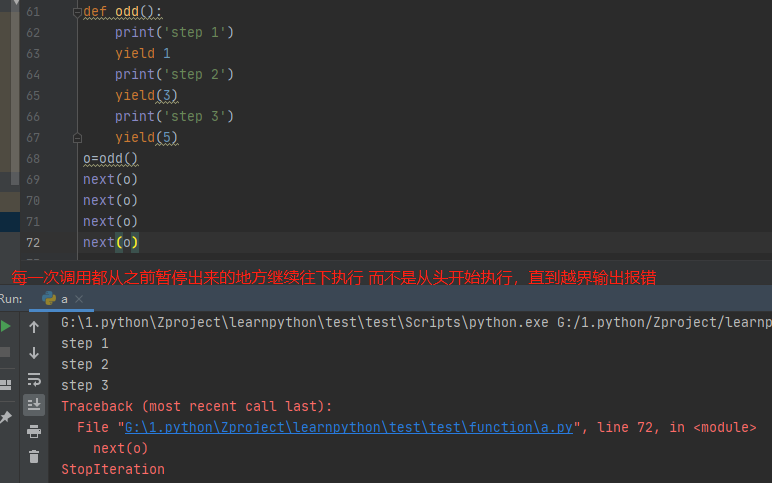
generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。
而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行,如下面这个函数显示的内容一样。
def odd():
print('step 1')
yield 1
print('step 2')
yield(3)
print('step 3')
yield(5)
o=odd()
next(o)
next(o)
next(o)
next(o)
回到fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
for n in fib(6): print(n)
#如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
# f=fib(6)
# print(f)
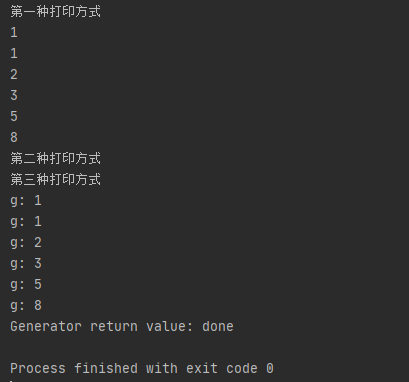
print('第一种打印方式')
for n in fib(6):
print(n)
#使用这种方式没有办法打印出真的值
print('第二种打印方式')
f=fib(6)
next(f)
#当前使用for循环调用generator时发现拿不到generator的return语句的返回值,如果想要拿到返回值
#必须捕获StopIteration错误 返回值在Iteration的value中
print('第三种打印方式')
g=fib(6)
while True:
try:
x=next(g)
print('g:',x)
except StopIteration as e:
print('Generator return value:',e.value)
break
结果
五、迭代器
什么是迭代器?可以直接作用于for循环的对象统称为可迭代对象:Iterable,包括
1.集合类数据类型:list、tuple、dict、set、str
2.generator:包括生成器和带yield的generator function
怎么判断是迭代器?
from collections.abc import Iterable
print(isinstance([], Iterable))
print(isinstance((), Iterable))
print(isinstance('abc', Iterable))
print(isinstance((x for x in range(10)), Iterable))

生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
pass
# 等价于首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号